0 概述-
近年来2D目标检测得到了很好的探索,并使自动驾驶等各种应用受益。当自动驾驶汽车需要在道路上平稳安全地行驶时,它必须拥有周围物体的准确3D信息,才能做出安全的决策。因此,3D目标检测在这些机器人应用中变得越来越重要。单目3D目标检测作为一种简单而廉价的部署形式,成为当今一个非常有意义的研究问题,因此,地平线集成了单目3D目标检测算法。本文为fcos3d参考算法的介绍和使用说明。
该示例为参考算法,仅作为在J5上模型部署的设计参考,非量产算法
1 性能精度指标-
fcos3d模型配置:
数据集
Input shape
Backbone
Neck
Head
NuScenes
1x3x512x896
efficientnetb0
BiFPN
FCOS3DHead
性能精度表现:
性能(双核FPS)
浮点/量化精度
mAP
NDS
589
0.2130/0.2097
0.3059/0.3023
注:Nuscenes 数据集官方介绍:Nuscenes
2 模型介绍
Fcos3d是在fcos基础上进行改进的一种anchor-free的单目3D目标检测算法,将通常定义的7-DoF 3D目标转换到图像域,并将它们解耦为2D和3D属性。考虑到目标的二维比例,将目标分布到不同的特征级别,并仅根据三维中心进行进一步分配。此外,利用基于3D中心的2D高斯分布来重新定义中心度,以拟合3D目标公式。所有这些都使该框架简单而有效,消除了任何2D检测或2D-3D对应先验。在NeurIPS 2020的nuScenes 3D检测挑战中,fcos3d算法在所有纯视觉方法中排名第一。
2.1 模型优化点
相对于官方实现,地平线对fcos3d做了如下优化:
- 将模型的backbone替换为与地平线硬件更为友好的efficientnetb0,提升了模型的性能;
- neck网络优化为bifpn,这种重复双向跨尺度连接+ 带权重的特征融合机制,实现了更高层次的特征融合;
- 检测头中的卷积运算使用深度可分离卷积,大幅优化了模型的性能;
2.2 源码说明
2.2.1 Config文件
configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py 为该模型的配置文件,定义了模型结构、数据集加载,和整套训练流程等。配置文件主要内容包括:
task_name = "fcos3d_efficientnetb0_nuscenes"
#每个gpu的batchsize设置
batch_size_per_gpu = 1
#gpu显卡设置
device_ids = [0, 1,2,3,4,5,6,7]
ckpt_dir = "../../release_models/%s" % task_name
cudnn_benchmark = True
seed = None
log_rank_zero_only = True
bn_kwargs = {}
#芯片架构设置
march = March.BAYES
INF = 1e8
data_rootdir = "./tmp_data/nuscenes/v1.0-trainval"
meta_rootdir = "./tmp_data/nuscenes/meta"
#模型结构定义
model = dict(
type="FCOS3D",
backbone=dict(
type="efficientnet",
...
),
neck=dict(
type="BiFPN",
...
),
head=dict(
type="FCOS3DHead",
...
),
targets=dict(
type="FCOS3DTarget",
...
),
post_process=dict(
type="FOCS3DPostProcess",
...
),
#损失函数配置
loss=dict(
type="FCOS3DLoss",
...
),
)
deploy_model = dict(
type="FCOS3D",
backbone=dict(
type="efficientnet",
...
),
neck=dict(
type="BiFPN",
...
),
head=dict(
type="FCOS3DHead",
...
),
)
#deploy_model输入shape
deploy_inputs = dict(img=torch.randn((1, 3, 512, 896)))
deploy_model_convert_pipeline = dict(
type="ModelConvertPipeline",
qat_mode="fuse_bn",
converters=[
dict(type="Float2QAT"),
dict(type="QAT2Quantize"),
],
)
#训练数据集加载和预处理配置
data_loader = dict(
type=torch.utils.data.DataLoader,
dataset=dict(
type="NuscenesMonoDataset",
data_path=os.path.join(data_rootdir, "train_lmdb"),
transforms=[
...]
),
...
,
)
#验证集加载
val_data_loader = dict(
type=torch.utils.data.DataLoader,
dataset=dict(
type="NuscenesMonoDataset",
data_path=os.path.join(data_rootdir, "val_lmdb"),
transforms=[...],
),
...
)
#不同stage的trainer配置
float_trainer = dict(...)
calibration_trainer = dict(...)
qat_trainer = dict(...)
int_infer_trainer = dict(...)
# 不同stage的predictor配置
float_predictor = dict(...)
calibration_predictor = dict(...)
qat_predictor = dict(...)
int_infer_predictor = dict(...)
