上节课我们学习了如何进行模型的训练, 这节课以及下一节课, 我们将会指导大家将训练出来的模型放在我们的ai开发板上面运行, 并亲眼看到实际运行的效果. 这里就需要使用我们为大家提供的嵌入式代码. 因此这一节课, 我将会带领大家熟悉一下我们的嵌入式代码发布包, 希望对大家了解和使用地平线的bpu进行智能应用的开发有所帮助.
1. 环境构建
1.1 基础说明
我们提供了3个发布包,用以帮助用户理解如何使用以及验证我们的api,这3个发布包分别为:
**embedded_release_sdk:**包含我们的示例源码,以及源码编译的可执行程序,同时我们提供了基于多种公版模型的验证脚本,用以帮助用户掌握和验证我们的api,以及芯片能力
**embedded_data_zoo:**基于公开数据集裁剪的一个简单测试数据集,用于验证我们的example的基本功能,目录结构基于数据集名称存放
embedded_model_zoo: 基于公版模型的模型池,用于验证各个模型的基础能力,目录结构基于模型结构归类存放
1. ├── 2_sdk_program_guide 2. │ ├── 2.2_det_example 3. │ ├── 2.3_api_example 4. │ ├── 2.4_hr_example 5. │ └── deps 6. │ ├── aarch64 7. │ │ ├── horizon 8. │ │ └── thirdparty 9. │ └── x86 10. │ ├── horizon 11. │ └── thirdparty 12. ├── 3_app_zoo 13. ├── 4_tools 14. │ ├── aarch64 15. │ │ ├── bin 16. │ │ └── libs 17. │ ├── accuracy 18. │ │ ├── python 19. │ │ └── shell 20. │ ├── config 21. │ │ ├── bpu 22. │ │ ├── input 23. │ │ ├── log 24. │ │ ├── model 25. │ │ └── output 26. │ ├── demo 27. │ │ ├── 2.2_det_example 28. │ │ ├── 2.3_api_example 29. │ │ └── 2.4_hr_example 30. │ ├── performance 31. │ └── x86 32. │ ├── bin 33. │ └── libs 34. ├── changelog 35. ├── CMakeLists.txt 36. ├── CMakeLists_x86.txt 37. ├── doc 38. └── README.md
embedded_release_sdk的目录结构,和本文档结构对应,这里简单介绍一下各大章节的内容:
2_sdk_program_guide: 主要为api使用教学示例,从最简单的用api运行一个模型推理(2.2),到api的使用场景介绍(2.3),再到将api组成一个简单的应用,用于验证和展示模型的使用效果(2.4)
3_app_zoo: 展示如何基于地平线的应用程序框架,组织一个实际的应用程序 (3.0)
4_tools: 提供了已经编译好的应用程序,以及各种测试脚本,用来测试多种模型在地平线bpu上运行的功能,性能,精度等 (4.0)
1.2 源码编译
1.2.1 真机编译
要编译可在地平线芯片上运行的程序,需要预先安装对应的交叉编译工具链:gcc-linaro-6.5.0-2018.12-x86_64_aarch64-linux-gnu
在embedded_release_sdk目录下,按照如下操作,进行编译
1. user@ubuntu:~/work/project/tools/example-suite$ mkdir build 2. user@ubuntu:~/work/project/tools/example-suite$ cd build/ 3. user@ubuntu:~/work/project/tools/example-suite/build$ export CC=/opt/gcc-linaro-6.5.0-2018.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-gcc 4. user@ubuntu:~/work/project/tools/example-suite/build$ export CXX=/opt/gcc-linaro-6.5.0-2018.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-g++ 5. user@ubuntu:~/work/project/tools/example-suite/build$ cmake .. 6. -- The C compiler identification is GNU 6.5.0 7. -- The CXX compiler identification is GNU 6.5.0 8. -- Check for working C compiler: /opt/gcc-linaro-6.5.0-2018.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-gcc 9. -- Check for working C compiler: /opt/gcc-linaro-6.5.0-2018.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-gcc -- works 10. -- Detecting C compiler ABI info 11. -- Detecting C compiler ABI info - done 12. -- Detecting C compile features 13. -- Detecting C compile features - done 14. -- Check for working CXX compiler: /opt/gcc-linaro-6.5.0-2018.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-g++ 15. -- Check for working CXX compiler: /opt/gcc-linaro-6.5.0-2018.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-g++ -- works 16. -- Detecting CXX compiler ABI info 17. -- Detecting CXX compiler ABI info - done 18. -- Detecting CXX compile features 19. -- Detecting CXX compile features - done 20. -- Configuring done 21. -- Generating done 22. -- Build files have been written to: /home/user/work/project/tools/example-suite/build 23. user@ubuntu:~/work/project/tools/example-suite/build$ make -j8 24. user@ubuntu:~/work/project/tools/example-suite/build$ make install
