0 概述-
在自动驾驶感知算法中BEV感知成为热点话题,BEV感知可以弥补2D感知的缺陷构建3D“世界”,更有利于下游任务和特征融合。为响应市场需求,地平线集成了基于bev的纯视觉算法,目前已支持ipm-based 、lss-based、 transformer-based(Geometry-guided Kernel Transformer、detr3d、PETR) 的多种bev视觉转换方法。其中PETR为基于detr的3D检测算法,实现是端到端的,本文为PETR感知算法的介绍和使用说明。
该示例为参考算法,仅作为在J5上模型部署的设计参考,非量产算法
1 性能精度指标-
PETR模型配置及指标::-
dataset
backbone
input_shape
num_query
NDS(浮点/定点)
FPS(双核)
Nuscenes
Eficientnet-B3
6x3x512x1408
900
37.66/37.19
8.3
注:建议使用小分辨率对模型性能会更友好:例如输入为[4,3,480,640]时,性能表现为双核62FPS,以实际需求为主-
Nuscenes 数据集官方介绍:nuScenes
2 模型介绍
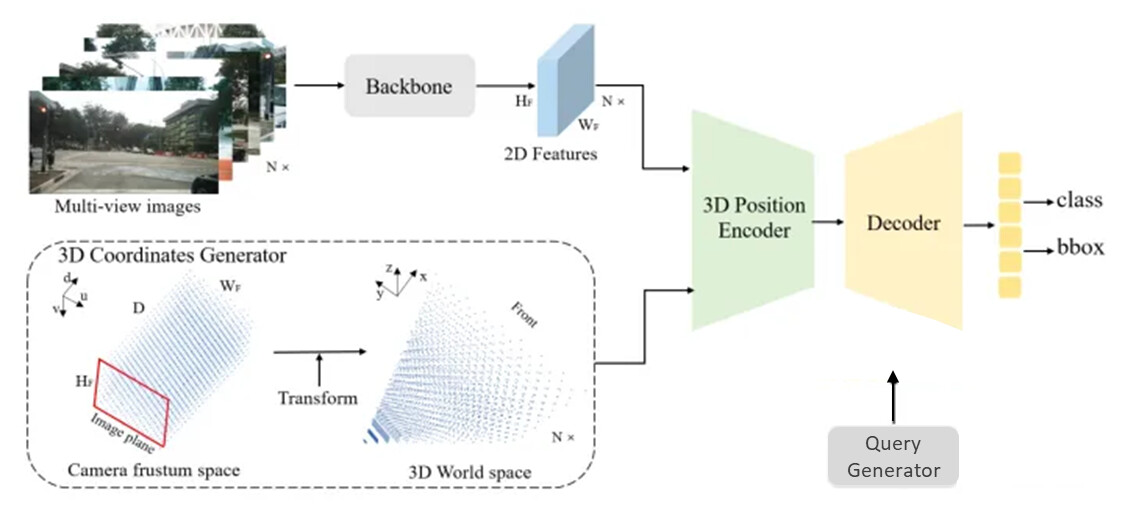
PETR模型主要包括以下部分:-
**Part1—2D feature extra:**对输入的6V图像经过2D CNN提取多视图2D图像特征。-
**Part2—3D Position Encoder:**生成3D坐标,对3D坐标融合位置编码形成3D Position Embedding。-
**Part3—transfomer Decoder:**transformer解码器,将query做自注意力后再与图像特征做交互注意力,最后通过FFN层得到目标的类别分数和位置。-
2.1 改动点说明-
- 替换了backbone,由resnet50的backbone替换回了同级别的efficientnet b3
- Decoder部分,query由原来的3维(1,900,256)/ NQC 改成了(1,256, 4, 128)/NCHW,逻辑实现上与公版一致
- 使用1x1的卷积替换了公版的linear,减少transpose和reshape的操作
- LayerNorm2d为地平线内部自实现算子,性能更高
2.2 源码说明-
2.2.1 Config文件-
configs/bev/petr_efficientnetb3_nuscenes.py 为该模型的配置文件,定义了模型结构、数据集加载,和整套训练流程,所需参数的说明在算子定义中会给出。配置文件主要内容包括:-
#基础参数配置
task_name = "petr_efficientnetb3_nuscenes"
num_classes = 10
batch_size_per_gpu = 1
device_ids = [0, 1, 2, 3, 4, 5, 6, 7]
#参数配置
num_query = 900
query_align = 128
data_shape = (3, 512, 1408)
bev_range = (-51.2, -51.2, -5.0, 51.2, 51.2, 3.0)
position_range = (-61.2, -61.2, -10.0, 61.2, 61.2, 10.0)
# 模型结构定义
model = dict(
type="Detr3d",
backbone=dict(
type="efficientnet",
model_type="b3",
...