#模型编译相关配置
compile_dir = os.path.join(ckpt_dir, "compile")
compile_cfg = dict(
march=march,
name=task_name,
out_dir=compile_dir,
hbm=os.path.join(compile_dir, "model.hbm"),
layer_details=True,
input_source=["pyramid"],
output_layout="NHWC",
opt="O3",#优化等级
)
注: 如果需要复现精度,config中的训练策略最好不要修改,否则可能会有意外的训练情况出现。
2.2.2 image encoder
Image encoder是对图像进行特征提取和融合。fcos3d参考算法通过backbone(efficientnetb0)和neck(BiFPN)提取图像的多尺度特征。网络结构如下图所示:
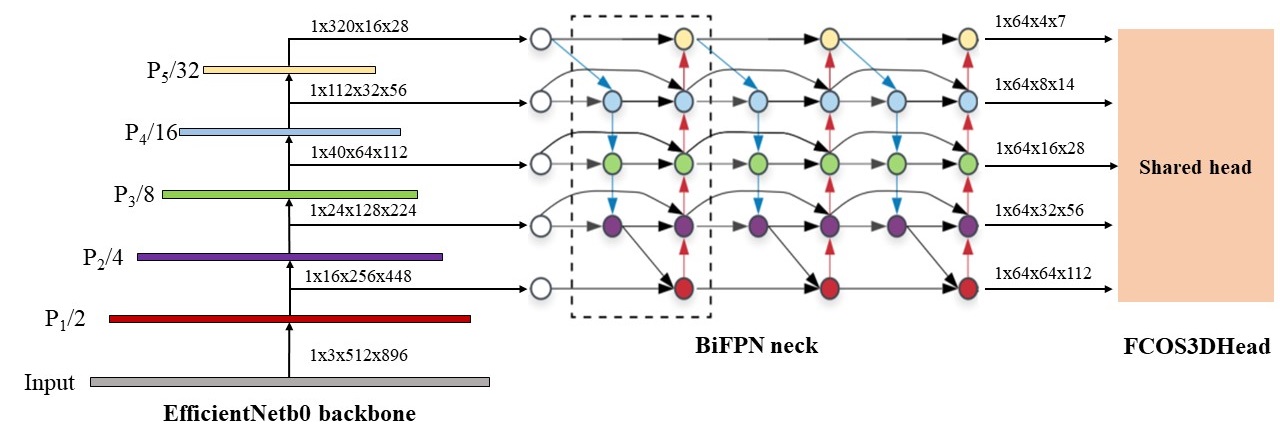
backbone
fcos3d参考算法采用与硬件比较友好的efficientnetb0作为backbone来提取图像多尺度特征,实现了性能的提升。-
代码路径:hat/models/backbones/efficientnet.py
neck
fcos3d用于多级分支构造的neck采用的是bifpn,是用于检测不同尺度目标的主要组件,其特性可以总结为重复双向跨尺度连接+ 加权特征融合机制。bifpn将每个双向路径(自顶向下和自底而上)作为一个特征网络层,并重复同一层多次,以实现更高层次的特征融合;另外,不同的输入 featuremap 具有不同的分辨率,它们对融合输入 featuremap 的贡献也是不同的,因此简单的对他们进行相加或叠加处理并不是最佳的操作,所以bifpn实现了简单而高效的加权特征融合的机制。-
代码路径:hat/models/necks/bifpn.py
2.2.3 FCOS3DHead
fcos3d不同级别的图像特征使用共享的检测头,首先通过efficientnetb0+bifpn网络提取多尺度特征,将目标分配到不同的特征级别和不同的点;然后多尺度特征通过4个共享深度可分离卷积block和small heads回归到不同的目标(如下图所示),这种为具有不同测量值的回归目标建立额外的解耦头的做法更加有效。
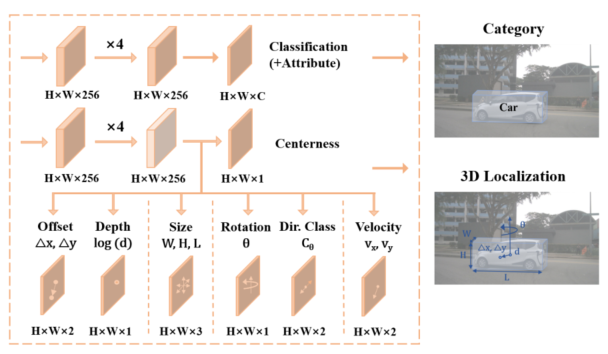
FCOS3DHead回归目标包括以下部分:
- cls_score: 分类分数
- Δx\Delta xΔx,Δy\Delta yΔy,log(d)log(d)log(d): 2.5D中心到特定前景点的偏移、 以及其相应的深度d
- W,H,L,θW,H,L,\thetaW,H,L,θ: 回归框尺寸和旋转角度
- vx,vyv_x,v_yvx,vy: 回归速度
- CθC_{\theta}Cθ: 即2-bin direction classification,考虑相反方向的目标具有相同的 sin(θ)sin(\theta)sin(θ)值
- attr_pred: 属性预测
- centerness: 即3D Center-ness,它作为一个softmax二分类器来确定哪些点更靠近中心,并有助于抑制那些远离目标中心的低质量预测
代码路径:hat/models/task_modules/fcos3d/head.py
def forward(self, feats):
feats = _as_list(feats)
return multi_apply(self.forward_single, feats, self.strides)
def forward_single(self, x, stride):
#x:efficientnetb0+bifpn提取的多尺度特征
cls_feat = x
reg_feat = x
#[8, 16, 32, 64, 128]
idx = self.strides.index(stride)
#多尺度特征共享深度可分离卷积
for cls_layer in self.cls_convs[idx]:
cls_feat = cls_layer(cls_feat)
# clone the cls_feat for reusing the feature map afterwards
clone_cls_feat = cls_feat
for conv_cls_prev_layer in self.conv_cls_prev[idx]:
clone_cls_feat = conv_cls_prev_layer(clone_cls_feat)
#分类score输出
cls_score = self.conv_cls(clone_cls_feat)
#多尺度特征共享深度可分离卷积block
for reg_layer in self.reg_convs[idx]:
reg_feat = reg_layer(reg_feat)
bbox_pred = []
#bbox预测信息
# 包含offset(∆x,∆y), depth(d), size(w,l,h), rot(\theta), velo(v_x,v_y)
for i in range(len(self.group_reg_dims)):
...
