近年来,基于深度学习的方法在图像分类、目标检测、实例分割等任务上取得了巨大的成就,这样的成就得益于神经网络模型的深层次结构和庞大的模型参数量。但是,庞大的参数量意味着很难将模型部署到资源受限的边缘设备中,比如智能手机、智能穿戴设备、无人机、机器人、自动驾驶汽车等,这些设备通常对神经网络的执行过程有着严格的时间限制或者在长期执行时对功耗有着严苛的要求。因此,迫切需要优化模型的技术,以减少模型尺寸、实现更低的功耗和更快的推理速度。
量化将信号的连续取值(float32)近似为有限多个离散值(int8等),是减少神经网络模型计算时间和功耗最常用的手段。但是,神经网络量化后引入的量化/反量化节点,在进行逐点elementwise运算过程中需要消耗大量时间进行数据遍历,严重影响量化模型推理的性能。为了减少计算时间,在模型部署实践中通常将反量化并入模型的后处理环节进行计算,以减少数据重复遍历的时间消耗,称为反量化节点融合。
如下表为efficientdetd0模型反量化节点融合前后在Horzion XJ3开发板上的性能,显然,当把反量化节点融入到模型的后处理后,模型的性能具有以下变化:
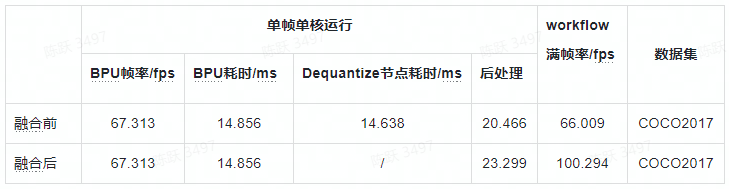
- 反量化节点融合进后处理的耗时远远小于融合前的Dequantize节点+后处理的耗时,减少一次数据遍历耗时的效果明显;
- 模型的workflow满帧率运行的FPS相对于反量化节点融合之前提升了惊人的34.18%。
所以,本文将以目标检测模型efficientdetd0为例,描述反量化节点融合的相关背景和基本过程。
1. 量化与反量化计算
模型量化(Quantize)就是建立一种浮点数据和定点数据间的映射关系,把featuremap或者常见的操作(卷积、激活、池化,均一化等)转化为等价的整数类型的操作,使得以较小的精度损失代价获得了较大的收益。反量化( Dequantize)则是指量化的逆运算,把整型数据转化为浮点型数据。
1.1 Quantize
Quantize节点用于将模型 float 类型的输入数据量化至 int类型,地平线量化工具采用对称量化方式,下面将对PTQ和QAT量化工具的公式和代码进行介绍。
1.1.1 PTQ量化
1. 量化公式
xint=clamp(round(xfloat/scale+zero_point),−2b−1,2b−1−1)x_{int}=clamp(round(x_{float}/scale+zero\_{point}),-2^{b-1},2^{b-1}-1)xint=clamp(round(xfloat/scale+zero_point),−2b−1,2b−1−1)
其中,round(x) 实现浮点数的四舍五入,clamp(x) 函数实现将数据钳位在[−2b−1,2b−1−1][-2^{b-1},2^{b-1}-1][−2b−1,2b−1−1]之间的整数数值。zero_point为非对称量化零点偏移值,对称量化时 zero_point = 0 。scale称为比例因子或量化系数,决定了量化后的分区数量(共2b−12^b-12b−1个分区),通常表示为浮点数。
2. 量化代码
int8量化python代码:
import numpy as np
#scale为量化比例因子,获取方式见2.2节
x= input_float/scale
x=np.clip(np.round(x),-128,127)
x = x.astype(np.int8)
int16量化python代码:
import numpy as np
#scale为量化比例因子,获取方式见2.2节
x= input_float/scale
x=np.clip(np.round(x),-32768,32767)
x = x.astype(np.int16)
int8量化C++代码:
static inline float32_t _round(float32_t const input) {
std::fesetround(FE_TONEAREST);
float32_t const result{std::nearbyintf(input)};
return result;
}
static inline int8_t int_quantize(float32_t value, float32_t const scale) {
value = _round(value / scale);
value = std::min(std::max(value, -128.0f), 127.0f);
return static_cast<int8_t>(value);
}
int16量化C++代码:
static inline float32_t _round(float32_t const input) {
std::fesetround(FE_TONEAREST);
float32_t const result{std::nearbyintf(input)};
return result;
}
static inline int16_t int_quantize(float32_t value, float32_t const scale) {
value = _round(value / scale);
value = std::min(std::max(value, -32768.0f), 32767.0f);
return static_cast<int16_t>(value);