),
head=dict(
type="PETRHead",
...
transformer=dict(
type="PETRTransformer",
decoder=dict(
type="PETRDecoder",
...
)
)
...
),
)
deploy_model = dict(
...
)
...
# 数据加载
data_loader = dict(
type=torch.utils.data.DataLoader,
...
)
val_data_loader = dict(...)
#不同step的训练策略配置
float_trainer=dict(...)
calibration_trainer=dict(...)
qat_trainer=dict(...)
int_infer_trainer=dict(...)
#不同step的验证
float_predictor=dict(...)
calibration_predictor=dict(...)
qat_predictor=dict(...)
int_infer_predictor=dict(...)
#编译配置
compile_cfg = dict(
march=march,
...
)
注: 如果需要复现精度,config中的训练策略最好不要修改。否则可能会有意外的训练情况出现。
2.2.2 img_encoder-
来自6个view的image作为输入通过共享的backbone(efficientnet-b3)输出经过encoder后的feature,feature_shape为(6*B,C,1/2H,1/2W)。encoder即对多个view的img_feature 做特征提取,过程见下图:

对应代码:hat/models/backbones/efficientnet.py
2.2.3 head-

由上图可知,PETR的head层完成特征提取和生成预测目标的全流程,通过生成的3D coords融合位置编码生成成pos_embed ;根据num_query生成可学习的query_embed;再将2D feature 做1x1的conv映射,将以上做为transformer解码器的输入。经由transfomer层做注意力计算生成target,通过cls、reg分支得到预测类别和位置。-
对应代码:hat/models/task_modules/petr/head.py
2D-Features 映射-
将2D feature使用1x1的卷积映射:
self.input_project = nn.Conv2d(
self.in_channels, self.embed_dims, kernel_size=1
)
3D Coords 生成
coords3d = self.position_embeding(feat, meta)
实现为position_embeding,通过feat的shape和homo生成3D coords:
def position_embeding(self, feat, meta):
_, _, img_H, img_W = meta["img"].shape
N, _, H, W = feat.shape
coords_h = torch.arange(H, device=feat.device).float() * img_H / H
coords_w = torch.arange(W, device=feat.device).float() * img_W / W
...
if self.homo is not None:
homography = self.homo
else:
homography = meta["ego2img"]
coords3d = []
for homo in homography:
...
coord3d = torch.matmul(coords, homo.permute(1, 0).float()).float()
coords3d.append(coord3d)
coords3d = torch.stack(coords3d)[..., :3]
coords3d[..., 0:1] = (coords3d[..., 0:1] - self.position_range[0]) / (
self.position_range[3] - self.position_range[0]
)
...
