引言 – 为什么需要工具链?
大家好,欢迎大家来到地平线 AI 学习系列课程的第二部分 - AI 算法与工具链,本部分课程将以知识点 + 实战 demo的形式,为大家一步一步讲解如何使用地平线的算法和工具链,打造 AI 智能产品。
其他相关课程,AI 开发快速入门,AI Express 应用开发,请参考:
https://developer.horizon.ai/forum/id=5e87076a597722a845fa15bd
本节课我们将会带您初步了解地平线天工开物(Horizon OpenExplorer)AI 芯片 & 算法工具链。**首先您可能会问,究竟什么是 AI 工具链?它的作用又是什么?**简单来说,AI 工具链就是一套工具包,能够帮助我们结合 AI 芯片的能力,优化算法模型的量化训练,简化将模型移植到芯片的整个过程,并在实际应用场景下高效地运行模型推理计算(Inference)。
对于大部分算法工程师来说,比较熟悉的应该是在本地 PC、开发机或者集群上,利用 GPU 去训练一个分类、检测、分割等算法模型。但 GPU 作为一种通用型的处理器,虽然它的算力、缓存等更强,但对应的成本、功率和面积也很大,所以并不适用于嵌入式端。地平线的 AI 芯片- BPU(Brain Processing Unit,地平线自主研发的高效人工智能处理单元)作为一种 ASIC(专用集成电路),主要是在特定的领域(计算机视觉)做了针对性地优化。目前我们重点优化的是卷积计算,特别是 depthwise 卷积。
还有需要注意的是,在 GPU 端进行 AI 算法计算和在嵌入式端(例如边缘智能 AI 设备,摄像头,车载设备,家用设备等)存在一定的差异。GPU 机器功耗大,各项配置非常高,成本昂贵;在嵌入式端,除了功耗、结构、算力等因素受限外,SRAM 缓存也因为成本的原因有一定限制,这就会导致在实际模型推理时可能会存在一定的瓶颈。
**针对这种情况,如何保证 AI 算力、算法精度不受影响,满足实际应用需求,具有一定挑战。其中一个常见做法,最佳实践,就是实现 AI 浮点(float)模型的定点化(quantization)**当模型的计算量大大降低后,既可以减少访存的次数,也可以更好地利用 SRAM 相比于普通内存的访存速度优势。使用 AI 工具链训练算法,不仅在于模型的定点化,还需要保证尽可能高的精度,并且在模型编译(将定点模型编译成能在芯片上运行的二进制指令序列)时还能进行更多的优化,以提升模型的运行效率。在地平线的 AI 工具链中,还包含嵌入式开发包,可以帮助开发者更加方便、简单地将自己的模型部署在芯片上,并做相应的应用开发,以达到实际在嵌入式端实现模型推理或评测的任务目标。
初步了解完 AI工具链的基本概念和意义后,如果您对 AI 算法,AI 智能产品开发感兴趣,那么我们会带您敲开地平线天工开物 AI 工具链的大门,提供工具帮您实现产品落地。本节课我们将从工具链构成、使用流程、特色和性能等方面做一个最基础的介绍,后面的进阶课程则会逐步讲解更多的细节,并进行实战演练。
1. 工具链构成
首先我们介绍一下地平线天工开物工具链的组成部分,主要由以下 3 个组件构成,如图 1 所示,从左至右分别为:
· Training Tools:集成定点化方法的算法包
· Compilation Tools:编译器工具
· Application Development Tools:嵌入式开发工具包
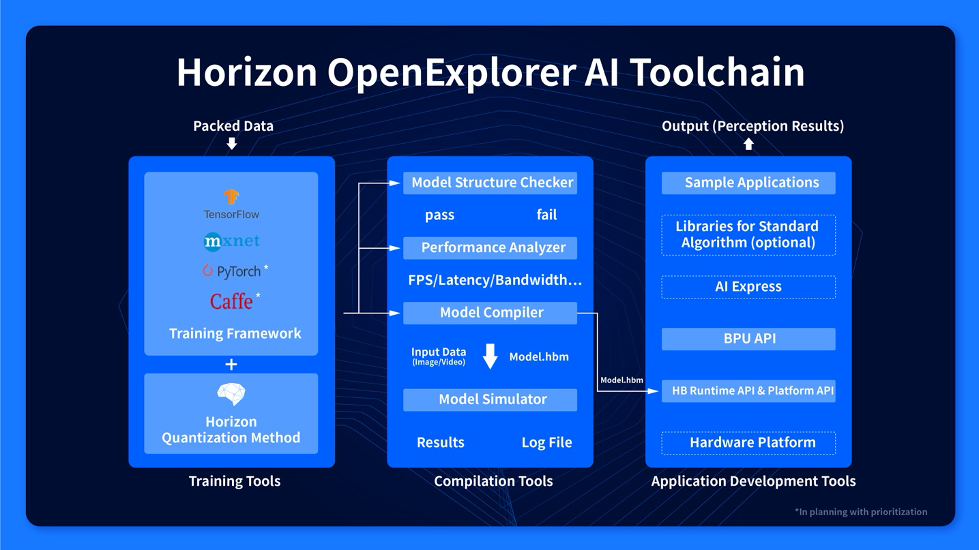
图1 地平线天工开物AI工具链
1.1 算法工具包
