RDK X5和Model Zoo使用体验
目录-
一、镜像烧录与配置-
1、SD卡烧录-
2、远程连接-
3、Vscode配置
二、Model Zoo拉取与模型安装-
1、拉取Model Zoo仓库-
2、安装Model Zoo的Python API-
3、下载模型-
4、python环境试运行
三、YoloWorld模型体验-
1、创建ROS2功能包-
2、编译、配置环境变量-
3、创建功能包-
4、编写python程序-
5、运行结果展示
一、镜像烧录与配置
1、SD卡烧录
★ 参考链接:地瓜开发者社区首页 (d-robotics.cc)-
X5镜像网址-
在地瓜开发者社区内选择rdk_x5的桌面版镜像,下载到电脑,解压。-
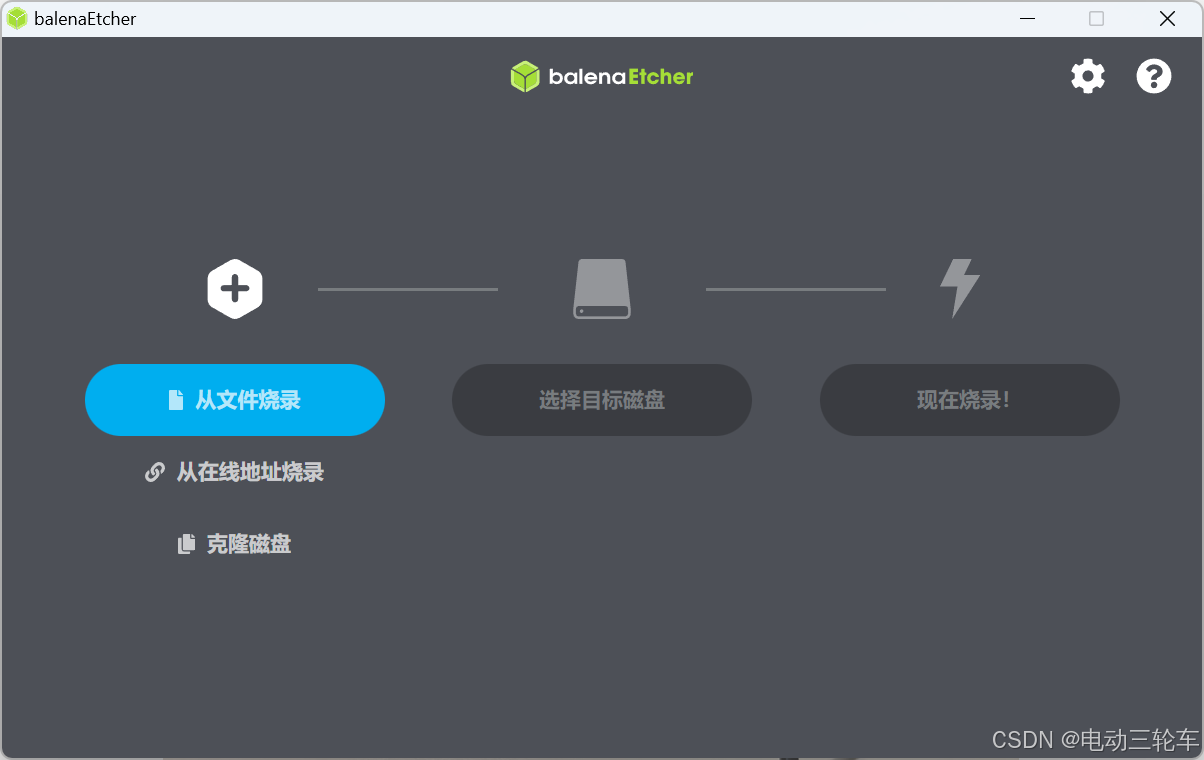
解压完成后,以管理员身份打开PC端启动盘制作工具balenaEtcher(点击跳转到下载链接),选择“从文件中烧录”,选择刚下载好的img文件,接着选择磁盘目标为SD卡对应盘符,完成后点击“现在烧录!”,等待烧录完成。-
管理员身份运行是为了防止出现烧录过程中出现 “镜像文件损坏” 这类问题。-
烧录完成后,在x5不插电的情况下,将烧录好的SD卡插值板卡底部的卡槽,再上电。-
-

上面的接口中,靠近边缘的为PWR电源接口;中间接口为USB 3.0 TYPE-C,USB Device模式,用于连接主机实现ADB、Fastboot、系统烧录等功能,这应该就是RDKx5板子首创的“闪连一下”功能的接口,需要配合RDK Studio使用;右侧Micro USB接口为调试用串口,后面的远程连接操作需要用到它。
2、远程连接
(1)串口连接
由于手边没有显示屏能直接连接到板子的HDMI接口,因此选择远程连接操作。-
