0 概述
将transformer结构应用于CV领域已成为业内常用的手段,传统transformer被更广泛目标检测任务,对于分割等场景则并不“擅长”。Swin-T的出现给计算机视觉领域提供了可广泛应用的backbone,基于窗口的注意力相比于全局更小巧,灵活。本文为在ImageNet数据集下对地平线的Swin-T算法的介绍和使用说明。
该示例为参考算法,仅作为在J5上模型部署的设计参考,非量产算法
1 性能精度指标
| model | dataset | accuracy-float | accuracy-quantization | 帧率(J5/双核) |
|---|---|---|---|---|
| Swin-T | ImageNet | 80.24 | 79.97 | 133 |
2 改动点说明
- patch_embedding阶段公版为patch_embed+flatten+transpose+LN,horizon_swin-t为patch_embed+LN,保持feature为(B,C,H,W)
- linear均替换为conv2d实现,实现BPU加速
- 使用地平线内部实现的LayerNorm替换torch.nn.LayerNorm,减少reshape算子的使用,从而提升模型fps 性能
- patch_merging阶段输出feature的shape为(B,C,H,W),无需reshape
3 模型介绍
3.1 模型结构
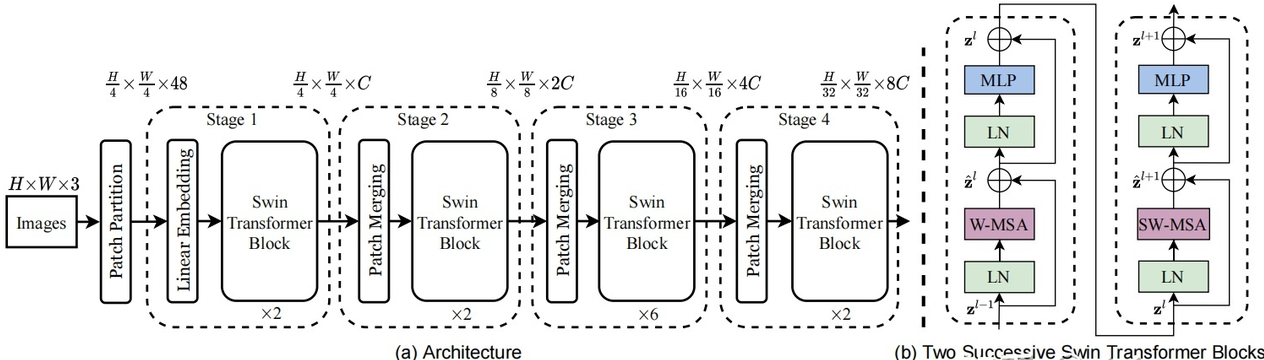
3.2 源码说明
3.2.1 Config文件
configs/classification/horizon_swin_transformer_imagenet.py 为 swin-t的配置文件,定义了模型结构、数据集加载,和整套训练流程,所需参数的说明在算子定义中会给出。配置文件主要内容包括:
#基础参数配置
task_name = "horizon_swin_transformer_cls"
num_classes = 1000
batch_size_per_gpu = 64
device_ids = [0, 1, 2, 3]
#模型参数配置
image_shape = (3, 224, 224)
# 模型结构定义
model = dict(
type="Classifier",
backbone=dict(
type="HorizonSwinTransformer",
depth_list=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
drop_path_ratio=0.2,
),
losses=dict(type="SoftTargetCrossEntropy"),
)
deploy_model = dict(
...
)
deploy_inputs = dict(img=torch.randn((1, 3, 224, 224)))
# 数据加载
data_loader = dict(
type=torch.utils.data.DataLoader,
...
)
val_data_loader = dict(...)
#不同step的训练策略配置
float_trainer=dict(...)
calibration_trainer = dict(...) #数据校准
qat_trainer=dict(...)
int_infer_trainer=dict(...)
#不同step的验证
float_predictor=dict(...)
qat_predictor=dict(...)
int_infer_predictor=dict(...)
#编译配置
compile_cfg = dict(
march=march,
...
