0 概述-
在自动驾驶感知算法中BEV感知成为热点话题,BEV感知可以弥补2D感知的缺陷构建3D“世界”,更有利于下游任务和特征融合。为响应市场需求,地平线集成了基于bev的纯视觉算法,目前已支持ipm-based 、lss-based、 transformer-based(Geometry-guided Kernel Transformer、detr3d) 的多种bev视觉转换方法。本文为transformer-based的BEV多任务感知算法介绍和使用说明。-
该示例为参考算法,仅作为在J5上模型部署的设计参考,非量产算法
1 性能精度指标-
模型配置:-
数据集
img_shape
Stage 1
grid_size
Stage 2
Nuscenes
512x960
Backbone
Neck
输出shape
64x64
Backbone
输出shape
mixvargenet
BiFPN
[6,160,32,60]
VargBev
[1,64,128,128]
性能精度表现:
性能(FPS/单核)
分割精度(浮点/定点)
检测精度(浮点/定点)
divider
ped_crossing
Boundary
Others
NDS
mAP
42
40.60/41.25
25.79/25.90
43.47/42.53
84.22/82.47
0.2811/0.2809
0.1991/0.1983
注:-
stage1为image encoder;stage2为bev encoder;-
Nuscenes 数据集官方介绍:Nuscenes
2 模型介绍
2.1 模型框架
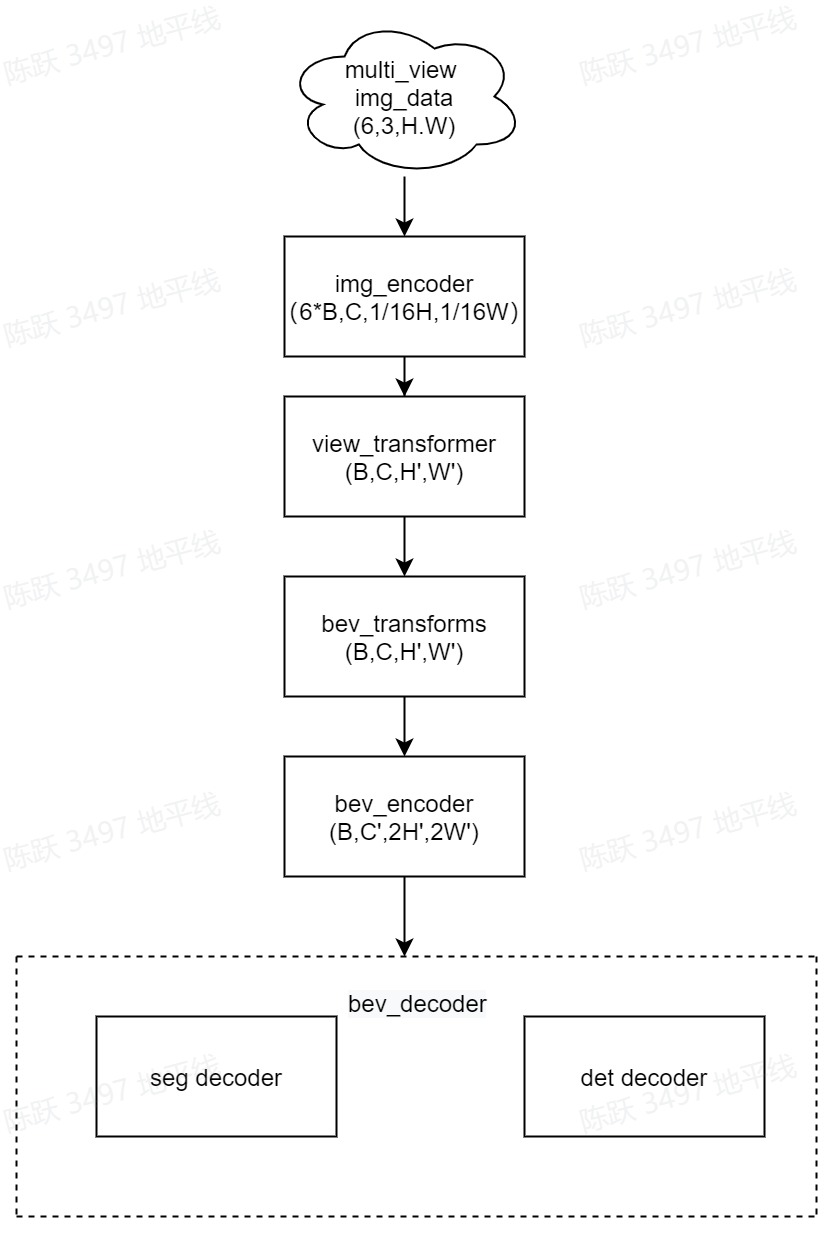
bev_gkt 模型结构图
bev_gkt 使用多视图的当前帧的6个RGB图像作为输入,输出是目标的3D Box和BEV分割结果。多视角图像首先使用2D主干获取2D特征。然后投影到3D BEV视角。接着对BEV feature 编码获取BEV特征。最后,接上任务特定的head,输出多任务结果。gkt的贡献在于使用相机参数作为指导而不过多依赖,对相机偏移产生的影响不敏感,提高模型的鲁棒性。
模型主要包括以下部分:-
**Part1—2D Image Encoder:**图像特征提取层。使用地平线自研的主干网络(mixvargenet)和BiFPN输出不同分辨率的特征图。返回最后一层–下采样至1/16原图大小层,用于下一步投影至3D 坐标系中。-
**Part2—View transformer:**采用gkt transformer映射完成image视角到bev视角的转换。-
**Part3—Bev transforms:**对bev特征做数据增强,仅发生在训练阶段。-
**Part4—3D BEV Encoder:**BEV特征提取层。-
**Part5—BEV Decoder:**分为Detection Head和Segmentation Head。得到统一的BEV特征后,使用FCNHead进行bev分割,分割种类为[“others”, “divider”, “ped_crossing”, “Boundary”]。使用VargCenterPointHead进行3D目标检测任务,检测的类别为[“car”,“truck”,“bus”,“barrier”,“bicycle”,“pedestrian”]。
2.2 源码说明
config文件
configs/bev/bev_gkt_mixvargenet_multitask_nuscenes.py 为该模型的配置文件,定义了模型结构、数据集加载,和整套训练流程,所需参数的说明在算子定义中会给出。配置文件主要内容包括:
#基础参数配置
task_name = "bev_gkt_mixvargenet_multitask_nuscenes"
batch_size_per_gpu = 2
device_ids = [0]
#bev参数配置
data_shape = (3, 512, 960)
bev_size = (51.2, 51.2, 0.8)
grid_size = (64, 64)
map_size = (15, 30, 0.15)
# 模型结构定义
model = dict(
type="ViewFusion",
backbone=dict(
type="MixVarGENet",
net_config=[...],
...