该组件集成了地平线定点化的训练方法,即通过该算法包,您可以将一个 float32 的浮点模型量化成一个 int8 的定点模型。
目前我们支持的公版训练框架为 MXNet 和 Tensorflow,其中 MXNet 框架主要用于内部研发使用,对外开放主要为基于 Tensorflow 框架的 Plugin 插件。当您下载安装后,只需要在开源的 Tensorflow 框架上进行少量改动,就可以快速地实现构建网络、定义 loss 函数等功能,非常容易上手。具体的量化训练原理及实现方法会在后面的课程中进行介绍。
caffe 和 pytorch 的训练框架目前正在开发中,以后会提供支持。
1.2 编译器工具包
该组件包含了编译器(Model Compiler)、模拟器(Model Simulator)、模型合法性检查(Model Checker)、模型性能评估(Performance Analyzer)等工具,安装后您可以在终端通过命令行的方式去调用各个功能。其中在实际应用中,最常用的功能是将算法工具包训练出的定点模型编译成能在 BPU 上运行的二进制指令序列,并评估定点模型在 BPU 上的帧率、带宽等性能指标,具体使用方法请参考后续课程。
1.3 嵌入式开发工具包
该组件用于提供嵌入式端的 BPU 软件开发环境。从图 1 最右可见,嵌入式端的接口从下至上依次包含以下几层:
1)Platform API:硬件平台之上最底层的系统软件接口,其中包含了用于管理 BPU 内存的 API;
2)HBRT API:Hobot Runtime,用于在 BPU 上执行编译后的模型的接口;
3)BPU API:封装在系统软件和 HBRT 之上的 BPU 预测库,让用户能够在芯片上使用 BPU 的各项功能;
4)AI Express:帮助用户快速开发应用的中间件,旨在让AI应用开发像搭积木一样简单快捷(AI Express 的介绍和教程已经在社区发布,请见:文字教程 和 课程视频);
5)嵌入式平台应用:包含通用的行人检测、车辆检测等感知应用examples和模型部署等工具,您可依照地平线提供的examples开发特定场景的感知应用。
2. 工具链使用流程
了解了每个模块的基本作用后,本章节我们以图2为例,对工具链的使用流程,即一个算法模型从训练量化到上板部署的具体实现进行一个简单的说明。
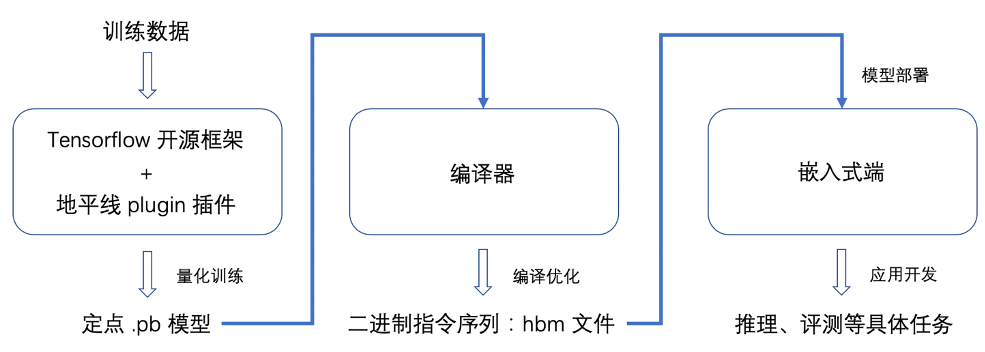
图2 工具链使用流程
当您在开源的 Tensorflow 框架上安装了我们的 plugin 插件后,可以仅在 Keras 接口上做一些微小的改动,就实现网络模型的搭建。此时您可以使用编译器工具包中的模型检查器(图 2 中未绘制)去确认您搭建的模型是否符合 BPU 运行的限制条件,如果不通过可以根据提示进行对应的修改。
模型搭建好后,您就可以送入数据进行量化训练了,训练后会得到一个 .pb 后缀的定点化模型。
接着将 pb 模型送入编译器,经过编译优化后会输出一个 .hbm 的二进制指令序列文件。
最后基于嵌入式开发包,进行 hbm 模型的部署和应用开发,即可在开发板上实现评测和推理等具体任务了。
3. 工具链包结构
学习到这里,如果您已经跃跃欲试,那么可以从 资料下载-AI Toolchain 工具链 下载我们的工具包。本章节我们会从包目录结构的角度,给大家做一个更加具体的介绍,帮助您建立一个整体的概念。
3.1 算法包结构
对于算法包,调用 “tree” 命令可以看到它的简单目录结构如下所示,其中主要包含 4 大模块:
1) /docs/ :提供了基于 Tensorflow 算法包的用户指南。
2) /packages/ :包含了所需的依赖包,install.sh 脚本可用于实现所有依赖包的一键安装。