}
1.1.2 QAT量化
1. 量化公式
xint=clamp(floor(xfloat/scale+0.5,−2b−1,2b−1−1)x_{int}=clamp(floor(x_{float}/scale+0.5,-2^{b-1},2^{b-1}-1)xint=clamp(floor(xfloat/scale+0.5,−2b−1,2b−1−1)
其中,floor(x+0.5) 实现浮点数的四舍五入, clamp(x) 函数实现将数据钳位在-
[−2b−1,2b−1−1][-2^{b-1},2^{b-1}-1][−2b−1,2b−1−1]之间的整数数值。scale称为比例因子或量化系数,决定了量化后的分区数量(共2b−12^b-12b−1个分区),通常表示为浮点数。-
2. 量化代码
int8量化python代码:
import numpy as np
#scale为量化比例因子,获取方式见2.2节
x= input_float/scale
x=np.clip(np.floor(x+0.5),-128,127)
x = x.astype(np.int8)
int16量化python代码:
import numpy as np
#scale为量化比例因子,获取方式见2.2节
x= input_float/scale
x=np.clip(np.floor(x+0.5),-32768,32767)
x = x.astype(np.int16)
int8量化C++实现代码:
float features_tmp = std::floor(static_cast<float>(x_float/scale)+0.5);
features_tmp = std::min(std::max(features_tmp, -128.f), 127.f);
features_tmp= static_cast<int8_t>(features_tmp);
int16量化C++实现代码:
float features_tmp = std::floor(static_cast<float>(x_float/scale)+0.5);
features_tmp = std::min(std::max(features_tmp, -32768.f), 32767.f);
features_tmp = static_cast<int16_t>(features_tmp);
1.2 Dequantize
Dequantize节点则用于将模型中整型的输出数据反量化回 float 类型,其计算公式如下:
deqx=(x−zero_point)∗scaledeqx = (x - zero\_point) * scaledeqx=(x−zero_point)∗scale
如下为Dequantize节点的C++的实现代码:
static_cast<float>(value) * scale
这里的zero_point和 scale与Quantize节点中的意义相同。
2. 反量化节点融合基本过程
通常情况下,对于 BPU/CPU 混合异构模型,单帧串行下的耗时包括以下几个方面:
输入量化CPU节点+模型BPU算子+输出反量化CPU节点+CPU后处理
- 输入量化CPU节点:float32->int8,只有 featuremap 输入模型包含,图像输入模型不包含此类节点;
- 输出反量化CPU节点:int8->float32;
另外,根据神经网络量化计算的背景知识可知:
- 模型部署阶段神经网络量化/反量化操作的本质是对输入张量的逐点elementwise乘加运算,即神经网络中的权值与量化参数scale和zero point进行的运算;
- 乘加操作和数据传输消耗了神经网络推理期间消耗的大量能量;
- 乘加运算需要遍历张量的每个元素,相对于乘加运算,遍历元素消耗的时间更多。
对于存在前后处理的网络模型,其必须要进行遍历数据的操作,那么就可以在模型量化过程中手动移除模型首尾部的Quantize和Dequantize节点,然后将Quantize和Dequantize操作融入模型前后处理的代码中实现,以减少数据重复遍历的损耗。
2.1 反量化节点删除
地平线AI工具链提供的移除模型尾部的Dequantize节点的方法主要有以下两种:
1. 配置yaml文件
使用hb_mapper makertbin 工具进行转换模型前,需要对yaml文件中的参数进行配置,在yaml文件的模型参数组可以设置删除节点的类型:
remove_node_type: "Quantize;Dequantize"
如此便可以删除模型输入输出端的Quantize和Dequantize节点。这里需要提及的是,yaml参数设置后只会删除模型开头或者末尾的节点。
2. hb_model_modifier工具
模型编译完成后,可以使用hb_model_modifier工具对指定的runtime模型中输入输出端的节点进行删除操作,并将删除节点的信息存放在BIN模型中。删除编译生成的.bin模型尾部的Dequantize节点,具体操作如下:
## 批量删除模型尾部所有反量化节点
hb_model_modifier model.bin -a Dequantize
# 删除指定节点node1
hb_model_modifier model.bin -r node1
2.2 scale值查看
量化比例因子scale是进行反量化计算的必要因素,删除Dequantize节点后,仍然需要获取删除节点的scale值以进行后续的反量化融合操作。可以使用以下方式来查看scale值:
1.方式1
在开发机端,使用上述任何一种方法移除Dequantize节点后,都会生成hb_model_modifier.log文件,其中包含被移除的Dequantize节点的名称和scale值。如下图所示:
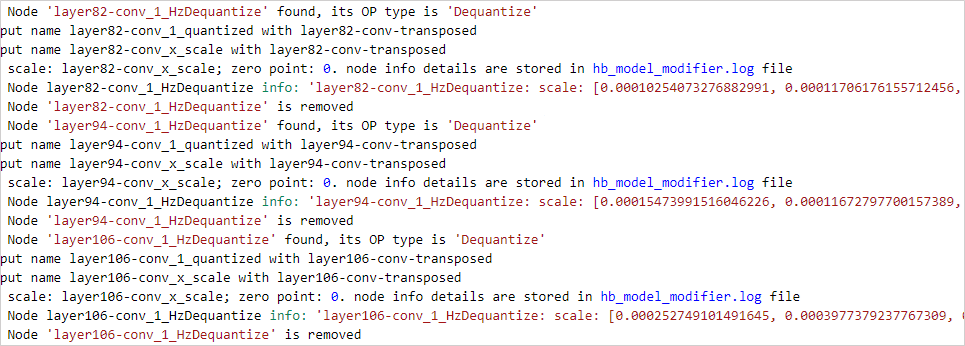
2. 方式2
还可以在开发机端运行 hb_model_info 工具查看被删除节点信息,输出信息末尾会打印被删除节点的名称,同时会生成 deleted_nodes_info.txt 文件, 文件中每一行记录了对应被删除节点的初始信息,比如被删除Dequantize节点的名称、scale值等。-
开发机端运行hb_model_info 工具:
hb_model_info model.bin
生成的deleted_nodes_info.txt文件包含的信息如下所示:

3.方式3
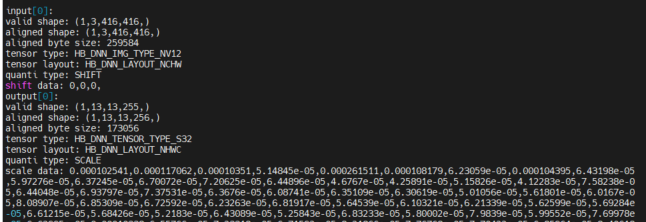
另外,还可以在板端运行hrt_model_exec工具获取被删除节点信息,终端会打印出被删除节点scale信息。-
板端运行hrt_model_exec 工具:
hrt_model_exec model_info --model_file model.bin
终端输出被删除节点的信息如下所示:-
4. 方式4
除此之外,runtime中也提供了可以获取scale值的BPU SDK API hbDNNTensor和hbDNNTensorProperties。首先使用APIhbDNNTensor定义用于存放模型输入输出信息的张量Tensor,然后使用hbDNNTensorProperties的成员scale来获取模型的输出端的Dequantize节点的scale信息,具体使用方法请看2.3节示例。-
如下为这两个API的定义和成员介绍:
//hbDNNTensor
typedef struct {
hbSysMem sysMem[4];
hbDNNTensorProperties properties;
} hbDNNTensor;
成员名称
描述
sysMem
存放张量的内存
properties
张量的信息
//hbDNNTensorProperties
typedef struct {
hbDNNTensorShape validShape;
hbDNNTensorShape alignedShape;
int32_t tensorLayout;
int32_t tensorType;
hbDNNQuantiShift shift;
hbDNNQuantiScale scale;
hbDNNQuantiType quantiType;
int32_t alignedByteSize;
} hbDNNTensorProperties;
成员名称
描述
validShape
张量有效内容的形状
alignedShape
张量对齐内容的形状
tensorLayout
张量的排布形式
tensorType
定点转浮点的偏移量
shift
定点转浮点的偏移量
scale
定点转浮点的缩放量
quantiType
定点转浮点的量化类型
alignedByteSize
张量对齐内容的内存大小
2.3 反量化节点融合示例
地平线在Open Explorer开发包horizon_xj3_open_explorer_v1.14.3_20220727/ddk/samples/ai_benchmark目录下提供了多个反量化节点融合的示例,本文以目标检测模型efficientdetd0为例描述反量化节点融合的过程:
- 移除Dequantize节点。可以通过2.1节的两种方法移除模型尾部的Dequantize节点。
- 获取量化比例因子scale的值。模型的Dequantize节点删除后,删除节点的信息会存放在BIN模型中,可以使用
tensor.properties.scale.scaleData来获取scale值 。 - 将获取的scale值融入到模型的后处理环节进行反量化计算,从而避免一次数据遍历的冗余操作。
runtime中反量化节点的C++实现代码如下:
static_cast<float>(value) * scale
在efficientdetd0示例的后处理代码/ddk/samples/ai_benchmark/code/src/method/ptq_efficientdet_post_process_method.cc中,使用BPU SDK API hbDNNTensor来存放模型输出的分类头信息c_tensor和检测头信息bbox_tensor:
hbDNNTensor *c_tensor,
hbDNNTensor *bbox_tensor,
然后使用指针从c_tensor和bbox_tensor获取量化比例因子scale的值cls_scale_data和box_scale_data:
float *cls_scale_data = c_tensor->properties.scale.scaleData;
float *box_scale_data = bbox_tensor->properties.scale.scaleData;
最后,按照上述公式进行反量化计算,然后再进行其他后处理操作。如下为efficientdetd0示例进行反量化计算的部分C++代码:
auto *raw_cls_data =