)
3.2.2 Patch Embedding
该模块主要将输入的图片等分小patch,每m个像素为一个patch。划分patch和embedding使用conv2D实现。默认kernel=stride=patch_size=4,embedding_dims为96,不可整除patch_size则pad 0。
self.patch_embedding = PatchEmbedding4d(
patch_size=patch_size,
in_channels=in_channels,
embedding_dims=embedding_dims,
norm_layer=LayerNorm2d if patch_norm else None,#plugin LayerNorm2d
)
添加dropout
self.pos_drop = nn.Dropout2d(p=dropout_ratio) # B x C x H x W
3.2.3 Swin Transformer Block
SwinBasicLayer4d 由以下4部分构成:LN,MLP,W-MSA,SW-MSA,其中每一个stage的depth为[2, 2, 6, 2];num_heads为[3, 6, 12, 24]。
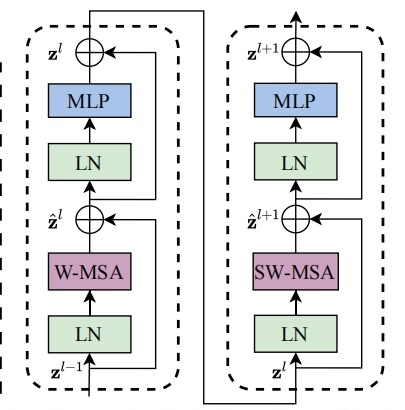
3.2.3.1 LN
LN层为LayerNorm,horizon-swin-t的实现为plugin实现:
x = self.norm1(x) # B, C, H, W
self.layer_norm = horizon.nn.LayerNorm(
normalized_shape, eps, elementwise_affine, device, dtype, 1
)
3.2.3.2 W-MSA
Window based-multi-head Attention,即在窗口内做注意力机制。相比于全局注意力,Swin Transformer则将注意力的计算限制在每个窗口内,主要结构包含window_partition 、WindowAttention、Window_Reverse。
window_partition 窗口分割
根据window_size将输入划分,即(B, H, W, C)-->(num_windows*B, window_size, window_size, C),对应代码:horizon_plugin_pytorch/nn/quantized/functional_impl.py
x_windows = horizon_wp(
shifted_x, self.window_size
) # nW*B, window_size, window_size, C
def _window_partition(x: Tensor, window_size: int):
B, H, W, C = x.shape
x = x.view(
B, H // window_size, window_size, W // window_size, window_size, C
)
windows = (
x.permute(0, 1, 3, 2, 4, 5)
.contiguous()
.view(-1, window_size, window_size, C)
)
return windows
WindowAttention
窗口内的注意力机制为transformer机制,使用多头注意力,结构如下:
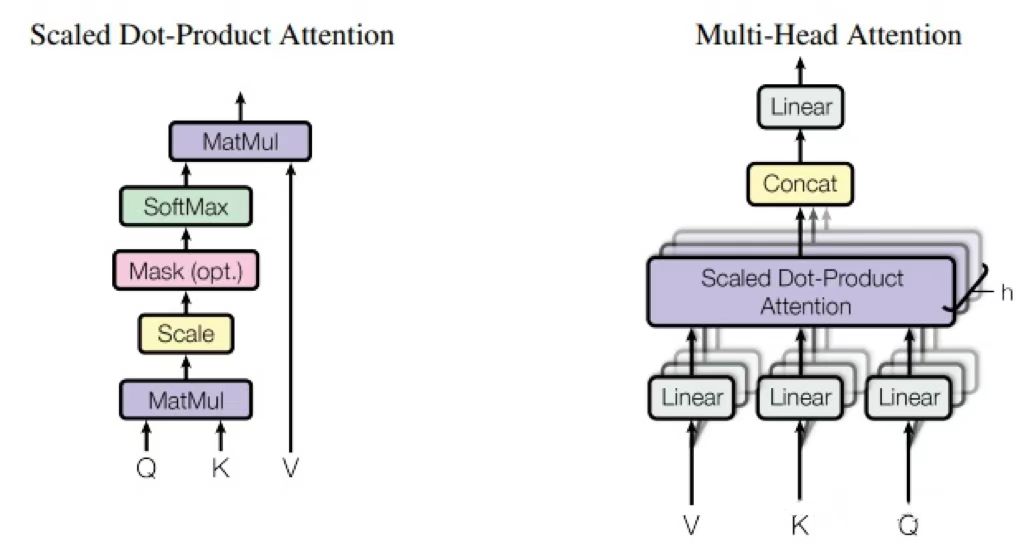
窗口内的attention计算,对应代码:hat/models/base_modules/basic_horizon_swin_module.py
#WSA的mask为None
attn_windows = self.attn( #WindowAttention4d
x_windows, mask=attn_mask
)
class WindowAttention4d(nn.Module):
def __init__(
self,
...
):
super().__init__()
...
self.qkv = nn.Conv2d(dim, dim * 3, 1, bias=qkv_bias)
self.attention_drop = nn.Dropout2d(attention_drop_ratio)
self.proj = nn.Conv2d(dim, dim, 1)
self.proj_drop = nn.Dropout2d(proj_drop_ratio)
...
def forward(self, x, mask=None):
B, C, H, W = torch.tensor(x.shape).numpy()
N = H * W
qkv = self.qkv(x)
# new 4dims
qkv = qkv.permute(0, 2, 3, 1) # BxHxWx3C
q, k, v = qkv[..., :C], qkv[..., C : C * 2], qkv[..., C * 2 :] # BHWC
q = q.reshape(B, H * W, self.num_heads, C // self.num_heads)
q = q.permute(0, 2, 1, 3)
k = k.reshape(B, H * W, self.num_heads, C // self.num_heads)
k = k.permute(0, 2, 1, 3)
v = v.reshape(B, H * W, self.num_heads, C // self.num_heads)
v = v.permute(0, 2, 1, 3)
# q = q * self.scale
# attention = (q @ k)
scale = self.scale_quant(self.scale)
q = self.mul.mul(q, scale)
attention = self.matmul.matmul(q, k, x_trans=False, y_trans=True)
# attention = attention + relative_position_bias
relative_position_bias = self.quant(self.relative_position_bias)
attention = self.add.add(attention, relative_position_bias)
...
attention = self.softmax(attention)
attention = self.attention_drop(attention)
# x = (attention @ v)
x = self.attn_matmul.matmul(attention, v)
...
x = self.proj(x) #nn.Conv2d(dim, dim, 1)
x = self.proj_drop(x)
return x
Window_Reverse
使用horizon_wr将多个窗口的特征提取值合入一个layer输出。即(num_windows*B, window_size, window_size, C)-->(B, H, W, C)。
shifted_x = horizon_wr(
attn_windows, self.window_size, Hp, Wp
) # B H' W' C
内部实现为:horizon_plugin_pytorch/nn/quantized/functional_impl.py
def _window_reverse(windows: Tensor, window_size: int, H: int, W: int):
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(
B, H // window_size, W // window_size, window_size, window_size, -1
)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
3.2.3.3 FFN
该层由MLP和layernorm构成,layernorm为LayerNorm2d([dim, 1, 1]),MPL为fc+激活+fc:
x = self.add.add(shortcut, self.drop_path(x))
x = self.add2.add(x, self.drop_path(self.mlp(self.norm2(x))))
fc1 = nn.Conv2d(in_channels, hidden_channels, 1)
fc2 = nn.Conv2d(hidden_channels, out_channels, 1)
layer_list = [fc1, act_layer, drop1, fc2, drop2]
3.2.3.4 SW-MSA
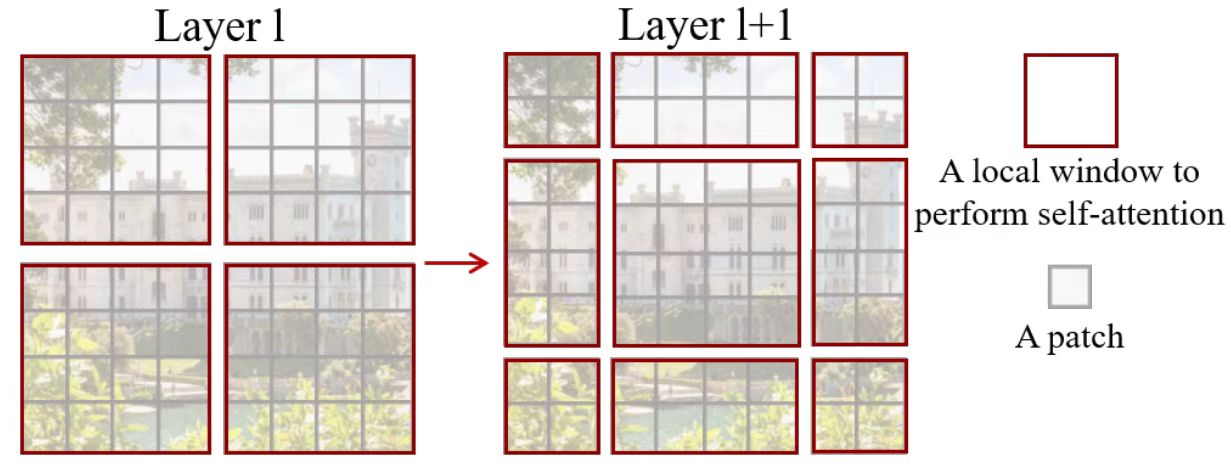
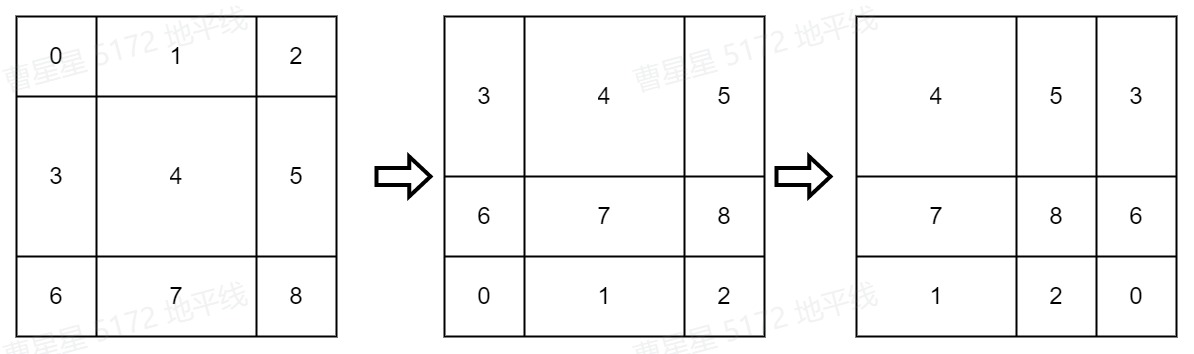
SW-MSA相较于W-MSA不同于在SW-MSA在window_partition前会做窗口移动(cyclic shift)操作,同时在做attention时会add attention mask,最后在Window_Reverse后做reverse cyclic shift操作,把数据挪回到原来的位置上。整体流程如下图:
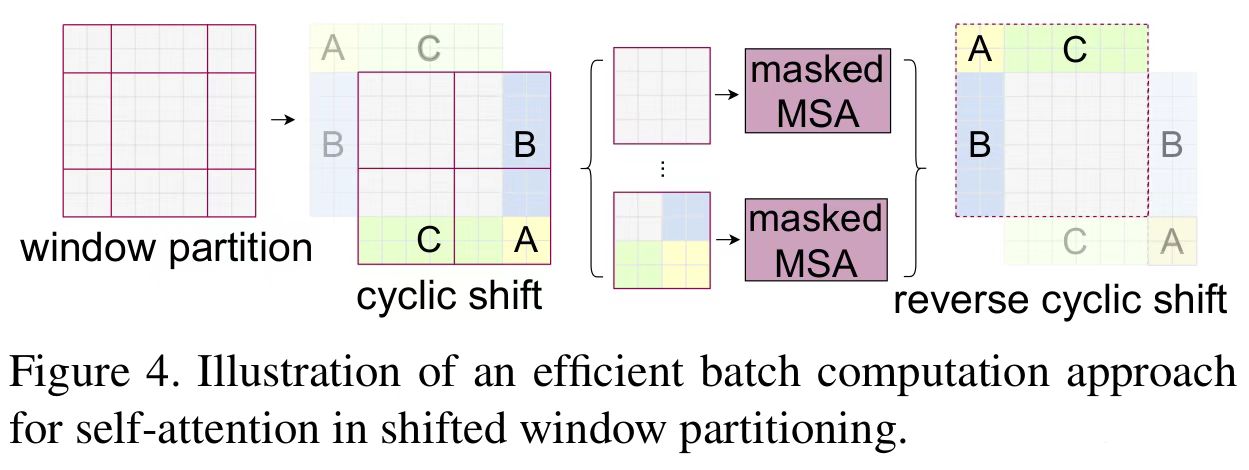
窗口下移 cyclic shift
如下图所示,左边的4个窗口(红色区域)向右下方移动1/2 window_size后构成右图。经过窗口移动后4个window被划分为9个window,且窗口的大小不一。
经过cyclic window后窗口中会融入了不相干的patch,因此在做注意力计算时会生成attention mask 用于标记该区域是否为同一patch,生成attention_mask的过程如下图:
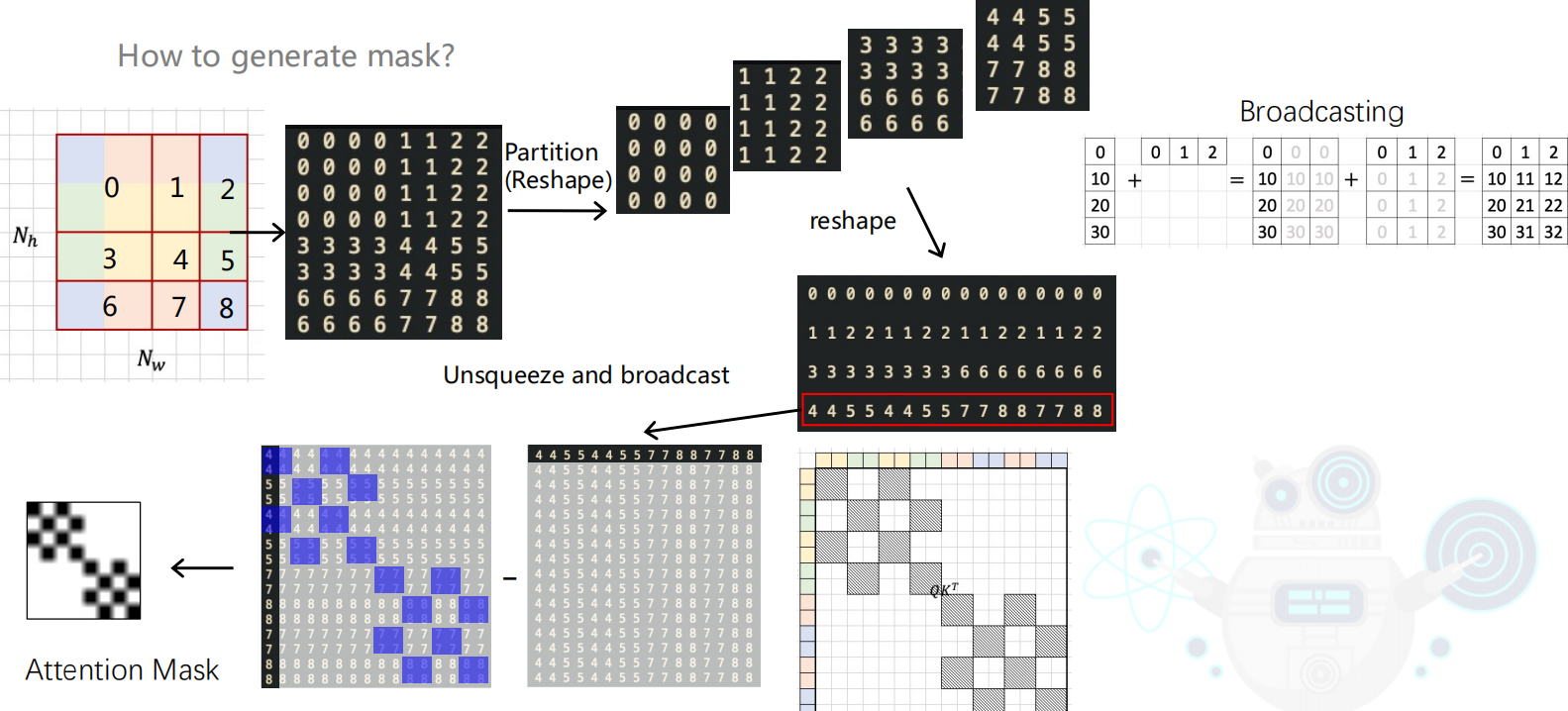
attn_mask生成对应代码:
if self.shift_size > 0:
...
img_mask = torch.zeros(
(1, 1, Hp, Wp), device=x.device
) # 1 1 Hp Wp
...
mask_windows = horizon_wp(img_mask, self.window_size)
mask_windows = mask_windows.permute(0, 3, 1, 2)
mask_windows = mask_windows.view(
-1, self.window_size * self.window_size
)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(