1.2.2 模拟器编译
我们同样提供了模拟器,用于给手上没有实际硬件的用户,在模拟器上通过软件模拟硬件的方式,来适应和学习地平线芯片的特性以及API的使用。
模拟器编译,需要的开发环境为centos, 编译器版本为 gcc 4.8.5和g++ 4.8.5
编译方式如下:
1. [root@host-10-10-108-109 example-suite]# cp CMakeLists_x86.txt CMakeLists.txt 2. [root@host-10-10-108-109 example-suite]# mkdir build 3. [root@host-10-10-108-109 example-suite]# cd build 4. [root@host-10-10-108-109 build]# cmake .. 5. -- The C compiler identification is GNU 4.8.5 6. -- The CXX compiler identification is GNU 4.8.5 7. -- Check for working C compiler: /usr/bin/cc 8. -- Check for working C compiler: /usr/bin/cc -- works 9. -- Detecting C compiler ABI info 10. -- Detecting C compiler ABI info - done 11. -- Check for working CXX compiler: /usr/bin/c++ 12. -- Check for working CXX compiler: /usr/bin/c++ -- works 13. -- Detecting CXX compiler ABI info 14. -- Detecting CXX compiler ABI info - done 15. -- Configuring done 16. -- Generating done 17. -- Build files have been written to: /root/user/example-suite/build 18. [root@host-10-10-108-109 build]# make -j8 19. [root@host-10-10-108-109 build]# make install
1.3 运行测试
在前面的编译过程中,我们已经通过make install, 将编译出来的可执行程序,以及依赖库,都安装到4_tools目录下面。
用户可以通过将整个4_tools,embedded_data_zoo,embedded_model_zoo3个包都上传到运行环境下。
将embedded_data_zoo通过软链接的方式,命名为model_zoo放在4_tools目录下,
1. [root@host-10-10-108-109 4_tools]# ln -s /root/user/embedded_model_zoo-v3.4.0/embedded_model_zoo/ model_zoo
同时在各个脚本执行目录,将embedded_data_zoo通过软件连接的方式,放在脚本执行目录下。
1. [root@host-10-10-108-109 4_tools]# cd demo/2.4_hr_example/ 2. [root@host-10-10-108-109 2.4_hr_example]# ln -s /root/user/embedded_data_zoo/ embedded_data_zoo
修改脚本目录下的base_config中的平台,然后通过各个start脚本,即可运行各个模型的例子
1. root@host-10-10-108-109 2.4_hr_example]# vi base_config.sh
修改如下内容:
# define base info# support platform:[x2, j2, 96board, mono, x86]platform=x86
我们同时提供了pc-sender和client展示端,用于展示实际模型运行的效果:

2. SDK 使用指南
2.1 整体说明
bpu_predict封装了关于bpu操作的底层接口,以简单易用的接口形式供用户调度。并实现了高并行度的调度策略,可以帮助用户快速集成基于bpu的模型集成,并达到较好的性效果。
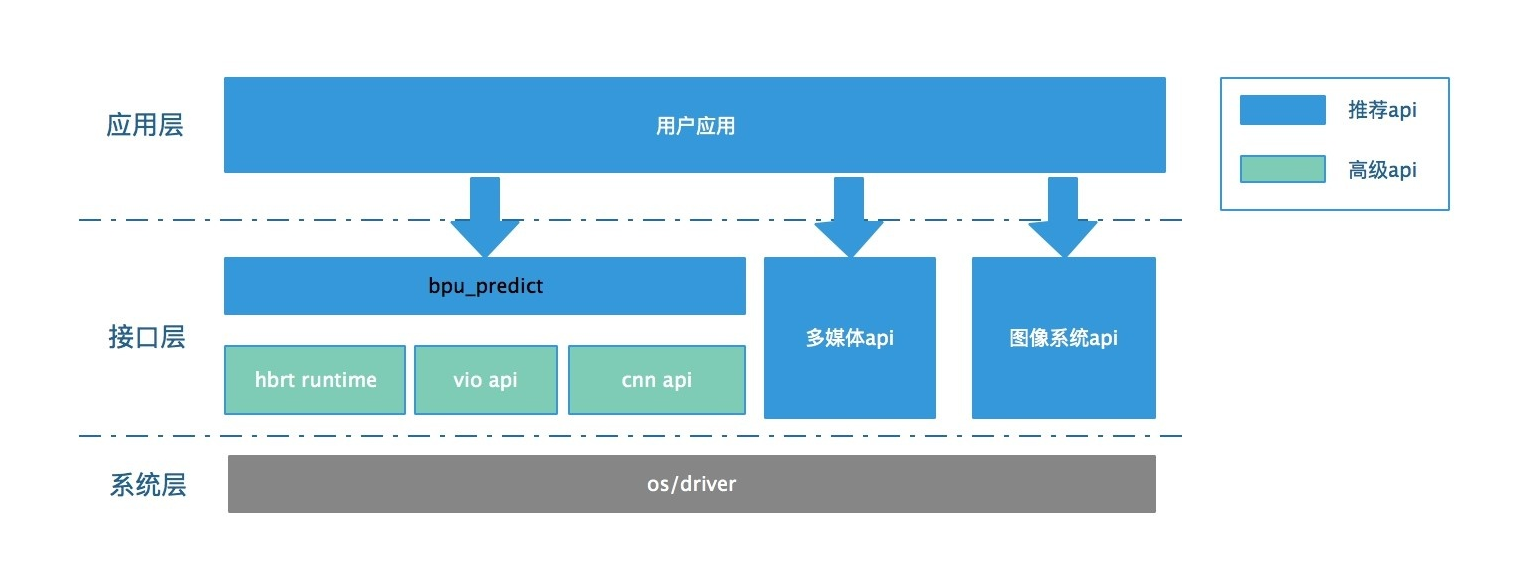
2.2 基本流程
如2.2_run_mobileNet_224_224_from_nv12中的代码所示,一个典型的sdk使用流程,包含将模型加载到bpu,准备输入数据,调用接口运行模型进行推理,获取推理结果进行解析。其代码流程大致如下:
1. // 1. 加载模型至BPU中 2. BPU_loadModel("mobileNetV1_224x224.hbm", &bpu_handle) 3. 4. // 2. 准备输入数据 5. BPUFakeImage *bpu_fake_image = 6. BPU_getFakeImage(fake_img_handle, nv12_ptr, 224 * 224 * 3 / 2); 7. 8. // 3. 使用bpu进行推理 9. BPU_runModelFromImage(bpu_handle, 10. "mobileNetV1", 11. bpu_fake_image, 12. output_buf.data(), 13. output_buf.size(), 14. &model_handle); 15. 16. // 4. 等待获取模型推理结果 17. BPU_getModelOutput(bpu_handle, model_handle); 18. 19. // 5. 对结果进行解析 20. parseSoftmaxClassResultTopK( 21. output_info, output_buf.data(), result_data.data(), 1);
接下来的章节,将会详细介绍流程中各个步骤的接口的含义,以及如何使用。
2.3 接口说明
2.3.1 IO接口
首先要对bpu-predict库的io部分进行介绍,这些io接口支持将camera输入或者本地图像导入bpu 内存中,以便后续模型在bpu上的前向推理,接口可分为三类,pyramid,fakeimage以及feedback,其中pyramid是基于camera输入的场景,而fakeimage和feedback则是本地图片输入的场景。
2.3.1.1 pyramid
BPU 提供了硬件实现图像金字塔的功能。可以对输入的一张图像做金字塔处理得到多尺度缩放的图像结果。这个功能可以提供多个不同尺寸的图像作为选择,能够帮助检测或者后验证模型的前向推理工作。而Pyramid类型就是使用开发板上配置的camera采集到的图像经过金字塔处理后的结果。-
在使用pyramid相关接口之前,需要先创建对应的handle。
1. int ret = BPU_createPyramid(vio_config, cam_config, 0, 0, &handle);