在没有/不使用网线的情况下,通过USB-Micro USB线连接PC和RDK,在PC端设备管理器中查看是否连接成功。-

-

根据设备连接的串口号(这里为COM6),打开MobaXterm (点此跳转下载),点击左上角“Session”,选择“Serial”,配置串口号为COM6(根据实际情况选择),波特率选择115200,其他设置如下图。-
-
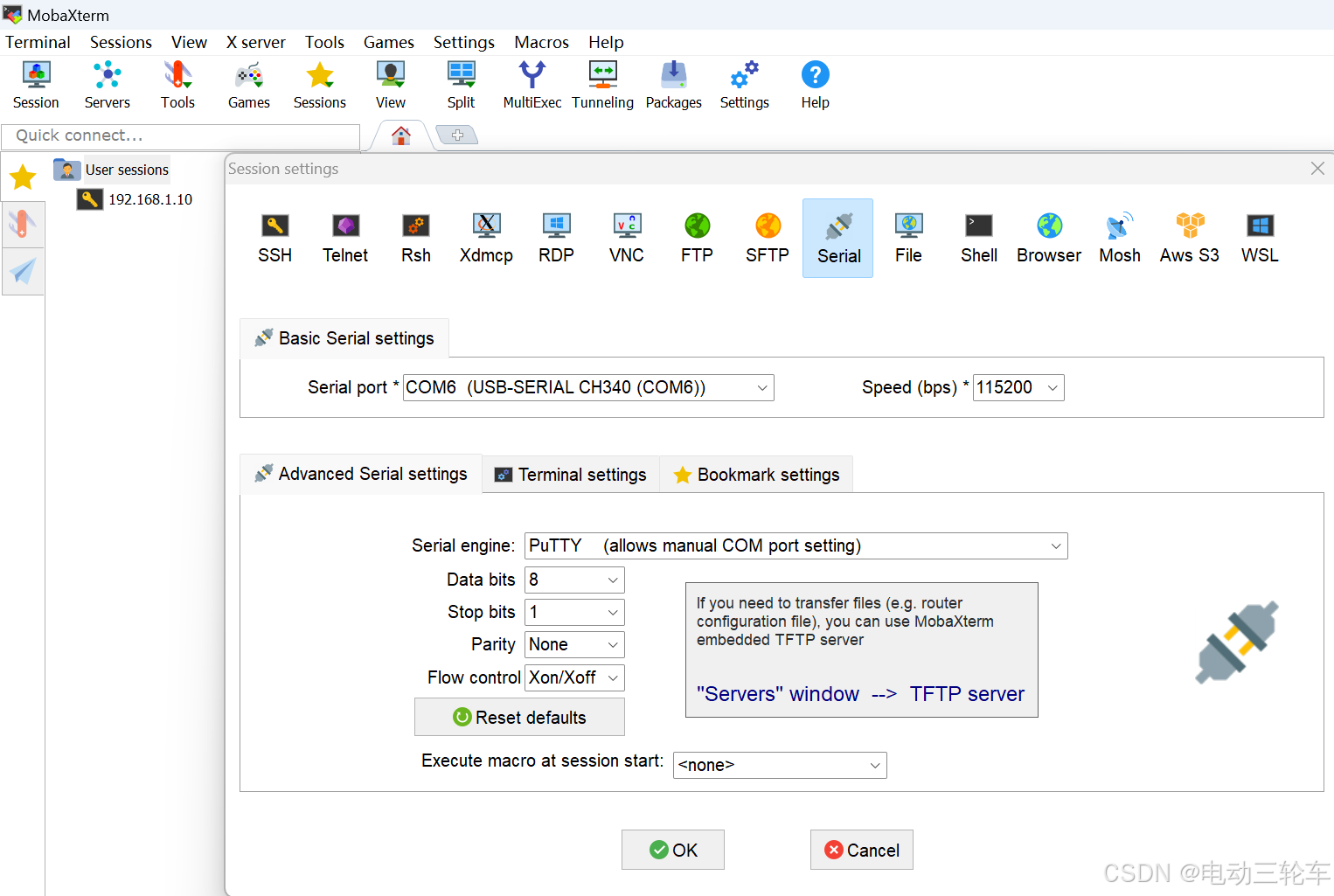
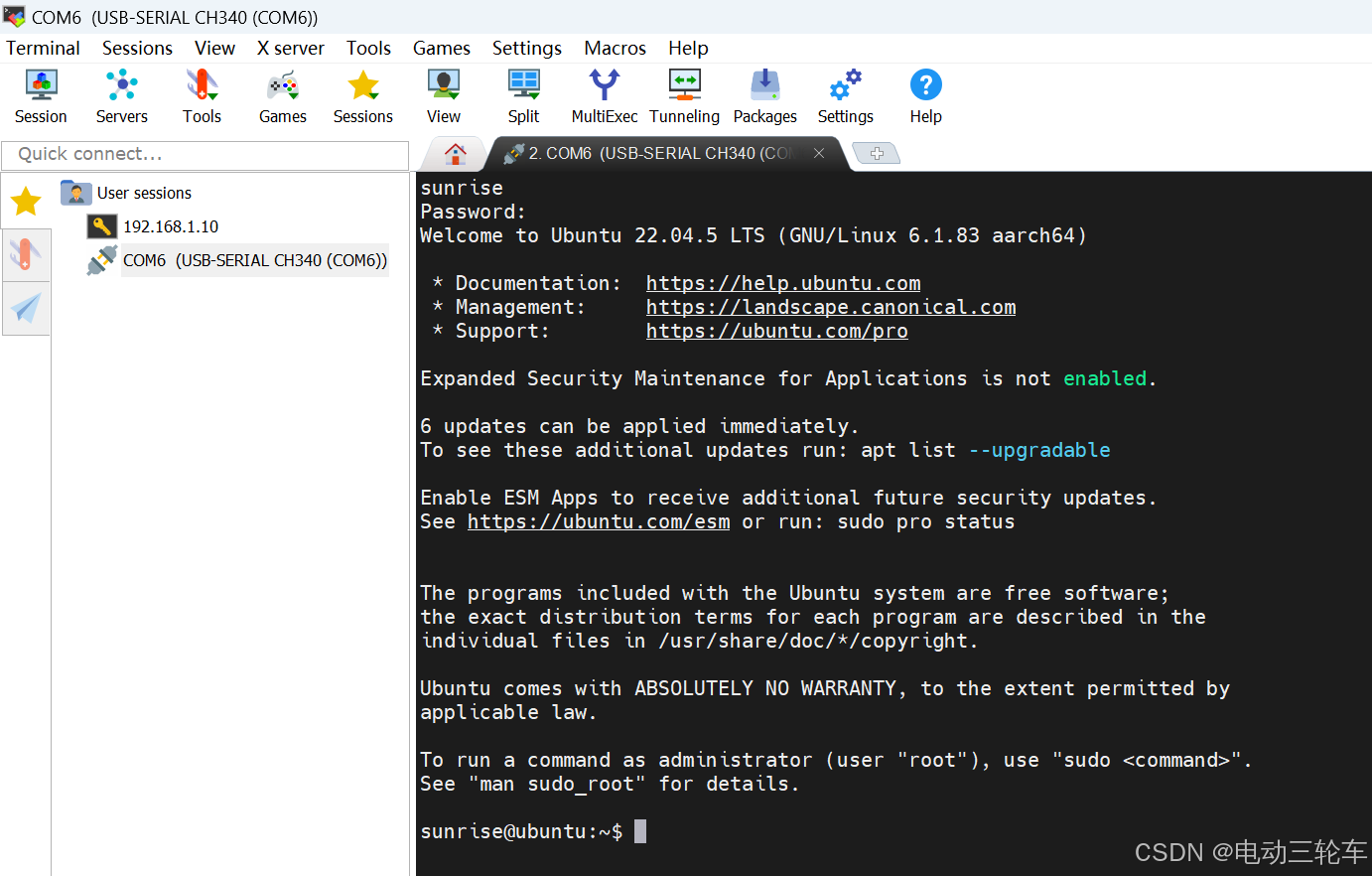
配置完成后“OK”即可,此时出现串口连接的窗口,输入账号“sunrise”,密码“sunrise”(窗口中不可见),回车则成功进入系统!-
(2)WiFi连接
进入系统后通过命令ifconfig查询当前板卡的IP地址,可以知道该镜像的静态IP地址为192.168.127.10,后续可通过该IP进行有线连接。通过如下命令连接WiFi。
sudo wifi_connect "wifi账号" "wifi密码"
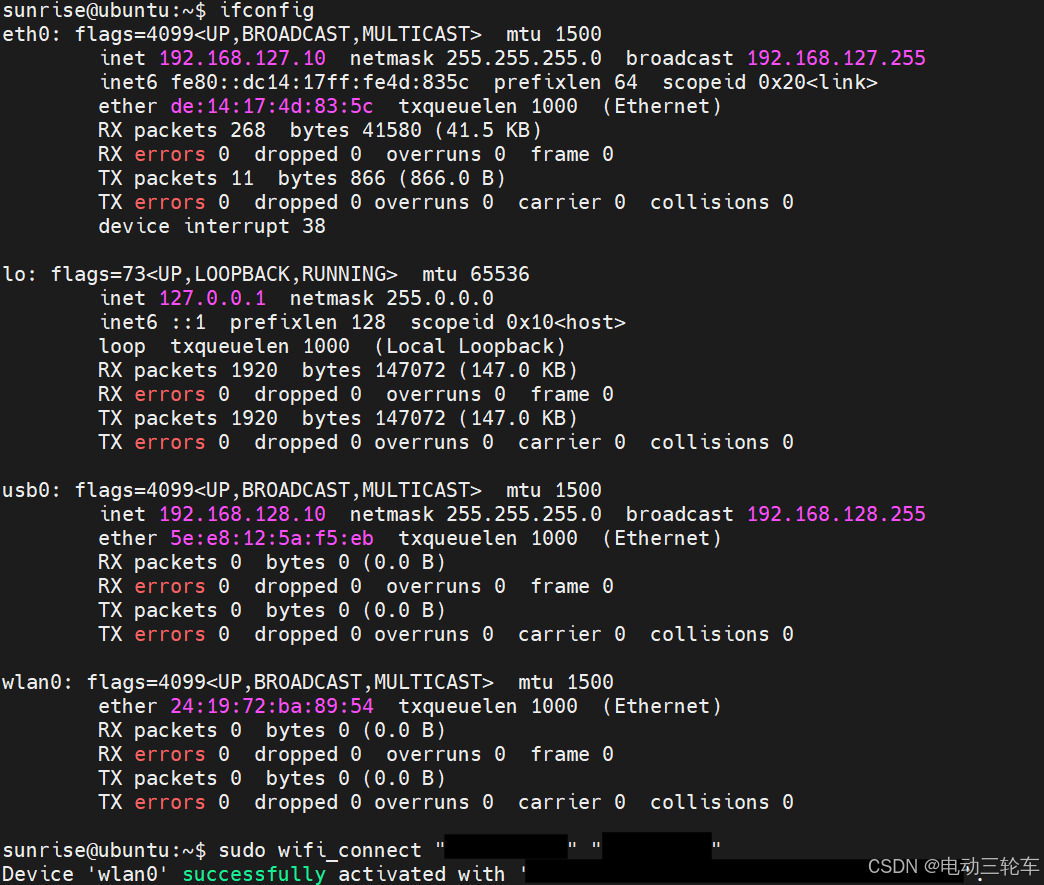
这一代的板卡网络连接速度明显快了不少,成功连接后查看wlan0端的IP地址[host_IP],这里为192.168.137.38。-
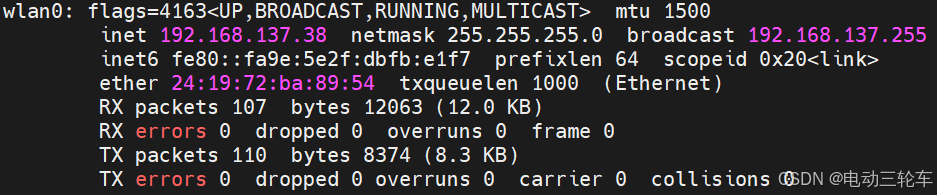
(3)SSH连接
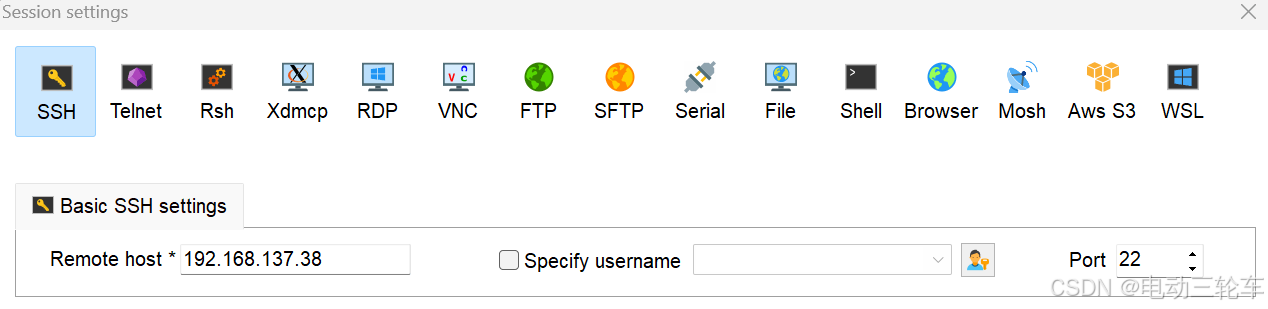
根据前面得到的动态IP地址host_IP进行无线SSH连接(静态IP地址为通过网线的有线连接)。在MobaXterm的“Session”窗口中选择“SSH”,输入对应host_IP即可。-
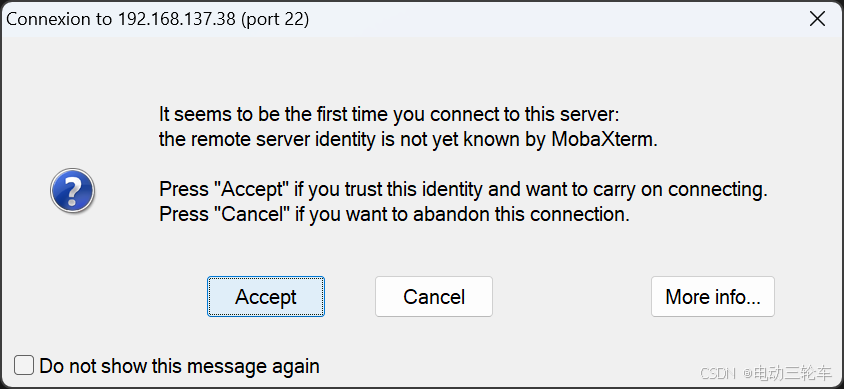