reinterpret_cast<int32_t *>(c_tensor->sysMem[0].virAddr);
auto *raw_box_data =
reinterpret_cast<int32_t *>(bbox_tensor->sysMem[0].virAddr);
for (int i = 0; i < box_num; i++) {
// score and cls
uint32_t res_id_cur_anchor = i * class_num;
int cls_scale_index = res_id_cur_anchor % 720;
// 获取分类头反量化节点的scale值
float *cls_scale_data = c_tensor->properties.scale.scaleData;
auto cls_scales = cls_scale_data + cls_scale_index;
// 获取max_id and max_score;
auto max_score_id =
MaxScoreID(raw_cls_data + res_id_cur_anchor, cls_scales, class_num);
float max_score = max_score_id.first;
int max_id = max_score_id.second;
// box
if (max_score <= score_threshold_) continue;
// stride is 40, if do not have dequanti node
int start = i * 4 + (4 * i) / 36 * 4;
int scale_index = (i * 4) % 36;
//获取检测头bbox反量化节点的scale值
float *box_scale_data = bbox_tensor->properties.scale.scaleData;
auto box_scales = box_scale_data + scale_index;
//反量化计算
float dx = raw_box_data[start] * box_scales[0];
float dy = raw_box_data[start + 1] * box_scales[1];
float dw = raw_box_data[start + 2] * box_scales[2];
float dh = raw_box_data[start + 3] * box_scales[3];
float width = anchors[i].w_;
float height = anchors[i].h_;
float ctr_x = anchors[i].c_x_;
float ctr_y = anchors[i].c_y_;
float pred_ctr_x = dx * width + ctr_x;
float pred_ctr_y = dy * height + ctr_y;
float pred_w = std::exp(dw) * width;
float pred_h = std::exp(dh) * height;
// python在这里需要对框做clip, x >= 0 && x <= input_width...
float xmin = (pred_ctr_x - 0.5f * (pred_w - 1.f));
float ymin = (pred_ctr_y - 0.5f * (pred_h - 1.f));
float xmax = (pred_ctr_x + 0.5f * (pred_w - 1.f));
float ymax = (pred_ctr_y + 0.5f * (pred_h - 1.f));
Bbox bbox;
bbox.xmin = std::max(xmin, 0.f);
bbox.ymin = std::max(ymin, 0.f);
bbox.xmax = std::min(xmax, img_w);
bbox.ymax = std::min(ymax, img_h);
dets.push_back(
Detection(max_id,
max_score,
bbox,
efficient_det_config_.class_names[max_id].c_str()));
}
}
return 0;
}
3.参考文献
- Nagel M, Fournarakis M, Amjad R A, et al. A white paper on neural network quantization[J]. arXiv preprint arXiv:2106.08295, 2021.
- Gholami A, Kim S, Dong Z, et al. A survey of quantization methods for efficient neural network inference[J]. arXiv preprint arXiv:2103.13630, 2021.
- https://pytorch.org/blog/introduction-to-quantization-on-pytorch/
- https://www.tensorflow.org/api_docs/python/tf/quantization