bbox_pred.append(self.conv_regs[i](clone_reg_feat))
#2-bin direction classification
dir_cls_pred = None
if self.use_direction_classifier:
...
dir_cls_pred = self.conv_dir_cls(clone_reg_feat)
#属性分数预测
attr_pred = None
if self.pred_attrs:
...
attr_pred = self.conv_attr(clone_cls_feat)
#3d-centerness回归
if self.centerness_on_reg:
...
centerness = self.conv_centerness(clone_reg_feat)
else:
...
centerness = self.conv_centerness(clone_cls_feat)
#输出结果反量化
cls_score = self.dequant(cls_score)
bbox_pred = [self.dequant(x) for x in bbox_pred]
dir_cls_pred = self.dequant(dir_cls_pred)
attr_pred = self.dequant(attr_pred)
centerness = self.dequant(centerness)
if self.return_for_compiler:
return (
cls_score,
*bbox_pred,
dir_cls_pred,
attr_pred,
centerness,
)
# decode
bbox_pred = torch.cat(bbox_pred, dim=1)
clone_bbox = bbox_pred.clone()
#2.5D中心到特定前景点的偏移∆x,∆y
bbox_pred[:, :2] = clone_bbox[:, :2].float()
#相应的深度log(d)
bbox_pred[:, 2] = clone_bbox[:, 2].float()
#bbox尺寸log(w),log(l),log(h)
bbox_pred[:, 3:6] = clone_bbox[:, 3:6].float()
#深度d
bbox_pred[:, 2] = bbox_pred[:, 2].exp()
#bbox尺寸w,l,h
bbox_pred[:, 3:6] = bbox_pred[:, 3:6].exp()
if not self.training:
# Note that this line is conducted only when testing
bbox_pred[:, :2] *= stride
return (
cls_score,
bbox_pred,
dir_cls_pred,
attr_pred,
centerness,
)
2.2.4 FCOS3DTarget
FCOS3DTarget的作用是在训练阶段生成分类/回归目标用于loss计算,包括labels_3d, bbox_targets_3d, centerness_targets 和 attr_targets。
points获取-
与基于锚的检测器通过将预定义的锚框作为参考来回归目标不同,fcos3d作为anchor-free的目标检测范式,通过特征图上的每个点来预测目标,该点对应于原始输入图像上均匀分布的点。fcos3d是通过特征图的尺寸和stride的计算获得points,对于特征图FiF_iFi上的每个位置(x,y),假设直到第i层的总stride是s,那么原始图像上的相应points位置应该是:
(sx+⌊s2⌋,sy+⌊s2⌋)(sx+\left \lfloor \frac{s}{2} \right \rfloor,sy+\left \lfloor \frac{s}{2} \right \rfloor)(sx+⌊2s⌋,sy+⌊2s⌋)
对应代码:
def get_points(feat_sizes, strides, dtype, device, flatten=False):
"""Generate points according to feat_sizes."""
def _get_points_single(feat_size, stride):
"""Get points of a single scale level."""
