前言
在编写板端部署的C++代码时,很重要的一步是为输入数据做padding,这是为了让输入数据符合BPU的跨距对齐规则,使得BPU的计算更加高效。有关跨距的概念和跨距对齐的详细解读,可以查看社区文章《数据排布与跨距对齐》。-
图像数据和featuremap数据做padding的方式并不相同,图像数据较为简单,可以调用板端的模型推理库自动进行padding操作,而featuremap数据只能在用户侧编写完整代码进行padding,本文会分别进行详细介绍。
图像数据
常见图像数据包括Y/NV12/NV12_SEPARATE/YUV444/RGB/BGR,您可以阅读社区文章《常见图像格式》进行了解。同时,本章节会基于OE包ddk/samples/ai_toolchain/horiozn_runtime_sample/code目录下的00_quick_start示例进行讲解,我们近期就会发布文章《模型推理快速上手》对该示例做详细介绍。-
在00_quick_start的示例代码中,函数prepare_tensor会解析模型输入节点的信息,并申请alignedByteSize大小的BPU内存,函数read_image_2_tensor_as_nv12负责读取输入图像并将图像数据存放进这块BPU内存中。此时,BPU内存中的输入数据是这样的存储形式:
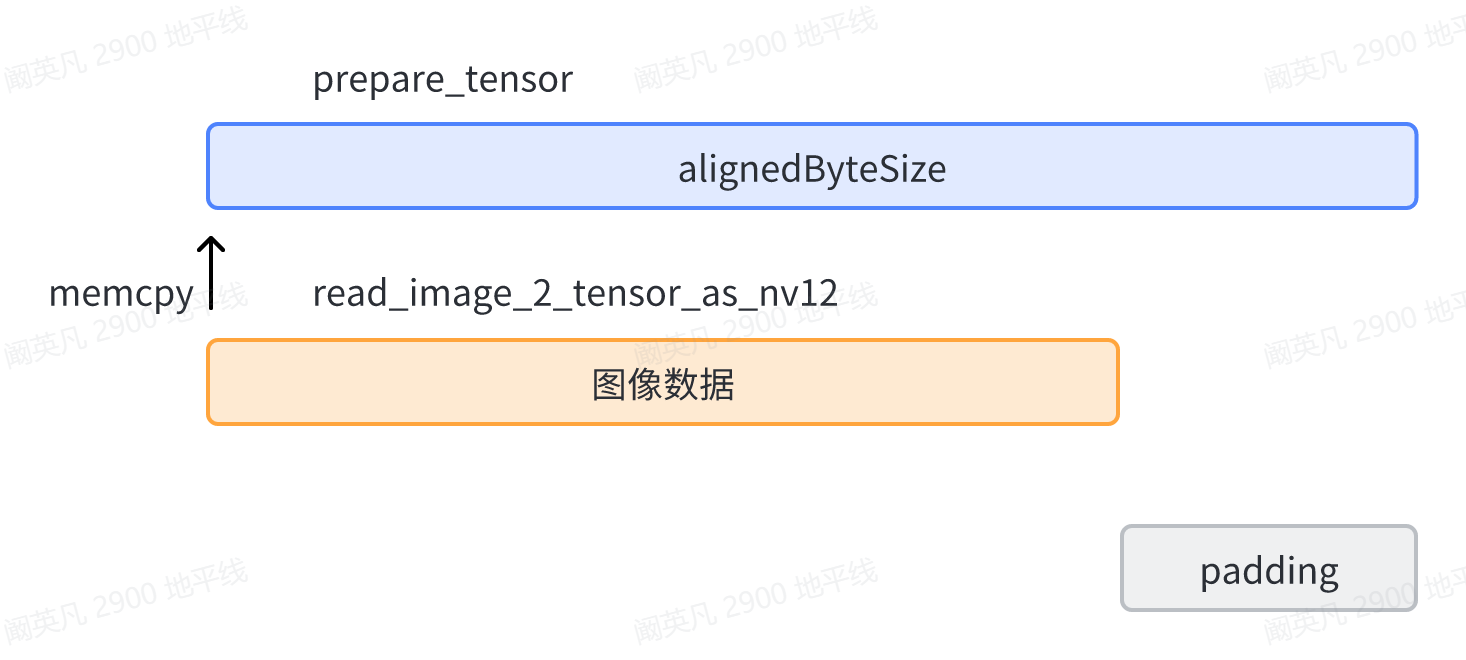
图1中,alignedByteSize是prepare_tensor函数申请的BPU内存空间,图像数据以memcpy的方式存储进内存中。这块内存的尾部会留有一部分空间没有存放数据,这部分空间用于留给板端推理库做padding操作。-
但通过对《数据排布与跨距对齐》的学习,我们知道,BPU的跨距对齐规则是这样的:-

考虑到内存是以一维的方式存储数据,我们将这张二维图展成一维,就会是下面这种形式: 图3-

那么从图1是怎么变成图3的呢?在prepare_tensor函数中,有这样一行代码:
input[i].properties.alignedShape = input[i].properties.validShape;
在板端推理时,当模型推理库解析到alignedshape等于validshape,就会判断用户没有主动对输入数据做padding,那么推理库就会按照不同数据类型对应的padding规则自动做padding,从而将图1转变成图3的形式。如果将图3以二维的形式体现,就会变回我们熟悉的图2的对齐形式。-
换言之,如果输入数据本身就是按照BPU对齐规则padding过了的,或者输入数据本身就符合BPU对齐规则,那么此时图像输入数据的大小已经等于alignedByteSize,在memcpy之后也就没有多余的空间了,图1直接就符合图2和图3的对齐形式。-
总结:以图像数据作为模型输入时,用户不需要自己主动做padding,只需要在分配BPU内存后,添加上述那一行代码,就可以让板端的模型推理库自动完成padding操作。
featuremap数据
