1. AI芯片工具链介绍
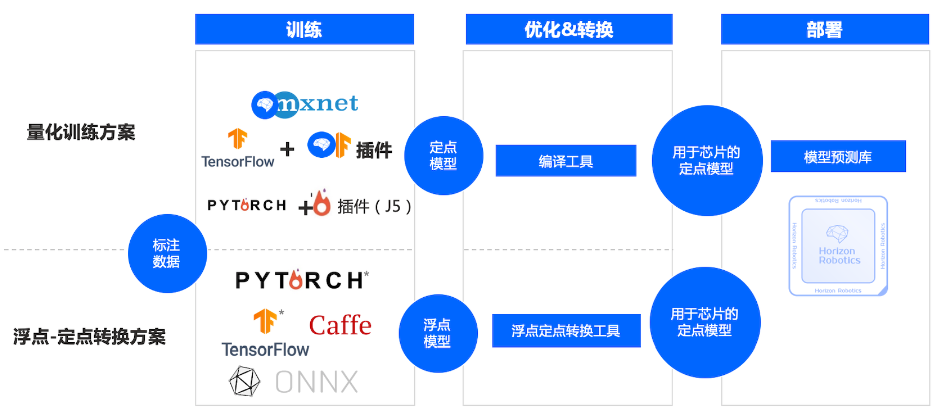
解决在地平线芯片上完成深度神经网络模型的训练、转换以及模型部署问题。
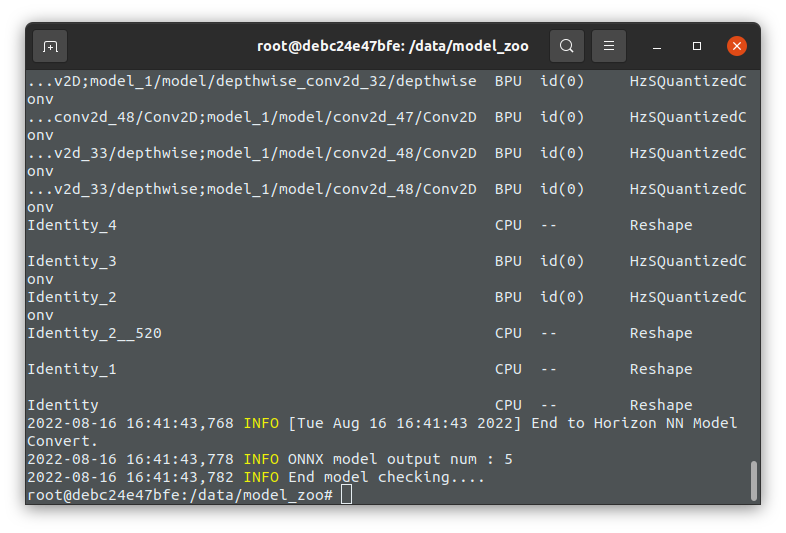
地平线量化工具链主要包括两套:量化训练工具链和浮点转定点工具链。
AI工具链开发手册:https://developer.horizon.ai/api/v1/fileData/doc/cn/source\_doc/x3\_ddk\_docs.html
2. docker环境搭建(linux)
Docker(>=1.12 建议安装18.03.0-ce)安装手册 https://docs.docker.com/install/
需要下载天工开物的开发包和镜像包
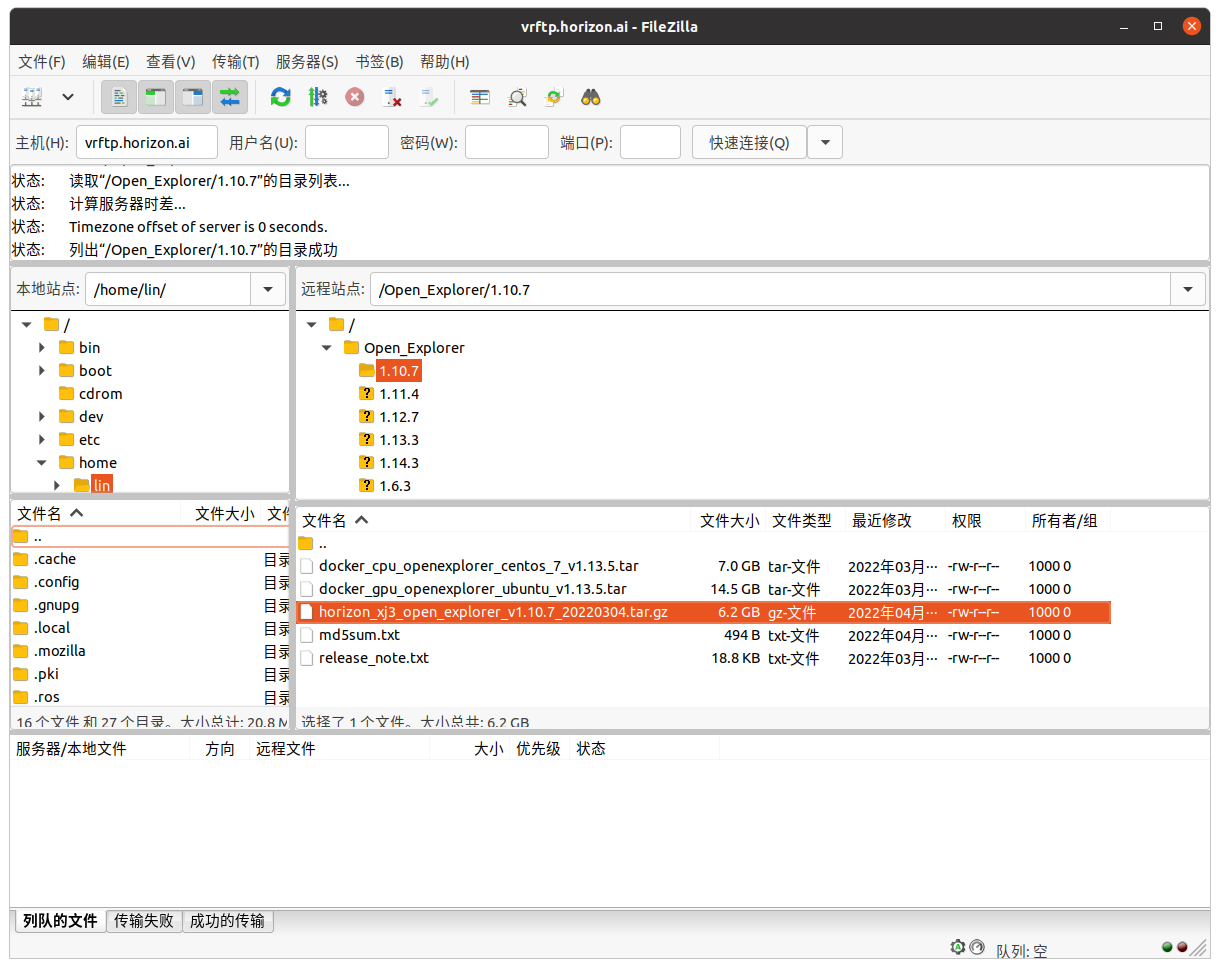
使用Filezilla下载开发包
新建终端下载Filezilla
sudo apt-get install filezilla
打开filezilla
filezilla
连接主机:vrftp.horizon.ai
下载对应开发包,要注意版本匹配。
使用路由器网络可能会导致连接不上,建议使用手机热点。
我这里下载的是1.10.7版本,对应镜像包版本为1.13.5
下载镜像包
镜像包可以选择从filezilla中下载,但是速度比较慢
镜像也可以从docker hub中选择所需版本pull:https://hub.docker.com/r/openexplorer/ai\_toolchain\_ubuntu\_gpu/tags
docker pull openexplorer/ai_toolchain_ubuntu_gpu:v1.13.5