coords3d = (
coords3d.permute(0, 3, 4, 1, 2).contiguous().view(N, -1, H, W)
)
coords3d = inverse_sigmoid(coords3d)
return coords3d
生成位置编码-
位置编码记录图像的位置信息,编码方式为正弦编码,实现为 SinePositionalEncoding3D
sin_embed = self.positional_encoding(masks)
##config
positional_encoding=dict(
type="SinePositionalEncoding3D", num_feats=128, normalize=True
),
3D PE 生成-
对3D coords 编码,实现为conv+relu+conv,输出的C为embed_dims
pos_embed = self.position_encoder(coords3d)
融合位置编码-
为了得到位置信息,将位置信息添加到PE中,融合方式为add
masks = torch.zeros((bs, self.num_views, h, w), device=feat.device).to(
torch.bool
)
sin_embed = self.positional_encoding(masks)
sin_embed = sin_embed.flatten(0, 1)
sin_embed = self.adapt_pos3d(sin_embed)
pos_embed = pos_embed + sin_embed
生成query 编码-
生成可学习的reference_points(queries) ,转换为3D的query,然后将其编码(conv+relu+conv),最终形成query_embed 。
self.reference_points = nn.Embedding(self.num_query, 3)
query_embed = pos2posemb3d(
reference_points, num_pos_feats=self.embed_dims // 2
)
query_embed = (
query_embed.permute(1, 0)
.contiguous()
.view(1, -1, self.num_query_h, self.num_query_w)
.repeat(bs, 1, 1, 1)
)
query_embed = self.query_embedding(query_embed)
transformer层-
完成2D features到3D features的 特征转换,该部分会在1.2.4章节详细说明。
feats = self.transformer(feat, query_embed, pos_embed, masks)
预测层-
预测分支分为reg_branch和cls_branch,PC端在head层完成根据reference_points和reg计算bbox过程。
for feat in feats:
cls = self.cls_branch(feat)
cls = self.cls_dequant(cls)
reg = self.reg_branch(feat)
reg = self.reg_dequant(reg)
if self.compile_model is True:
cls_list.append(cls)
reg_list.append(reg)
else:
...
#calculate bbox
reg[..., 0:3] = reg[..., 0:3] + reference_points
reg[..., 0:3] = reg[..., 0:3].sigmoid()
reg[..., 0] = (
reg[..., 0] * (self.bev_range[3] - self.bev_range[0])
+ self.bev_range[0]
)
...
reg = reg.view(bs, -1, self.reg_out_channels)
reg_list.append(reg)
return cls_list, reg_list
1.2.4 PETR Transformer-
由DecoderLayer构成:
def forward(self, query, key, value, query_pos, key_pos, masks):
outs = []
for decode_layer in self.decode_layers:
query = decode_layer(
query=query,
key=key,
value=value,
query_pos=query_pos,
key_pos=key_pos,
)
outs.append(query)
return outs
Decoder层数为6层,上一层的输出为下一层的输入,每层主要完成两个注意力计算:在query之间做self-attention,再和图像特征之间做cross-attention。整理流程如下图:

Self attention-
该层为query之间的4维自注意力层,q=k,避免不同的queries 预测同一个目标。
##初始化后的tgt融合query_pos(query_embed):Add
query_pos_embed = self.pos_add1.add(query, query_pos)
tgt2, _ = self.self_attns(
query=query_pos_embed, key=query_pos_embed, value=query
)
self_attns为多头注意力机制MultiheadAttention,具体实现的代码路径为hat/models/base_modules/attention.py:
class HorizonMultiheadAttention(nn.Module):
...
def forward(...):
# set up shape vars
bsz, embed_dim, tgt_h, tgt_w = query.shape
_, _, src_h, src_w = key.shape
...
#q k v projection layers
...
#q k v reshpe
q = (
q.contiguous()
.view(bsz * self.num_heads, self.head_dim, tgt_h, tgt_w)
.permute(0, 2, 3, 1)
)
k = ...
...
# q = q * self.scale
# attention = (q @ k.transpose(-2, -1))
scale = self.scale_quant(self.scale)
q = self.mul.mul(
q, scale
) # [bsz*self.num_heads, tgt_h, tgt_w, self.head_dim]
attention = self.matmul.matmul(
q, k
) # [bsz*self.num_heads, tgt_h, tgt_w, src_h*src_w]
if attn_mask is not None:
# attention = attention + mask
attn_mask = attn_mask.contiguous().unsqueeze(1)
attention = self.mask_add.add(attention, attn_mask)
attention = self.softmax(attention)
else:
attention = self.softmax(attention)
attention = self.attention_drop(attention)
# output = (attention @ v)
attn_output = self.attn_matmul.matmul(
attention, v
) # [bsz*self.num_heads, tgt_h, tgt_w, self.head_dim]
...
