qconfig使用简介
在使用PTQ时,用户只需要修改yaml文件,便可以实现对模型量化策略和精度的控制。对于QAT,配置qconfig可以达成相同的效果,并且qconfig既可以配置给整个模型,也可以配置给某一类算子,还可以单独配置给模型中的单个算子,使用起来较为灵活。qconfig支持的主要功能如下:
- 配置伪量化方式(包含fake_quant,lsq,pact)
- 配置observer(类似校准策略),并为不同的observer配置相应参数
- 启用per_channel量化方式
- 为模型或特定算子配置int16高精度量化
- 为模型尾部的conv算子配置int32高精度输出
qconfig配置参数详解
get_default_qconfig接口说明
首先介绍horizon_plugin_pytorch.quantization.get_default_qconfig接口,该接口定义了qconfig的基本参数,具体说明如下:
horizon_plugin_pytorch.quantization.get_default_qconfig(activation_fake_quant:
Optional[str] = 'fake_quant', weight_fake_quant: Optional[str] = 'fake_quant',
activation_observer: Optional[str] = 'min_max', weight_observer: Optional[str] = 'min_max',
activation_qkwargs: Optional[Dict] = None, weight_qkwargs: Optional[Dict] = None)
- activation_fake_quant – 激活的伪量化类别,可配置fake_quant,lsq,pact,默认为fake_quant
- weight_fake_quant – 权重的伪量化类别,可配置fake_quant,lsq,pact,默认为fake_quant
- activation_observer – 激活的校准策略,可配置min_max,fixed_scale,clip,percentile,clip_std,mse,kl,默认为min_max
- weight_observer – 权重的校准策略,可配置min_max,fixed_scale,clip,percentile,clip_std,mse,默认为min_max
- activation_qkwargs – 激活校准策略的字典参数
- weight_qkwargs – 权重激活策略的字典参数
其中,activation代表算子的输出,weight代表算子的权重。
自定义qconfig方式说明
用户可调用get_default_qconfig接口自定义qconfig,示例代码如下:
my_qconfig = get_default_qconfig(
activation_fake_quant="fake_quant",
weight_fake_quant="fake_quant",
activation_observer="mse",
weight_observer="min_max",
activation_qkwargs=None,
weight_qkwargs=None,
)
接下来依次讲解如何配置第一章提到的各种功能。
qconfig功能配置说明
伪量化方式
通常来说,激活和权重的伪量化方式使用默认的fake_quant即可,除非用户十分有把握,否则不建议修改。
observer类别
从经验来看,权重的校准策略推荐优先配置min_max,激活的校准策略推荐优先配置mse或min_max。qkwargs参数则根据选用的校准策略去配置,用户可以先不做特别修改,当后面需要细致地调节精度时,可参考《Calibration指南》章节尾部的API说明进行配置。参考代码如下:
my_observer_qconfig = get_default_qconfig(
activation_fake_quant="lsq",
weight_fake_quant="lsq",
activation_observer="min_max",
weight_observer="min_max",
activation_qkwargs={
"averaging_constant": 0.1,
},
weight_qkwargs={
"averaging_constant": 0.1,
},
)
其中averaging_constant就是min_max的可配置参数。
per_channel量化
在weight_qkwargs中配置qscheme和ch_axis参数即可:
my_per_channel_qconfig = get_default_qconfig(
activation_fake_quant="fake_quant",
weight_fake_quant="fake_quant",
activation_observer="min_max",
weight_observer="min_max",
activation_qkwargs=None,
weight_qkwargs={
"qscheme": torch.per_channel_symmetric,
"ch_axis": 0,
},
)
注意,qscheme和ch_axis的值是固定的,用户无需修改。
int16高精度量化
在weight_qkwargs中配置dtype参数即可:
my_int16_qconfig = get_default_qconfig(