这里第一和第二个输入参数分别是vio和camera的配置文件,开发板可支持多种camera类型,通过输入camera配置文件中的config_id和port_id来指定camera,目前仅支持720P和1080P的camera。-
接着获取金字塔的结果,如果还没有图像进来,接口就会阻塞,并等待金字塔处理完成。
1. ret = BPU_getPyramidResult(handle, &pym_buffer);
获取的金字塔结果是BPUPyramidBuffer类型,其中不仅仅包含了图像的多尺度缩放结果,还包括了诸如frame id,时间戳等重要信息,都可以通过接口获取出来。-
获取当前图像帧的frame id。
1. int frame_id = BPU_getPyramidFrameID(pym_buffer);
获取当前图像帧的时间戳。
1. int64_t timestamp = BPU_getPyramidTimestamp(pym_buffer);
除此之外,还可以直接获取金字塔每一层处理结果的图像指针,图像为nv12类型。
1. struct CB_DATA { 2. int height; 3. int width; 4. uint8_t *y_ptr; 5. uint8_t *uv_ptr; 6. }; 7. void cb_pyramid( 8. void *y_ptr, void *uv_ptr, int height, int width, void *cb_data_ptr) { 9. CB_DATA *cb_data = reinterpret_cast<CB_DATA *>(cb_data_ptr); 10. cb_data->height = height; 11. cb_data->width = width; 12. cb_data->y_ptr = reinterpret_cast<uint8_t *>(y_ptr); 13. cb_data->uv_ptr = reinterpret_cast<uint8_t *>(uv_ptr); 14. } 15. CB_DATA cb_data; 16. BPU_processPyramidResult(pym_buffer, 0, cb_pyramid, &cb_data);
可以看到,接口是通过提供了回调函数的方式来获取指定层的图像结果,这里也说明一下金字塔生成层的方式,是根据vio配置文件中 `pymid_ctrl_config` 和 `pymid_ds_config`,可以控制金字塔生成的层数。其中,0层表示原始图像,4、8、12等4的倍数层分别是原始图像的1/2、1/4和1/8层。配置文件中的1、2、3、5、6、7等层是根据ROI做对应factor的scale。用户一般都是使用4的倍数层,而倍数的roi层有特殊用法,这里暂不介绍。-
pyramid结果用完之后要记得释放,否则会导致内存泄漏问题。
1. ret = BPU_releasePyramidResult(handle, pym_buffer);
程序最后也要释放pyramd handle占用的资源。
1. ret = BPU_releasePyramid(handle);
2.3.1.2 fakeimage
在X2/J2开发板上camera的输入一般支持720P和1080P两种尺寸,虽然后续的金字塔处理会提供多尺度缩放,但是camera输入时可提供的图像尺寸依旧不多,而实际训练出的深度学习网络的输入是没有尺寸的限制,例如分类模型的输入为224x224,yolov3检测模型的输入是416x416,为了能在bpu中运行这类模型,我们提供了另一种输入类型fakeimage,这种类型可支持任意大小的图像输入,唯一的限制是宽度必须是16的整数倍,这是由底层硬件决定的。-
首先要创建一个BPUFakeImageHandle的对象,这里输入参数宽和高对应着图像的尺寸,也就是说一个handle只能对应一种图像尺寸。
1. int ret = BPU_createFakeImageHandle(img_h, img_w, &handle);
接下来需要输入图像数据,并获得对应的BPUFakeImage类型的对象,fakeimage仅支持nv12类型的图像输入。
1. BPUFakeImage *fakeimage = BPU_getFakeImage(handle, nv12_img.data(), nv12_size)
这里会检查数据大小与handle对应的尺寸是否匹配(size = h * w * 3 / 2),然后函数会申请bpu内存,并把nv12类型的图像导入bpu内存中,并等待后续调用执行接口(BPU_runModelFromImage)完成前向推理。-
在模型跑完之后,需要将获取的fakeimage释放,由于释放fakeimage时会间接释放内部申请的bpu内存,因此如果不及时释放,会导致内存泄漏问题。
1. ret = BPU_releaseFakeImage(handle, fakeimage);
结束时也要记得释放BPUFakeImageHandle。
1. ret = BPU_releaseFakeImageHandle(handle);
2.3.1.3 feedback
2.3.1.2 的fakeimage类型虽然支持了任意尺寸的图像,但是相较于2.3.1.1节的pyramid类型又缺少了对输入图像的金字塔处理,多尺度图像输入在特殊场合中会有重要的作用,因此为了弥补这一缺点,我们提供了另一种feedback类型作为图像输入。Feedback相关接口通过软件调用底层硬件实现了对图像的金字塔处理,并且相较于基于camera输入的pyramid类型的尺寸单一,Feedback类型也可支持任意尺寸,仅有的约束是高是4的倍数,宽是16的倍数。
首先创建BPUFeedbackHandle的对象。
1. int ret = BPU_createFeedback(fb_config, &handle);
这里fb_config是feedback类型的配置文件,主要用于配置金字塔处理的输入尺寸,每个配置文件对应一种图像的尺寸,和pyramid类型中的vio的配置文件类似。-
将nv12类型的输入图像回灌金字塔硬件中,并获取金字塔处理结果。
1. ret = BPU_getFeedbackResult(handle, nv12_img.data(), nv12_size, &pym_buffer);
这里输入必须是nv12类型的图像,并且会对数据的大小和handle对应的尺寸做检查,同时由于生成的金字塔处理结果也是BPUPyramidBuffer类型,因此基于BPUPyramidBuffer类型获取信息的相关接口,这里也都能适用,具体参考2.3.1.1小节,这里不再赘述。
在模型跑完之后需要将回灌结果释放掉,否则会造成内存泄露的问题。
1. ret = BPU_releaseFeedbackResult(handle, pym_buffer);
程序最后也要释放BPUFeedbackHandle
1. ret = BPU_releaseFeedbackHandle(handle);
2.3.2 基础接口
在了解如何运行模型之前,需要掌握与模型相关的基础接口,这些接口能够帮助用户加载并获取模型的相关信息,有助于模型的了解,后续模型执行以及输出结果的解析。-
首先是模型文件加载,运行模型之前必须先将模型文件加载到bpu内存中,通过调用BPU_loadModel接口加载并创建一个BPUHandle类型的句柄,这个句柄用于后续获取各种模型信息。