return attn_output, None
CrossAttention-
该层为交叉注意力层,为MultiheadAttention,将2D feature融合3D PE作为key,该层在特征中实现提取和聚集目标信息,参数如下:
##
query_pos_embed = self.pos_add2.add(tgt, query_pos)
key_pos_embed = self.pos_add3.add(key, key_pos)
tgt2, _ = self.corss_attn(
query=query_pos_embed,
key=key_pos_embed,
value=value,
)
3 浮点模型训练-
3.1 Before Start-
3.1.1 发布物及环境部署-
step1:获取发布物-
下载OE包horizon_j5_open_explorer_v$version$.tar.gz,获取方式见地平线开发者社区 OpenExplorer算法工具链 版本发布-
step2:解压发布包
tar -xzvf horizon_j5_open_explorer_v$version$.tar.gz
解压后文件结构如下:
|-- bsp
|-- ddk
| |-- package
| `-- samples
| |-- ai_benchmark
| |-- ai_forward_view_sample
| |-- ai_toolchain
| | |-- ...
| | |-- horizon_model_train_sample
| | `-- model_zoo
| |-- model_zoo
| `-- vdsp_rpc_sample
|-- README-CN
|-- README-EN
|-- resolve_all.sh
`-- run_docker.sh
其中horizon_model_train_sample为参考算法模块,包含以下模块:
|-- horizon_model_train_sample #参考算法示例
| |-- plugin_basic #qat 基础示例
| `-- scripts #模型配置文件、运行脚本
step3:拉取docker环境
docker pull openexplorer/ai_toolchain_ubuntu_20_j5_gpu:v$version$
#启动容器,具体参数可根据实际需求配置
#-v 用于将本地的路径挂载到 docker 路径下
nvidia-docker run -it --shm-size="15g" -v `pwd`:/WORKSPACE openexplorer/ai_toolchain_ubuntu_20_j5_gpu:v$version$
3.1.2 数据集准备-
3.1.2.1 数据集下载-
进入nuscenes官网,根据提示完成账户的注册,下载Full dataset(v1.0)、CAN bus expansion和Map expansion(v1.3)这三个项目下的文件。下载后的压缩文件为:
|-- nuScenes-map-expansion-v1.3.zip
|-- can_bus.zip
|-- v1.0-mini.tar
|-- v1.0-trainval01_blobs.tar
|-- ...
|-- v1.0-trainval10_blobs.tar
`-- v1.0-trainval_meta.tar
Full dataset(v1.0)包含多个子数据集,如果不需要进行v1.0-trainval数据集的浮点训练和精度验证,可以只下载v1.0-mini数据集进行小场景的训练和验证。
将下载完成的v1.0-trainval01_blobs.tar~v1.0-trainval10_blobs.tar、v1.0-trainval_meta.tar和can_bus.zip进行解压,解压后的目录如下所示:
|--nuscenes
|-- can_bus #can_bus.zip解压后的目录
|-- samples #v1.0-trainvalXX_blobs.tar解压后的目录
| |-- CAM_BACK
| |-- ...
| |-- CAM_FRONT_RIGHT
| |-- ...
| `-- RADAR_FRONT_RIGHT
|-- sweeps
| |-- CAM_BACK
| |-- ...
| |-- CAM_FRONT_RIGHT
| |-- ...
| `-- RADAR_FRONT_RIGHT
|-- v1.0-trainval #v1.0-trainval_meta.tar解压后的数据
|-- attribute.json
| ...
`-- visibility.json
3.1.2.2 数据集打包-
进入 horizon_model_train_sample/scripts 目录,使用以下命令将训练数据集和验证数据集打包,格式为lmdb:
#pack train_Set
python3 tools/datasets/nuscenes_packer.py --src-data-dir /WORKSPACE/nuscenes/ --pack-type lmdb --target-data-dir /WORKSPACE/tmp_data/nuscenes/v1.0-trainval --version v1.0-trainval --split-name train
#pack val_Set
python3 tools/datasets/nuscenes_packer.py --src-data-dir /WORKSPACE/nuscenes/ --pack-type lmdb --target-data-dir /WORKSPACE/tmp_data/nuscenes/v1.0-trainval --version v1.0-trainval --split-name val
--src-data-dir为解压后的nuscenes数据集目录;-
--target-data-dir为打包后数据集的存储目录;-
--version 选项为[“v1.0-trainval”, “v1.0-test”, “v1.0-mini”],如果进行全量训练和验证设置为v1.0-trainval,如果仅想了解模型的训练和验证过程,则可以使用v1.0-mini数据集;v1.0-test数据集仅为测试场景,未提供注释。-
全量的nuscenes数据集较大,打包时间较长。每打包完100张会在终端有打印提示,其中train打包约28100张,val打包约6000张。
数据集打包命令执行完毕后会在target-data-dir下生成train_lmdb和val_lmdb,train_lmdb和val_lmdb就是打包之后的训练数据集和验证数据集为config中的data_rootdir。
|-- tmp_data
| |-- nuscenes
| | |-- v1.0-trainval
| | | |-- train_lmdb #打包后的train数据集
| | | | |-- data.mdb
| | | | `-- lock.mdb
| | | `-- val_lmdb #打包后的val数据集
| | | | |-- data.mdb
| | | | `-- lock.mdb
2.1.2.3 meta文件夹构建-
在tmp_data/nuscenes 下创建meta文件夹,将v1.0-trainval_meta.tar压缩包解压至meta,得到meta/maps文件夹,再将nuScenes-map-expansion-v1.3.zip压缩包解压至meta/maps文件夹下,解压后的目录结构为:
|-- tmp_data
| |-- nuscenes
| | |-- meta
| | | |-- maps #nuScenes-map-expansion-v1.3.zip解压后的目录
| | | | |-- 36092f0b03a857c6a3403e25b4b7aab3.png
| | | | |-- ...
| | | | |-- 93406b464a165eaba6d9de76ca09f5da.png
| | | | |-- prediction
| | | | |-- basemap
| | | | |-- expansion
| | | |-- v1.0-trainval #v1.0-trainval_meta.tar解压后的目录
| | | |-- attribute.json
| | | ...
| | | |-- visibility.json
| | `-- v1.0-trainval
| | | |-- train_lmdb #打包后的train数据集
| | | `-- val_lmdb #打包后的val数据集
3.1.3 config配置-
在进行模型训练和验证之前,需要对configs文件中的部分参数进行配置,一般情况下,我们需要配置以下参数:
- device_ids、batch_size_per_gpu:根据实际硬件配置进行device_ids和每个gpu的batchsize的配置;
- ckpt_dir:浮点、calib、量化训练的权重路径配置,权重下载链接在config文件夹下的README中;
- data_rootdir:2.1.2.2中打包的数据集路径配置;
- meta_rootdir :2.1.2.3中创建的meta文件夹的路径配置;
- float_trainer下的checkpoint_path:浮点训练时backbone的预训练权重所在路径,可以使用README的# Backbone Pretrained ckpt中ckpt download提供的float-checkpoint-best.pth.tar权重文件。
3.2 浮点模型训练-
config文件中的参数配置完成后,使用以下命令训练浮点模型:
python3 tools/train.py --config configs/bev/petr_efficientnetb3_nuscenes.py --stage float
float训练后模型ckpt的保存路径为config配置的
ckpt_callback中save_dir的值,默认为ckpt_dir。
3.3 浮点模型精度验证-
浮点模型训练完成以后,通过指定训好的float_checkpoint_path,使用以下命令验证已经训练好的模型精度:
python3 tools/predict.py --config configs/bev/petr_efficientnetb3_nuscenes.py --stage float
验证完成后,会在终端打印浮点模型在验证集上检测和分割精度,如下所示:
Per-class results:
Object Class AP ATE ASE AOE AVE AAE
car 0.416 0.571 0.184 0.400 1.329 0.209
...
2023-06-06 18:24:09,976 INFO [nuscenes_metric.py:358] Node[0] NDS: 0.3060, mAP:0.2170
...