activation_fake_quant="fake_quant",
weight_fake_quant="fake_quant",
activation_observer="min_max",
weight_observer="min_max",
activation_qkwargs={
"dtype": qint16,
},
weight_qkwargs=None,
)
# 注:如果在自定义qconfig中配置qint16,需要先from horizon_plugin_pytorch.dtype import qint16尾部conv算子int32输出
由于尾部conv的输出不需要伪量化和校准,因此将activation_fake_quant和activation_observer配置为None即可:
my_int32_out__qconfig = get_default_qconfig(
activation_fake_quant=None,
weight_fake_quant="fake_quant",
activation_observer=None,
weight_observer="min_max",
activation_qkwargs=None,
weight_qkwargs=None,
)
预设qconfig解读
在horizon_plugin_pytorch(以2.3.2为例)中,预设了地平线预先定义好的qconfig,大多数情况下,只使用这些qconfig即可满足calib和qat的需要。这些预设qconfig的详细配置方式您可以解压horizon_plugin_pytorch的whl包,并打开quantization目录下的qconfig.py文件查看。
常用的预设qconfig及其参数列表如下:
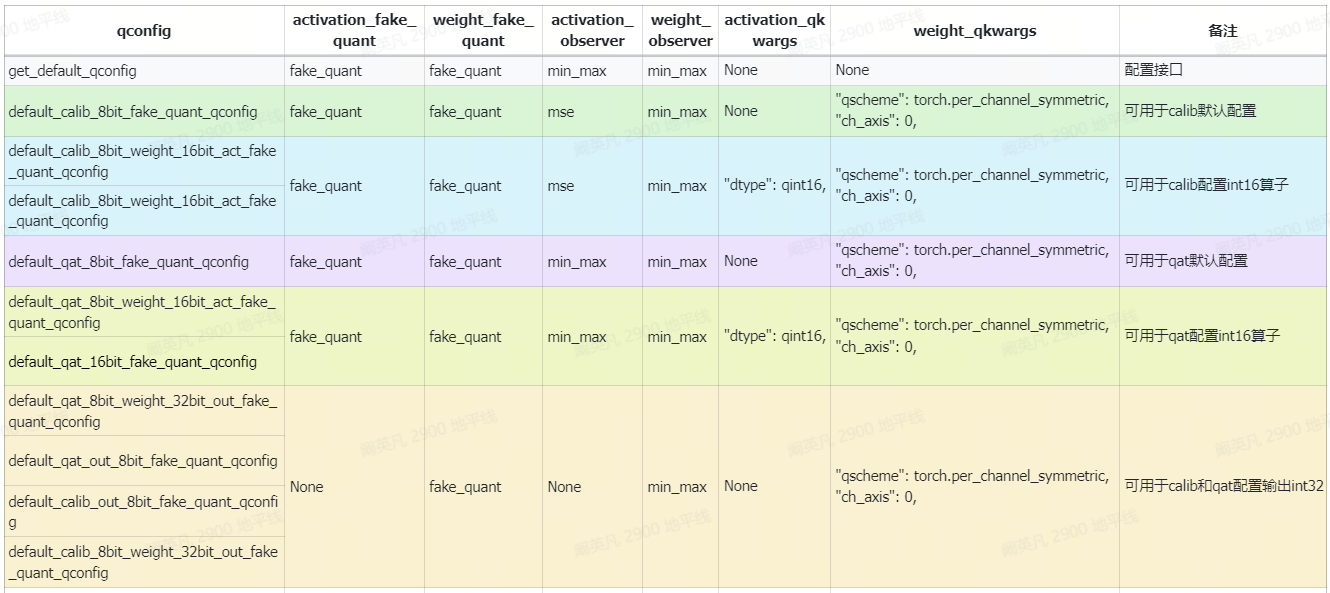
使用注意事项如下:
- get_default_qconfig不能直接使用,它只是一个qconfig配置接口,而不是现成的qconfig,因此需要先按本文2.2的方式进行配置
- default_calib_8bit_fake_quant_qconfig可用于模型的calib阶段
- default_calib_8bit_weight_16bit_act_fake_quant_qconfig和default_calib_8bit_weight_16bit_act_fake_quant_qconfig命名不同,功能相同,可用于在calib阶段为模型配置int16量化精度
- default_qat_8bit_fake_quant_qconfig命名不同,功能相同,可用于模型的qat阶段
- default_qat_8bit_weight_16bit_act_fake_quant_qconfig和default_qat_16bit_fake_quant_qconfig命名不同,功能相同,可用于在qat阶段为模型配置int16量化精度
- default_qat_8bit_weight_32bit_out_fake_quant_qconfig、default_qat_out_8bit_fake_quant_qconfig、default_calib_out_8bit_fake_quant_qconfig、default_calib_8bit_weight_32bit_out_fake_quant_qconfig命名不同,功能相同,可用于在模型的calib和qat阶段为尾部conv配置int32精度输出
以下为不常用的预设qconfig列表,由于activation_fake_quant和weight_fake_quant未使用fake_quant,因此除非您十分确定要使用pact或者lsq方法,否则请慎重选择。

需要注意的是,以上表格只列举了预设qconfig的推荐使用场景,用户并不需要严格遵从,当预设qconfig不满足需求时,可以使用自定义qconfig进行calib和qat。
为模型和算子配置qconfig
建议使用prepare_qat_fx接口的qconfig_dict参数进行配置。
无论是将模型从float阶段转为calib阶段还是qat阶段,都需要使用prepare_qat_fx接口,该接口包含qconfig_dict参数,可在该参数中为整个模型或者部分算子配置qconfig,参数具体说明如下:
qconfig_dict = {
"": qconfig,
"module_type": [(torch.nn.Conv2d, qconfig),...,],
"module_name": [("foo.bar", qconfig)...,],
其中,""表示为整个模型配置全局的qconfig,"module_type"表示为某一类算子批量配置qconfig,"module_name"表示为某一个算子单独配置qconfig。这三项均为可选配置,且优先级依次上升。
配置qconfig的示例代码如下,该段代码为calib模型配置了全局默认配置,并且将尾部的conv算子配置int32输出。
calib_model = prepare_qat_fx(
float_model,
{
"": default_calib_8bit_fake_quant_qconfig,
"module_name": {
"classifier": default_calib_8bit_weight_32bit_out_fake_quant_qconfig,
},
},
).to(device)
此外也有直接设置qconfig属性和使用qconfig模板的方法,可以参考用户手册《qconfig详解》章节进行了解。