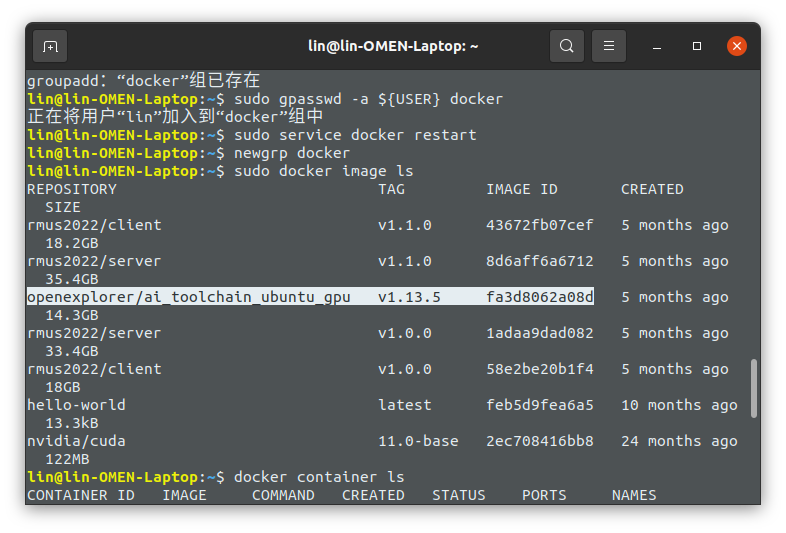
下载完毕之后查看docker镜像列表 sudo docker image ls
复制对应ID
将开发包中/ddk/samples文件映射到镜像的/data文件夹下,rename容器为horizon
命令需要修改自己对应的路径和 image ID
sudo docker run -it -d -v /home/lin/horizon_xj3_open_explorer_v1.10.7_20220304/ddk/samples:/data --name horizon --gpus all fa3d8062a08d
进入容器中
docker attach horizon
在容器中查询显卡驱动和cuda版本,查询不到的需要安装NVIDIA-docker以及检查显卡驱动
cuda version 为11.6也是没有问题的

如果电脑关机重启了,需要重新启动容器再进入容器
docker start horizon
退出容器通过ctrlP+ctrlQ
如果要重新建立容器,可以删除原有容器再重新建立
sudo docker stop horizon
sudo docker rm horizon
3. 模型检查
模型转换通过HB Mapper工具
其流程为 模型检查 → 模型转换 → 模型推理 → 精度验证
在模型检查这个过程中会检查待转换的模型中是否包含不支持的OP类型。
本文所转化的模型为 mediapipe 中人体姿态检测的 tflite 模型
MediaPipe是一个用于构建机器学习管道的框架,用于处理视频、音频等时间序列数据。
这个跨平台框架适用于桌面/服务器、Android、iOS和嵌入式设备,如Raspberry Pi和Jetson Nano。