2023-06-06 18:24:10,513 INFO [mean_iou.py:170] Node[0] ~~~~ MeanIOU Summary metrics ~~~~
Summary:
Scope mIoU mAcc aAcc
global 51.47 75.62 86.29
Per Class Results:
Class IoU Acc
others 85.10 88.42
...
2023-06-06 18:24:10,524 INFO [metric_updater.py:320] Node[0] Epoch[0] Validation petr: NDS[0.3060] MeanIOU[tensor(0.5147, device='cuda:0')]
4 模型量化和编译-
完成浮点训练后,还需要进行量化训练和编译,才能将定点模型部署到板端。地平线对该模型的量化采用horizon_plugin框架,经过Calibration+定点模型转换后,使用compile的工具将量化模型编译成可以上板运行的hbm文件。-
4.1 Calibration-
模型完成浮点训练后,便可进行 Calibration。calibration在forward过程中通过统计各处的数据分布情况,从而计算出合理的量化参数。 通过运行下面的脚本就可以开启模型的Calibration过程:
python3 tools/train.py --config configs/bev/petr_efficientnetb3_nuscenes.py --stage calibration
4.2 Calibration 模型精度验证-
calibration完成以后,可以使用以下命令验证经过calib后模型的精度:
python3 tools/predict.py --config configs/bev/petr_efficientnetb3_nuscenes.py --stage calibration
验证完成后,会在终端输出calib模型在验证集上检测和分割精度,格式见3.3。
4.3 量化模型训练-
Calibration完成后,就可以加载calib权重开启模型的量化训练。 量化训练其实是在浮点训练基础上的finetue,具体配置信息在config的qat_trainer中定义。量化训练的时候,初始学习率设置为浮点训练的十分之一,训练的epoch次数也大大减少。和浮点训练的方式一样,将checkpoint_path指定为训好的calibration权重路径。-
通过运行下面的脚本就可以开启模型的qat训练:
python3 tools/train.py --config configs/bev/petr_efficientnetb3_nuscenes --stage qat
4.4 量化模型精度验证-
量化模型的精度验证,只需要运行以下命令:
#qat模型精度验证
python3 tools/predict.py --config configs/bev/petr_efficientnetb3_nuscenes.py --stage qat
#quantize模型精度验证
python3 tools/predict.py --config configs/bev/petr_efficientnetb3_nuscenes.py --stage int_infer
qat模型的精度验证对象为插入伪量化节点后的模型(float32);quantize模型的精度验证对象为定点模型(int8),验证的精度是最终的int8模型的真正精度,这两个精度应该是十分接近的。
4.5 仿真上板精度验证-
除了上述模型验证之外,我们还提供和上板完全一致的精度验证方法,可以通过下面的方式完成:
python3 tools/align_bpu_validation.py --config configs/bev/petr_efficientnetb3_nuscenes.py
4.6 量化模型编译-
在训练完成之后,可以使用compile的工具用来将量化模型编译成可以上板运行的hbm文件,同时该工具也能预估在BPU上的运行性能,可以采用以下脚本:
python3 tools/compile_perf.py --config configs/bev/petr_efficientnetb3_nuscenes .py --out-dir ./ --opt 3
opt为优化等级,取值范围为0~3,数字越大优化等级越高,运行时间越长。-
compile_perf脚本将生成.html文件和.hbm文件(compile文件目录下),.html文件为BPU上的运行性能,.hbm文件为上板实测文件。
5 其他工具-
5.1 结果可视化-
如果你希望可以看到训练出来的模型对于单帧的检测效果,我们的tools文件夹下面同样提供了预测及可视化的脚本,你只需要运行以下脚本即可:
python3 tools/infer.py --config configs/bev/petr_efficientnetb3_nuscenes.py --save_path ./
注:需在config文件中配置infer_cfg字段。
可视化示例:

6 板端部署-
6.1 上板性能实测-
使用hrt_model_exec perf工具将生成的.hbm文件上板做BPU性能FPS实测,hrt_model_exec perf参数如下:
hrt_model_exec perf --model_file {model}.hbm \
--thread_num 8 \
--frame_count 2000 \
--core_id 0 \
--profile_path '.'
-