点击“OK”后,正常会弹出首次登录提醒,“Accept”即可。-
-
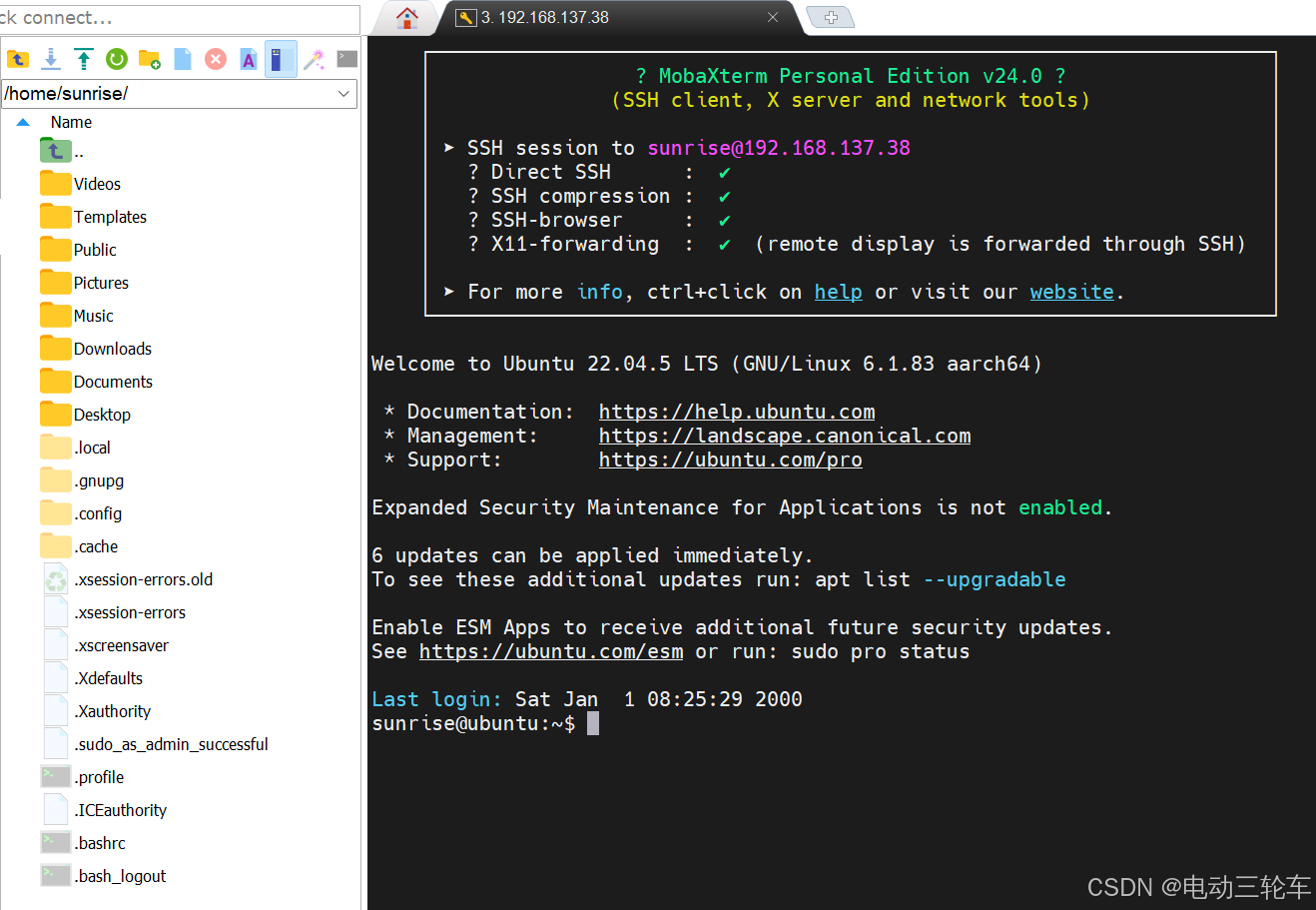
接着同样在窗口中输入账号(sunrise)、密码(sunrise)即可成功进入系统。-
3、Vscode配置
VS Code是一个非常好用的程序编辑软件,可以用过它远程连接小车板端并访问文件目录,同时可以提供代码补全功能。需要安装Remote-SSH和ROS2扩展插件,接着点击左侧标志"Remote Explorer",输入对应IP即可进入,接着进入对应的ROS2工作空间,VS Code会自动识别ROS2工作空间,之后就可以在编辑程序时自动补全。-
二、Model Zoo拉取与模型安装
★ 仓库链接:RDK Model Zoo-
★ 手册链接:Model Zoo 快速上手
1、首先拉取Model Zoo仓库到本地:
git clone https://github.com/D-Robotics/rdk_model_zoo
2、安装Model Zoo的Python API:
pip install bpu_infer_lib_x5 -i http://archive.d-robotics.cc/simple/ --trusted-host archive.d-robotics.cc
3、下载github中提供的模型, 在指定目录下输入如下命令
具体可以在Model Zoo各模型子文件下查看download.md文件找到对应的下载命令即可。
#下载yoloworld.bin
wget https://archive.d-robotics.cc/downloads/rdk_model_zoo/rdk_x5/yolo_world.bin
#下载yolov8s.bin,分割模型
