AIoT第二天实验报告
===============
1 图片标注
image.png-
如上图所示,用labelImg工具进行人脸的标注,生成xml文件,文件已上传到教学立方的附件中
2 解析XML代码
XML代码如下
<object>
<name>motorbike</name>
<pose>Right</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>48</xmin>
<ymin>85</ymin>
<xmax>499</xmax>
<ymax>374</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>125</xmin>
<ymin>2</ymin>
<xmax>316</xmax>
<ymax>344</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Frontal</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>44</xmin>
<ymin>4</ymin>
<xmax>128</xmax>
<ymax>167</ymax>
</bndbox>
规定xml代码中motorbike=100(可以写成十进制4),person=010(可以写成十进制2)-
我们已经知道 PPT 中的向量形式是由中心坐标 x,y 和宽度 w 和高度h 表示,和 XML 代码中一样也是由四个数据表示。表示形式如下
y=PCbxbybwbhCy=\begin{matrix}P_{C}\\ b_{x}\\ b_{y}\\ b_{w}\\ b_{h}\\ C \end{matrix}y=PCbxbybwbhC
其中 Pc 是表示有目标的概率,b-box 是表示中心坐标和长宽,C 是独热编码表示类别。公式如下:
bx=(xmin+xmax)/2by=(ymin+ymax)/2bw=xmax−xminbh=ymax−yminbx = (xmin + xmax)/2\\ by = (ymin + ymax)/2 \\ bw = xmax − xmin\\ bh = ymax − yminbx=(xmin+xmax)/2by=(ymin+ymax)/2bw=xmax−xminbh=ymax−ymin
所以计算结果为:
Y=127322945128941220173191342218685841632Y =\begin{matrix} 1\\ 273\\ 229\\ 451\\ 289\\ 4\\ 1\\ 220\\ 173\\ 191\\ 342\\ 2\\ 1\\ 86\\ 85\\ 84\\ 163\\ 2 \end{matrix}Y=127322945128941220173191342218685841632
