注:新版本教程已刷新,请查看《Batch模型推理》。
前言
在 J5 芯片上我们更建议使用大尺寸模型来发挥芯片算力优势,对于小模型(边长 <= 256),推荐使用 batch 模式进行推理,因为在batch模式下,模型的参数在每个 batchsize 内(或编译时分析得到的 batchsize 上限)只会 load 一次,从而可以更有效地平衡计算/访存比,降低算力浪费,让模型的运行更加高效。
本文将分享如何编译并正确部署多batch模型。以batch=4的googlenet分类模型为示例,介绍从编译C++源码到J5板端执行模型推理的完整过程,并对C++的代码编写进行简要说明。多batch模型的使用与部署是J5的OpenExplorer v1.1.19新增示例,下表展示了此教程使用的OE包版本及所用模型的基本信息,建议用户使用最新的OE包版本。
OE版本
J5 v1.1.19
模型文件
googlenet_4x224x224_nv12.bin
batch
4
输入尺寸(CHW)
3x224x224
多batch模型的使用与部署示例在OE包的ddk/samples/ai_toolchain/horizon_runtime_sample目录中。-
C++源码nv12_batch.cc位于该目录的code/02_advanced_samples/nv12_batch/src文件夹内,使用build_j5.sh脚本即可在Linux环境下编译生成板端可执行文件。-
J5板端的执行脚本run_nv12_batch.sh位于j5/script/02_advanced_samples文件夹内,该脚本需要复制到板端执行。-
googlenet_4x224x224_nv12.bin是已经经过了量化编译的混合异构模型,文件所在路径为j5/model/runtime/googlenet文件夹。如果希望使用自己编译的多batch模型,只需修改板端的执行脚本即可。
1 准备模型
首先介绍如何编译生成多batch模型。OE包的ddk/samples/ai_toolchain/horizon_model_convert_sample目录包含了大量分类、分割、检测等不同模型的编译示例,可以将onnx或caffe形式的原始浮点模型转换成板端可运行的混合异构bin模型。在yaml配置文件中,输入信息参数组(input_parameters)的参数input_batch默认被“#”注释,此时编译会生成batch=1的模型。在编译多batch模型时,需要删除注释符号,并将参数的值从1改成期望的batch数。同时为了保证转换精度,校准数据的数量需要设置为当前batch的整数倍。之后执行编译脚本,即可生成多batch模型。-
详细的模型编译流程可参考 工具链用户手册 。后文会使用示例中提供的googlenet_4x224x224_nv12.bin模型进行介绍。
2 编译源码
nv12_batch.cc为调用多batch模型执行分类任务的C++源码,其包括了数据预处理,前向推理,数据后处理、计算资源分配与释放等部分。编写该代码需要较为熟悉地平线AI工具链Runtime部分的C++接口,使用方法可以参考 BPU SDK API手册。
在完成C++源码及对应CMakelists.txt文件的编写后,运行build_j5.sh脚本即可将c++源码编译成应用于J5开发板的可执行程序run_nv12_batch,可执行程序及对应依赖会生成在j5/script/aarch64文件夹中。
build_j5.sh脚本里指定的交叉编译工具路径默认是 /opt 目录,如果安装在了其他位置,可以手动修改build_j5.sh脚本的交叉编译工具路径。
3 传输上板
在C++源码编译完成后,将以下文件和文件夹复制到J5开发板上:
j5/script/02_advanced_samples目录下的run_nv12_batch.sh脚本文件j5/script目录下的aarch64文件夹- 多batch混合异构模型googlenet_4x224x224_nv12.bin文件
- 存放待推理图片的文件夹A
可以建立如下所示文件目录:-
batch_model-
├── 02_advanced_samples-
│ └──run_nv12_batch.sh-
├── model-
│ └──googlenet_4x224x224_nv12.bin-
├── aarch64-
│ ├── bin-
│ └── lib-
├── pic-
│ ├── zebra_cls.jpg-
│ └── cat_cls.jpg
修改run_nv12_batch.sh脚本文件,将其中的bin、lib、model_file、image_file重新指向J5开发板上设置的路径。其中,image_file需要指向多张图片,图片数量和batch大小需相同。此外,对于分类模型,可以自定义top_k的大小。run_nv12_batch.sh脚本文件的内容可以修改成如下所示。
#!/usr/bin/env sh
bin=../aarch64/bin/run_nv12_batch
lib=../aarch64/lib
chmod 777 ../aarch64/bin/run_nv12_batch
export LD_LIBRARY_PATH=${lib}:${LD_LIBRARY_PATH}
export BMEM_CACHEABLE=true
${bin} \
--model_file=../model/googlenet_4x224x224_nv12.bin \
--image_file=../pic/zebra_cls.jpg,../pic/cat_cls.jpg,../pic/zebra_cls.jpg,../pic/cat_cls.jpg \
--top_k=5
4 板端推理
在run_nv12_batch.sh脚本文件所在目录运行sh run_nv12_batch.sh命令,即可得到如下所示的模型推理结果。
../aarch64/bin/run_nv12_batch --
model_file=../model/googlenet_4x224x224_nv12.bin --
image_file=../pic/zebra_cls.jpg,../pic/cat_cls.jpg,../pic/zebra_cls.jpg,../pic/cat_cls.jpg --top_k=5
I0000 00:00:00.000000 3992 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[BPU_PLAT]BPU Platform Version(1.3.2)!
