为了帮助用户更加快速地了解精度debug分析的使用方法以及测试流程,我们在此处提供三个测试用例以供用户参考,分别为:MobileVit_s、repvgg_b2_deploy以及mnasnet_1.0_96。-
其中:-
针对repvgg_b2_deploy的分析流程请参考:https://developer.horizon.ai/forumDetail/146176821770229922-
针对mnasnet_1.0_96的分析流程请参考:https://developer.horizon.ai/forumDetail/146176821770229925-
本文主要使用精度debug工具对MobileVit_s进行量化精度问题定位。MobileVit_s模型在 imagenet数据集的50000张图片上进行分类精度测试,在默认情况下,模型精度如下:
模型名称
架构
浮点精度
量化精度
MobileVit_s
bayes
0.7654
0.46856(61.22%)
量化后定点模型的精度没有达到浮点模型的99%,因此使用精度debug工具对该模型进行精度异常定位。
1. 确认单独量化权重 / 激活 的累积误差分布情况
1.1 API使用
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./', # 结果保存路径
calibrated_data='./calibration_data', # 校准数据
model_or_file='./calibrated_model.onnx', # 校准模型
quantize_node=['weight', 'activation'], # 量化节点列表,当设置为['weight','activation']时则分别只量化权重和激活
metric='cosine-similarity', # 计算误差的方式(度量方式)
average_mode=False # 是否采用平均累积误差作为输出
)
1.2 输出结果
-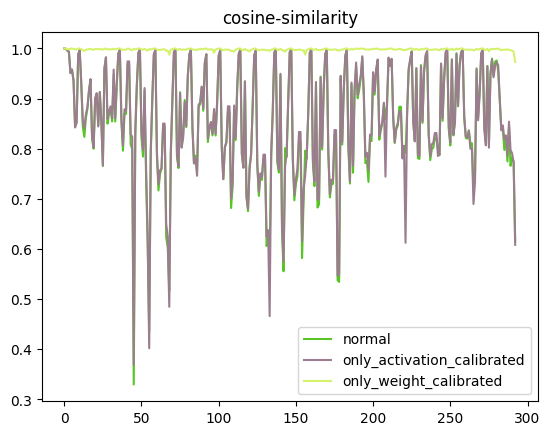
通过分析当模型只量化激活时,出现非常严重的精度掉点。因此判断,模型的主要量化误差来源为对激活的量化。
2. 激活校准节点敏感度排序
2.1 API使用
import horizon_nn.debug as dbg
node_message = dbg.get_sensitivity_of_nodes(
model_or_file='./calibrated_model.onnx', # 校准模型
metrics='cosine-similarity', # 计算敏感度的方式(度量方式)
calibrated_data='./calibration_data/', # 校准数据
output_node=None, # 选取模型中某个节点的输出用于计算敏感度,默认(None)则采用模型的最终输出
node_type='activation', # 节点类型
data_num: int = None,
verbose=True, # 是否在终端显示计算结果。True显示,反之,不显示
interested_nodes=None # 选择某些节点只计算这些节点的敏感度。默认(None)计算模型所有节点
)
2.2 输出结果
-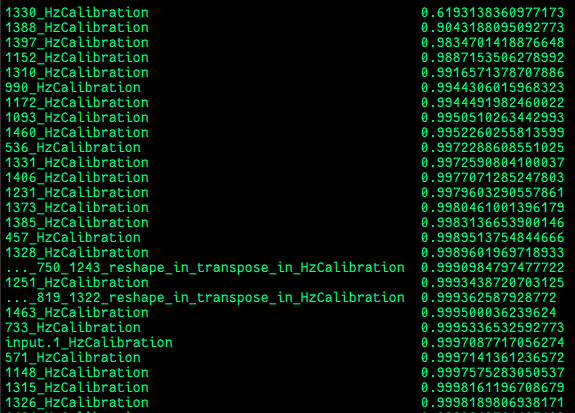
通过分析模型激活校准节点的量化敏感度发现,top4节点的量化敏感度较低,均低于0.99,其中top1节点的量化敏感度低于0.9,仅为0.619。
3. 查看敏感层数据分布情况
3.1 API使用
3.1.1 数据分布
import horizon_nn.debug as dbg
dbg.plot_distribution(
save_dir='./', # 结果保存路径
model_or_file='./calibrated_model.onnx', # 校准模型
calibrated_data='./calibration_data', # 校准数据
nodes_list=['1330_HzCalibration','1388_HzCalibration',
'1397_HzCalibration','1152_HzCalibration'] # 节点列表
)
3.1.2 箱线图
import horizon_nn.debug as dbg
dbg.get_channelwise_data_distribution(
save_dir='./', # 结果保存路径
model_or_file='./calibrated_model.onnx', # 校准模型
calibrated_data='./calibration_data', # 校准数据
nodes_list=['1388_HzCalibration', '1397_HzCalibration'], # 节点列表
axis=None
)
dbg.get_channelwise_data_distribution(
save_dir='./', # 结果保存路径
model_or_file='./calibrated_model.onnx', # 校准模型