wget https://archive.d-robotics.cc/downloads/rdk_model_zoo/rdk_x5/yolov8s_instance_seg_bayese_640x640_nv12_modified.bin

4、安装完成后在python环境中试运行:
(1)导入bpu_infer_lib库并实例化
>>> import bpu_infer_lib
>>> inf = bpu_infrt_lib.Infer(False)
>>> #从对应目录下加载分割模型Yolov8s-segmentation
>>> inf.load_model("/root/rdk_model_zoo/demos/Instance_Segmentation/Yolov8s_instance_seg_bayese_640x640_nv12_modified.bin")

(2)查看模型信息
>>> #查看输入数据的数量、类型、排布
>>> print("Number of Model's inputs", len(inf.inputs))
>>> print("Input[0]'s tensor layout:", inf.inputs[0].properties.tensorLayout)
>>> print("Input[0]'s tensor type:", inf.inputs[0].properties.tensorType)

>>> #查看输出数据的数量、类型、排布
>>> print("Number of Model's outputs", len(inf.outputs))
>>> print("Output[0]'s tensor layout:", inf.outputs[0].properties.tensorLayout)
>>> print("Output[0]'s tensor type:", inf.outputs[0].properties.tensorType)

从输出的结果数量、类型可以看出,分割模型的输出结果需要进一步的处理才能得到可视化的结果,比较复杂。输出的数据有s_mces, m_mces, l_mces, s_bboxes, m_bboxes, l_bboxes, s_clses, m_clses, l_clses, protos共10个参数。-
而YoloWorld模型的输出数据较少(见RDK用户手册),处理相对简单,因此后续测试会使用YoloWorld这一模型。
三、YoloWorld模型体验
1、创建ROS2功能包
root@ubuntu:~# mkdir -p /userdata/dev_ws/src
2、编译、配置环境变量
root@ubuntu:~# cd /userdata/dev_ws/
root@ubuntu:/userdata/dev_ws# colcon build
3、创建功能包
root@ubuntu:/userdata/dev_ws# cd src
root@ubuntu:/userdata/dev_ws/src# ros2 pkg create --build-type ament_python test_yolov8s_seg
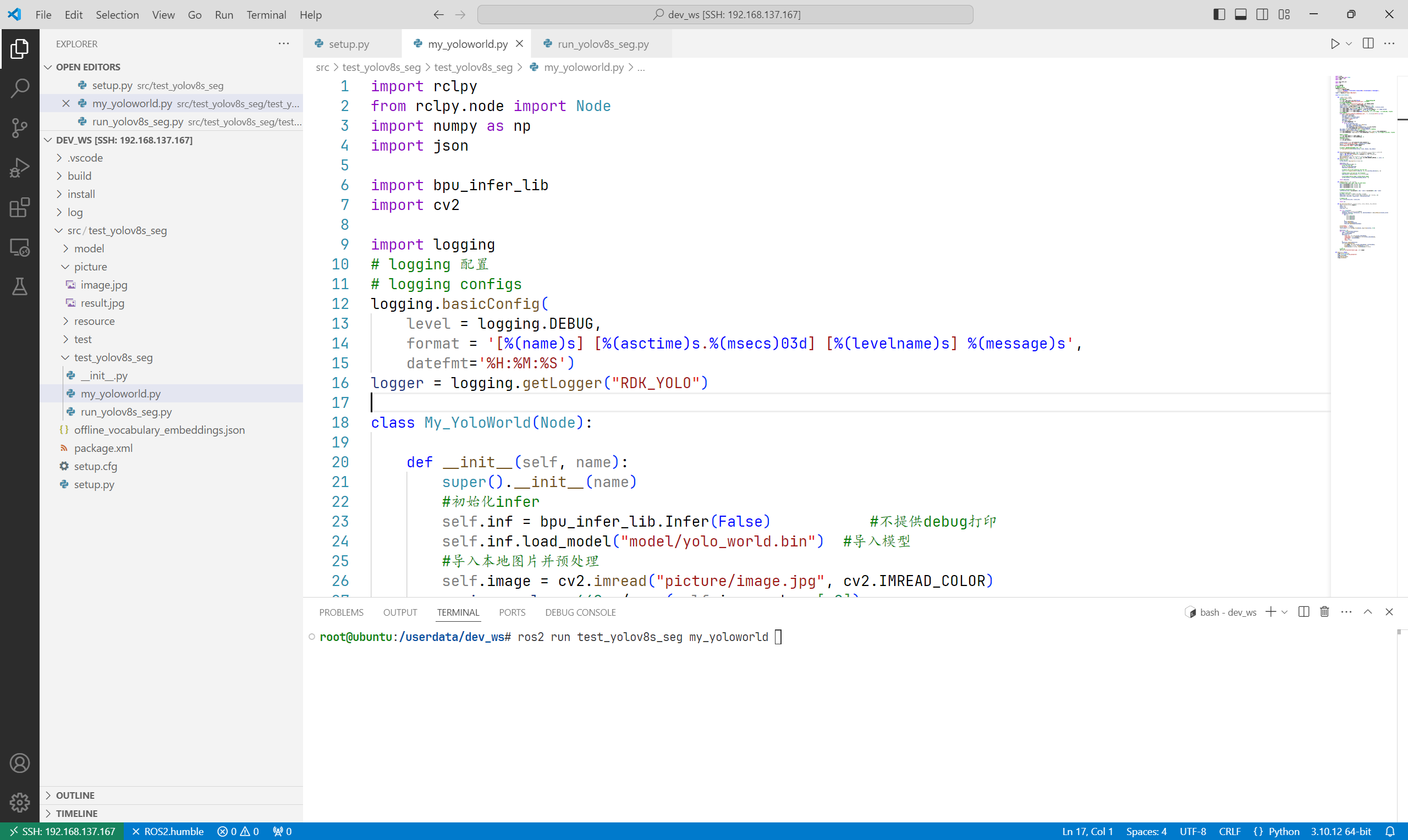
4、编写python程序
★ 参考文档:yoloworld.ipynb
(1)导入库
import rclpy
from rclpy.node import Node
import numpy as np
import json
import bpu_infer_lib