[HBRT] set log level as 0. version = 3.14.14
[DNN] Runtime version = 1.10.3_(3.14.14 HBRT)
I0902 15:12:39.408330 3992 nv12_batch.cc:151] Infer1 start
I0902 15:12:39.467193 3992 nv12_batch.cc:166] read image to tensor as nv12 success
I0902 15:12:39.470314 3992 nv12_batch.cc:204] Batch[0]:
I0902 15:12:39.470363 3992 nv12_batch.cc:206] TOP 0 result id: 340
I0902 15:12:39.470388 3992 nv12_batch.cc:206] TOP 1 result id: 83
I0902 15:12:39.470412 3992 nv12_batch.cc:206] TOP 2 result id: 41
I0902 15:12:39.470434 3992 nv12_batch.cc:206] TOP 3 result id: 912
I0902 15:12:39.470458 3992 nv12_batch.cc:206] TOP 4 result id: 292
I0902 15:12:39.470480 3992 nv12_batch.cc:204] Batch[1]:
I0902 15:12:39.470502 3992 nv12_batch.cc:206] TOP 0 result id: 282
I0902 15:12:39.470525 3992 nv12_batch.cc:206] TOP 1 result id: 281
I0902 15:12:39.470547 3992 nv12_batch.cc:206] TOP 2 result id: 285
I0902 15:12:39.470594 3992 nv12_batch.cc:206] TOP 3 result id: 287
I0902 15:12:39.470618 3992 nv12_batch.cc:206] TOP 4 result id: 283
I0902 15:12:39.470641 3992 nv12_batch.cc:204] Batch[2]:
I0902 15:12:39.470664 3992 nv12_batch.cc:206] TOP 0 result id: 340
I0902 15:12:39.470686 3992 nv12_batch.cc:206] TOP 1 result id: 83
I0902 15:12:39.470710 3992 nv12_batch.cc:206] TOP 2 result id: 41
I0902 15:12:39.470731 3992 nv12_batch.cc:206] TOP 3 result id: 912
I0902 15:12:39.470753 3992 nv12_batch.cc:206] TOP 4 result id: 292
I0902 15:12:39.470777 3992 nv12_batch.cc:204] Batch[3]:
I0902 15:12:39.470798 3992 nv12_batch.cc:206] TOP 0 result id: 282
I0902 15:12:39.470820 3992 nv12_batch.cc:206] TOP 1 result id: 281
I0902 15:12:39.470844 3992 nv12_batch.cc:206] TOP 2 result id: 285
I0902 15:12:39.470865 3992 nv12_batch.cc:206] TOP 3 result id: 287
I0902 15:12:39.470887 3992 nv12_batch.cc:206] TOP 4 result id: 283
I0902 15:12:39.471376 3992 nv12_batch.cc:228] Infer1 end
I0902 15:12:39.471416 3992 nv12_batch.cc:233] Infer2 start
I0902 15:12:39.528785 3992 nv12_batch.cc:246] read image to tensor as nv12 success
I0902 15:12:39.531352 3992 nv12_batch.cc:284] Batch[0]:
I0902 15:12:39.531391 3992 nv12_batch.cc:286] TOP 0 result id: 340
I0902 15:12:39.531417 3992 nv12_batch.cc:286] TOP 1 result id: 83
I0902 15:12:39.531440 3992 nv12_batch.cc:286] TOP 2 result id: 41
I0902 15:12:39.531463 3992 nv12_batch.cc:286] TOP 3 result id: 912
I0902 15:12:39.531486 3992 nv12_batch.cc:286] TOP 4 result id: 292
