您好,
在J3上进行runtime测试时遇到了精度下降的问题,具体情况如下。
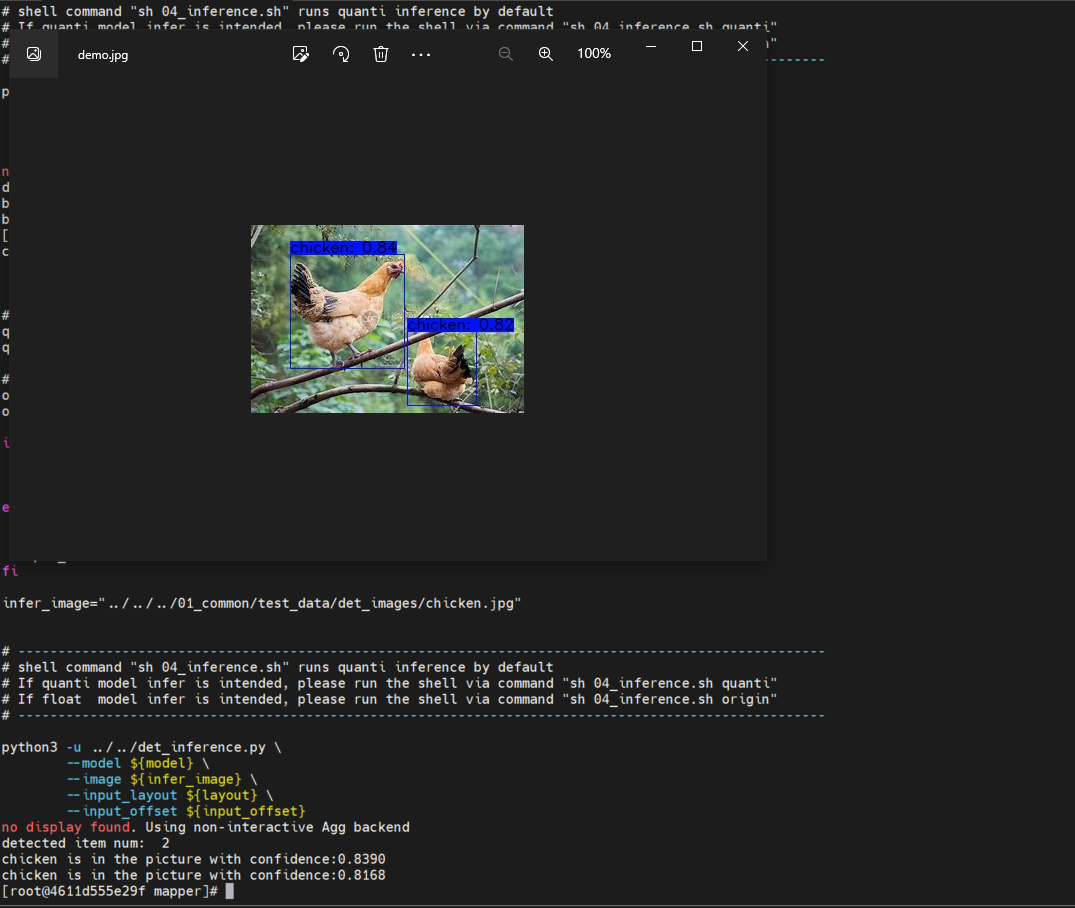
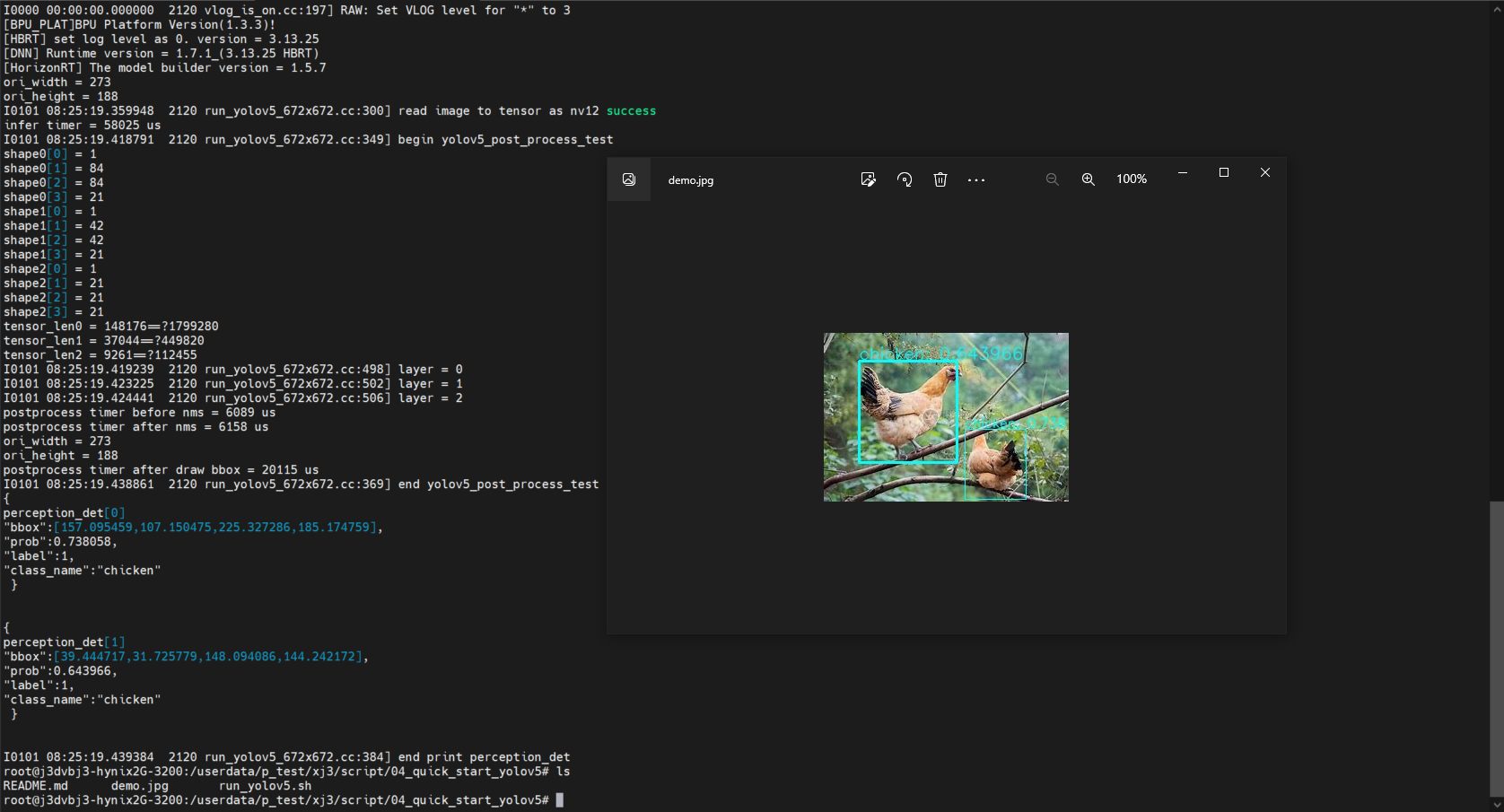
自己训练的yolov5-2.0模型,在J3上进行runtime测试时出现精度下降的问题。如图,第一张是在开发机上转换完成后使用quantized.onnx推理测试的结果,精度还可以(与pt模型检测精度差不多);第二张是用bin模型在J3板端进行runtime推理的结果,前面的目标精度下降明显后面的精度也略有下降。板端后处理的代码是根据aibenchmark中的yolov5后处理改写的,之前使用地平线oe包中的yolov5模型转换出的bin模型上板测试,没有这种精度损失的情况发生,检测结果与开发机上无异。-
后又放在J5上测试了一下,结果和J3上测试结果类似,都是前面目标精度下降明显后面的精度也略有下降。-
会是转换的yaml配置问题吗,我上传了yaml文件在附件中。
如果不是,请问还有哪些排查的方向呢。
yolov5_config_20230612144422.yaml
颜值即正义
2