import cv2
(2)编写YoloWorld类的初始化函数
class My_YoloWorld(Node):
def __init__(self, name):
super().__init__(name)
#初始化infer
self.inf = bpu_infer_lib.Infer(False) #不提供debug打印
self.inf.load_model("model/yolo_world.bin") #导入模型
#导入本地图片并预处理
self.image = cv2.imread("picture/image.jpg", cv2.IMREAD_COLOR)
resize_scale = 640. / max(self.image.shape[:2])
scale = max((self.image.shape[0], self.image.shape[1])) / 640
image_resized = cv2.resize(self.image, (0, 0), fy=resize_scale, fx=resize_scale)
self.input_image = np.zeros((640, 640, 3), dtype=np.float32)
self.input_image[:image_resized.shape[0], :image_resized.shape[1], :] = image_resized
self.input_image = self.input_image[:, :, [2, 1, 0]] # bgr->rgb
self.input_image = self.input_image[None].transpose(0, 3, 1, 2) # shape - (1,3,640,640), float32
#导入本地文本
with open('offline_vocabulary_embeddings.json', 'r', encoding='utf-8') as file:
data = json.load(file)
json_keys = data.keys()
json_keys_list = list(json_keys)
self.classes = json_keys_list
input_voc = ["dog"]
key_indexs = []
self.text_embeddings = []
for voc in input_voc:
if voc in json_keys_list:
key_index = json_keys_list.index(voc)
key_indexs.append(key_index)
text_embedding = np.array(data[voc], dtype=np.float32)
self.text_embeddings.append(text_embedding)
key_indexs += [key_indexs[-1]] * (32 - len(key_indexs)) # padding
key_indexs = np.array(key_indexs) # shape (32,)
self.text_embeddings += [self.text_embeddings[-1]] * (32 - len(self.text_embeddings))
self.text_embeddings = np.array(self.text_embeddings).reshape(1, 32, -1) # shape (1,32,512), float32
#输入图像、文本
self.inf.read_input(self.input_image, 0)
self.inf.read_input(self.text_embeddings, 1)
#推理、输出结果
self.inf.forward()
self.inf.get_output()
classes_scores = self.inf.outputs[0].data.squeeze(-1)
print("classes_scores has shape:", classes_scores.shape)
bboxes = self.inf.outputs[1].data.squeeze(-1)
print("bboxes has shape:", bboxes.shape)
#找到并框出最大置信度的区域
self.get_maxscores_box(classes_scores, scale, bboxes, key_indexs)
#保存图片
cv2.imwrite("picture/result.jpg", self.image)
(3)编写完主程序后,在setup.py中创建指向main函数的接口

(4)运行程序
root@ubuntu:/userdata/dev_ws# ros2 run test_yolov8s_seg my_yoloworld
5、运行结果展示
原始图片:-

推理结果展示:-
-

程序中调用本地配置文件
offline_vocabulary_embeddings.json,输入的框选目标为dog,最终得到的推理结果准确度很高,同时推理速度很快,不过目前只体验了本地图片回灌,后续可以使用bpu_infer_lib这一python的API接口做更多的开发。