h, w = feat_size
x_range = torch.arange(w, dtype=dtype, device=device)
y_range = torch.arange(h, dtype=dtype, device=device)
y, x = torch.meshgrid(y_range, x_range)
if flatten:
y = y.flatten()
x = x.flatten()
points = (
torch.stack(
(x.reshape(-1) * stride, y.reshape(-1) * stride), dim=-1
)
+ stride // 2
)
return points
mlvl_points = []
for i in range(len(feat_sizes)):
mlvl_points.append(_get_points_single(feat_sizes[i], strides[i]))
return mlvl_points
代码路径:hat/models/task_modules/fcos/target.py
centerness计算-
由于fcos3d的回归目标改为基于3D中心的范式,通过以投影的3D中心为原点的2D高斯分布来定义centerness。二维高斯分布简化为:
c=e−α((Δx)2+(Δy)2)c=e^{-\alpha((\Delta x)^2+(\Delta y)^2)}c=e−α((Δx)2+(Δy)2)
这里,α\alphaα用于调整从中心到外围的强度衰减,并设置为2.5。fcos3d将c作为centerness的groundtruth,并从回归分支对其进行预测,以便稍后过滤低质量的预测。-
对应代码:
bbox_targets_3d = bbox_targets_3d[range(num_points), min_dist_inds]
relative_dists = torch.sqrt(
torch.sum(bbox_targets_3d[..., :2] ** 2, dim=-1)
) / (1.414 * stride[:, 0])
# [N, 1] / [N, 1]
centerness_targets = torch.exp(-self.centerness_alpha * relative_dists)
代码路径:hat/models/task_modules/fcos/target.py
FCOS3DTarget的forward代码为:
def forward(
self,
cls_scores,
bbox_preds,
gt_bboxes_list,
gt_labels_list,
gt_bboxes_3d_list,
gt_labels_3d_list,
centers2d_list,
depths_list,
attr_labels_list,
):
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
#获取points
points = get_points(
featmap_sizes,
#strides=[8, 16, 32, 64, 128]
self.strides,
bbox_preds[0].dtype,
bbox_preds[0].device,
)
#regress_ranges=((-1, 48), (48, 96), (96, 192), (192, 384), (384, INF))
assert len(points) == len(self.regress_ranges)
num_levels = len(points)#5
# 扩展regress ranges与points对齐
expanded_regress_ranges = [
points[i]
.new_tensor(self.regress_ranges[i])[None]
.expand_as(points[i])
for i in range(num_levels)
]
# concat 所有levels的points和regress ranges
concat_regress_ranges = torch.cat(expanded_regress_ranges, dim=0)
concat_points = torch.cat(points, dim=0)
# the number of points per img, per lvl
num_points = [center.size(0) for center in points]
if attr_labels_list is None:
attr_labels_list = [
gt_labels.new_full(gt_labels.shape, self.attr_background_label)
for gt_labels in gt_labels_list
]
# 获取每张图像的lables和bbox_targets
(
_,
_,
labels_3d_list,
bbox_targets_3d_list,
centerness_targets_list,
attr_targets_list,
) = multi_apply(
...
)
# 将标注信息划分到每张图像,每个级别的特征
labels_3d_list = [
labels_3d.split(num_points, 0) for labels_3d in labels_3d_list
]
bbox_targets_3d_list =...
centerness_targets_list = ...
attr_targets_list = ...
# concat 每个level的图像
for i in range(num_levels):
...
return (
concat_lvl_labels_3d,
concat_lvl_bbox_targets_3d,
concat_lvl_centerness_targets,
concat_lvl_attr_targets,
)
2.2.5 Loss
获取到labels_3d, bbox_targets_3d,centerness_targets, attr_targets等分类回归groundtruth后,需要在训练阶段进行loss的计算。fcos3d参考算法的损失定义与公版一致,对于分类和不同的回归目标,分别定义它们的损失,损失函数的设置在config文件中:
#分类损失:focal loss