3) /pretrain-models/ :包含了地平线提供的一些预训练的 backbone 模型。
4) /scripts/ :包含了各种模型的示例代码和脚本。其中,
/configs/ 包含了各模型的配置文件,可用于对文件路径、超参数等进行设置;
/models/ 用于保存用户自己训练出的模型文件;
/tools/ 则包含了数据打包、模型训练、模型验证和模型可视化的相关代码,具体使用也会在后续课程中进行介绍。
├── doc├── packages│ ├── addict-2.2.1-py3-none-any.whl│ ├── bpu_sim-3.2.5-py2.py3-none-any.whl│ ├── horizon_plugin_tensorflow-0.9.0-py2.py3-none-manylinux1_x86_64.whl│ ├── horizon_plugin_tensorflow_gpu-0.9.0-py2.py3-none-manylinux1_x86_64.whl│ ├── horizon_vision_tensorflow-1.0.1-py3-none-any.whl│ ├── install.sh│ └── widerface_evaluation-0.0.2.tar.gz├── pretrain_models│ ├── darknet53_imagenet│ ├── mobilenetv1_alpha05_imagenet│ ├── mobilenetv1_imagenet│ ├── mobilenetv2_imagenet│ ├── resnet18_imagenet│ ├── resnet50_imagenet│ ├── shufflenetv2_imagenet│ ├── varg_darknet53_small_imagenet│ ├── vargnetv2_group4_imagenet│ ├── vargnetv2_imagenet├── scripts│ ├── configs│ ├── classification│ ├── datasets│ ├── detection│ ├── instance│ ├── segmentation│ ├── models│ ├── tools│ ├── im2tfrec.py│ ├── multi_mergebn_train.py│ ├── train.py│ ├── validation.py│ └── visualize.py
3.2 嵌入式开发工具包结构
对于嵌入式开发,我们一共提供了以下 3 个发布包:
1) embedded_release_sdk:包含了示例源码以及源码编译的可执行程序,同时我们还提供了基于多种公版模型的验证脚本,用于帮助用户掌握和验证我们的 API 以及芯片能力,其目录结构如下所示;
├── 2_sdk_program_guide│ ├── 2.2_det_example│ ├── 2.3_api_example│ ├── 2.4_hr_example│ └── deps│ ├── aarch64│ │ ├── horizon│ │ └── thirdparty│ └── x86│ ├── horizon│ └── thirdparty├── 3_app_zoo├── 4_tools│ ├── aarch64│ ├── bin│ └── libs│ ├── accuracy│ ├── python│ └── shell│ ├── config│ ├── bpu│ ├── input│ ├── log│ ├── model│ └── output│ ├── demo│ ├── 2.2_det_example│ ├── 2.3_api_example│ └── 2.4_hr_example│ ├── performance│ └── x86│ ├── bin│ └── libs├── changelog├── CMakeLists.txt├── CMakeLists_x86.txt├── doc└── README.md