1. int LoadBpuModel(const char *model_file, 2. const char *config_file, 3. BPUHandle *bpu_handle) { 4. int ret = BPU_loadModel(model_file, bpu_handle, config_file); 5. if (ret != BPU_OK) { 6. std::cout << "load model fail: " 7. << BPU_getErrorName(ret) 8. << std::endl; 9. return -1; 10. } 11. return 0; 12. }
代码中通过函数LoadBpuModel封装了加载的过程,可以看到调用后将接口BPU_loadModel的返回值与BPU_OK(BPU_OK属于错误码的枚举类型)进行比较,当返回值不等于BPU_OK时表示模型加载失败,失败后可通过调用BPU_getErrorName来获取返回的错误码对应的信息来协助代码的debug。
模型加载成功之后,可以获取bpu-predict库的版本信息,接口输入的参数是加载接口创建好的handle句柄,返回的指针指向了携带版本信息的字符串,当调用失败后会返回空指针。
1. const char *version = BPU_getVersion(bpu_handle);
由于一个模型文件中可能包含一个或多个模型,可以通过获取模型文件中的模型名称列表及相应的模型个数来确定需要的模型是否存在,并且后续很多接口也需要指定模型名字来对相应的模型进行操作。
1. const char **model_name_list; 2. int model_cnt = 0; 3. int ret = BPU_getModelNameList(bpu_handle, &model_name_list, &model_cnt);
这里BPU_getModelNameList的输出参数包含model_name_list和model_cnt,其中model_name_list指向了字符串列表的首地址,而model_cnt则表示文件中包含的模型个数。-
为了能够执行模型并解析输出结果,我们还需要掌握模型输入输出的有关信息,以便能做好相应的准备,BPU_getModelInputInfo和GetModelOutputInfo可分别用于获取模型的输入输出信息,这两个接口参数和调用方法类似,其中输入参数model_name指定模型文件中的模型,而输出参数BPUModelInfo结构体则存储着模型输入输出的节点信息。
1. BPUModelInfo input_info; 2. int ret = BPU_getModelInputInfo(bpu_handle, model_name, &input_info); 3. BPUModelInfo output_info; 4. ret = BPU_getModelOutputInfo(bpu_handle, model_name, &output_info);
对于BPU_getModelInputInfo返回的输入节点的结构体中,num表示输入节点的个数,valid_shape_array表示若干个输入节点的有效shape拼接成的一维数组,dtype_array表示输入节点的数据类型(单字节还是四字节),通过这些信息我们就可以正确的准备模型的输入了。
1. for (int i = 0; i < input_info.num; ++i) { 2. std::cout << "("; 3. for (int j = input_info.ndim_array[i]; 4. j < input_info.ndim_array[i + 1]; ++j) { 5. std::cout << input_info.valid_shape_array[j] << ","; 6. } 7. std::cout << ")" << std::endl; 8. }
对于BPU_getModelOutputInfo返回的输出节点的结构体中, num表示输出节点的个数,size_array表示输出节点的对齐内存大小,这两个字段可以计算出模型输出需要占据的总内存,当后续执行模型需要为输出申请内存时会用到;而dtype_array可以确定输出的数据类型是int8还是int32,is_big_endian可以判断大小端读取int32类型数据的方式,shift_value是定点结果的移位值,aligned_shape_array和valid_shape_array分别是输出结果的对齐尺寸和有效尺寸,这些字段可以帮助用户解析模型的输出结果,完成模型的后处理部分。
1. for (int i = 0; i < output_info.num; ++i) { 2. std::cout << "name: " << output_info.name_list[i] << ", shape: "; 3. std::cout << "("; 4. for (int j = output_info.ndim_array[i]; 5. j < output_info.ndim_array[i + 1]; ++j) { 6. std::cout << output_info.aligned_shape_array[j] << ","; 7. } 8. std::cout << ")" << std::endl; 9. int out_type_size = sizeof(int8_t); 10. if (output_info.dtype_array[i] == BPU_DTYPE_FLOAT32) { 11. out_type_size = sizeof(float); 12. if (output_info.is_big_endian[i]) { 13. std::cout << "output is big endian mode" << std::endl; 14. } 15. } 16. std::cout << "aligned byte size is : " 17. << output_info.size_array[i] << std::endl; 18. }
当然在程序的最后,我们也需要把模型文件卸载,可以调用BPU_release来释放模型文件占用的资源。
1. int ret = BPU_release(bpu_handle);
2.3.3 内存管理
模型执行之前需要准备模型的输入和输出,bpu-predict库中有多个模型执行接口,对应的模型输入类型也有多种,包括BPUPyramidBuffer,BPUFakeImage以及BPU_Buffer_Handle,而输出只有BPU_Buffer_Handle这一种,这一小节只介绍BPU_Buffer_Handle,其余的在之后会有介绍。-
BPU_Buffer_Handle用于对外部申请的cpu内存进行管理,它既可以作为输入buffer存储输入数据,也可以作为输出存储模型推理的结果,buffer的数量需要和模型输入输出的节点数量对应。-
首先基于申请的内存地址来创建buffer。
1. *in_buffer = BPU_createBPUBuffer(img, size);
创建输入输出的buffer数量可以从2.3.1节的BPU_getModelInputInfo和BPU_getModelOutputInfo返回的BPUModelInfo结构体中得到。
1. *in_num = info.num; 2. *out_num = info.num