attn_mask != 0, float(-100.0)
).masked_fill(attn_mask == 0, float(0.0))
attn_mask = attn_mask.unsqueeze(1)
else:
attn_mask = None
在计算窗口内的attentation时,在softmax前会add attn_mask ,使不相干的区域经过softmax后得分为0。
nW = torch.tensor(mask.shape[0]).numpy()
mask = mask.repeat(B // nW, 1, 1, 1)
# attention = attention + mask
attention = self.mask_add.add(attention, mask)
attention = attention.permute(0, 3, 1, 2)
attention = self.softmax(attention)
attention = attention.permute(0, 2, 3, 1)
reverse cyclic shift
将平移后的“窗口”恢复位置,将图片的patch往右和往下各自滑动半个窗口大小的步长。
x = torch.roll(
shifted_x,
shifts=(self.shift_size, self.shift_size),
dims=(2, 3),
)
3.2.4 patch Merging
Patch Merging的操作非常像池化,不同于池化的小窗口取最大值或平均值,Patch Merging把每个小窗口中相同位置的值取出来,拼成新的patch,再把所有patch都concat起来。具体过程见下图:
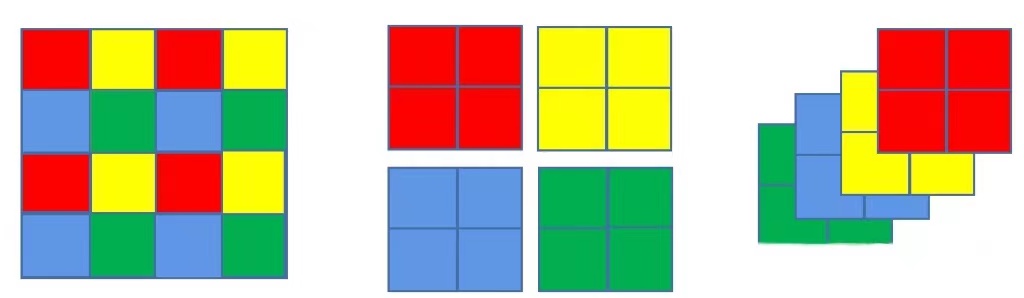
在horizon_swin transformer中,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍,每个stage的降低分辨率的过程都是通过Patch Merging实现的。对应代码段:
# patch merging layer
if downsample is not None:
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
downsample内部实现为PatchMerging4d ,对应代码:
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
x = F.pad(x, (0, W % 2, 0, H % 2))
x0 = x[:, :, 0::2, :][:, :, :, 0::2] # B C H/2 W/2
x1 = x[:, :, 1:A:2, :][:, :, :, 0::2] # B C H/2 W/2
x2 = x[:, :, 0::2, :][:, :, :, 1::2] # B C H/2 W/2
x3 = x[:, :, 1::2, :][:, :, :, 1::2] # B C H/2 W/2
x = self.cat.cat([x0, x1, x2, x3], 1) # B 4*C H/2 W/2
4 浮点模型训练
4.1 Before Start
4.1.1 环境部署
swin-t示例集成在OE包中,获取方式见:J5芯片算法工具链OpenExplorer 版本发布