),
neck=dict(
type="BiFPN",
...
),
view_transformer=dict(
type="GKTTransformer", #gkt transform
...
),
bev_transforms=[...],
bev_encoder=dict(
type="BevEncoder",
...
),
bev_decoders=[
dict(
type="BevSegDecoder",
...
),
dict(
type="BevDetDecoder",
...
)
],
)
deploy_model = dict(
...
)
...
# 数据加载
data_loader = dict(
type=torch.utils.data.DataLoader,
...
)
val_data_loader = dict(...)
#不同step的训练策略配置
float_trainer=dict(...)
calibration_trainer=dict(...)
int_infer_trainer=dict(...)
#不同step的验证
float_predictor=dict(...)
calibration_predictor=dict(...)
int_infer_predictor=dict(...)
#编译配置
compile_cfg = dict(
march=march,
...
)
注:如果需要复现精度,config中的训练策略最好不要修改。否则可能会有意外的训练情况出现。
img_encoder
来自6个view的image作为输入通过共享的backbone(MixVarGENet)和neck(BiFPN)输出经过encoder后的feature,feature_shape为(6*B,C,1/16H,1/16W)。encoder即对多个view的img_feature 做特征提取,过程见下图:
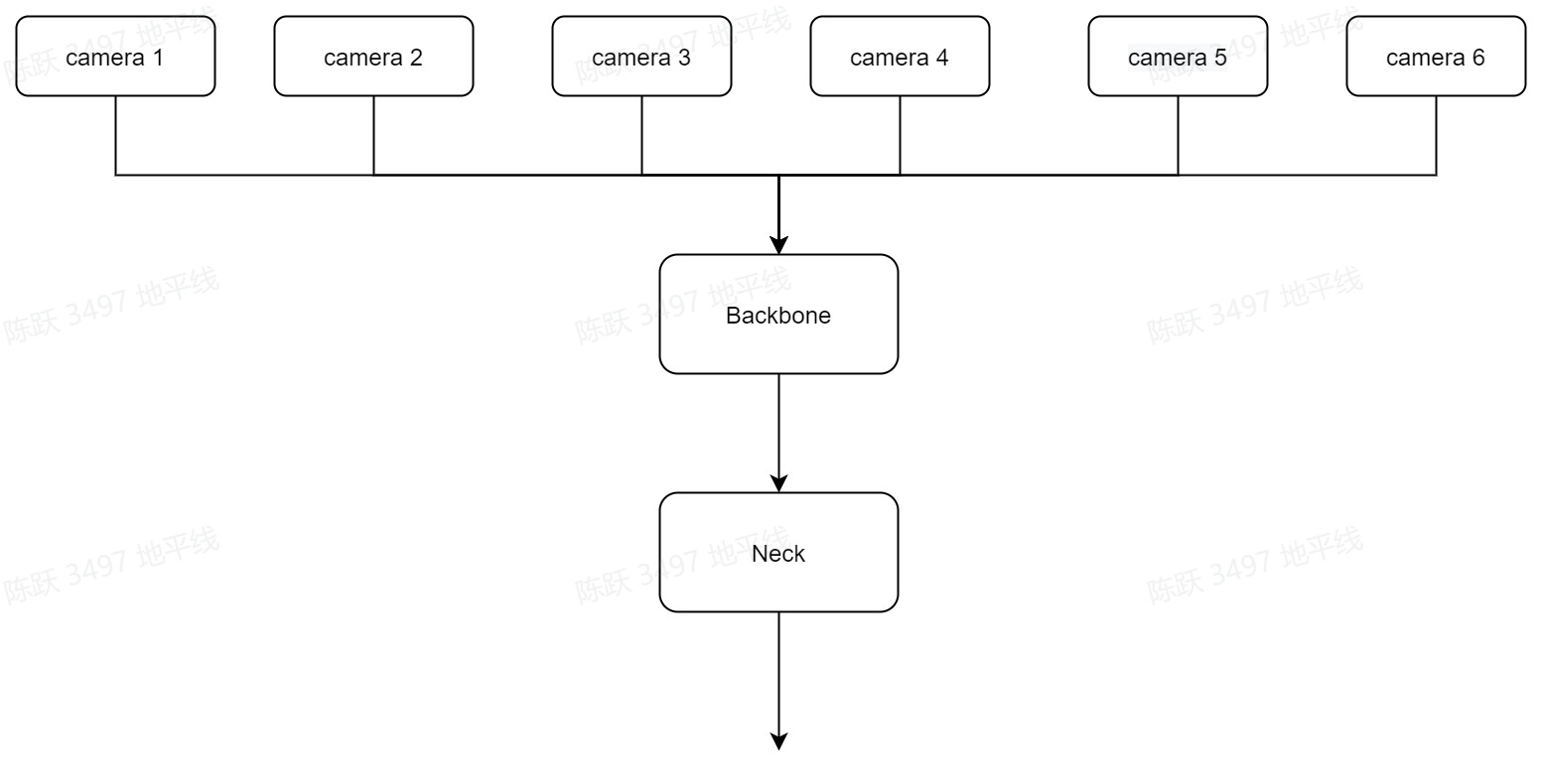
对应代码:
hat/models/backbones/mixvargenet.py hat/models/necks/bifpn.py
bev_gkt 在img_encoder阶段使用地平线自研的MixVarGENet,MixVarGENet是基于J5芯片计算特性开发的轻量级backbone。具有计算效率高、性能优的基本特点。
该结构的基本单元为MixVarGEBlock。一般情况下,一个stage用一个MixVarGEBlock表示,由head op, stack ops,downsample layers,fusion layers四个基本模块组成。bev_gkt 中的配置见config文件的“backbone”。
view_transformer