loss_cls=dict(
type="FocalLoss",
num_classes=11,
gamma=2.0,
alpha=0.25,
),
#回归损失:Smooth L1 Loss
loss_bbox=dict(type="SmoothL1Loss", beta=1.0 / 9.0, loss_weight=1.0),
#方向分类损失:Cross Entropy Loss
loss_dir=dict(
type="CrossEntropyLoss", use_sigmoid=False, loss_weight=1.0
),
#属性分类损失:Cross Entropy Loss
loss_attr=dict(
type="CrossEntropyLoss", use_sigmoid=False, loss_weight=1.0
),
#centerness回归损失:Binary Cross Entropy Loss
loss_centerness=dict(
type="CrossEntropyLoss",
use_sigmoid=True,
loss_weight=1.0,
),
loss计算代码路径:hat/models/task_modules/fcos3d/loss.py
2.2.6 PostProcess
fcos3d的3D边界框的回归采用了比较简单的方法,即把通常定义的7-DoF(3D bbox中心、尺寸和偏转角)回归目标转换为2.5D中心和3D尺寸。通过相机固有矩阵,可以将2.5D中心转换回3D空间,因此,对2.5D中心进行回归可以进一步简化为对从中心到特定前景点的偏移量∆x、∆y及其相应深度d进行回归。所以,在获取到回归目标后,在后处理阶段进行了坐标转换和非极大值抑制(Non-Maximum Suppression,NMS)等操作,将class score和centerness相乘作为每个预测的置信度,并在鸟瞰图中作为大多数3D检测器进行旋转的NMS,以获得最终结果。
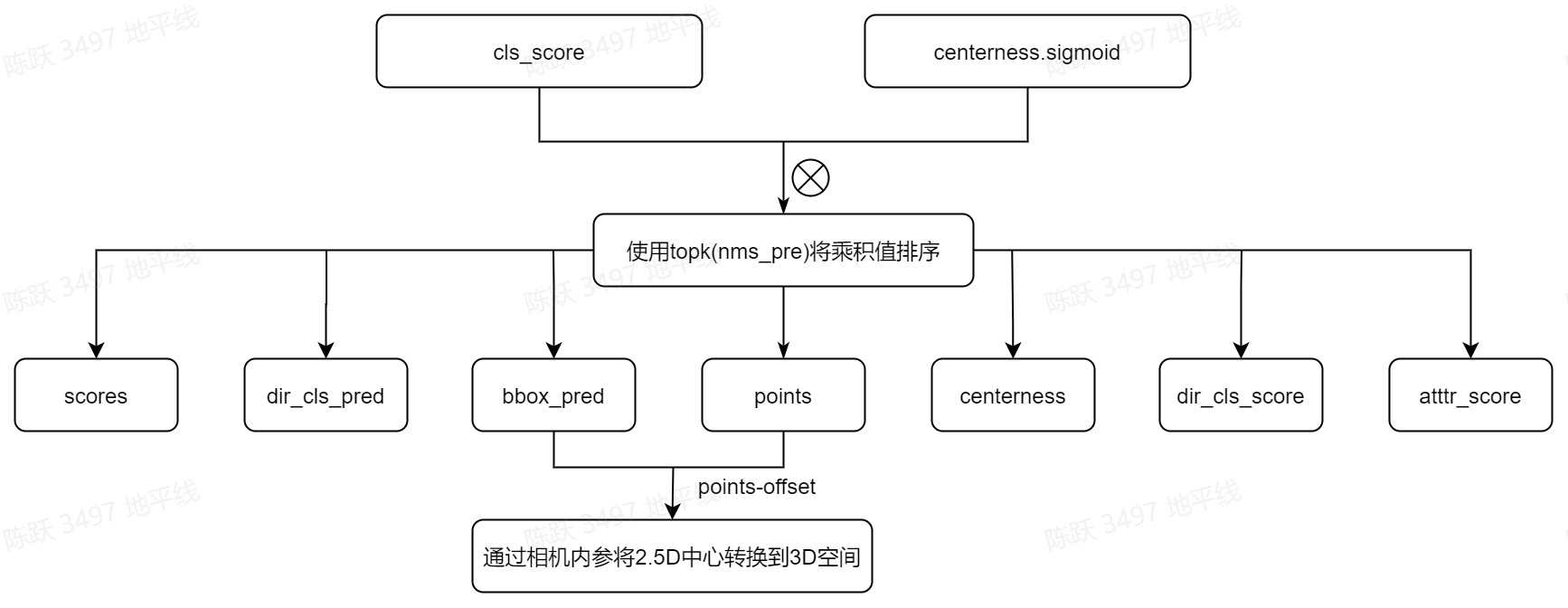
置信度计算-
fcos3d的后处理阶段是根据分类分数cls_score和centerness的乘积来筛选3d bbox的,对乘积的结果进行降序排列后,选择前100个作为我们需要的bbox,流程如下图所示:
相关代码如下所示:
def _get_bboxes_single(
self,
cls_scores,
bbox_preds,
dir_cls_preds,
attr_preds,
centernesses,
mlvl_points,
input_meta,
cfg,
rescale=False,
):
view = np.array(input_meta["cam2img"])
# scale_factor = input_meta["scale_factor"]
...
for (
cls_score,
bbox_pred,
dir_cls_pred,
attr_pred,
centerness,
points,
) in zip(
cls_scores,
bbox_preds,
dir_cls_preds,
attr_preds,
centernesses,
mlvl_points,
):
...
if nms_pre > 0 and scores.shape[0] > nms_pre:
#将scores和centerness的乘积作为bbox的score
#bbox筛选:根据score和centerness乘积进行排序
max_scores, _ = (scores * centerness[:, None]).max(dim=1)
#获取score值前100的索引值
_, topk_inds = max_scores.topk(nms_pre)
#选择索引对应的points,bbox,score,dir,centerness等目标
points = points[topk_inds, :]
bbox_pred = bbox_pred[topk_inds, :]
scores = scores[topk_inds, :]
dir_cls_pred = dir_cls_pred[topk_inds, :]
centerness = centerness[topk_inds]
dir_cls_score = dir_cls_score[topk_inds]
attr_score = attr_score[topk_inds]
# 将相对于点的偏预测转到points预测
bbox_pred[:, :2] = points - bbox_pred[:, :2]
pred_center2d = bbox_pred[:, :3].clone()
#将2.5D中心通过相机内参矩阵转换到3D空间
#x,y,depyh(2.5D中心)->x,y,z(3D空间)
#view为内参矩阵
bbox_pred[:, :3] = points_img2cam(bbox_pred[:, :3], view)
mlvl_centers2d.append(pred_center2d)
mlvl_bboxes.append(bbox_pred)
...
mlvl_centers2d = torch.cat(mlvl_centers2d)
mlvl_bboxes = torch.cat(mlvl_bboxes)
mlvl_dir_scores = torch.cat(mlvl_dir_scores)
# change local yaw to global yaw for 3D nms
cam2img = mlvl_centers2d.new_zeros((4, 4))
cam2img[: view.shape[0], : view.shape[1]] = mlvl_centers2d.new_tensor(
view
)
#将偏航角转换到3D空间
mlvl_bboxes = self.bbox_coder.decode_yaw(
mlvl_bboxes,
mlvl_centers2d,
mlvl_dir_scores,
self.dir_offset,
cam2img,
)
#将3D bbox转到鸟瞰图场景下进行旋转非极大值抑制
mlvl_bboxes_for_nms = xywhr2xyxyr(
input_meta["box_type_3d"](
mlvl_bboxes,
box_dim=self.bbox_code_size,
origin=(0.5, 0.5, 0.5),
).bev
)
...