3 模型准备
3.1 配置准备
由于在容器中使用CPU计算速度较慢,我上网查询了在docker中使用宿主机的GPU的办法,但网上的教程莫衷一是,且较为复杂,所以选择了在主机中用conda创建虚拟环境配置cuda、cudnn直接运行模型下面讲述配置过程(配置也不简单,耗费了我的大量时间)
3.2 选择根据自己电脑cuda选择对应的版本
查看自己电脑cuda版本的命令为nvidia-smi,会显示如下图所示的版本-
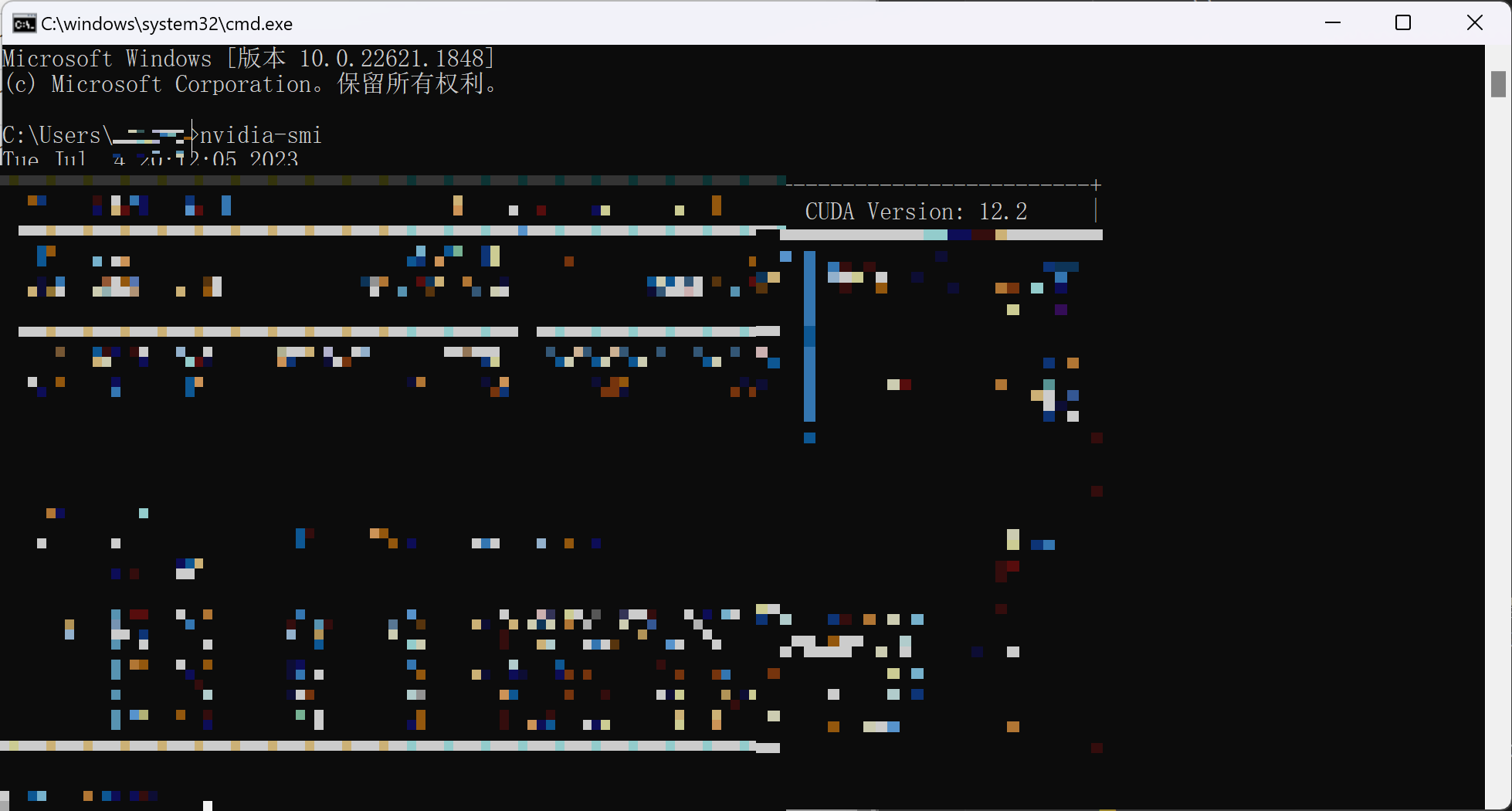
但是这个版本仅仅是电脑可以安装cuda的最高版本,并且是向下兼容的,所以,我选择了安装cuda11.2、cudnn8.1、tensorflow2.6.0,cuda、cudnn、tensorflow的版本对应参考如下网址https://tensorflow.google.cn/install/source_windows?hl=zh-cn#gpu-
之后的安装可以参考https://blog.csdn.net/anmin8888/article/details/127910084然后就是下载对应版本的tensorflow,切记:用pip下载,不要用conda!-
pip的命令为
pip install tensorflow==版本号