该算法参考的gkt,gkt 全称为Geometry-guided Kernel Transformer。Geometry-guided 为基于几何先验在图像特征中寻找reference points,Kernel Transformer为在该reference points处通过预先设置窗口抠取图像特征,并在此基础上使用attention操作实现特征优化,从而获取bev特征的方法。具体实现框架见下图:
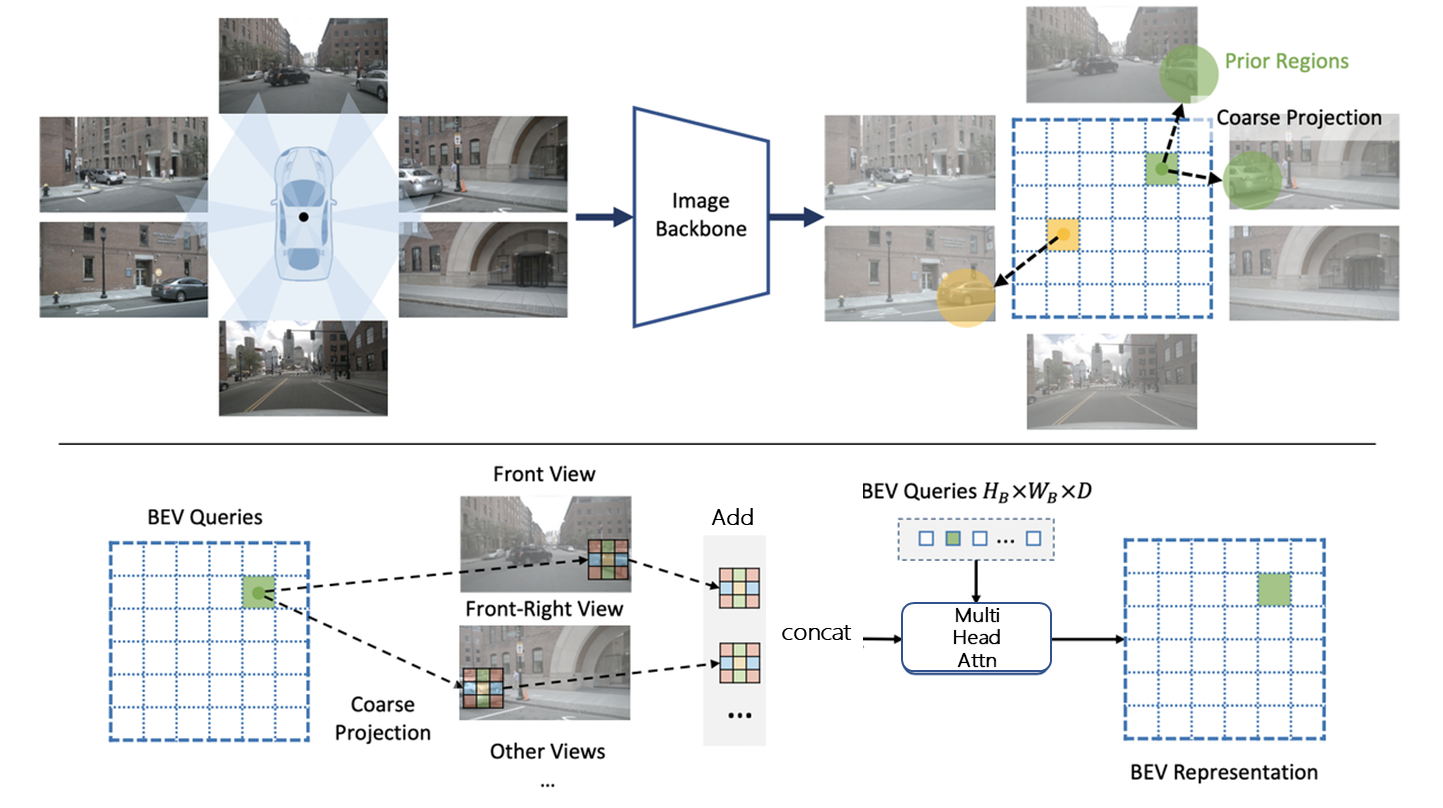
gkt 模型框架图
其中BEV Queries 为4维:[1,160,64,64]
其中的shape变化见下图:
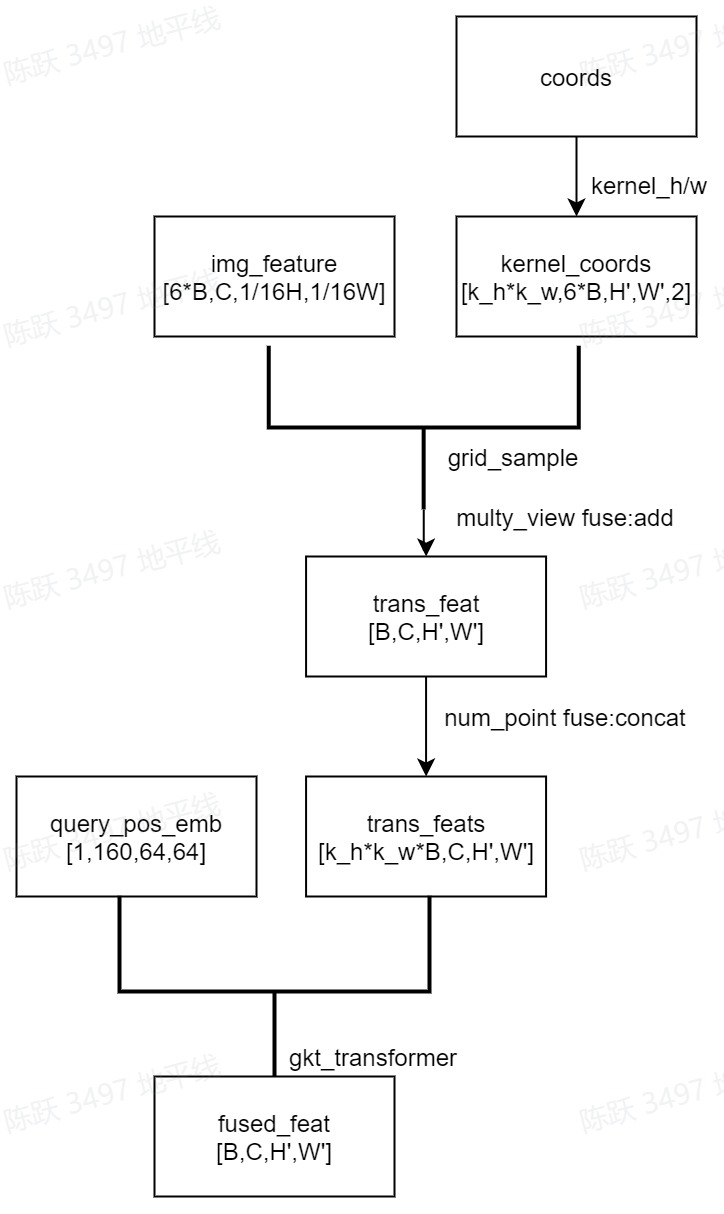
其中points的生成在将每个BEV网格coords根据相机内外参数获取采样点coords后,再对附近像素coords Kh×Kw核区域取点,最终的kernel_coords为[kernel_h*kernel_w,6*B,64,64,2]

对应代码实现:
def _gen_coords_from_kernel(self, coords):
h = self.kernel_size[0] - 2 #h,w=1,1
w = self.kernel_size[1] - 2
kernel_coords = []
for i in range(-h, h + 1):
for j in range(-w, w + 1):
new_coords = coords.clone()
new_coords[..., 0] += j
new_coords[..., 1] += i
kernel_coords.append(new_coords)
kernel_coords = torch.stack(kernel_coords)#[9,6*B,64,64,2]
return kernel_coords
根据kernel_coords使用grid_sample抠取对应的kernel特征然后concat,其中多view的特征融合使用add实现。对应代码实现:
def _spatial_transfom(self, feats, points):
num_points = self.kernel_size[0] * self.kernel_size[1] #9
...
for i in range(num_points):
trans_feat = self.grid_sample(
feats,
self.quant_stub(points[i]),#[6*B, 64, 64, 2]
)
if B > 1:
trans_feat = trans_feat.view(B, self.num_views, C, H, W)