mlvl_nms_scores = mlvl_scores * mlvl_centerness[:, None]
#进行非极大值抑制
results = box3d_multiclass_nms(
mlvl_bboxes,
mlvl_bboxes_for_nms,
mlvl_nms_scores,
cfg.score_thr,
cfg.max_per_img,
cfg,
mlvl_dir_scores,
mlvl_attr_scores,
)
...
return {
"ret": ret,
"bboxes": bboxes,
"scores": scores,
"labels": labels,
"attrs": attrs,
}
代码路径:hat/models/task_modules/fcos3d/post_process.py
非极大值抑制-
fcos3d通过计算投影的3D边界框的外部矩形来生成2D边界框,然后,在鸟瞰图中作为大多数3D检测器进行旋转的非最大值抑制,以获得最终结果。相关代码如下所示:
def box2d3d_multiclass_nms(
mlvl_bboxes,
mlvl_bboxes_for_nms,
mlvl_scores,
score_thr,
max_num,
cfg,
mlvl_dir_scores=None,
mlvl_attr_scores=None,
mlvl_bboxes2d=None,
):
"""Multi-class NMS for 3D boxes. The IoU used for NMS is defined as the 2D \
IoU between BEV boxes.
""" # noqa
# do multi class nms
# the fg class id range: [0, num_classes-1]
num_classes = mlvl_scores.shape[1] - 1
bboxes = []
scores = []
labels = []
dir_scores = []
attr_scores = []
bboxes2d = []
for i in range(0, num_classes):
# get bboxes and scores of this class
#选择score大于0.05的bbox
cls_inds = mlvl_scores[:, i] > score_thr
if not cls_inds.any():
continue
_scores = mlvl_scores[cls_inds, i]
_bboxes_for_nms = mlvl_bboxes_for_nms[cls_inds, :]
#在bev视角使用旋转nms,
if cfg.use_rotate_nms:
nms_func = nms_bev
else:
nms_func = nms_normal_bev
selected = nms_func(_bboxes_for_nms, _scores, cfg.nms_thr)
_mlvl_bboxes = mlvl_bboxes[cls_inds, :]
bboxes.append(_mlvl_bboxes[selected])
scores.append(_scores[selected])
cls_label = mlvl_bboxes.new_full((len(selected),), i, dtype=torch.long)
labels.append(cls_label)
...
return results
代码路径:hat/core/nms/box3d_nms.py
forward代码为:
def forward(
self,
cls_scores,
bbox_preds,
dir_cls_preds,
attr_preds,
centernesses,
img_metas,
cfg=None,
rescale=None,
):
assert (
len(cls_scores)
== len(bbox_preds)
== len(dir_cls_preds)
== len(centernesses)
== len(attr_preds)
)
num_levels = len(cls_scores)
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
#获取多级points
mlvl_points = get_points(
featmap_sizes,
self.strides,
bbox_preds[0].dtype,
bbox_preds[0].device,
)
result_list = []
#做NMS,获取一张图的回归目标
for img_id in range(cls_scores[0].size(0)):
cls_score_list = [
cls_scores[i][img_id].detach() for i in range(num_levels)
]
bbox_pred_list = [
bbox_preds[i][img_id].detach() for i in range(num_levels)
]
if self.use_direction_classifier:
dir_cls_pred_list = [
dir_cls_preds[i][img_id].detach()
for i in range(num_levels)
]
else:
...
if self.pred_attrs:
attr_pred_list = [
attr_preds[i][img_id].detach() for i in range(num_levels)
]
else:
...
centerness_pred_list = [
centernesses[i][img_id].detach() for i in range(num_levels)
]
# input_meta = img_metas[img_id]
input_meta = {}
input_meta["box_type_3d"] = CameraInstance3DBoxes
for key in img_metas.keys():
input_meta[key] = img_metas[key][img_id]
#NMS,获取单张图像的bboxes
det_bboxes = self._get_bboxes_single(
cls_score_list,
bbox_pred_list,
dir_cls_pred_list,
attr_pred_list,
centerness_pred_list,
mlvl_points,
input_meta,
cfg,
rescale,
)
result_list.append(det_bboxes)
return result_list
代码路径:hat/models/task_modules/fcos3d/post_process.py
3 浮点模型训练-
3.1 Before Start-
3.1.1 发布物及环境部署-
step1:获取发布物-
下载OE包horizon_j5_open_explorer_v$version$.tar.gz,获取方式见地平线开发者社区 OpenExplorer算法工具链 版本发布-
step2:解压发布包
tar -xzvf horizon_j5_open_explorer_v$version$.tar.gz
解压后文件结构如下:
|-- bsp
|-- ddk
| |-- package
| `-- samples
| |-- ai_benchmark
| |-- ai_forward_view_sample
| |-- ai_toolchain
| | |-- ...