3.3 检验是否安装成功
用命令
import tensorflow as tf
tf.test.is_built_with_cuda()
tf.test.is_gpu_available()
来检验。后两行分别是检验cuda是否安装成功和能否检测到gpu。若都是True,恭喜你,之后的内容都不用看了。-
如果是false,也不要着急,只要cuda、cudnn、tensorflow的版本对应没有问题,一定可以实现gpu的调用。-
当你好不容易调的都是True后,在命令行中输入的第一行命令import tensorflow as tf之后又会有这么一句Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found之后可能还会有Could not locate cublas64_12.dll. Please make sure it is in your library path! Could not locate zlibwapi.dll. Please make sure it is in your library path!等等。不要悲伤,不要心急,你离终点已经很近了,都是缺乏一些文件造成的。对于上述第一条报错https://blog.csdn.net/jiankangyq/article/details/121880500对于上述第二条报错,可以参考https://blog.csdn.net/atlasroben/article/details/130479715,第三条报错可以参考https://blog.csdn.net/Jacky__Lv/article/details/128048726
4 成功使用gpu运行完整版YOLO-v3
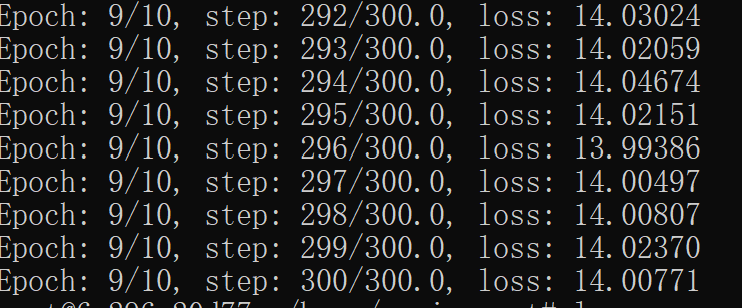
与上午在docker中使用cpu相比,速度明显提升,使用cpu训练了总共2小时左右,使用gpu半小时就训练完了-
整体输出结果如下-
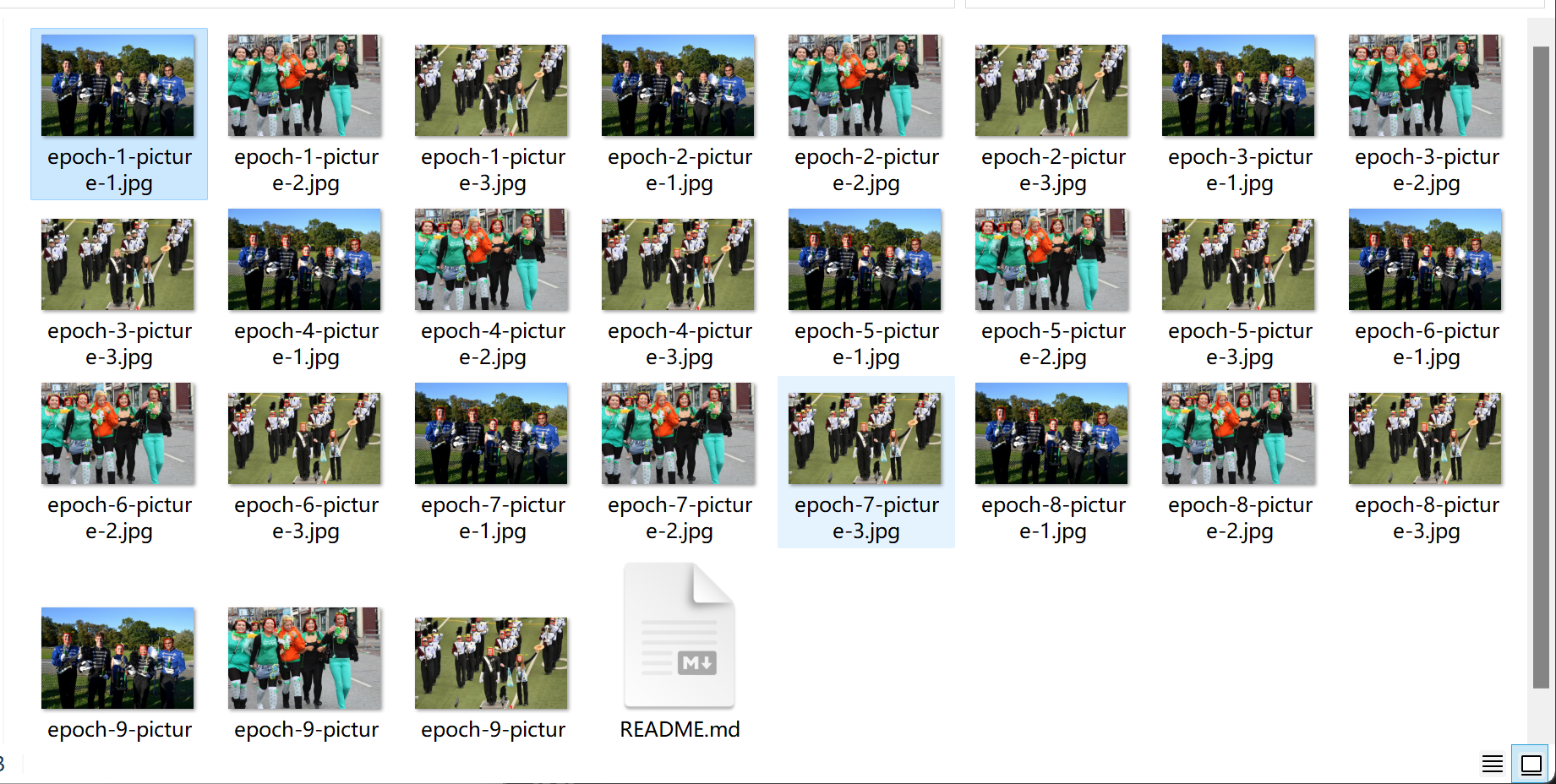
-
这是epoch-1的一张照片,可以看到还没有人脸被识别出来-
-

这是epoch-9中的一张照片,可以看到基本上全部人脸都已识别且准确度较高-

5 成功使用gpu运行剪枝后的模型
整体输出结果如下-
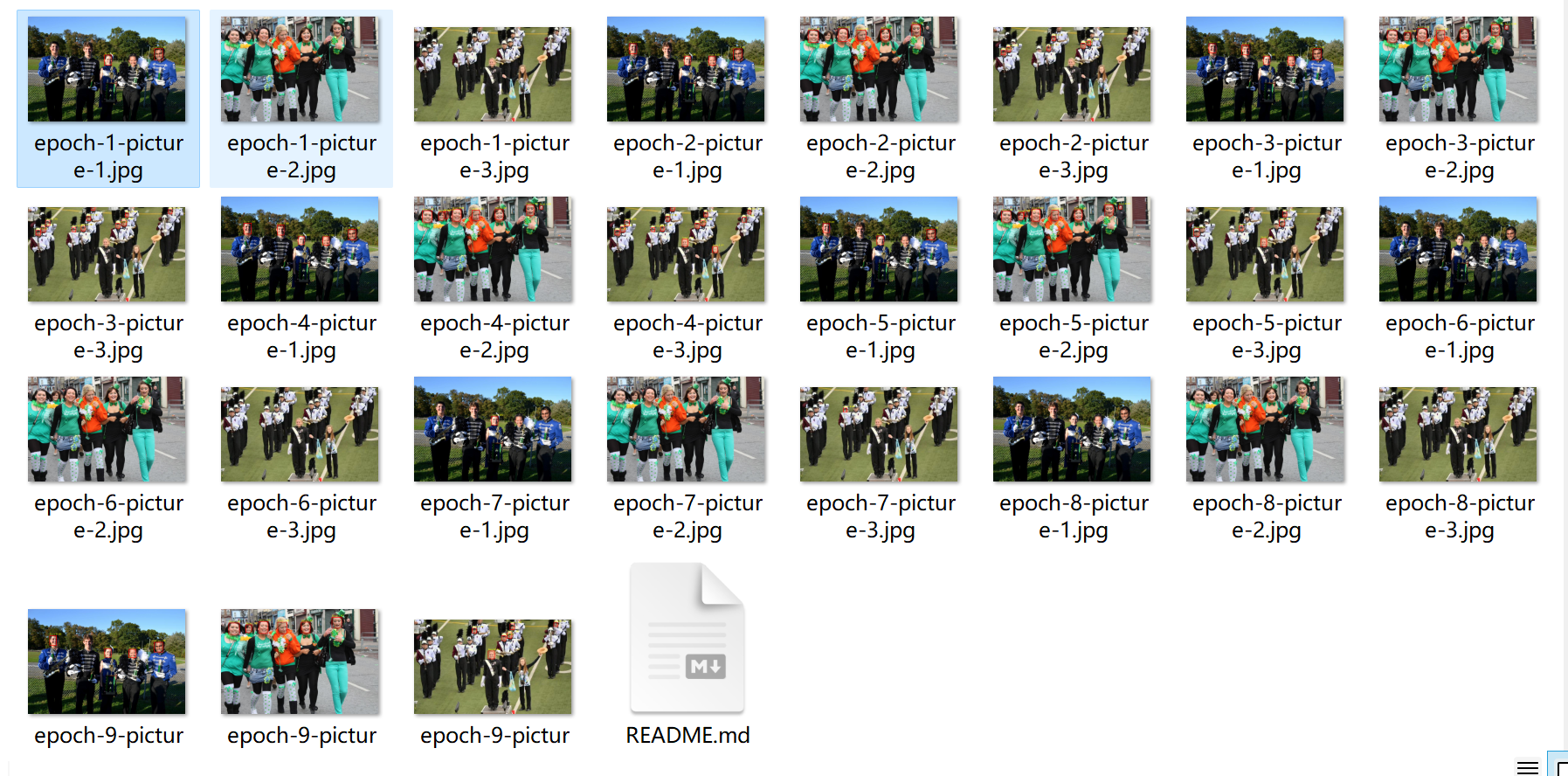
-
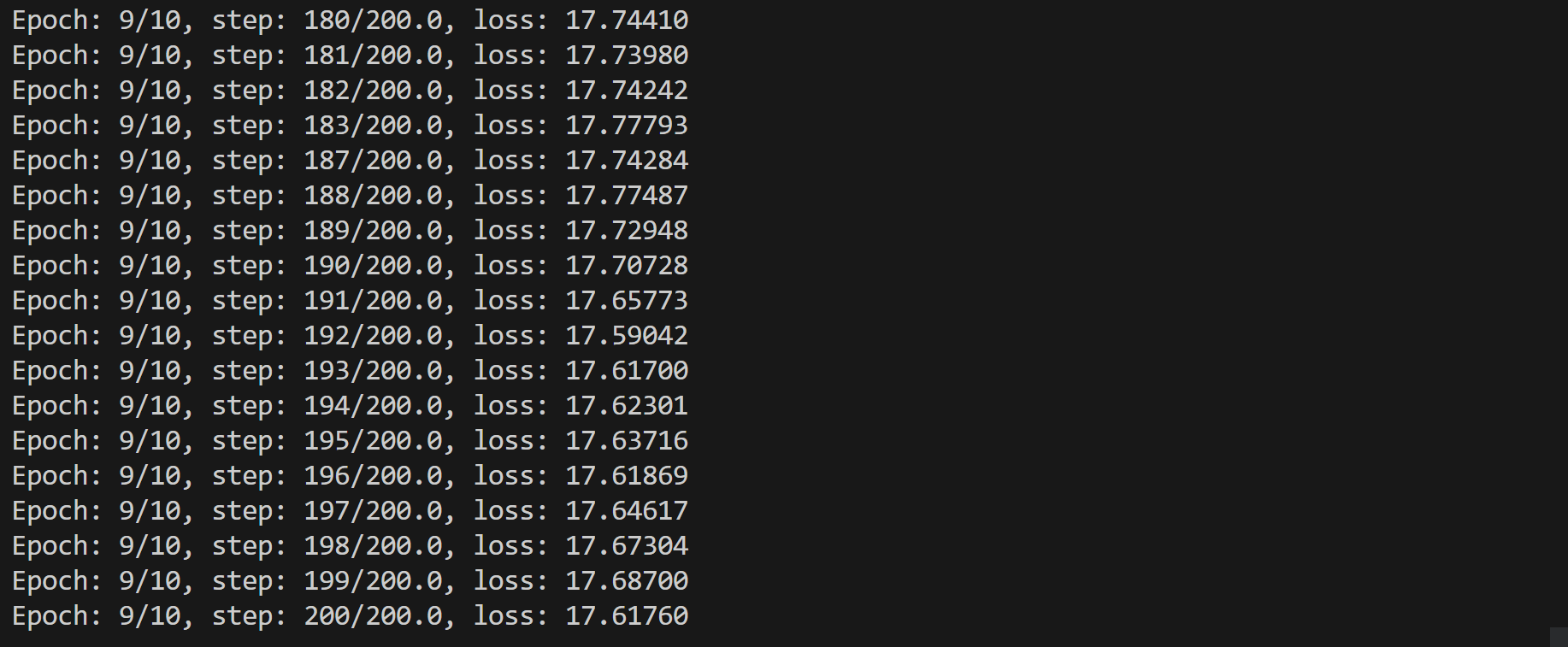
与完整版相同的一张图片在epcho-1中计算结果如下-
-

epcho-9中结果如下-
-

与完整版模型相比,模型较小,计算速度较快,但损失函数也较大,准确度不如完整版,多个人脸未识别出来
{kind=link}