trans_feat = self.floatFs.sum(
trans_feat, dim=1, keepdim=True
).squeeze()
else:
#multy view fuse
trans_feat = self.floatFs.sum(trans_feat, dim=0, keepdim=True)
trans_feats.append(trans_feat)
#num_point(kernel_h*w) fuse
trans_feats = self.floatFs.cat(trans_feats)
将抠取的特征features和可学习的BEV Queries使用attention操作实现特征优化,其中attention layer为GKTTransformerLayer。
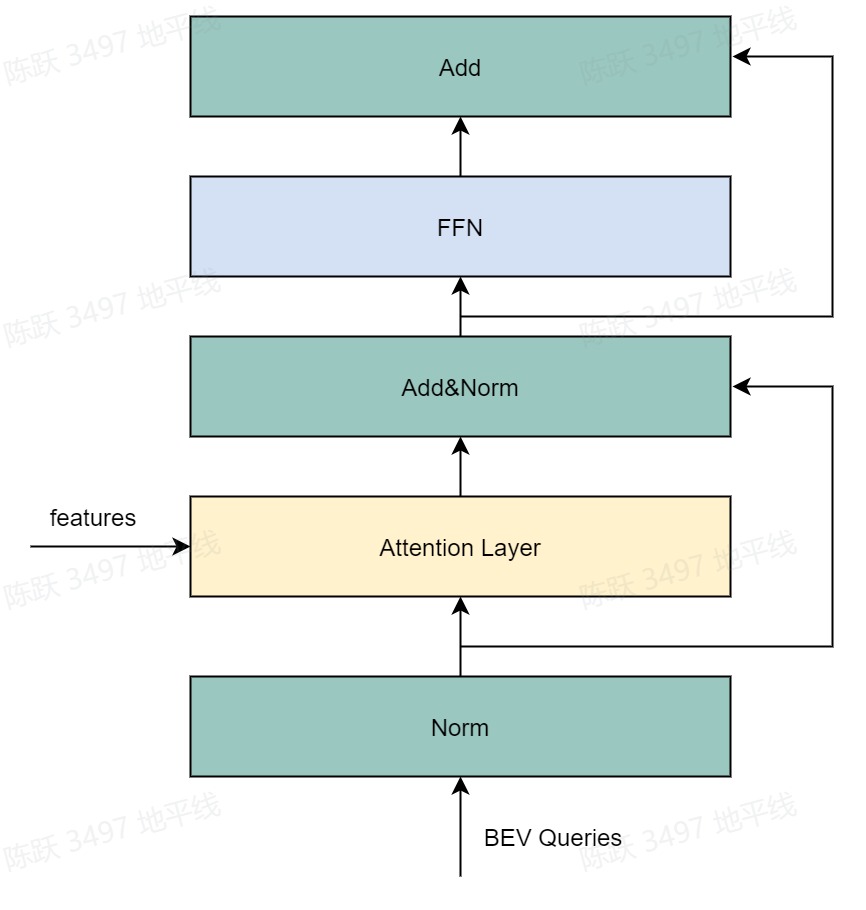
代码路径:hat/models/task_modules/view_fusion/view_transformer.py
bev transform
bev的数据增强仅发生在训练过程中,在 BEV 下做了 rotate的数据增强,作用域是 view transformer 的输出。配置如下:
bev_transforms=[
dict(
type="BevRotate",
bev_size=bev_size,
rot=(-0.3925, 0.3925),
),
],
bev_encoder
bev_encoder过程是对bev_feature 做特征提取的过程,backbone为VargBevBackbone。流程见下图:
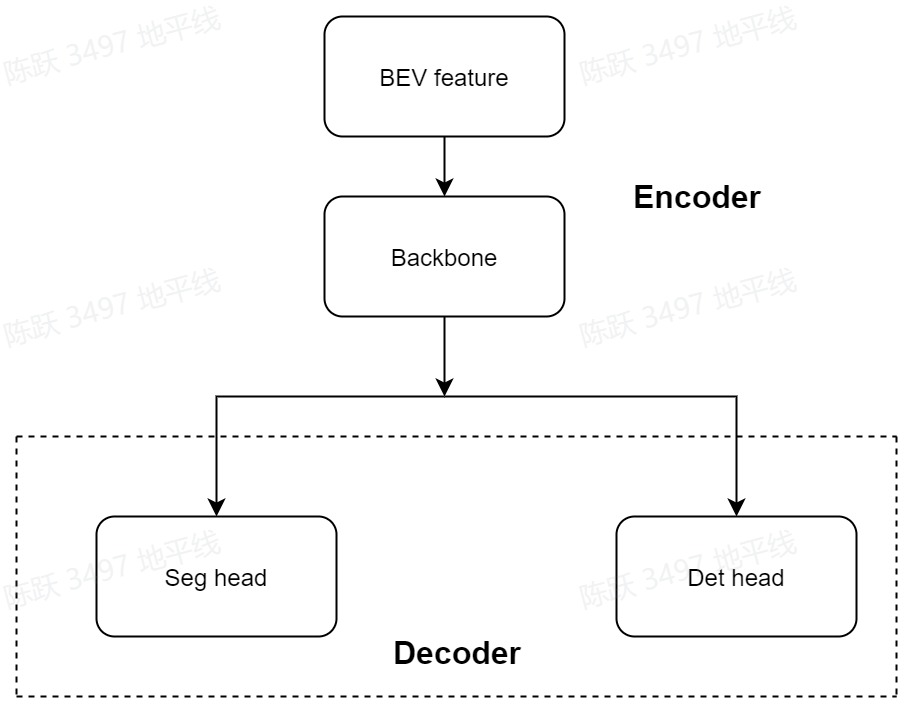
对应代码:
hat/models/task_modules/view_fusion/encoder.py
class BevEncoder(nn.Module):
def __init__(self, backbone: nn.Module, neck: nn.Module):
super(BevEncoder, self).__init__()
self.backbone = backbone
self.neck = neck
def forward(self, feat, meta):
feat = self.backbone(feat)
if self.neck is not None:
feat = self.neck(feat)
return feat
class VargBevBackbone(BevBackbone):
def __init__(self, **kwargs):
...
def _make_conv(self, in_channels, out_channels):