| | |-- horizon_model_train_sample
| | `-- model_zoo
| |-- model_zoo
| `-- vdsp_rpc_sample
|-- README-CN
|-- README-EN
|-- resolve_all.sh
`-- run_docker.sh
其中horizon_model_train_sample为参考算法模块,包含以下模块:
|-- horizon_model_train_sample #参考算法示例
| |-- plugin_basic #qat 基础示例
| `-- scripts #模型配置文件、运行脚本
step3:拉取docker环境
docker pull openexplorer/ai_toolchain_ubuntu_20_j5_gpu:v$version$
#启动容器,具体参数可根据实际需求配置
#-v 用于将本地的路径挂载到 docker 路径下
nvidia-docker run -it --shm-size="15g" -v `pwd`:/WORKSPACE openexplorer/ai_toolchain_ubuntu_20_j5_gpu:v$version$
3.1.2 数据集准备-
3.1.2.1 数据集下载-
进入nuscenes官网,根据提示完成账户的注册,下载Full dataset(v1.0)、CAN bus expansion和Map expansion(v1.3)这三个项目下的文件。下载后的压缩文件为:
|-- nuScenes-map-expansion-v1.3.zip
|-- can_bus.zip
|-- v1.0-mini.tar
|-- v1.0-trainval01_blobs.tar
|-- ...
|-- v1.0-trainval10_blobs.tar
`-- v1.0-trainval_meta.tar
Full dataset(v1.0)包含多个子数据集,如果不需要进行v1.0-trainval数据集的浮点训练和精度验证,可以只下载v1.0-mini数据集进行小场景的训练和验证。
将下载完成的v1.0-trainval01_blobs.tar~v1.0-trainval10_blobs.tar、v1.0-trainval_meta.tar和can_bus.zip进行解压,解压后的目录如下所示:
|--nuscenes
|-- can_bus #can_bus.zip解压后的目录
|-- samples #v1.0-trainvalXX_blobs.tar解压后的目录
| |-- CAM_BACK
| |-- ...
| |-- CAM_FRONT_RIGHT
| |-- ...
| `-- RADAR_FRONT_RIGHT
|-- sweeps
| |-- CAM_BACK
| |-- ...
| |-- CAM_FRONT_RIGHT
| |-- ...
| `-- RADAR_FRONT_RIGHT
|-- v1.0-trainval #v1.0-trainval_meta.tar解压后的数据
|-- attribute.json
| ...
`-- visibility.json
3.1.2.2 数据集打包-
进入 horizon_model_train_sample/scripts 目录,使用以下命令将训练数据集和验证数据集打包,格式为lmdb:
#pack train_Set
python3 tools/datasets/nuscenes_packer.py --src-data-dir /WORKSPACE/nuscenes/ --pack-type lmdb --target-data-dir /WORKSPACE/tmp_data/nuscenes/v1.0-trainval --version v1.0-trainval --split-name train
#pack val_Set
python3 tools/datasets/nuscenes_packer.py --src-data-dir /WORKSPACE/nuscenes/ --pack-type lmdb --target-data-dir /WORKSPACE/tmp_data/nuscenes/v1.0-trainval --version v1.0-trainval --split-name val
--src-data-dir为解压后的nuscenes数据集目录;-
--target-data-dir为打包后数据集的存储目录;-
--version 选项为[“v1.0-trainval”, “v1.0-test”, “v1.0-mini”],如果进行全量训练和验证设置为v1.0-trainval,如果仅想了解模型的训练和验证过程,则可以使用v1.0-mini数据集;v1.0-test数据集仅为测试场景,未提供注释。-
全量的nuscenes数据集较大,打包时间较长。每打包完100张会在终端有打印提示,其中train打包约28100张,val打包约6000张。
数据集打包命令执行完毕后会在target-data-dir下生成train_lmdb和val_lmdb,train_lmdb和val_lmdb就是打包之后的训练数据集和验证数据集为config中的data_rootdir。
|-- tmp_data
| |-- nuscenes
| | |-- v1.0-trainval
| | | |-- train_lmdb #打包后的train数据集
| | | | |-- data.mdb
| | | | `-- lock.mdb
| | | `-- val_lmdb #打包后的val数据集
| | | | |-- data.mdb
| | | | `-- lock.mdb
3.1.2.3 meta文件夹构建-
在tmp_data/nuscenes 下创建meta文件夹,将v1.0-trainval_meta.tar压缩包解压至meta,得到meta/maps文件夹,再将nuScenes-map-expansion-v1.3.zip压缩包解压至meta/maps文件夹下,解压后的目录结构为:
|-- tmp_data
| |-- nuscenes
| | |-- meta
| | | |-- maps #nuScenes-map-expansion-v1.3.zip解压后的目录
| | | | |-- 36092f0b03a857c6a3403e25b4b7aab3.png
| | | | |-- ...
| | | | |-- 93406b464a165eaba6d9de76ca09f5da.png
| | | | |-- prediction
| | | | |-- basemap
| | | | |-- expansion
| | | |-- v1.0-trainval #v1.0-trainval_meta.tar解压后的目录
| | | |-- attribute.json
| | | ...