当然也可以访问buffer中的数据,例如在解析模型结果时,需要从BPU_Buffer_Handle中返回模型输出的首地址以及内存大小。
1. void *out_ptr = BPU_getRawBufferPtr(out_buffer[i]); 2. int buf_size = BPU_getRawBufferSize(out_buffer[i])
最后记得要释放申请的buffer。
1. BPU_freeBPUBuffer(buffer[i]);
以上的这些接口对于准备模型的输入和输出来说都通用,不过还有一种更方便,更高效的方式来创建模型的输出buffer。-
empty buffer是专门为了模型输出准备的,在我们的芯片中bpu和cpu的内存是独立的,但是当前的bernoulli和bernoulli2架构中,bpu的内存可以直接被cpu访问,因此我们不需要在外部为输出申请内存,然后将bpu的处理结果导入,而是直接将bpu内存的地址返回,这样会大大减少消耗的时间。
1. out_buffer[i] = BPU_createEmptyBPUBuffer();
可以看到创建emptybuffer的接口没有任何输入参数,更加的方便,并且输出也是BPU_Buffer_Handle类型,因此获取结果的指针和大小的方法与之前一致,因此当准备输出的buffer时更推荐emptybuffer这一种方式。
2.3.4 模型执行
bpu-predict库中提供了六种模型执行的接口,这些接口都是异步调用方式,为了方便介绍可按照模型输入来源划分成三类,这里的模型输入来源不是指软件的变量类型,而是模型的编译选项,这些模型执行接口是与编译选项绑定的。不管是tf模型还是mxnet模型都需要通过编译指令转换为hbm模型文件,才可以在bpu中执行,而编译指令中有一个-i的编译选项,可提供三种模型输入参数,分别是pyramid,ddr以及reiszer。
2.3.4.1编译选项–i pyramid
选项-i pyramid输入是专门支持nv12类型的图像输入,当模型执行时,硬件会先将nv12图像转换为yuv444图像,然后接着执行前向推理。基于这类编译选项,可调用的软件执行接口有BPU_runModelFromPyramid,BPU_runModelFromImage以及BPU_runModelCropPyramid。
a) BPU_ runModelFromPyramid
首先介绍接口BPU_runModelFromPyramid,这个接口使用金字塔结果BPUPyramidBuffer类型作为输入(BPUPyramidBuffer可参见2.3.1.1小节),使用BPU_Buffer_Handle存储模型输出地址(可参见2.3.3小节)。
1. BPUModelHandle model_handle; 2. ret = BPU_runModelFromPyramid(bpu_handle, 3. model_name, 4. pym_buffer, 5. pym_level, 6. out_buffer.data(), 7. out_buffer.size(), 8. &model_handle)
这里的pym_level用来指定金字塔图像的那一层用来作为输入。-
这是个异步执行接口,会将执行任务添加至任务队列。该任务将由后台 engine 执行。所以当该接口返回,并不意味着模型执行已经完成。当返回时,会设置 BPUModelHandle变量,这个变量用于调用 BPU_getModelOutput接口,等待模型执行完成,获取执行结果。
1. ret = BPU_getModelOutput(bpu_handle, model_handle);
模型执行完成后实际结果会被写入到 BPU_runModelFromPyramid 提供的output buffer中,这个接口是阻塞调用,在接口返回0后,output buffer 才可以被访问。-
当解析完结果后,也需要释放当前的BPUModelHandle变量所占用的资源,如果申请的output buffer是empty buffer类型,那么释放后buffer指向的地址不能再被访问。
1. ret = BPU_releaseModelHandle(bpu_handle, model_handle);
后续的执行接口也都是异步调用,流程与上述一致。
b) BPU_runModelCropPyramid-
BPU_runModelCropPyramid接口与BPU_runModelFromPyramid类似,也是接收金字塔处理结果作为输入,但不同的是BPU_runModelFromPyramid接口是选取某一层图像作为输入,而BPU_runModelCropPyramid是在某一层图像的基础上裁剪出一个roi作为输入。
1. BPUModelHandle model_handle; 2. ret = BPU_runModelCropPyramid(bpu_handle, 3. model_name, 4. pym_buffer, 5. pym_level, 6. start_x, 7. start_y, 8. out_buffer.data(), 9. out_buffer.size(), 10. &model_handle)
可以看到相较于BPU_runModelFromPyramid接口,BPU_runModelCropPyramid仅仅多了两个参数,这两个参数用于指定roi的左上角顶点的坐标,roi的宽和高与模型输入大小一致。这个接口也是异步调用,因此后续的用法与之前一致,这里不再赘述。-
注意:调用这个接口时,还需要一个模型编译选项-pyramid-stride的帮助,用于图像宽度的步进。通常模型的输入尺寸需要和图像尺寸一致,而编译选项-pyramid-stride会默认为模型宽度,但是在这里模型的输入尺寸不能大于图像,这样才能裁剪出一个roi,因此编译hbm文件时要指定-pyramid-stride与所选的金字塔图像层的宽度一致,而不是默认为模型宽度。
c) BPU_runModelFromImage-
BPU_runModelFromImage接口除了使用BPUFakeImage类型作为输入,其余用法与上述一致,BPUFakeImage类型可参见2.3.1.2节。
1. BPUModelHandle model_handle; 2. ret = BPU_runModelFromImage(bpu_handle, 3. model_name, 4. fake_image, 5. out_buffer.data(), 6. out_buffer.size(), 7. &model_handle)
2.3.4.2编译选项–i ddr
编译选项-i pyramid是专门支持图像输入的模型,但是实际上深度学习不仅仅包括视觉,还有语音识别,自然语言处理等多个方向,此时输入类型是多种多样的,可以选择-i ddr选项,此时bpu会直接从内存中读取数据而不做任何的预处理,可以支持任意类型的输入。-
a) BPU_runModelFromDDR
需要BPU_Buffer_Handle类型作为输入输出,注意的是由于底层硬件限制,输入数据必须是对齐的,而bpu不会对ddr类型的输入做任何预处理,因此必须软件自己做这部分工作,即对nhwc的每一维度都加padding进行对齐。