swin-t示例位于ddk/samples/ai_toolchain/horizon_model_train_sample下,其结构为:
└── horizon_model_train_sample
├── scripts
├── configs #配置文件
`── tools #工具及运行脚本
release_models获取路径见:horizon_model_train_sample/scripts/configs/classification/README.md
拉取docker环境
docker pull openexplorer/ai_toolchain_ubuntu_20_j5_gpu: {version}
#启动容器,具体参数可根据实际需求配置
#-v 用于将本地的路径挂载到 docker 路径下
nvidia-docker run -it --shm-size="15g" -v `pwd`:/open_explorer openexplorer/ai_toolchain_ubuntu_20_j5_gpu: {version}
如需本地离线安装HAT,我们提供了训练环境的whl包,路径在ddk/package/host/ai_toolchain
4.1.2 数据打包
在 tools/datasets 目录下提供了 cityscapes 、 imagenet 、 voc、 mscoco 常见数据集的打包脚本。例如 imagenet2lmdb 的脚本,可以利用torchvision 提供的默认公开数据集处理方法直接将原始的公开 ImageNet 数据集转成 Numpy 或者 Tensor 的格式,最后将得到的数据统一用 msgpack的方法压缩到 LMDB 的文件中。可以通过下面的脚本完成数据集打包:
#pack train_Set
python3 tools/datasets/imagenet_packer.py --src-data-dir ${src-data-dir} --target-data-dir ${target-data-dir} --split-name train --num-workers 10 --pack-type lmdb
#pack test_Set
python3 tools/datasets/imagenet_packer.py --src-data-dir ${src-data-dir} --target-data-dir ${target-data-dir} --split-name train --num-workers 10 --pack-type lmdb
train_lmdb 和 val_lmdb 就是打包之后的训练数据集和验证数据集,也是网络最终读取的数据集。
4.1.3 config 配置
在进行模型训练和验证之前,需要对configs文件中的部分参数进行配置,一般情况下,我们需要配置以下参数:
- device_ids、batch_size_per_gpu:根据实际硬件配置进行device_ids和每个gpu的batchsize的配置;
- ckpt_dir:浮点、calib、量化训练的权重路径配置,权重下载链接在config文件夹下的README中
- dataloader、qat_data_loader参数组中的data_path:为打包过程的输出-train_lmdb
- val_data_loader参数组中的data_path:为打包过程的输出-val_lmdb