但是在X3派上使用mediapipe只能在cpu上跑,因此我们还需将其中的人体姿态检测模型运行在bpu上。
pip install mediapipe
模型名称为 pose_landmark_lite.tflite,当然你也可以使用自己训练的模型然后进行模型检查,查询不支持的op再进行修改。
下载地址:mediapipe/mediapipe/modules/pose_landmark at master · google/mediapipe · GitHub
输入和输出均为 tensor
下面是在mediapipe中的部分图结构,模型输出后的tensor还需进一步处理变成我们所需要的人体33个关键点的坐标信息。
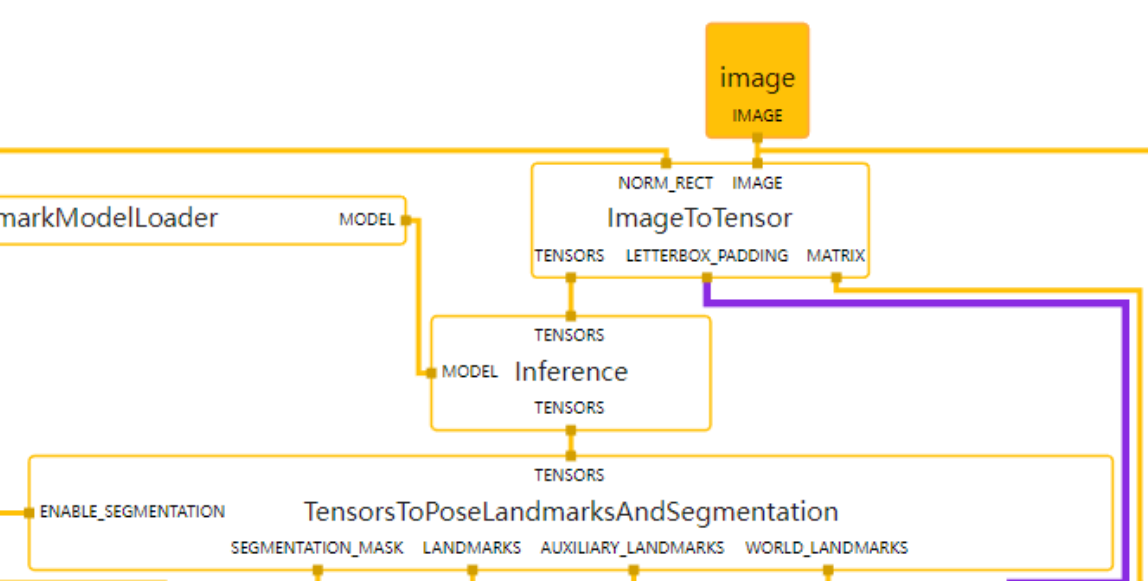
3.1 tflite模型转onnx模型
使用tf2onnx工具
获取地址:GitHub - onnx/tensorflow-onnx: Convert TensorFlow, Keras, Tensorflow.js and Tflite models to ONNX
用vscode打开,在终端下运行
这里必须手动设置opset版本,ai工具链支持的opset版本为10、11
python -m tf2onnx.convert --opset 10 --tflite pose_landmark_lite.tflite --output poseop10.onnx
3.2 模型检查
hb_mapper checker --model-type ${model_type} \
--march ${march} \
--proto ${proto} \
--model ${caffe_model/onnx_model} \
--input-shape ${input_node} ${input_shape} \