calibrated_data='./calibration_data', # 校准数据
nodes_list=['1330_HzCalibration', '1152_HzCalibration'], # 节点列表
axis=2 # 指定channel在shape中的index
)
3.2 输出结果
从2.2的结果来看,top4激活校准节点的敏感度较低,因此分析其数据分布情况。
1388_HzCalibration/1397_HzCalibration
1330_HzCalibration/1152_HzCalibration
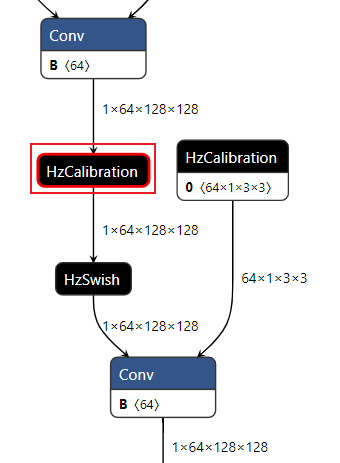
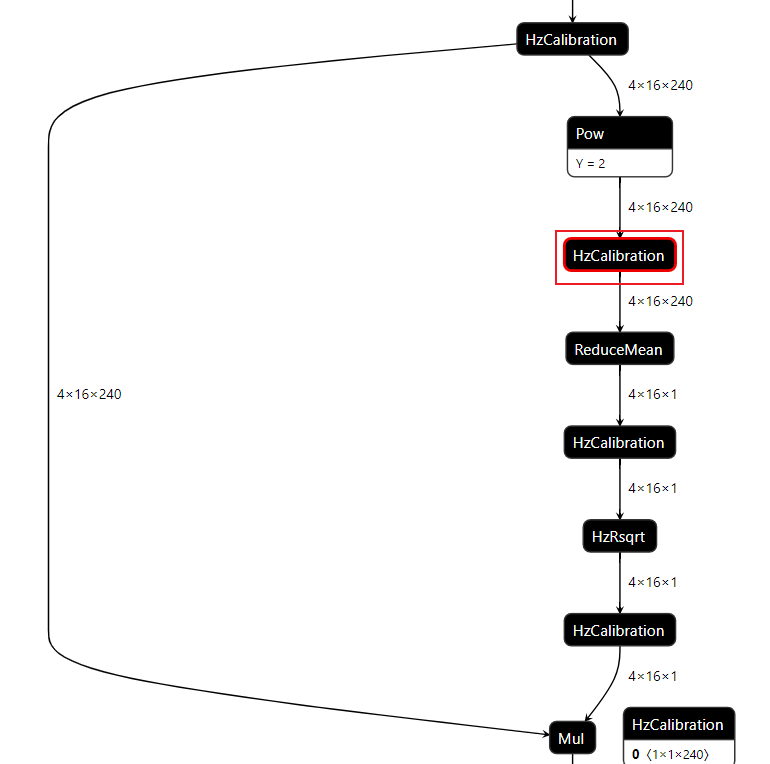
-
1330_HzCalibration-
数据分布
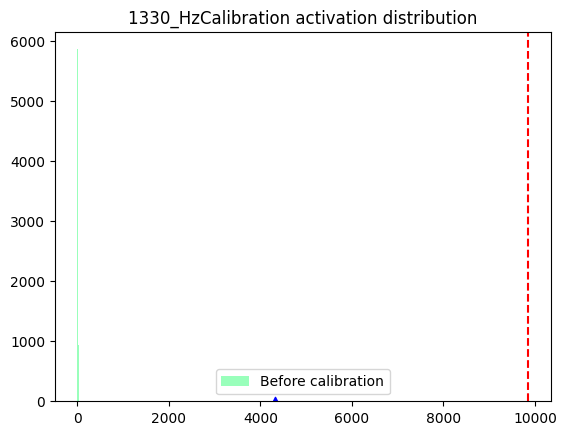
箱线图
-
1388_HzCalibration-
数据分布
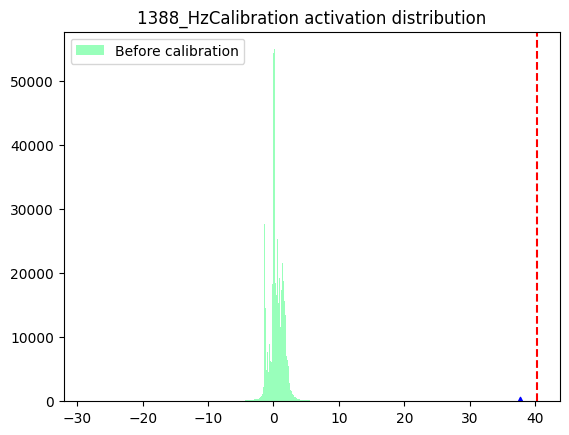
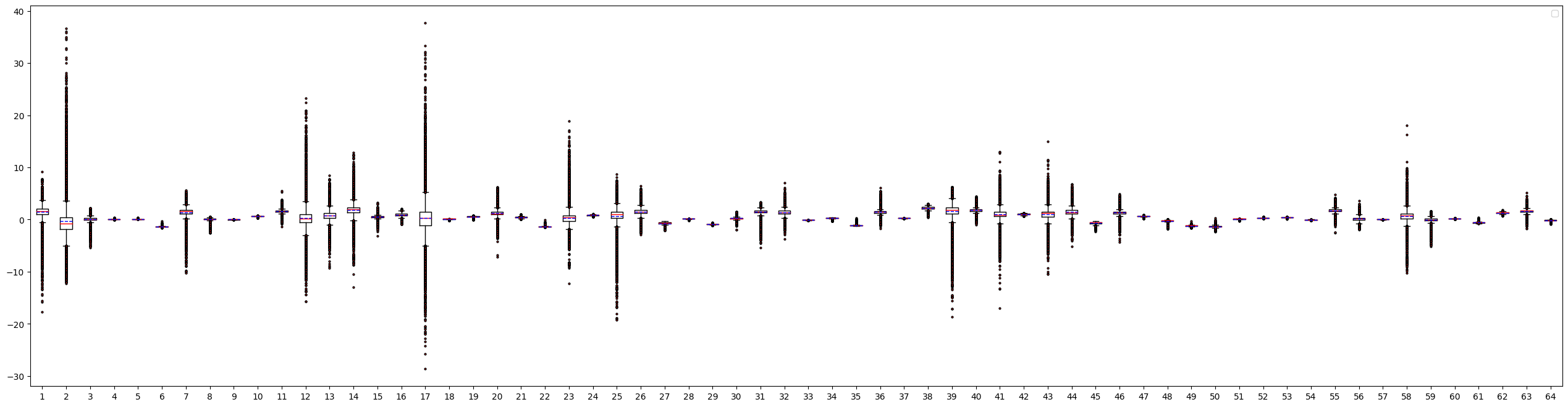
箱线图
-
1397_HzCalibration-
数据分布
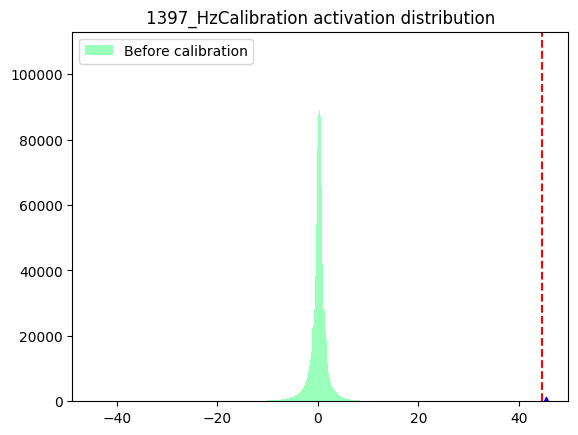

箱线图
-
1152_HzCalibration-
数据分布
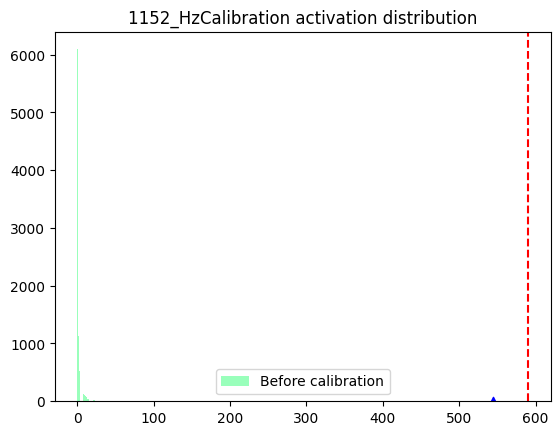
箱线图
数据分布:数据分布的判断标准为是否满足对量化有好的正态分布,只要分布中只有一个很明显的单峰就认为满足正态分布,不需要严格满足正态分布。根据上述判断标准来看,表中节点的数据分布均满足正态分布。但是通过对比数据分布范围,即数据分布图的横坐标范围发现,相较于1388_HzCalibration和1397_HzCalibration,1330_HzCalibration和1152_HzCalibration节点的输入数据分布范围较大。-
箱线图:通过向箱线图可以直观地了解当前数据每个通道之间的数据分布情况。通过观察箱线图纵坐标确认数据分布范围,当某一个通道有异常值时,即数值极大或极小时,认为当前节点采用per-tensor量化会有较大的量化误差。通过观察上述箱线图发现,1330_HzCalibration和1152_HzCalibration节点中,红色框标出的通道均包含异常值,因此判断为per-tensor量化风险节点。
4. 部分量化精度测试
4.1 API使用