其中,2_sdk_program_guide 主要为 API 使用教学示例,其包含从最简单的用 API 运行一个模型推理,到API的使用场景介绍,再到将 API 组成一个简单的应用,用于验证和展示模型的使用效果;
3_app_zoo 用于展示如何基于地平线的应用程序框架,组织一个实际的应用程序;
4_tools 提供了已经编译好的应用程序,以及各种测试脚本,用来测试多种模型在地平线 BPU 上运行的功能、性能、精度等。
2) embedded_data_zoo:基于公开数据集裁剪的一个简单测试数据集,用于验证我们 example 的基本功能,目录结构基于数据集名称存放;
3) embedded_model_zoo: 基于公版模型的模型池,用于验证各个模型的基础能力,目录结构基于模型结构归类存放。
4. 工具链特色及性能
了解完地平线天工开物工具链的基本结构后,您可能又要问了,地平线这套工具链的优势究竟在哪里呢?我觉得有两个词可以比较准确地概括我们量化训练工具链的主要特色:开放、高性能。
开放性 指的是我们完全支持可编程,而且地平线作为一家算法芯片公司,有很多很多的 knowhow,您可以通过源码看到地平线在算法上的一些积累。
高性能 则指的是我们量化训练后的定点模型也可以保持很高的精度。
在 资料下载-AI Toolchain 工具链 您可以获取我们 release 出来的一些模型,在每一个模型目录下我们都提供了一个 README.md,如图 3 所示,里面给出模型训练的精度指标。这里需要提前说明的是,我们的量化训练主要有两个阶段:
1)第一阶段会先训练一个正常的浮点模型,2.1 节算法包的 pretrain_models 中存放的也就这种初步训练的 withBN 浮点模型。训练后我们会通过一个函数接口将 conv 层和其后的 BN(Batch Normalization)层进行参数融合(即所谓的吸收 BN ),再通过移位值的方式进行一种伪量化(参数会拆分成一个浮点数和一个 2 进制的移位值,相乘后为一个 -128~127 的定点数)。
2)第二阶段会基于上一步得到的伪定点模型继续训练,提升吸收 BN 所导致的精度损失,最后再通过另一个函数接口导出一个真正意义上的定点模型。
具体吸收 BN 方法和量化原理我们会在后续课程中介绍,这里仅做初步说明。
在图 3 中我们可以看到,工具链在吸收 BN 阶段时造成的精度损失还是很小的。
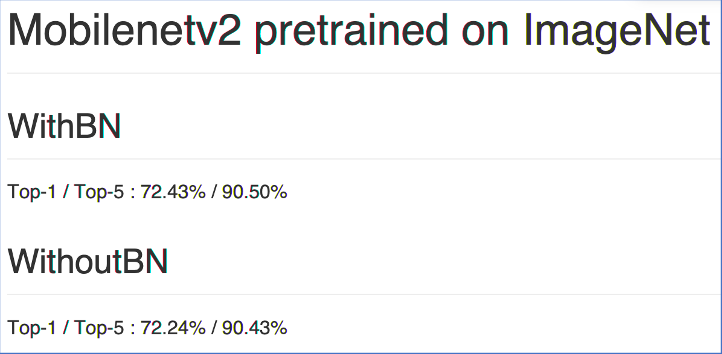
图3 Mobilenet_v2量化精度指标
图 4 给出了我们与 Google 量化精度的对比情况,可以看到以 MobileNetV1 为例,我们的精度损失均优于 Google,而且由于我们在训练过程中还加入了地平线自己的一些 tricks,所以目前量化模型的精度又进一步得到了提升(红字数据),已经高于公版的浮点模型指标。
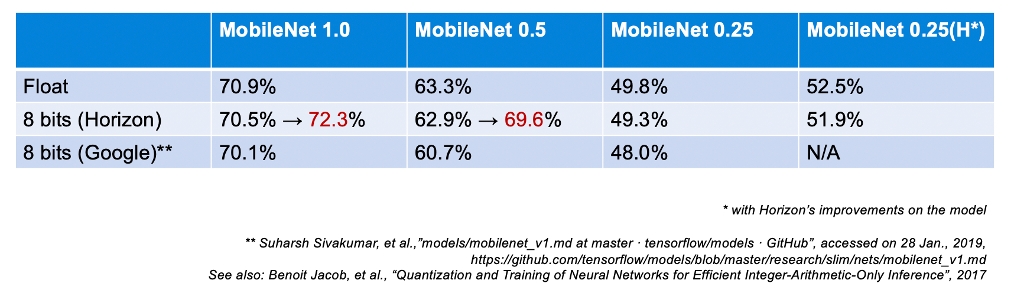
图4 天工开物与Google对比情况
5. 结语
经过本节课的学习,相信您已经对地平线天工开物工具链有了一个初步的整体认识,希望它能够帮助您更好地理解和学习后面的课程!