--output ${output}
hb_mapperchecker的命令行参数:
--model-type 转换的模型类型,目前支持 caffe 或者 onnx。
--march BPU的微架构。应将其设置为 bernoulli2。
--proto Caffe模型的prototxt文件。
--model Caffe或ONNX浮点模型文件。
--input-shape 可选参数,输入模型的输入节点以及该节点的输入的shape,其shape以 x 分隔, e.g. data 1x3x224x224。
--output 该参数已经废弃, log信息默认存储于 hb_mapper_checker.log 中。
--help 显示帮助信息并退出。
模型检查
注意文件路径,注意\后不能加空格
hb_mapper checker --model-type onnx \--march bernoulli2 \--model poseop10.onnx
报错1:opset版本过高报错
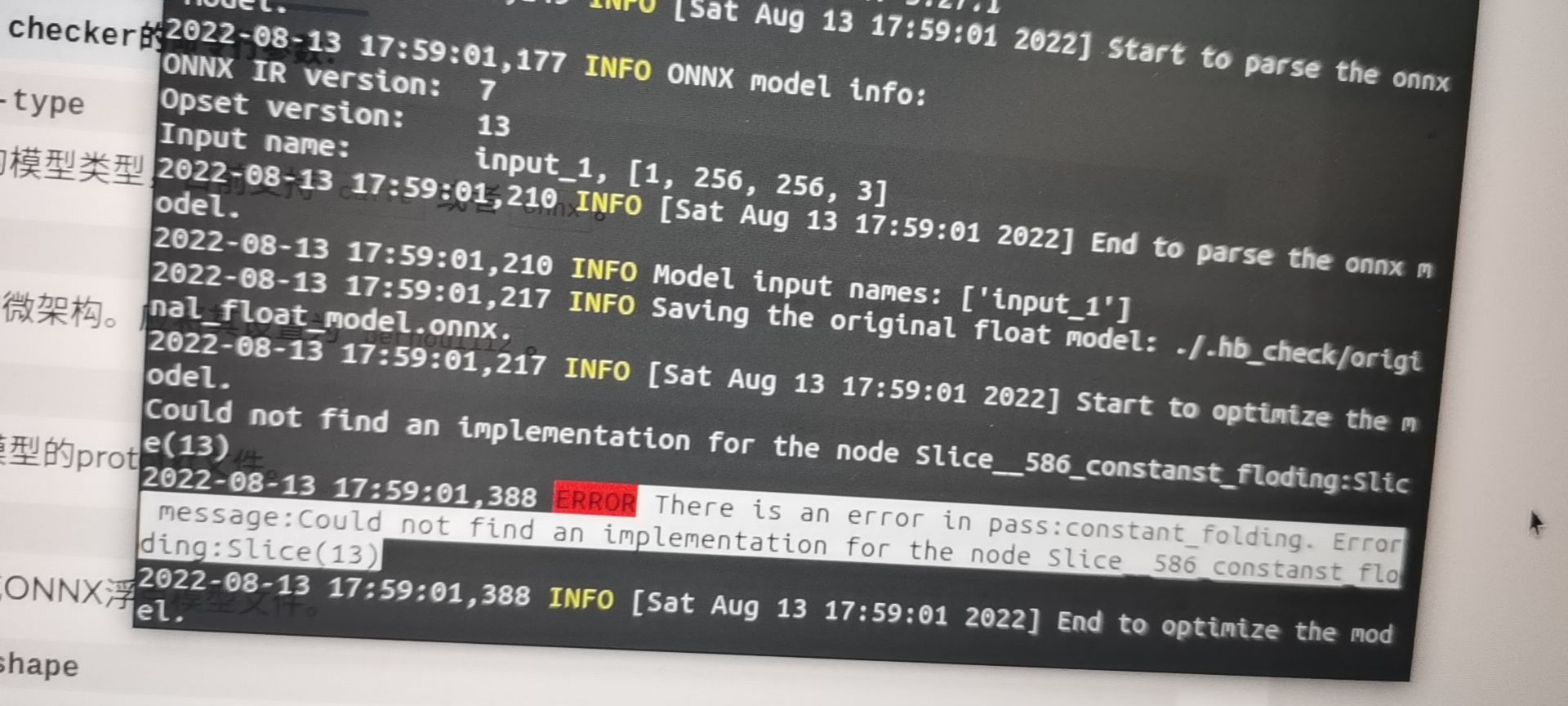
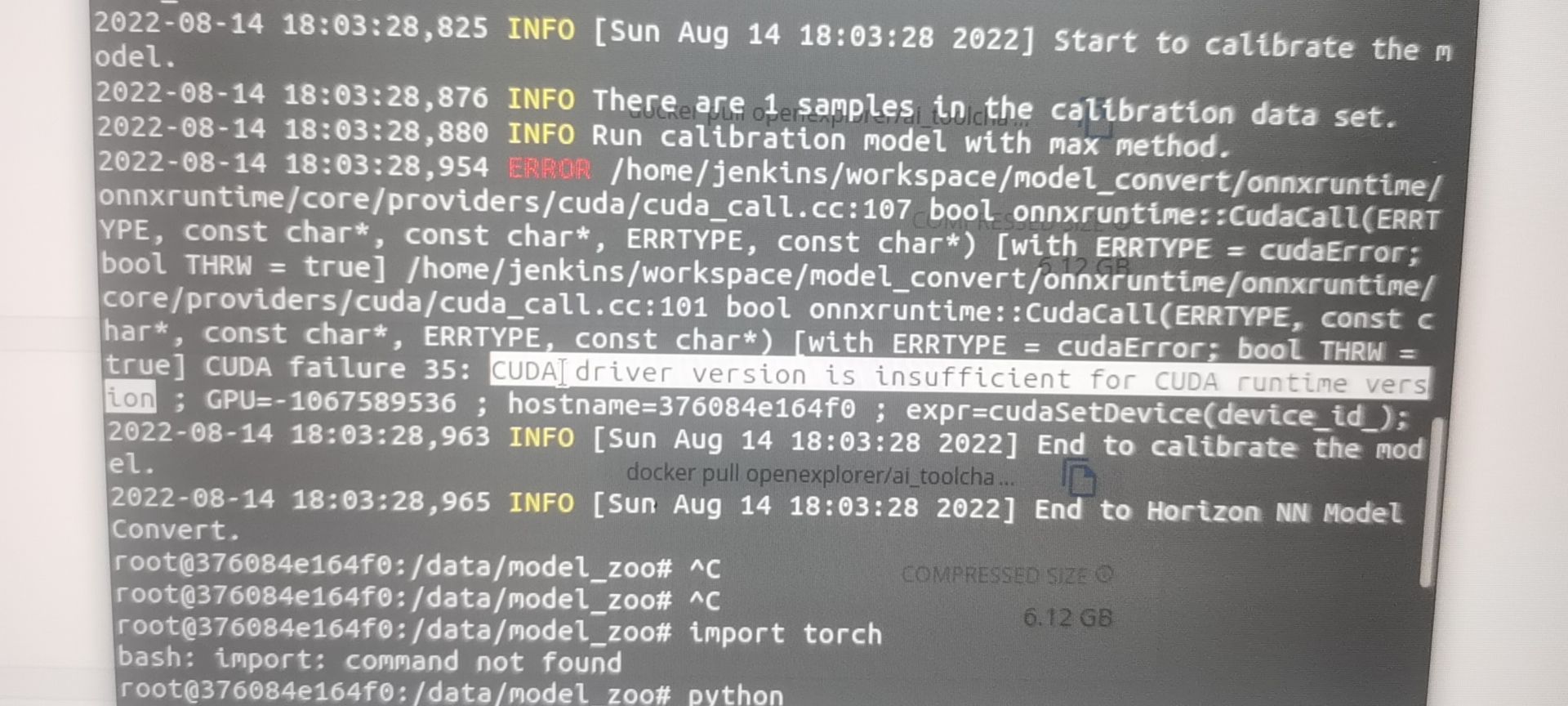
报错2:cuda版本错误
在docker容器内运行命令nvidia-smi没有输出
在docker容器内 torch.cuda.is_available() 输出为False
import torch
torch.__version
torch.cuda.is_available()
torch.cuda.device_count()
torch.version.cuda
在ubuntu中已安装显卡驱动,cuda版本为11,容器内pytorch所需要的cuda版本为10
原因:没有安装NVIDIA-docker,在docker容器内不能使用gpu