I0902 15:12:39.531508 3992 nv12_batch.cc:284] Batch[1]:
I0902 15:12:39.531531 3992 nv12_batch.cc:286] TOP 0 result id: 282
I0902 15:12:39.531554 3992 nv12_batch.cc:286] TOP 1 result id: 281
I0902 15:12:39.531577 3992 nv12_batch.cc:286] TOP 2 result id: 285
I0902 15:12:39.531599 3992 nv12_batch.cc:286] TOP 3 result id: 287
I0902 15:12:39.531621 3992 nv12_batch.cc:286] TOP 4 result id: 283
I0902 15:12:39.531667 3992 nv12_batch.cc:284] Batch[2]:
I0902 15:12:39.531690 3992 nv12_batch.cc:286] TOP 0 result id: 340
I0902 15:12:39.531714 3992 nv12_batch.cc:286] TOP 1 result id: 83
I0902 15:12:39.531736 3992 nv12_batch.cc:286] TOP 2 result id: 41
I0902 15:12:39.531759 3992 nv12_batch.cc:286] TOP 3 result id: 912
I0902 15:12:39.531781 3992 nv12_batch.cc:286] TOP 4 result id: 292
I0902 15:12:39.531803 3992 nv12_batch.cc:284] Batch[3]:
I0902 15:12:39.531826 3992 nv12_batch.cc:286] TOP 0 result id: 282
I0902 15:12:39.531847 3992 nv12_batch.cc:286] TOP 1 result id: 281
I0902 15:12:39.531870 3992 nv12_batch.cc:286] TOP 2 result id: 285
I0902 15:12:39.531893 3992 nv12_batch.cc:286] TOP 3 result id: 287
I0902 15:12:39.531914 3992 nv12_batch.cc:286] TOP 4 result id: 283
I0902 15:12:39.532202 3992 nv12_batch.cc:308] Infer2 end
googlenet_4x224x224_nv12.bin模型共进行了两遍推理,分别为Infer1和Infer2,两次推理的主要差异在于数据准备方式的不同,在模型推理时没有区别。Infer1单独设置多batch数据内每个单batch张量的地址,分别申请内存空间。Infer2只申请一个完整的内存空间,包含多batch数据的所有内容。根据推理后的输出信息,可以看出Infer1和Infer2的推理结果是完全相同的。
示例C++源码解析
示例的C++源码nv12_batch.cc展示了使用batch=4的googlenet分类模型对4张图片执行两次推理的完整过程,包扩计算资源分配回收,数据预处理,前向推理,分类结果后处理等步骤,该部分教程旨在指导用户C++源码的编写。
主函数
源码中,主函数的完整执行流程为:
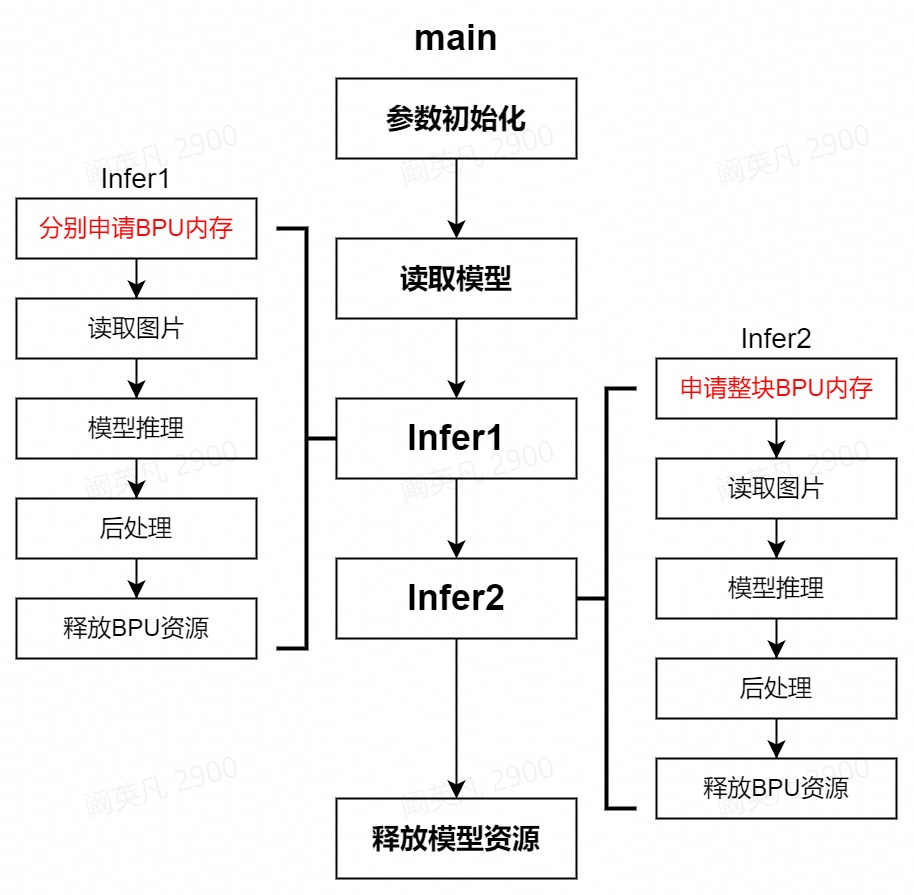
下文介绍C++源码中调用的各种主要函数的功能,并贴出部分重要代码。
HB_CHECK_SUCCESS
用于检查函数是否执行出错。调用的时候,value处填写的是其他函数,若其他函数正确执行(如成功读取模型,成功申请内存等),则返回值为0,即value值等于0,该函数执行结束。若其他函数执行错误,则该函数会输出errmsg处填写的报错信息。
#define HB_CHECK_SUCCESS(value, errmsg) \
do { \
/*value can be call of function*/ \
auto ret_code = value; \
if (ret_code != 0) { \
VLOG(EXAMPLE_SYSTEM) << errmsg << ", error code:" << ret_code; \
return ret_code; \
} \
} while (0);
prepare_tensor_batch_separate/combine
依据模型信息,设定好输入张量和输出张量的大小,并为其申请BPU内存。
prepare_tensor_batch_separate函数用于循环和batch相同的次数为batch内的每张图片分别申请BPU内存。
//prepare_tensor_batch_separate
int32_t batch = input.properties.alignedShape.dimensionSize[0];
int32_t batch_size = input.properties.alignedByteSize / batch;