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./', # 结果保存路径
calibrated_data='./calibration_data', # 校准数据
model_or_file='./calibrated_model.onnx', # 校准模型
non_quantize_node=[['1330_HzCalibration'],
['1330_HzCalibration','1388_HzCalibration'],
['1330_HzCalibration','1388_HzCalibration','1397_HzCalibration'],
['1330_HzCalibration','1388_HzCalibration','1397_HzCalibration','1152_HzCalibration']], # 四种部分量化方式对应图中的partial_qmodel_0 ~ partial_qmodel_3
metric='cosine-similarity', # 计算误差的方式(度量方式)
average_mode=False # 是否采用平均累积误差作为输出
)
4.2 测试结果
-
经测试发现,解除top2激活校准节点的量化对模型精度有较大的提升,继续增加不量化节点对模型的提升效果较小。
model
量化策略
浮点精度
校准方式
calibrated_model
MobileVit_s
default
0.7654
default_percentile
0.46856(61.22%)
MobileVit_s
1330_HzCalibration不量化
0.7654
default_percentile
0.69850(91.26%)
MobileVit_s
不量化1330_HzCalibration和1388_HzCalibration
0.7654
default_percentile
0.76106(99.43%)
5. 总结
5.1 误差原因分析
- 通过使用精度debug工具中的plot_acc_error分别对量化权重和量化激活的部分量化模型进行累积误差分析可知,量化激活会导致模型量化精度下降。
- 对量化敏感度较低的节点进行数据分布分析发现,数据分布跨度较大,且top1节点通道间数据分布波动较大,会引入更大的量化误差,因此造成模型量化精度下降的主要原因是是由于敏感节点量化导致的。
5.2 提升精度建议
- 尝试打开per-channel开关以提升模型量化精度。
- 将对量化敏感的节点run on CPU。