4.2 浮点模型训练
在configs/classification/horizon_swin_transformer_imagenet.py下配置参数,需要将相关硬件配置和数据集路径配置修改后使用以下命令训练浮点模型:
python3 tools/train.py --stage float --config configs/classification/horizon_swin_transformer_imagenet.py
4.3 浮点模型验证
通过指定训好的float_checkpoint_path,使用以下命令验证已经训练好的模型精度:
python3 tools/predict.py --stage float --config configs/classification/horizon_swin_transformer_imagenet.py
5 模型量化和编译
模型上板前需要将模型编译为.hbm文件, 可以使用compile的工具用来将量化模型编译成可以上板运行的hbm文件,因此首先需要将浮点模型量化,地平线对swin-t模型的量化采用horizon_plugin框架,通过QAT量化训练和转换最终获得定点模型。
5.1 Calibration
为加速QAT训练收敛和获得最优量化精度,建议在QAT之前做calibration,其过程为通过batchsize个样本初始化量化参数,为QAT的量化训练提供一个更好的初始化参数,和浮点训练的方式一样,将checkpoint_path指定为训好的浮点权重路径。
通过运行下面的脚本就可以开启模型的Calibration:
python3 tools/train.py --stage calibration --config configs/classification/horizon_swin_transformer_imagenet.py
5.2 Calibration 精度验证
calibration完成以后,可以使用以下命令验证经过calib后模型的精度:
python3 tools/predict.py --config configs/classification/horizon_swin_transformer_imagenet.py --stage calibration
验证完成后,会在终端输出calib模型在验证集上的检测精度。
5.3 量化模型训练
Calibration完成后,就可以加载calib权重开启模型的量化训练。 量化训练其实是在浮点训练基础上的finetue,具体配置信息在config的qat_trainer中定义。量化训练的时候,初始学习率设置为浮点训练的十分之一,训练的epoch次数也大大减少。和浮点训练的方式一样,将checkpoint_path指定为训好的calibration权重路径。
通过运行下面的脚本就可以开启模型的qat训练:
python3 tools/train.py --stage qat --config configs/classification/horizon_swin_transformer_imagenet.py
5.4 量化模型验证
量化模型的精度验证,只需要运行以下命令:
#qat模型精度验证
python3 tools/predict.py --stage qat--config configs/classification/horizon_swin_transformer_imagenet.py
