提升量化精度、降低量化损失是量化转换工具的一大关键点,也是一个难点。以下将对我们在实际使用中所遇到的精度问题进行一些说明,提供给大家一些分析思路。
以我们的 mobilenet sample(samples/03_classification/01_mobilenet/)为例,我们在运行 sh 03_build.sh 脚本成功转换模型后,会在该路径下生成 model_output 文件夹,保存各阶段的模型产出(详细说明可参考浮点转换工具链文档5.1节):
- *_original_float_model.onnx:解析 caffe 浮点模型后生成的 onnx 模型,与原模型完全等价(若原浮点模型为 onnx 模型,则不生成);
- *_optimized_float_model.onnx:对 1 中模型进行一些预处理操作(算子融合、等效替换等)后生成的中间模型,便于后续的校准和量化操作;
- *_quantized_model.onnx:基于 2 中模型校准后生成的量化模型;
- *_hybrid_horizonrt.bin:基于 3 中量化模型编译后生成的混合模型,可直接上板或在模拟器中运行。
模型转换成功后,我们一般会通过以下几种方法来进行精度评估或验证:
- 基于 mapper/04_inference.sh 脚本和 *_quantized_model.onnx 去做单张或多张图片的 infer,查看推理结果的置信度、准确性或可视化效果等;
- 基于 mapper/05_evaluate.sh 脚本和 *_quantized_model.onnx 去做小批量或完整测试集的精度验证,并与浮点模型精度进行比较;
- 基于 runtime_arm(板端)/runtime_sim(模拟器)路径下的相关脚本和 *_hybrid_horizonrt.bin 模型,同1、2一样,直接在板端或模拟器中进行 infer 或 eval。
一般来说,用户自己都会有浮点模型的精度指标,如果没有也可基于我们的示例代码进行部分改写,如 samples/03_classification/cls_inference(evaluate).py,以运行 *_original_float_model.onnx 模型的推理自行测试。
不过以上 3 种方法均是对模型进行端到端的算法指标评测,依赖用户自己实现模型推理的输入预处理及后处理逻辑的代码,但更能在业务模型指标上反映量化损失的程度。
对于预处理,我们在工具链中提供了不少的 transformer 函数以方便用户的快速调用。
对于后处理,分类模型一般仅为 Softmax 逻辑,可基于我们的示例代码进行简单实现;而检测、分割、识别等模型的实现可能就需要花些功夫了。
那么是否有一些简单的方法能辅助我们进行一些定性分析呢?目前地平线的浮点转换工具链提供了以下 2 种方案思路:
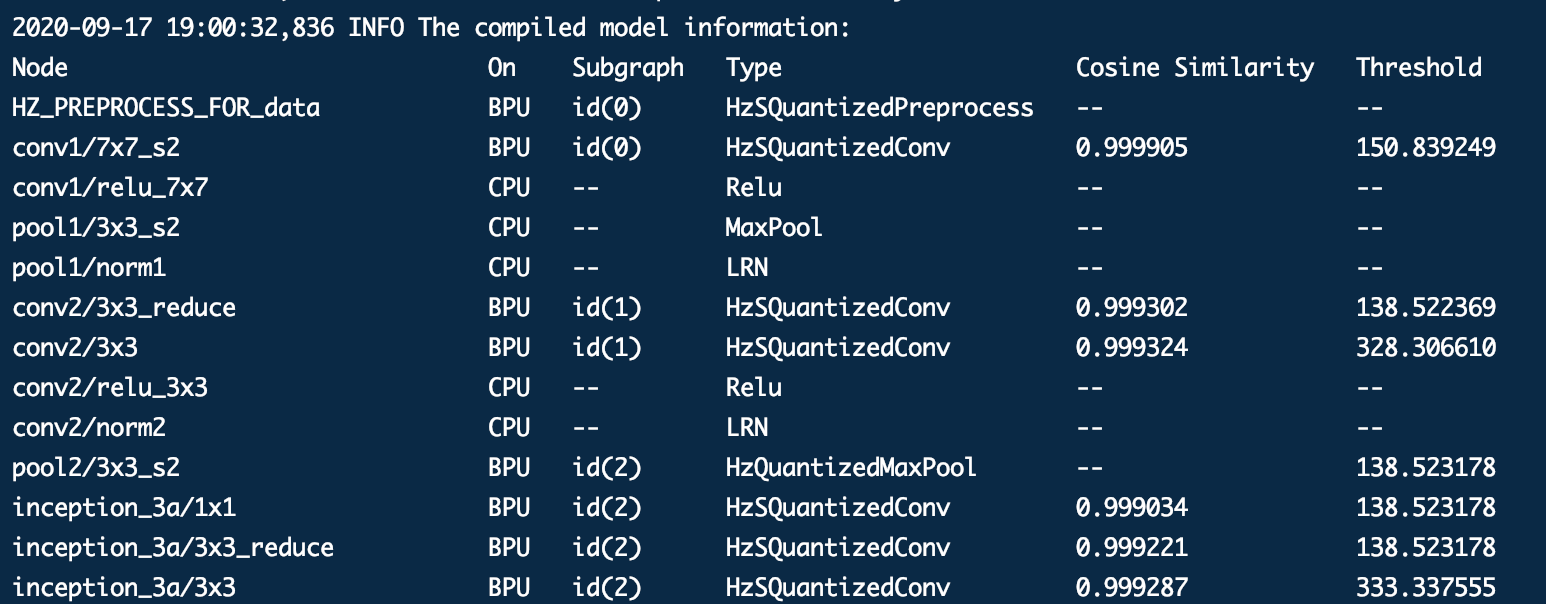
- 方案1:以下图 GoogleNet 为例,基于 1.1.16 及以后版本,我们在模型量化转换成功后,会在终端打印(也会保存在转换 log 文件中,方便以后查看)float 和 quanti 模型每一层卷积算子量化前后的向量余弦相似度。一般来说如果相似度低于 0.99,即反映了模型量化存在一定损失;如果相似度低于 0.8,那基本可以代表量化失败。
