用户您好,请详细描述您所遇到的问题:
你好,我在进行模型转换时候,发现 hb_mapper makertbin会自动将NCHW的输入转换成NHWC格式,且BPU支持的Upsample算子(Resize)要求输入为NCHW,导致模型后续每个Upsample算子前都自动加上了在CPU上运行的 Transpose算子(NHWC2NCHW),这使得模型每帧推断时延(X3派开发板实测)到了1302ms左右,其中自动加的Transpose都带来了很高的时延。
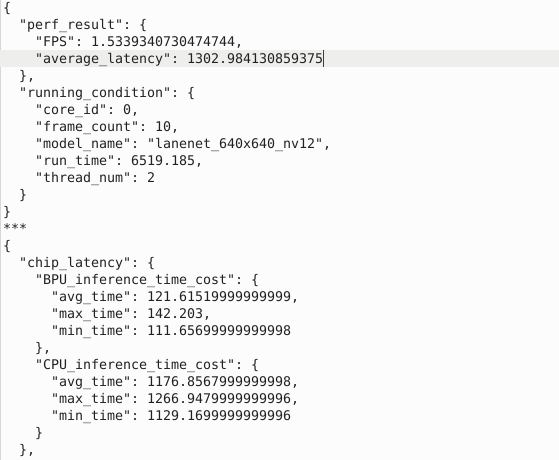
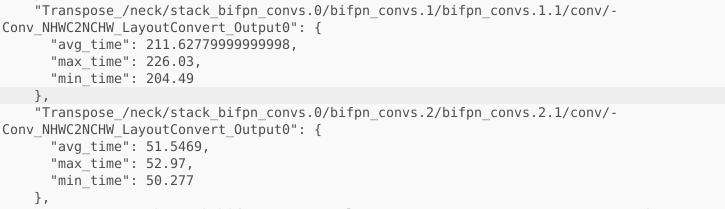
具体受影响存在于原模型的 BiFPN neck 层。
请问这种情况该如何处理?
-
系统软件版本: (通过 cat /etc/version 获得)
-
问题涉及的技术领域: (硬件、操作系统、驱动、其他)
-
问题描述:(尽可能详细的描述在进行什么功能的开发或者测试,发现了什么问题,问题现象,并且提供预期的结果)
-
复现概率:(必现、高、中、低,并描述大致的概率数值) 已进行的排查措施、分析及结果:
-
硬件问题先排查供电和时钟
-
驱动问题先排查外设的供电、复位和时钟
-
功能异常,先排查一下是不是运行的代码和demo存在差异,修改不多的情况下直接用对比软件先对比
-
提供必要的问题日志:
-
软件上是否有做自定义修改: