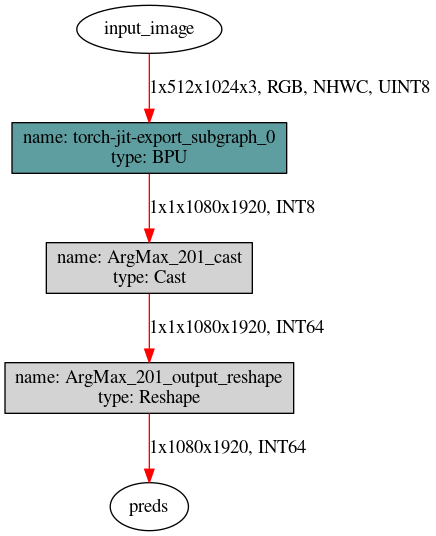
在onnx模型转换成bin文件时,模型尾部算子Argmax被自动拆分成了四个算子,然后三个运行在CPU上,这个是为什么呢?
您好, 我们想实现时序信号处理。即输入是1*n ,全连接多层,输出 1*n。 可以在GPU中运行 部署,加速吗。GPU部署对模型的限制有哪些?
谢谢!
您好,由于硬件特性,只有conv支持int32高精度输出,若模型以其他算子结尾,则只能以int8输出,然后接一个反量化算子变成float32。由于argmax算子原始计算精度为int64,所以会有一个cast用来完成int8->int64,另外原来模型输出是三维的,所有会有reshape用来完成4维->3维。 如果您觉得这两个算子耗时过长,可以使用hb_model_modifier工具将这两个cpu节点删除,并在后处理中完成对应计算。



{kind=link}