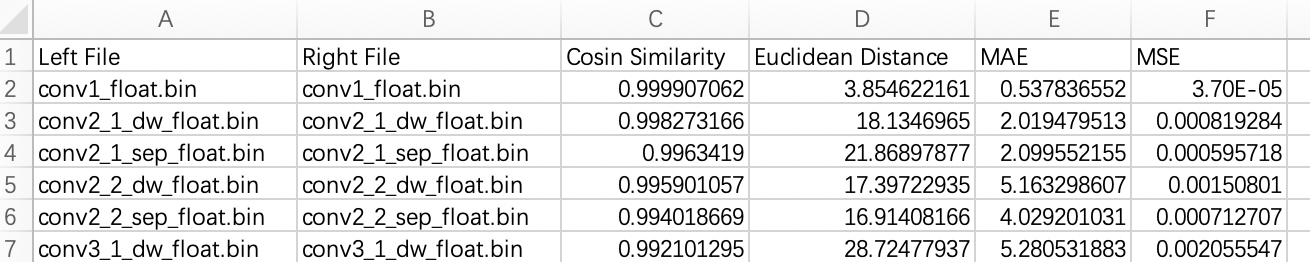
- 方案2:在 samples/05_miscellaneous/03_vector_diff 目录下,地平线还提供了一套向量比对工具。其基本思路与 方案1 相同,即针对模型转换过程中生成的浮点模型(float.onnx)、量化模型(quanti.onnx)以及异构混合模型(hybrid.bin)分别进行推理,并利用 vec_diff 工具来比对各个环节模型的卷积算子的向量相似度来判断是否存在量化损失。工具产出为 csv 文件,如下图所示。相比于 方案1,该方案不仅覆盖了量化的精度损失,还覆盖了异构模型编译优化过程中带来的精度损失。
如果您通过上述方案判断出模型的精度存在掉点问题,那么可以通过以下几条思路来分析和定位:
- 思路1: 排查模型预处理逻辑的正确性,具体包括:
- 确认 yaml 文件中的 input_type_rt、input_type_train、mean、scale 参数;
- 确认 mapper/02_preprocess.sh 脚本依赖的 data_preprocess.py 文件里调用的读图函数是 skimage.io.imread 还是 cv2.imread,这两个库函数读图后的 layout、数值区间均不同。需注意,目前在我们的 sample 中,分类模型示例调用的是 skimage.io.imread,而检测模型示例调用的是 cv2.imread;
- 确认 data_transformer.py 里调用的 transformer,包括基于 2 中所说的读图函数所需的 Transpose 或 ChannelSwap,以及 Resize,Crop,Padding 等。
- 思路2: 排查量化校准数据集的设置,包括:
- 校准图片数量是否满足 20~50 张要求(一般情况下);
- 校准图片是否能够覆盖典型场景,请不要包含过曝、饱和、模糊、纯黑、纯白等图片;
- 对于已经预处理好的校准集,其预处理方式是否正确(即思路1)。
- 思路3: 排查后处理逻辑的正确性。
如果经过上述检查后,基本可以排除因某环节 bug 导致的大幅精度损失,此时精度若仍存在问题,一般也在 0.9*浮点指标及以上。对于量化本身导致的精度损失,我们可以通过以下方式尝试精度优化:
-
方法1: 调整 calibration_type 量化校准算法(yaml中配置),工具链目前支持 kl、max 两种,可通过实验判断哪一种校准算法效果更好。
-
方法2: 如果默认的 kl 或 max 的校准方法均效果一般,那么可以尝试 promoter 优化手段,即在 yaml 中通过 promoter_level 参数控制不同的优化等级来收敛量化精度。
-
方法3: 基于 vec_diff 或者量化转换中生成的相似度数据,联系地平线工程师进行协助分析和解决。
- 首先,我们可以根据相似度数据去分析是否为某一个或某些算子的量化存在问题(例如相似度突然降低),来进行针对性的优化;
- 其次,我们还有一些未对外发布的校准或调优方法,可提供进行测试,具体情况可联系地平线工程师进行了解。
最后,祝你们的模型一次转换成功!!?