#quantize模型精度验证
python3 tools/predict.py --stage int_infer --config configs/classification/horizon_swin_transformer_imagenet.py
qat模型的精度验证对象为插入伪量化节点后的模型(float32);quantize模型的精度验证对象为定点模型(int8),验证的精度是最终的int8模型的真正精度,这两个精度应该是十分接近的。
5.5 仿真上板精度验证
除了上述模型验证之外,我们还提供和上板完全一致的精度验证方法,可以通过下面的方式完成:
python3 tools/align_bpu_validation.py --config configs/classification/horizon_swin_transformer_imagenet.py
5.6 量化模型编译
在训练完成之后,可以使用compile的工具用来将量化模型编译成可以上板运行的hbm文件,同时该工具也能预估在BPU上的运行性能,可以采用以下脚本:
python3 tools/compile_perf.py --config configs/classification/horizon_swin_transformer_imagenet.py --out-dir ./ --opt 3
opt为优化等级,取值范围为0~3,数字越大优化等级越高,运行时间越长;
compile_perf脚本将生成.html文件和.hbm文件(compile文件目录下),.html文件为BPU上的运行性能,.hbm文件为上板实测文件。
6 其他工具
6.1 结果可视化
如果你希望可以看到训练出来的模型对于单帧的检测效果,我们的tools文件夹下面同样提供了点云预测及可视化的脚本,你只需要运行以下脚本即可:
python3 tools/infer.py --config configs/classification/horizon_swin_transformer_imagenet.py --save_path ./
需在config文件中配置infer_cfg字段。
7 板端部署
7.1 上板性能实测
使用hrt_model_exec perf工具将生成的.hbm文件上板做BPU性能实测,hrt_model_exec perf参数如下:
hrt_model_exec perf --model_file {model}.hbm \
--thread_num 8 \
--frame_count 2000 \
--core_id 0 \
--profile_path '.'
7.2 AI Benchmark示例
OE开发包中提供了swin-t的AI Benchmark示例,位于:ddk/samples/ai_benchmark/j5/qat/script/classification/swint,具体使用可以参考开发者社区J5算法工具链产品手册-AIBenchmark评测示例
可在板端使用以下命令执行做模型评测:
#性能数据
sh fps.sh
#单帧延迟数据
sh latency.sh
运行后会在终端打印出fps和latency数据。如果要进行精度评测,请参考开发者社区J5算法工具链产品手册-AIBenchmark示例精度评测 进行数据的准备和模型的推理。
相关链接:
地平线swin-t参考算法FAQ
如何让Transformer在征程5上跑得既快又好?以SwinT部署为例的优化探索