1. 说明
在7月5日的实验中,笔者已基于200张普通人脸图片和300张戴口罩的人脸图片训练出了TensorFlow框架下的YOLOv3目标检测模型,并保存为了TF框架的SavedModel模型。但由于地平线工具链中提供的YOLOv3示例是基于Caffe框架训练的,原本基于TensorFlow的YOLOv3模型无法正常转换为Caffe格式,所以重新选择YOLOv5s框架完成从迁移学习到框架转换的全流程(YOLOv5提供了方便的工具可以把模型导出为ONNX格式)。
2. 模型训练
根据地平线提供的文档https://developer.horizon.ai/api/v1/fileData/doc/ddk_doc/navigation/ai_toolchain/docs_cn/hb_mapper_sample_doc/samples/algorithm_sample.html#id2,他们支持的是YOLOv5的v2.0版本,因此将YOLOv5源码克隆到本地以后tags切换到v2.0。
接下来使用https://roboflow.com/制作数据集。将原先准备好的300张口罩人脸图片导入到RoboFlow里,又增添了一些图片并标注,最终形成了总量为392的数据集,按照7(train):2(valid):1(test)划分,并按照CC-BY-4.0协议开放知识版权。数据集链接:https://app.roboflow.com/tma-zp8vp/face_masked/6
接下来用YOLOv5官方提供的yolov5s.pt预训练模型在数据集上训练了约70个epoch,在验证集上达到了最佳mAP@.5=0.961的较好结果。以下是在测试集上的部分推理图片。


3. 模型预处理
在使用地平线工具链之前,首先应该将YOLOv5的.pt权重文件转换为可供工具链使用的ONNX模型。这里使用YOLOv5自带的models/export.py进行操作,其中在参数上有一些微调,详参地平线文档。
将转换好的ONNX模型放到工具链的对应文件夹,替换01_common/model_zoo/mapper/detection/yolov5_onnx_optimized/YOLOv5s.onnx
4. 模型量化参考图像配置
ddk/samples/ai_toolchain/horizon_model_convert_sample/01_common/calibration_data/中存放着用于模型量化的参考图像。默认使用的是COCO,为了保证量化效果,从口罩人脸数据集中选取44张作为参考图像,并将其路径写入02_preprocess.sh中。
--src_dir ../../../01_common/calibration_data/my_masked_face \
5. 模型转换
接下来按照01_check→02_preprocess→03_build的流程来转换模型。
小插曲: 用于calibration的图片文件名不能包含除英文数字下划线以外的字符(比如英文句号),否则在build时会发生以下报错
ERROR Could not find a backend to open `/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/04_detection/03_yolov5s/mapper/calibration_data_rgb_f32/0000_jpg.rf.1c2b41885a1a2a76a00e8cf2c1655c7d.rgb`` with iomode `ri`.
6. 模型测试
转换完成后生成了yolov5s_672x672_nv12_original_float_model.onnx,yolov5s_672x672_nv12_optimized_float_model.onnx,yolov5s_672x672_nv12_quantized_model.onnx,yolov5s_672x672_nv12.bin。分别对应原始浮点ONNX模型、优化后的浮点模型,量化模型和交叉编译后可以直接在开发板上运行的二进制文件量化模型。
工具链中的04_inference.sh可以利用量化后的模型进行单张图片的推断。
但首次运行时,发生了报错
ValueError: cannot reshape array of size 127008 into shape (1,84,84,3,85)
检查代码的对应段落可知,原本的代码是把三个输出向量reshape为1x84x84x3x85、1x42x42x3x85、1x21x21x3x85的YOLO格式(85即为Bounding Box=xyhwc+80 classes)然而通过再次运行01_check.sh可以发现,模型实际的output1形状是1x84x84x3x6(Bounding Box=xyhwc+1 classes)。此时笔者意识到,由于训练过程中只有masked_face这一种标注,因此输出向量的class被优化为了1。且1x84x84x3x6=127008,验证了这个想法。

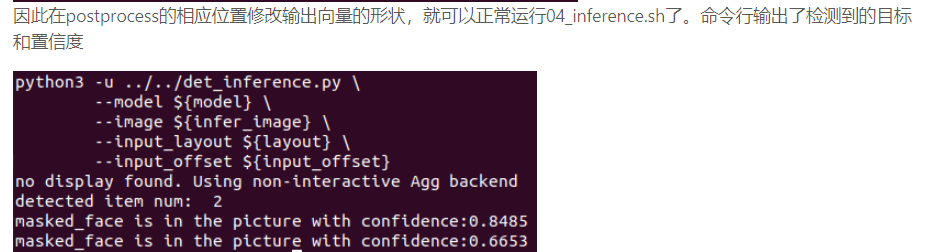
因此在postprocess的相应位置修改输出向量的形状,就可以正常运行04_inference.sh了。命令行输出了检测到的目标和置信度

生成的推断图片如下

7. 开发板部署
笔者在检查开发板上用于摄像头推断的主程序mipi_camera.py后发现,其仅适用于FCOS算法。迫于时间限制,未来得及自主编写针对YOLOv5算法的版本,今后若有时间,将尝试基于上位机上的det_inference.py编写。