你好,请参考https://developer.horizon.ai/forumDetail/71036815603174578,1.3节 python端与板端一致性校验,使用hb_verifier工具来验证quantized.onnx与bin模型的一致性
quantized.onnx与bin模型的一致性验证都是passed,应该没问题

感谢回答,是不是只要这个检查通过就说明不是转换过程的问题呀。但这套runtime代码之前用官方的yolov5转出的bin模型测试过kite那张图片,精度没什么问题。我再确认下看看使用官方的yolo是不是准确的。
很奇怪诶,我测试了一下这套代码, 用J5上的yolov5x跑出来的runtime效果没什么问题,比开发机上quantized.onnx的效果还好一点。我那个效果不好的模型只有两个分类,不知道分类结果较少会不会对结果造成影响呢

嗯。。确实是用的同一套的前后处理代码,唯一的差异就是分类个数这里官方是80。有精度损失的这里改成了2。我再看看吧

颜值即正义
8
严格检查通过,说明在bin模型自身是没有问题的,也就是说引起精度下降是在前后处理代码里,建议再认真分析一下~
颜值即正义
9
这个和类别数量多少关系应该不大,可能是处理过程中算法的前后处理代码存在一点差异。
颜值即正义
10
排查到这儿,定位的范围是前后处理代码的差异哈,比如resize方式等等,这些都是开发者们代码层面的细节了