1.硬件获取渠道:网上购买
2.当前系统镜像版本:x3pi_ubuntu_server_disk_20221201201422
3.问题定位:
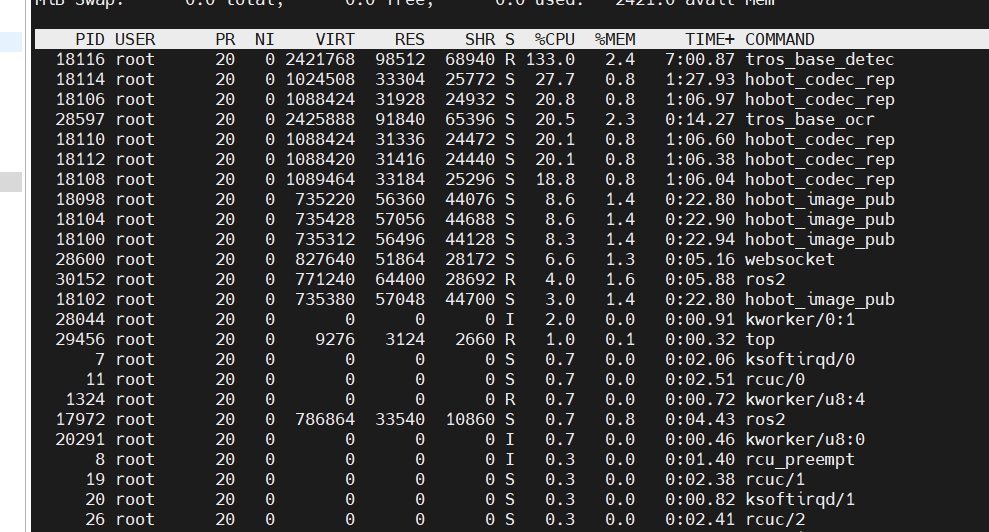
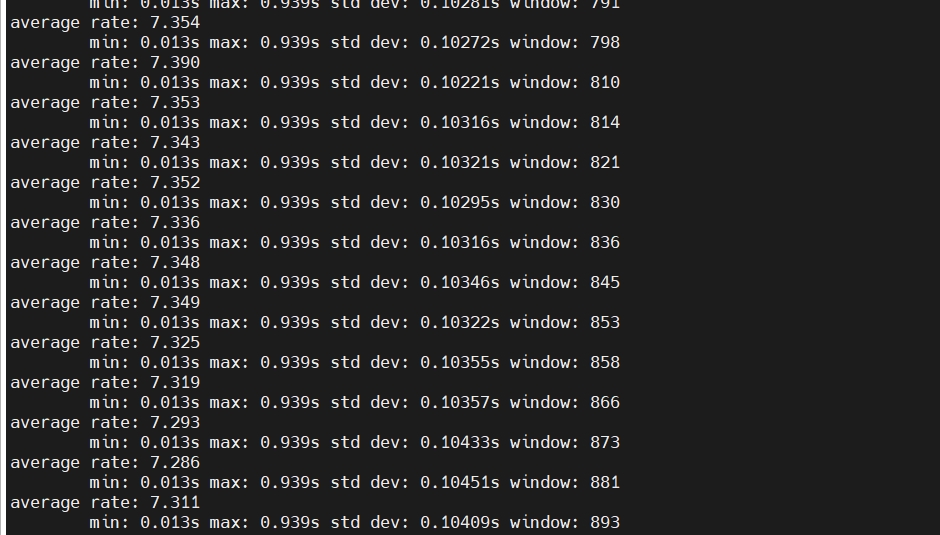
上游检测模型,在代码内定义4路视频顺序推理,fps每个在7.3左右,如下图:
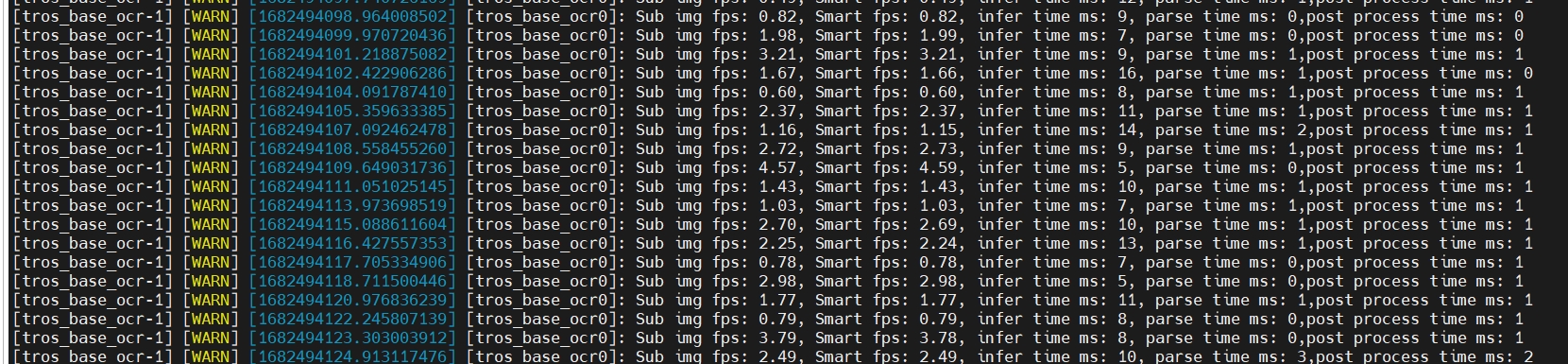
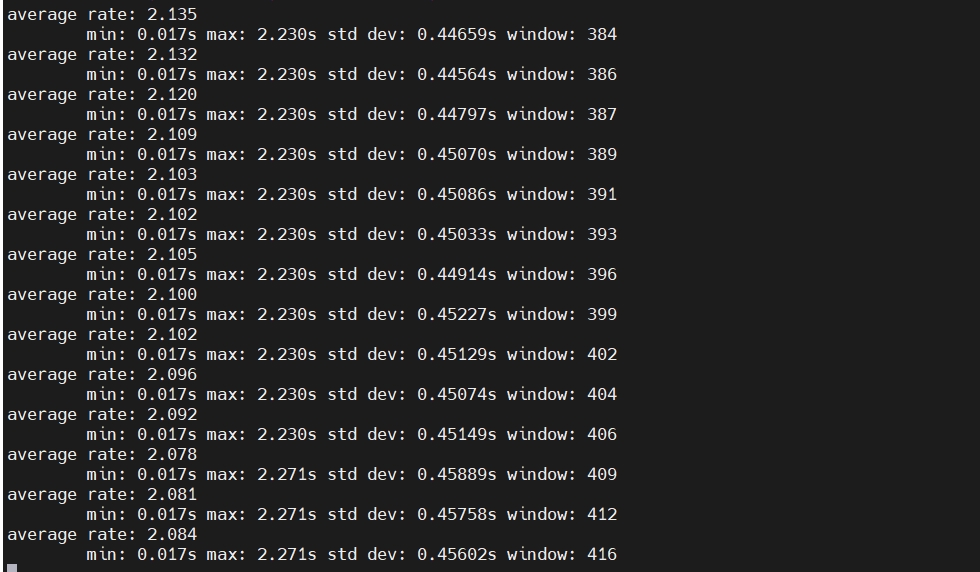
但是,在下游ocr模型接受单路aimsg流时,fps降低为2左右,不知道是什么情况(后尝试上游模型顺序推两路检测, 下游接受一路aimsg,发现上游每路fps在13左右, 下游ocr fps在4.7左右),如下图:
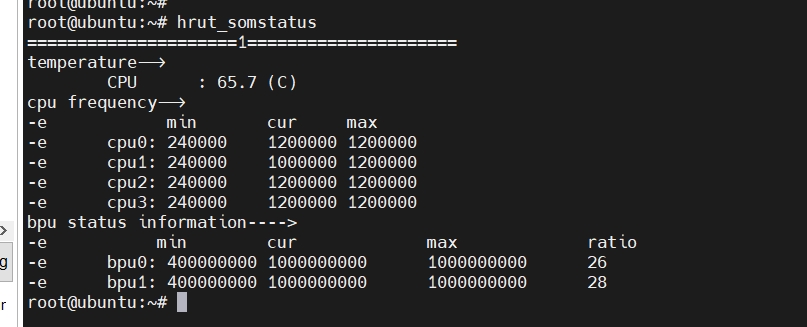
cpu和bpu使用情况如下:
1.硬件获取渠道:网上购买
2.当前系统镜像版本:x3pi_ubuntu_server_disk_20221201201422
3.问题定位:
上游检测模型,在代码内定义4路视频顺序推理,fps每个在7.3左右,如下图:
但是,在下游ocr模型接受单路aimsg流时,fps降低为2左右,不知道是什么情况(后尝试上游模型顺序推两路检测, 下游接受一路aimsg,发现上游每路fps在13左右, 下游ocr fps在4.7左右),如下图:
cpu和bpu使用情况如下:
使用hz统计帧率的时候指定下window为30,统计的帧率更实时。 下游模型如果只订阅消息不处理的话,帧率是多少?
收到,已经安排同事在查了
怎么指定window 30,命令行是什么样
使用–window参数指定,ros2 topic hz --help命令查询支持的参数