1. void RemoveMeanAndAddPadding(int valid_h, int valid_w, int valid_c, 2. const int *aligned_shape, 3. const uint8_t *img, 4. int8_t *img_with_padding) { 5. // batch of img only support 1 6. int aligned_h = aligned_shape[1]; 7. int aligned_w = aligned_shape[2]; 8. int aligned_c = aligned_shape[3]; 9. int h_stride = aligned_w * aligned_c; 10. int w_stride = aligned_c; 11. for (int hh = 0; hh < valid_h; ++hh) { 12. for (int ww = 0; ww < valid_w; ++ww) { 13. for (int cc = 0; cc < valid_c; ++cc) { 14. int offset = hh * h_stride + ww * w_stride + cc; 15. // convert uint8 to int8 16. img_with_padding[offset] = *(img++) - 128; 17. } 18. } 19. } 20. }
这个函数中还做了一次减均值的操作,这是因为bpu处理的是有符号数,而模型输入的yuv444图像是无符号类型,因此需要做一次转换,这个预处理并不是必须的,由具体情况决定。-
对齐的shape大小可以通过接口BPU_getModelInputInfo获得
1. BPUModelInfo info; 2. int ret = BPU_getModelInputInfo(bpu_handle, model_name, &info); 3. … 4. // aligned shape is valid shape with padding 5. *aligned_shape = info.aligned_shape_array; 6. *aligned_size = info.size_array[0]
输入与输出的BPU_Buffer_Handle类型的创建可参考2.3.2节,然后就可以调用执行接口了。
1. BPUModelHandle model_handle; 2. ret = BPU_runModelFromDDR(bpu_handle, 3. model_name, 4. in_buffer.data(), 5. in_buffer.size(), 6. out_buffer.data(), 7. out_buffer.size(), 8. &model_handle)
b) BPU_runModelFromDDRWithConvertLayout
相较于BPU_runModelFromDDR需要用户自己对输入数据加padding对齐,接口BPU_runModelFromDDRWithConvertLayout则将这部分操作集成到了接口内部,方便的用户的使用,用户只需要将输入数据直接送入bpu进行运算即可。
1. ret = BPU_runModelFromDDRWithConvertLayout(bpu_handle, 2. model_name, 3. in_buffer.data(), 4. in_buffer.size(), 5. out_buffer.data(), 6. out_buffer.size(), 7. &model_handle);
2.3.4.3 编译选项-i resizer
这个选项主要用于后验证的场景,例如在检测阶段识别了行人,接着可以在下个阶段基于行人的检测框对行人的朝向进行识别,由于检测框的大小是任意的,而识别的模型输入是固定的,因此不能直接进行前向推理,而编译选项resizer会将图像的检测框resize到模型输入的尺寸,resize部分是由硬件执行,更加高效。-
BPU_runModelFromResizer封装了resize和模型执行的操作,更方便于用户的使用。
1. ret = BPU_runModelFromResizer(bpu_handle, 2. model_name, 3. pym_buffer, 4. bbox.data(), 5. bbox.size(), 6. &resizable_cnt, 7. out_buffer.data(), 8. out_buffer.size(), 9. &model_handle)
可以看到这个接口的输入是金字塔处理结果,通过BPUBBox变量参数指定roi进行resize,然后送入bpu参与前向运算,这里的roi必须是基于原图的roi,如果第一阶段检测框是源于非原图的金字塔层结果,则检测框结果也需要做相应的缩放。-
由于硬件resizer的缩放比例受到限制,因此接口在选取roi时不仅仅在原图上搜索,也会在金字塔的其他层上寻找合适的roi,如果最后依旧搜索不到,则当前输入的roi不会参与运算,参数resizable_cnt就是输入的检测框中能够做resize的数量,而结构体BPUBBox中有一个成员resizable,此roi成功被resize,则被赋值为true,反之为false,可通过这个字段判断那些box参与了模型前向推理。-
注意:由于BPU_runModelFromResizer接口可能会做多次模型运算,因此需要申请足够多的output buffer,数量应该是模型输出的节点个数与roi数量的乘积,并且部分的roi可能会失败,没有输出,那么成功跑模型的roi的结果会顺序存储在buffer中,剩余的buffer里没有结果,例如模型输出节点为n,输入的roi数量为a,能被resize的roi数量为b,则申请output buffer的数量应该为(n*a),执行结果会存在前(n*b)个buffer中,后(n*(a-b))个buffer没有实际结果。
2.3.5 多模型运行的资源分配控制
bpu-predict库中针对多个模型同时需要在bpu上运行的调度情况, 提供了对模型分组并对其BPU占用(双核)的比例进行限制的策略接口, 可用于限制不同模型对于BPU资源利用时间片的百分比. 若要启用该策略, 只需遵循以下步骤:
-
在bpu_config配置中将"engine_type"字段改为"group"类型, 例如:
- { 2. “core_engine”: “dual”, 3. “core_num_enable” : 2, 4. “engine_type” : “group”, 5. “debug” : 0 6. }
-
创建并将相应的模型添加到对应的组内, 并给该组分配对应的资源占用百分比
- int group1 = BPU_createGroup(); 2. int group_proportion = 80; 3. BPU_setModelGroup(bpu_handle, model_name1, group1); 4. BPU_setModelGroup(bpu_handle, model_name2, group1); 5. int ret = BPU_setGroupProportion(group1, group_proportion); 6. if (ret != 0) { 7. LOG(ERROR) << “set group proportion failed” << std::endl; 8. }
设置返回值为0则表示设置成功, 在一定时间内, 该组模型在BPU上运行的时间片占比不会超过相应的比例数值.
2.4 典型示例
本章节,将前面介绍的bpu_predict的接口串联起来,形成一些完整的应用示例。通过这些应用示例,我们可以学习了解如果用我们的api,来实现一个完整的应用,同时可以通过这些示例,来验证地平线芯片在各种公开测试集上,公版模型的性能。
2.4.1 代码结构
1. ├── CMakeLists.txt 2. ├── config 3. ├── include 4. │ ├── input 5. │ ├── output 6. │ ├── postprocess 7. │ └── utils 8. ├── protocol 9. │ ├── aarch64 10. │ ├── raw 11. │ └── x86 12. ├── sample 13. │ ├── det_cls_example.cc 14. │ ├── single_model_example.cc 15. │ └── validate.cc 16. └── src 17. ├── input 18. ├── output 19. ├── postprocess 20. └── utils
从如上结构可以看出,我们将整个工程分为了input, output 以及postprocess3部分,sample中我们提供了3个典型的示例,用来展示如何在不同场景下,进行流程搭建。
2.4.1.1 Input
input实现了bpu_io相关的数据输入功能,从外部(camera, network,静态图)读取图片,并放入到bpu的内存中(FakeImage, Pyramid),其基本结构如下:
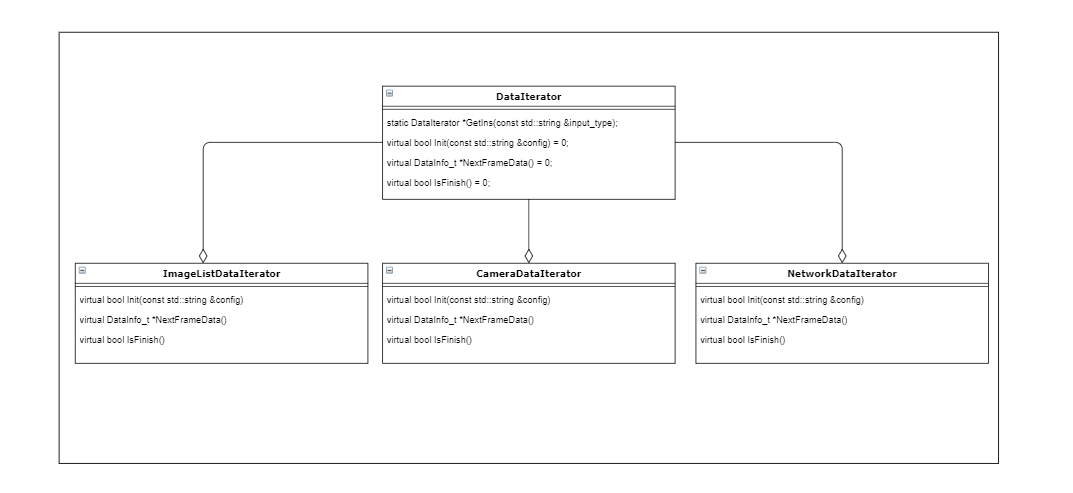
我们通过input_type,来决定使用哪种数据输入,同时每种输入的配置,在init接口中进行解析。每次调用NextFrameData, 则可以获取一帧图像。isFinish用来判断,当前数据源图像读取是否已经结束。
2.4.1.2 PostProcess
postprocess封装了模型执行后的结果的解析,不同结构的模型,有不同的解析方式。大部分模型都是按照公版模型通用的解析方式进行处理,部分模型地平线芯片做有特殊优化处理,具体在2.4.2章节介绍
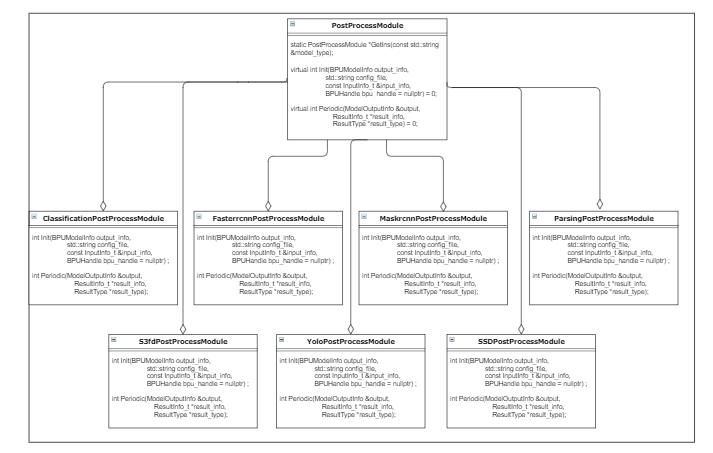
我们可以通过GetIns接口,通过模型名称,来获取到对应的模型处理实例,不同模型解析,需要不同的配置文件,通过Init函数,将配置文件传入实例中进行初始化,最后就可以通过Periodic接口,来进行各个模型推理后数据的解析
2.4.1.3 output
output封装了模型推理结果以及原始视频数据的处理,支持通过网络传输到client端进行展示,在本地渲染录制成视频或者jpg图片,也支持将模型推理结果按照指定结构记录为精度记录文件,已进行精度分析(4.2章节)
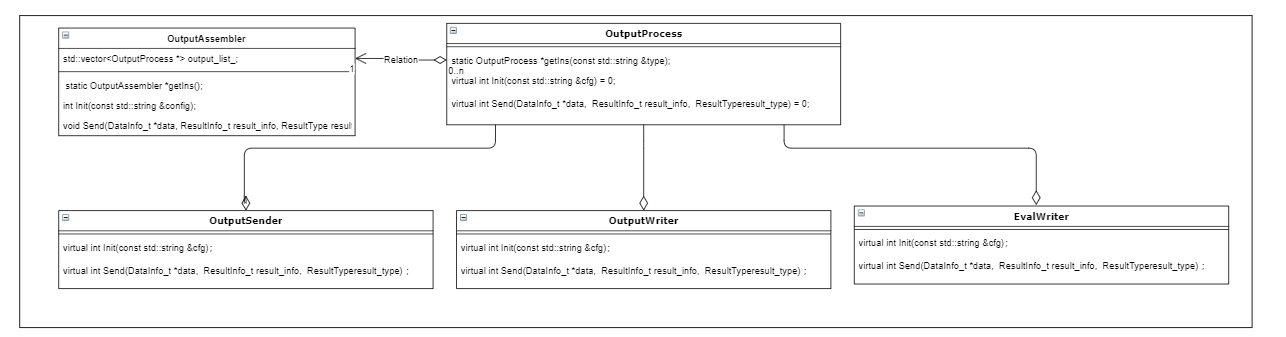
用户可以通过GetIns,来获取output的实体,而在Init的配置文件中,可以配置打开哪种能力,用户可以打开1种或者N种output。目前支持network发送至client端,写精度日志,写video,以及写jpeg文件四种output能力
2.4.1.4 sample
sample中我们实现了3个典型的示例,在main函数代码中,包含了完整调用bpu_predict进行数据准备,模型推理,结果解析的完整流程。
**single_model_example:**单模型示例,用来展示最简单的应用结构。同时可以用来测试各公版模型的性能和精度
det_cls_example: 检测+分类模型示例,展示多模型如何配合使用,用户可以通过多种模型的配置,构造出各种复杂的应用场景
validate-int8: 自定义输入示例,该示例展示如何直接在应用中,预置输入,通过RunFromDDR的方式,来直接跑模型,该示例适用于当前bpu_io接口,无法满足应用输入时使用,如音频检测等
2.4.2 特殊后处理
在2.4.1.2中,我们描述了我们后处理代码的组织方式,其中大部分后处理,都是通用的公版模型的后处理解析方式,这里特别说明其中几个特殊的后处理
2.4.2.1 fasterrcnn & maskrcnn
在fasterrcnn和maskrcnn中,我们经过内部优化,可以直接在BPU中进行检测框的解析,直接调用接口,即可解析出具体的检测框,而不需要在后处理中,再做复杂的计算:
1. BPURppBBox rpp_bbox; 2. int ret = BPU_parseRPPResult(bpu_handle_, model_name_.c_str(), &output[0], 1, &rpp_bbox);
2.4.2.2 yolo & ssd & s3fd
在这些后处理中,我们使用exptable来替代exp指数计算,用查表的方式代替计算过程,以提高计算性能。具体exptable的值,可以在src/utils/exptable.cc中看到
2.4.2.3 parsing
parsing模型的输出已经做了像素类别间argmax的处理,所以可以直接读取图像分割的结果。
3. 应用开发
这部分还在开发当中, 我们将会在不久之后对该部分内容进行更多的补充
3.1 框架说明
简单介绍应用框架,具体链接框架介绍页面
3.2 工程迁入框架
将2.4 典型示例进行封装,告诉用户如何从裸工程,迁移到应用框架
3.3 典型demo
基于场景的典型demo,如识别机,车辆视频结构化代码结构说明
4. 模型支持
如我们在第1章节所写,我们将整个example源码,编译打包后,存放入了4_tools目录,并在改目录预置了大量脚本,用以帮助用户快速验证我们芯片和模型的能力
1. ├── 4_tools 2. │ ├── aarch64 3. │ │ ├── bin 4. │ │ └── libs 5. │ ├── accuracy 6. │ │ ├── python 7. │ │ └── shell 8. │ ├── config 9. │ │ ├── bpu 10. │ │ ├── input 11. │ │ ├── log 12. │ │ ├── model 13. │ │ └── output 14. │ ├── demo 15. │ │ ├── 2.2_det_example 16. │ │ ├── 2.3_api_example 17. │ │ └── 2.4_hr_example 18. │ ├── performance 19. │ └── x86 20. │ ├── bin 21. │ └── libs
aarch64: 在地平线芯片真机上运行的可执行程序以及依赖库,目前支持96broad, x2, j2, mono, quad等机型
x86: 在centos上,以模拟器方式运行的测试程序,以及依赖库
config: 配置文件目录,其中预置了大量已经通过验证的,各种模型,各种输入源的配置,方便用户直接使用
demo: 功能性脚本,内置大量各种公版模型在不同输入源,不同输入尺寸下的完整运行例子,可以在client端快速查看运行效果
**performance:**性能测试脚本,预置配置了当前已经验证过的公版模型的性能测试程序配置,以及最终的性能计算配置
**accuracy:**精度测试脚本,预置了精度测试时程序执行的配置,以及最终精度计算的脚本
4.1 功能测试
在demo目录中,我们提供了部分公版模型的在各种典型输入下的执行脚本,支持列表如下:

在启动其中某一个示例时,可以通过配置client的IP地址,实时查看该部分示例实时展示效果
4.2 精度测试
在accuracy目录中,我们提供了2个子目录。
shell目录为各个模型在精度测试模式下的启动脚本
python目录包含程序完成后,进行精度计算的脚本,以及发送图片数据,到精度测试进行的send_tools
由于精度测试时,数据集较大,一般的测试步骤为:
1. 启动精度测试目录下的模型启动脚本
2. 将send_tools放在精度测试数据集下,按照脚本提示,发送精度测试图片
3. 在精度测试完成后,会自动在运行目录下,生成eval.log的精度日志(路径可在config/output/output_config.json中配置)
4. 使用python目录中对应的精度计算脚本,对eval.log,以及精度数据集的GT数据,进行精度计算
4.3 性能测试
在performance目录中,我们提供了大量脚本,来进行各个模型的性能测试。由于目前示例中,都是以单帧同步的方式在执行测试,所以当前性能数据,是根据单帧执行时间,计算整体性能
性能测试的一般步骤为:
1. 通过perf.sh脚本,启动实际应用脚本
2. 在脚本稳定运行一段时间后(5分钟左右), 手动停止程序
3. perf.sh脚本在程序停止后,会将性能分析报告,导入到 /userdata/目录下的实时log文件中-
我们在了解了代码结构之后, 有助于我们根据自身需求, 进行相应的个性化改动及验证, 在对代码整体结构有了大致了解后, 我们下面将会教大家如何将之前我们得到的模型文件上板运行, 敬请期待.