| | | |-- visibility.json
| | `-- v1.0-trainval
| | | |-- train_lmdb #打包后的train数据集
| | | `-- val_lmdb #打包后的val数据集
3.1.3 config配置-
在进行模型训练和验证之前,需要对configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py文件中的部分参数进行配置,一般情况下,我们需要配置以下参数:
- device_ids、batch_size_per_gpu:根据实际硬件配置进行device_ids和每个gpu的batchsize的配置;
- ckpt_dir:浮点、calib、量化训练的权重路径配置,权重下载链接在config文件夹下的README中;
- data_rootdir:3.1.2.2中打包的数据集路径配置;
- meta_rootdir :3.1.2.3中创建的meta文件夹的路径配置;
- float_trainer下的checkpoint_path:浮点训练时backbone的预训练权重所在路径,可以使用README的# Backbone Pretrained ckpt中ckpt download提供的float-checkpoint-best.pth.tar权重文件。
3.2 浮点模型训练-
config文件中的参数配置完成后,使用以下命令训练浮点模型:
python3 tools/train.py --config configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py --stage float
float训练后模型ckpt的保存路径为config配置的ckpt_callback中save_dir的值,默认为ckpt_dir。
3.3 浮点模型验证-
浮点模型训练完成以后,可以使用以下命令验证已经训练好的浮点模型精度:
python3 tools/predict.py --config configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py --stage float
4 模型量化和编译-
完成浮点训练后,还需要进行量化训练和编译,才能将定点模型部署到板端。地平线对该模型的量化采用horizon_plugin框架,经过Calibration+QAT量化训练后,使用compile的工具将量化模型编译成可以上板运行的hbm文件。
4.1 Calibration
模型完成浮点训练后,便可进行 Calibration。calibration在forward过程中通过统计各处的数据分布情况,从而计算出合理的量化参数。 通过运行下面的脚本就可以开启模型的Calibration过程:
python3 tools/train.py --config configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py --stage calibration
4.2 Calibration 模型精度验证
Calibration完成以后,可以使用以下命令验证经过calib后模型的精度:
python3 tools/predict.py --config configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py --stage calibration
模型经过 Calibration 后的量化精度若已满足要求,便可直接进行转定点模型的步骤,否则需要进行量化训练进一步提升精度。
4.3 量化训练
fcos3d经过 Calibration 后的量化精度未能满足要求,所以需要使用以下命令进行量化训练:
python3 tools/train.py --config configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py --stage qat
4.4 qat模型精度验证
量化训练完成后,通过运行以下命令验证qat模型的精度:
python3 tools/predict.py --config configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py --stage qat
4.5 量化模型精度验证
通过运行以下命令验证量化模型的精度:
python3 tools/predict.py --config configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py --stage int_infer
qat模型的精度验证对象为插入伪量化节点后的模型(float32);quantize模型的精度验证对象为定点模型(int8),验证的精度是最终的int8模型的真正精度,这两个精度应该是十分接近的。
4.6 仿真上板精度验证
除了上述模型验证之外,我们还提供和上板完全一致的精度验证方法,可以通过下面的方式完成:
python3 tools/align_bpu_validation.py --config configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py
4.7 量化模型编译-
在量化训练完成之后,可以使用compile_perf.py脚本将量化模型编译成可以板端运行的hbm模型,同时该工具也能预估在BPU上的运行性能,compile_perf脚本使用方式如下:
python3 tools/compile_perf.py --config configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py --out-dir ./ --opt 3
opt为优化等级,取值范围为0~3,数字越大优化等级越高,编译时间也会越长;-
可以指定–out_dir为编译后产出物的存放路径,默认在ckpt_dir的compile文件夹
运行后,ckpt_dir的compile目录下会产出以下文件:
|-- compile
| |-- .html #模型在bpu上的静态性能数据
| |-- .json
| |-- model.hbm #板端部署的模型
| |-- model.hbir #编译过程的中间文件
`-- model.pt #模型的pt文件
5 其他工具-
5.1 结果可视化-
如果你希望可以看到训练出来的模型对于单帧图像的检测效果,我们的tools文件夹下面同样提供了预测及可视化的脚本,你只需要运行以下脚本即可:
python3 tools/infer.py --config configs/detection/fcos3d/fcos3d_efficientnetb0_nuscenes.py --save_path ./
- save_path:推理可视化结果保存路径;
- 需在config文件中配置infer_cfg字段。
可视化示例:

6 板端部署
6.1 上板性能实测
使用hrt_model_exec perf工具将生成的.hbm文件上板做BPU性能FPS实测,hrt_model_exec perf参数如下:
hrt_model_exec perf --model_file {model}.hbm \
--thread_num 8 \
--frame_count 2000 \
--core_id 0 \
--profile_path '.'
6.2 AIBenchmark 示例-
OE开发包中提供了fcos3d的AI Benchmark示例,位于:ddk/samples/ai_benchmark/j5/qat/script/detection/fcos3d_efficientnetb0,具体使用可以参考开发者社区J5算法工具链产品手册-AIBenchmark评测示例-
可在板端使用以下命令执行做模型评测:
#性能数据
sh fps.sh
#单帧延迟数据
sh latency.sh
运行后会在终端打印出fps和latency数据。如果要进行精度评测,请参考开发者社区J5算法工具链产品手册-AIBenchmark示例精度评测 进行数据的准备和模型的推理。