以featuremap数据作为输入时,板端推理库无法自动padding,需要用户按照BPU对齐规则,编写具体代码做padding。从J5算法工具链的1.1.49b版本,以及XJ3算法工具链的2.5.2(gcc-9.3.0)和1.16.2c(gcc-6.5.0)版本开始,horizon_runtime_sample新增了对featuremap数据做padding的示例代码,开发者可以进入OE包的ddk/samples/ai_toolchain/horizon_runtime_sample/code/03_misc/resnet_feature/src目录,打开run_resnet_feature.cc代码进行学习。
首先需要强调,并不是所有的featuremap输入都需要手动做padding。如果featuremap输入的第一个算子是CPU算子(比如量化),由于跨距对齐规则只针对BPU不针对CPU,那么此时就不要做padding了。另外,即便featuremap输入的第一个算子是BPU算子,如果输入本身已经符合跨距对齐的要求,那么也不需要做padding。-
具体来说,featuremap输入必须同时符合以下两个条件才需要由用户手动做padding:
- featuremap输入的第一个算子必须是BPU算子;
- featuremap输入不满足跨距对齐要求,在数据排布的最后一个维度上未做到16字节对齐。
接下来分析horizon_runtime_sample的示例是怎么给featuremap输入做对齐的。示例使用的模型是一个单输入的featuremap模型,该模型输入节点原有的量化算子已经被删除,所以第一个算子直接就是BPU算子,模型输入数据的要求是int8数据类型,数据排布为NCHW,维度为1x64x56x56,结构如下图所示:
-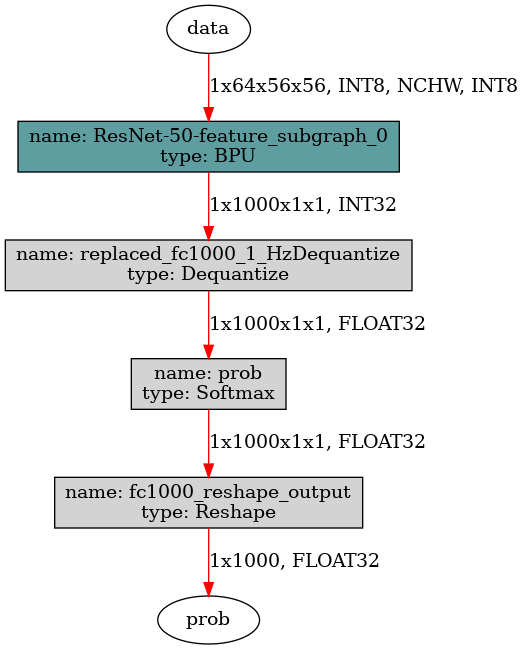
图4
因为输入侧的第一个算子是BPU算子,并且输入在最后一个维度上是56字节,不符合16字节对齐的要求,因此符合上述两条需要用户手动padding的条件,在推理开始前,需要将featuremap输入的W维度padding到64字节。-
和图像数据的步骤类似,padding这一步在prepare_feature_tensor函数中完成。在prepare_feature_tensor函数中,为输入张量分配完对齐后的内存空间后,又使用了tensor_padding_feature函数做padding,我们重点对这个函数进行解读,以下展示了该函数的部分关键代码:
float *feature_data = reinterpret_cast<float *>(data);
float scale = tensor_property.scale.scaleData[0];
int *stride = tensor_property.stride;
int8_t *tensor_data = reinterpret_cast<int8_t *>(tensor->sysMem[0].virAddr);
// do quantize and padding