input.properties.alignedByteSize = batch_size;
input.properties.validShape.dimensionSize[0] = 1;
input.properties.alignedShape = input.properties.validShape;
for (int j{0}; j < batch; j++) {
HB_CHECK_SUCCESS(hbSysAllocCachedMem(&input.sysMem[0], batch_size),
"hbSysAllocCachedMem failed");
input_tensor.push_back(input);
}
prepare_tensor_batch_combine函数用于一次为整个batch的所有图片申请连续的BPU内存。
//prepare_tensor_batch_combine
HB_CHECK_SUCCESS(
hbSysAllocCachedMem(&input.sysMem[0], input.properties.alignedByteSize),
"hbSysAllocCachedMem failed");
input.properties.alignedShape = input.properties.validShape;
input_tensor.push_back(input);
read_image_2_tensor_as_nv12_batch_separate/combine
函数会先依据模型信息确定好输入张量的长宽信息,之后先以bgr形式读取图片,转为nv12格式后,以内存拷贝的方式将图片信息存储在BPU内存的相应位置。
read_image_2_tensor_as_nv12_batch_separate函数使用循环的方式,重复batch次数依次读取该batch内每个张量的长宽信息。
//read_image_2_tensor_as_nv12_batch_separate
for (int32_t i{0}; i < input_tensor.size(); i++) {
hbDNNTensor &input = input_tensor[i];
hbDNNTensorProperties &Properties = input.properties;
int input_h = Properties.validShape.dimensionSize[1];
int input_w = Properties.validShape.dimensionSize[2];
if (Properties.tensorLayout == HB_DNN_LAYOUT_NCHW) {
input_h = Properties.validShape.dimensionSize[2];
input_w = Properties.validShape.dimensionSize[3];
}
...
read_image_2_tensor_as_nv12_batch_combine函数能一次获取整个batch所有输入张量的长宽信息。
//read_image_2_tensor_as_nv12_batch_combine
hbDNNTensor &input = input_tensor[0];
hbDNNTensorProperties &Properties = input.properties;
int batch = Properties.alignedShape.dimensionSize[0];
int input_h = Properties.validShape.dimensionSize[1];
int input_w = Properties.validShape.dimensionSize[2];
if (Properties.tensorLayout == HB_DNN_LAYOUT_NCHW) {
input_h = Properties.validShape.dimensionSize[2];
input_w = Properties.validShape.dimensionSize[3];
}
get_topk_result
推理结果后处理,以队列的方式存储top5分类结果,会根据模型是否量化及量化方式的不同(SHIFT/SCALE)选择对应的计算方式。
总结
示例的C++源码执行了同一个多batch模型的两次推理流程。在需要为每张输入图片单独分配BPU内存的场合,可以参考Infer1阶段的代码,重点关注prepare_tensor_batch_separate和read_image_2_tensor_as_nv12_batch_separate函数。相应地,如果需要为batch数量的图片申请整块BPU内存,可以参考Infer2阶段的代码,重点关注prepare_tensor_batch_combine和read_image_2_tensor_as_nv12_batch_combine函数。
考虑到vio场景下的需求,源码以nv12输入为例进行了代码编写的示范,由于vio送入的数据可能是多个地址,因此在Infer1中使用了针对batch内不同图片分别分配内存的代码编写方法。当使用ddr方式读取图片时,多batch模型支持bgr/rgb/featuremap等数据的推理,用户可以按照Infer2的方式为整个batch的多张图像一次性分配连续的BPU内存。