return BasicVarGBlock(...)
bev_head
seg_head-
本模型的分割头为FCNHead,对应代码:hat/models/task_modules/fcn/head.py
class FCNHead(nn.Module):
def __init__(self,...):
...
def forward(self, inputs: List[torch.Tensor]):
x = inputs[self.input_index]
x = self.convs(x)
if self.dropout:
x = self.dropout(x)
seg_pred = self.cls_seg(x)
if self.training:
if self.upsample_output_scale:
seg_pred = self.resize(seg_pred)
if self.argmax_output:
seg_pred = seg_pred.argmax(dim=1)
if self.dequant_output:
seg_pred = self.dequant(seg_pred)
return seg_pred
det_head
检测为多task检测,主要分为:
tasks = [
dict(name="car", num_class=1, class_names=["car"]),
dict(
name="truck",
num_class=2,
class_names=["truck", "construction_vehicle"],
),
dict(name="bus", num_class=2, class_names=["bus", "trailer"]),
dict(name="barrier", num_class=1, class_names=["barrier"]),
dict(name="bicycle", num_class=2, class_names=["motorcycle", "bicycle"]),
dict(
name="pedestrian",
num_class=2,
class_names=["pedestrian", "traffic_cone"],
),
]
在nuscenes数据集中,目标的类别一共被分为了6个大类,网络给每一个类都分配了一个head,装在headlist中,而每个head内部都为预测的参数。-
bev_det的分割头为VargCenterPointHead-
对应代码:hat/models/task_modules/centerpoint/head.py
class VargCenterPointHead(CenterPointHead):
def _make_conv(
self,
...