只进行接受不做处理,因为上游是开了4路视频,实际上应该是在7左右感觉,


只订阅不处理,帧率正常的吗?
订阅的时候帧率应该是一样的
有实测数据吗?从你上面发的log看,sub img fps平均只有2左右。
对,实际就只有2左右,你需要什么实测数据,log么,还是什么,需要我把代码发你么
现在的测试结果是不是这样?
1、上游模型发布的消息帧率是7
2、下游模型订阅消息,不处理的时候帧率是7
3、下游模型订阅消息,处理的时候帧率是2
是的,aimsg接受的帧率是一样的
那问题范围就缩小在下游模型的推理和后处理了。
下游模型订阅到消息、送接口进行推理、后处理开始、后处理完成,这4个时间点打下log,输出时间戳,看看是哪一步耗时太长。
不是,就接受的aimsg 帧率是正常的,但是在后处理显示信息的时候,调用run()进行推理,之后// 统计输入fps : dnn_output->rt_stat->input_fps = input_stat_.Get(); 这里就已经变成2了,之后再进行推理,如图:


在dnn_node_impl.cpp里面统计输入fps的时候就变成2了
在run()之前是一样的帧率,我把parser的处理过程给去掉了,后处理打印结果还是2左右

dnn node统计的是推理时候输入的fps,输出下log查下单帧的处理过程吧
怎么输出单帧的处理过程
下游模型订阅到消息、送接口进行推理、后处理开始、后处理完成,这4个时间点打下log,输出时间戳,看看是哪一步耗时太长。