解决:安装NVIDIA-docker,并删除原horizon容器,重新建立可以使用gpu的容器
3.3 不支持的算子
解决报错后,重新使用hb_mapperchecker检查model
报错:ERROR Pad: only support h and w dimension padding


原因:BPU的Pad只支持H和W维度的转换
对op进行修改
参考:用mediepipe的模型(tflite)转onnx再转TRT使用 - 知乎 (zhihu.com)
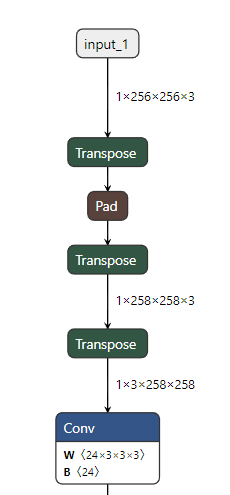
这是模型中报错的pad op
pad将input的shape 1*256*256*3转为1*258*258*3
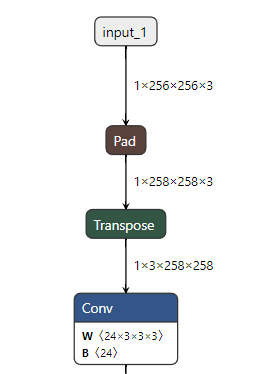
但是BPU的Pad [B,C,W,H] 只支持W和H维度
因此我们需要将的input_1的[1,256,256,3]变成[1,3,256,256]再进行pad
删除原Pad,加一层Transpose-Pad-Transpose就好了。
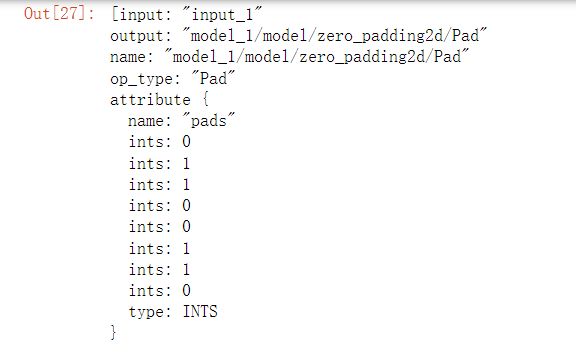
查询需要修改的pad
结合hb_mapperchecker的输出,以及pad前后shape的变化,可以找到需要修改的op
import onnx
#查询需要修改的pad
for i in range(len(node)):
if node[i].op_type == "Pad" or node[i].op_type == "MaxPool":
print(node[i],i)
我的模型中7个pad仅需修改第一个
删除报错的op
#删除需要修改的Pad
node.remove(node[0])#0
添加新的Transpose的op,将[1,256,256,3]变成[1,3,256,256]
shape转换用perm参数实现
node1=onnx.helper.make_node(
'Transpose',
name='to_pad',
inputs=["input_1"],
outputs=["to_pad"],
perm=[0,3,1,2]
)
node.insert(0,node1)
添加新的pad,将[1,3,256,256]变成[1,3,258,258]
#[1,3,256,256]->[1,3,258,258]
node2=onnx.helper.make_node(
'Pad',
name="to_train",
inputs=["to_pad"],
outputs=["to_train"],
perm=[0,1,1,0,0,1,1,0],
mode='constant'
)
node.insert(1,node2)
添加新的Transpose的op,将[1,3,258,258]变成[1,258,258,3]
node3=onnx.helper.make_node(
'Transpose',
name="model_1/model/zero_padding2d/Pad",
inputs=["to_train"],
outputs=["model_1/model/zero_padding2d/Pad"],
perm=[0,2,3,1]
)
node.insert(2,node3)
模型保存并检查
onnx.save(model,"Pose_op10_MODPad.onnx")
onnx.checker.check_model("Pose_op10_MODPad.onnx")
将优化过的onnx模型重新进行模型检查,无报错。