):
pw_norm_layer = nn.BatchNorm2d(in_channels, **self.bn_kwargs)
pw_act_layer = nn.ReLU(inplace=True)
return BasicVarGBlock(
in_channels=in_channels,
...
)
def _make_task(self, **kwargs):
return TaskHead(**kwargs)
class CenterPointHead(nn.Module):
def __init__(self,...):
self.shared_conv = nn.Sequential(
*(
self._make_conv(...)
for i in range(share_conv_num)
)
)
#head module
for num_cls in num_classes:
heads = copy.deepcopy(common_heads)
heads.update({"heatmap": (num_cls, num_heatmap_convs)})
task_head = self._make_task(
...,
)
self.task_heads.append(task_head)
def forward(self, feats):
rets = []
feats = feats[0]
feats = self.shared_conv(feats)
for task in self.task_heads:
rets.append(task(feats))
forward时,经过共享的Conv后,将feature再分别传入task_heads做task_pred。-
在hat/models/task_modules/centerpoint/head.py的TaskHead对不同的task定义conv_layers:
class TaskHead(nn.Module):
def __init__(...):
...
for head in self.heads:
classes, num_conv = self.heads[head]
...
#head_conv
for _ in range(num_conv - 1):
conv_layers.append(
self._make_conv(
...
)
)
c_in = head_conv_channels
#cls_layer
conv_layers.append(
ConvModule2d(
in_channels=head_conv_channels,
out_channels=classes,
...
)
)
conv_layers = nn.Sequential(*conv_layers)
def forward(self, x):
ret_dict = {}
for head in self.heads:
ret_dict[head] = self.dequant(self.__getattr__(head)(x))
return ret_dict
bev_decoder
多任务模型的decoder分为分割和检测的解码,在分割任务中使用FCNDecoder,在检测任务中使用-
CenterPointDecoder,具体实现流程见下图:
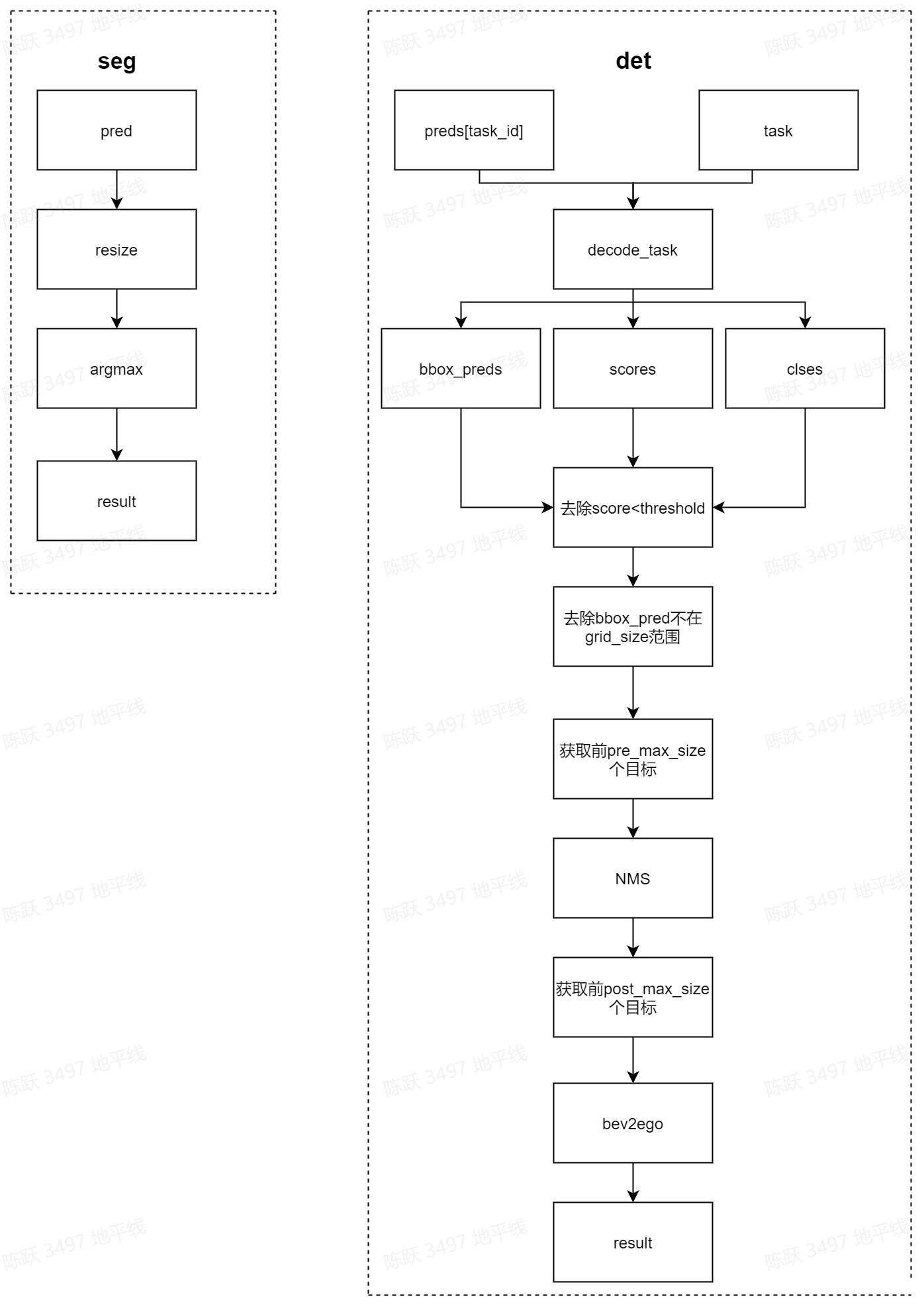
对应代码:
hat/models/task_modules/centerpoint/decoder.py-
hat/models/task_modules/fcn/decoder.py
3 浮点模型训练-
3.1 Before Start-
3.1.1 2.1.1 发布物及环境部署-
step1:获取发布物-
下载OE包horizon_j5_open_explorer_v$version$.tar.gz,获取方式见地平线开发者社区 OpenExplorer算法工具链 版本发布-
step2:解压发布包
tar -xzvf horizon_j5_open_explorer_v$version$.tar.gz
解压后文件结构如下:
|-- bsp
|-- ddk
| |-- package
| `-- samples
| |-- ai_benchmark
| |-- ai_forward_view_sample
| |-- ai_toolchain
| | |-- ...