if (tensor_property.tensorLayout == HB_DNN_LAYOUT_NCHW) {
// for j5 NCHW
for (int n = 0; n < batch; n++) {
for (int c = 0; c < channel; c++) {
for (int h = 0; h < height; h++) {
auto *raw =
tensor_data + n * stride[0] + c * stride[1] + h * stride[2];
for (int w = 0; w < width; w++) {
*raw++ = int_quantize(*feature_data++, scale, 0, -128.f, 127.f);
}
}
}
}
}
在tensor_padding_feature函数中,按照数据排布(layout)区分了NCHW和NHWC两种情况。NCHW需要在W维度满足16字节对齐,NHWC需要在C维度满足16字节对齐。两种数据排布的对齐操作相近,由于示例模型是NCHW,我们就对NCHW进行分析。-
代码依次对N、C、H、W套了4层for循环。考虑到模型的量化节点被删除,因此在最内层W维度的循环中编写了int_quantize函数补上量化计算。padding操作是在H的循环中实现的,stride含义是步长,指的是当前维度每增加1,在内存上需要跨越的字节数,在这个示例中,N的步长stride[0]=64x56x64=229376,C的步长stride[1]=64x56=3584,H的步长stride[2]=64,W的步长stride[3]=1,其中W的步长未使用。-
由于步长stride计算使用的是对齐后的数据,因此每当W维度做完有效的56次量化计算并赋值给_raw后,H维度的_tensor_data指针都会在原先的基础上跨越64字节,相当于让W维度跳了64-56=8字节再继续做量化并将结果赋值给*raw,以实现W维度对齐到64字节,满足16字节对齐的要求,8字节便是padding的部分,无需做量化计算。-
在执行完所有对齐操作后,BPU内存中的数据便会以下图的形式分布:

至此,需要用户主动编写的步骤已经结束。我们为输入数据留下了padding的空间,但并没有给这些空间赋0值,这是因为赋0的操作会在模型推理时,由板端推理库自行完成,不需要用户去写。
tensor_padding_feature函数中使用的步长stride来自hbDNNTensorProperties结构体,注意和跨距(同样叫作stride)的概念作区分。步长stride指的是该维度的数值每增长1,在内存上需要增加的字节数;跨距stride指的是某维度需要对齐/padding到的目标字节数。
总结:以featuremap数据作为模型输入时,用户需要编写完整代码主动做padding,在分配BPU内存后,根据数据排布类型编写for循环,在由内往外的第二层for循环中对需要padding的空间进行跳过,板端推理库会对跳过的空间进行赋0。如果模型删去了输入侧的量化算子,可以在最内层循环中补上量化计算。