| | |-- horizon_model_train_sample
| | `-- model_zoo
| |-- model_zoo
| `-- vdsp_rpc_sample
|-- README-CN
|-- README-EN
|-- resolve_all.sh
`-- run_docker.sh
其中horizon_model_train_sample为参考算法模块,包含以下模块:
|-- horizon_model_train_sample #参考算法示例
| |-- plugin_basic #qat 基础示例
| `-- scripts #模型配置文件、运行脚本
step3:拉取docker环境
docker pull openexplorer/ai_toolchain_ubuntu_20_j5_gpu:v$version$
#启动容器,具体参数可根据实际需求配置
#-v 用于将本地的路径挂载到 docker 路径下
nvidia-docker run -it --shm-size="15g" -v `pwd`:/WORKSPACE openexplorer/ai_toolchain_ubuntu_20_j5_gpu:v$version$
3.1.2 数据集准备-
3.1.2.1 数据集下载-
进入nuscenes官网,根据提示完成账户的注册,下载Full dataset(v1.0)、CAN bus expansion和Map expansion(v1.3)这三个项目下的文件。下载后的压缩文件为:
|-- nuScenes-map-expansion-v1.3.zip
|-- can_bus.zip
|-- v1.0-mini.tar
|-- v1.0-trainval01_blobs.tar
|-- ...
|-- v1.0-trainval10_blobs.tar
`-- v1.0-trainval_meta.tar
Full dataset(v1.0)包含多个子数据集,如果不需要进行v1.0-trainval数据集的浮点训练和精度验证,可以只下载v1.0-mini数据集进行小场景的训练和验证。
将下载完成的v1.0-trainval01_blobs.tar~v1.0-trainval10_blobs.tar、v1.0-trainval_meta.tar和can_bus.zip进行解压,解压后的目录如下所示:
|--nuscenes
|-- can_bus #can_bus.zip解压后的目录
|-- samples #v1.0-trainvalXX_blobs.tar解压后的目录
| |-- CAM_BACK
| |-- ...
| |-- CAM_FRONT_RIGHT
| |-- ...
| `-- RADAR_FRONT_RIGHT
|-- sweeps
| |-- CAM_BACK
| |-- ...
| |-- CAM_FRONT_RIGHT
| |-- ...
| `-- RADAR_FRONT_RIGHT
|-- v1.0-trainval #v1.0-trainval_meta.tar解压后的数据
|-- attribute.json
| ...
`-- visibility.json
3.1.2.2 数据集打包-
进入 horizon_model_train_sample/scripts 目录,使用以下命令将训练数据集和验证数据集打包,格式为lmdb:
#pack train_Set
python3 tools/datasets/nuscenes_packer.py --src-data-dir /WORKSPACE/nuscenes/ --pack-type lmdb --target-data-dir /WORKSPACE/tmp_data/nuscenes/v1.0-trainval --version v1.0-trainval --split-name train
#pack val_Set
python3 tools/datasets/nuscenes_packer.py --src-data-dir /WORKSPACE/nuscenes/ --pack-type lmdb --target-data-dir /WORKSPACE/tmp_data/nuscenes/v1.0-trainval --version v1.0-trainval --split-name val
--src-data-dir为解压后的nuscenes数据集目录;-
--target-data-dir为打包后数据集的存储目录;-
--version 选项为[“v1.0-trainval”, “v1.0-test”, “v1.0-mini”],如果进行全量训练和验证设置为v1.0-trainval,如果仅想了解模型的训练和验证过程,则可以使用v1.0-mini数据集;v1.0-test数据集仅为测试场景,未提供注释。-
全量的nuscenes数据集较大,打包时间较长。每打包完100张会在终端有打印提示,其中train打包约28100张,val打包约6000张。
数据集打包命令执行完毕后会在target-data-dir下生成train_lmdb和val_lmdb,train_lmdb和val_lmdb就是打包之后的训练数据集和验证数据集为config中的data_rootdir。
|-- tmp_data
| |-- nuscenes
| | |-- v1.0-trainval
| | | |-- train_lmdb #打包后的train数据集
| | | | |-- data.mdb
| | | | `-- lock.mdb
| | | `-- val_lmdb #打包后的val数据集
| | | | |-- data.mdb
| | | | `-- lock.mdb
2.1.2.3 meta文件夹构建-
在tmp_data/nuscenes 下创建meta文件夹,将v1.0-trainval_meta.tar压缩包解压至meta,得到meta/maps文件夹,再将nuScenes-map-expansion-v1.3.zip压缩包解压至meta/maps文件夹下,解压后的目录结构为:
|-- tmp_data
| |-- nuscenes
| | |-- meta
| | | |-- maps #nuScenes-map-expansion-v1.3.zip解压后的目录
| | | | |-- 36092f0b03a857c6a3403e25b4b7aab3.png
| | | | |-- ...
| | | | |-- 93406b464a165eaba6d9de76ca09f5da.png
| | | | |-- prediction
| | | | |-- basemap
| | | | |-- expansion
| | | |-- v1.0-trainval #v1.0-trainval_meta.tar解压后的目录
| | | |-- attribute.json
| | | ...
| | | |-- visibility.json
| | `-- v1.0-trainval
| | | |-- train_lmdb #打包后的train数据集
| | | `-- val_lmdb #打包后的val数据集
3.1.3 config配置-
在进行模型训练和验证之前,需要对configs文件中的部分参数进行配置,一般情况下,我们需要配置以下参数:
- device_ids、batch_size_per_gpu:根据实际硬件配置进行device_ids和每个gpu的batchsize的配置;
- ckpt_dir:浮点、calib、量化训练的权重路径配置,权重下载链接在config文件夹下的README中;
- data_rootdir:2.1.2.2中打包的数据集路径配置;
- meta_rootdir :2.1.2.3中创建的meta文件夹的路径配置;
- float_trainer下的checkpoint_path:浮点训练时backbone的预训练权重所在路径,可以使用README的# Backbone Pretrained ckpt中ckpt download提供的float-checkpoint-best.pth.tar权重文件。
- infer_cfg:指定模型输入,在infer.py脚本使用时需配置;
3.2 浮点模型训练
config文件中的参数配置完成后,使用以下命令训练浮点模型:
python3 tools/train.py --config configs/bev/bev_gkt_mixvargenet_multitask_nuscenes.py --stage float
float训练后模型ckpt的保存路径为config配置的ckpt_callback中save_dir的值,默认为ckpt_dir。
3.3 浮点模型验证
浮点模型训练完成以后,可以使用以下命令验证已经训练好的浮点模型精度:
python3 tools/predict.py --config configs/bev/bev_gkt_mixvargenet_multitask_nuscenes.py --stage float
4 模型量化和编译
完成浮点训练后,还需要进行量化训练和编译,才能将定点模型部署到板端。地平线对该模型的量化采用horizon_plugin框架,经过Calibration+QAT量化训练后,使用compile的工具将量化模型编译成可以上板运行的hbm文件。
4.1 Calibration
模型完成浮点训练后,便可进行 Calibration。calibration在forward过程中通过统计各处的数据分布情况,从而计算出合理的量化参数。 通过运行下面的脚本就可以开启模型的Calibration过程:
python3 tools/train.py --config configs/bev/bev_gkt_mixvargenet_multitask_nuscenes.py --stage calibration
4.2 Calibration 模型精度验证
Calibration完成以后,可以使用以下命令验证经过calib后模型的精度:
python3 tools/predict.py --config configs/bev/bev_gkt_mixvargenet_multitask_nuscenes.py --stage calibration
对于GKT模型,仅做calib 即可满足量化精度,无需做qat训练!
4.3 量化模型验证
指定calibration-checkpoint后,通过运行以下命令进行量化模型的精度验证:
python3 tools/predict.py --config configs/bev/bev_gkt_mixvargenet_multitask_nuscenes.py --stage int_infer
4.4 仿真上板精度验证
除了上述模型验证之外,我们还提供和上板完全一致的精度验证方法,可以通过下面的方式完成:
python3 tools/align_bpu_validation.py --config configs/bev/bev_gkt_mixvargenet_multitask_nuscenes.py
4.5 量化模型编译
在量化训练完成之后,可以使用compile_perf.py脚本将量化模型编译成可以板端运行的hbm模型,同时该工具也能预估在BPU上的运行性能,compile_perf脚本使用方式如下:
python3 tools/compile_perf.py --config configs/bev/bev_gkt_mixvargenet_multitask_nuscenes.py --out-dir ./ --opt 3
opt为优化等级,取值范围为0~3,数字越大优化等级越高,编译时间更长,但部署性能更好。-
compile_perf脚本将生成.html文件和.hbm文件(compile文件目录下),.html文件为BPU上的运行性能,.hbm文件为上板实测文件。
运行后,ckpt_dir的compile目录下会产出以下文件:
|-- compile
| |-- .html #模型在bpu上的静态性能数据
| |-- .json
| |-- model.hbm #板端部署的模型
| |-- model.hbir #编译过程的中间文件
`-- model.pt #模型的pt文件
5 其他工具
5.1 结果可视化
如果你希望可以看到训练出来的模型对于单帧的检测效果,我们的tools文件夹下面同样提供了预测及可视化的脚本,你只需要运行以下脚本即可:
python3 tools/infer_bev.py --config configs/bev/bev_gkt_mixvargenet_multitask_nuscenes.py --save-path ./
需在config文件中配置infer_cfg字段。
可视化结果将会在save-path路径下输出。-
可视化示例:

6 板端部署-
6.1 上板性能实测-
使用hrt_model_exec perf工具将生成的.hbm文件上板做BPU性能FPS实测,hrt_model_exec perf参数如下:
hrt_model_exec perf --model_file {model}.hbm \
--thread_num 8 \
--frame_count 2000 \
--core_id 0 \
--profile_path '.'
6.2 AIBenchmark 示例-
OE开发包中提供了bev_gkt的AI Benchmark示例,位于:ddk/samples/ai_benchmark/j5/qat/script/bev/bev_mt_gkt,具体使用可以参考开发者社区J5算法工具链产品手册-AIBenchmark评测示例-
可在板端使用以下命令执行做模型评测:
#性能数据
sh fps.sh
#单帧延迟数据
sh latency.sh