本博客由于过长,分为上下集来展示,此博客也在CSDNhttps://blog.csdn.net/Zhaoxi_Li/article/details/127820841发布,欢迎各位点赞收藏哈哈。
2.3 阶段3 模型上板:Python推理部署与校验
理论上,阶段2校验③走通了,就一定能在板子上成功推理出来,因为这两者主要区别是模型加载方式不同(一个是onnx一个是bin),因此该阶段的构建流程代码与阶段2校验③的代码高度相似。
但代码跨平台很容易出现问题,因此安全起见,也要规范一下校验流程来定位问题,因此,构建流程部分没有得到正确结果的话,请参考本部分的校验流程。
基于Python的部署主要调用的是pyeasy_dnn,这个包里面的一些函数/类/数据类型的用法我会在后面详细解释。
2.3.1 构建流程
BIN模型的推理代码如下所示,prepare_functions 中的函数get_rgb_image, preprocess_onboard, postprocess在这里可以直接复用。而模型的推理和加载也非常简单。代码细节见detect_bin.py,在torchdnn的根目录下执行sudo python demos/unet/detect_bin.py(这个代码只能在开发板中运行)。
import numpy as np
import cv2
import os
from prepare_functions import get_bgr_image, preprocess_onboard, postprocess
from hobot_dnn import pyeasy_dnn as dnn
# 记得要安装一些包
# sudo pip3 install scipy opencv-contrib-python
def get_hw(pro):
if pro.layout == "NCHW":
return pro.shape[2], pro.shape[3]
else:
return pro.shape[1], pro.shape[2]
dataroot = "data/unet"
imgpath = os.path.join(dataroot, "mra_img_12.jpg")
binpath = os.path.join(dataroot, "model_output/unet.bin")
# 加载图像和BIN模型
img = get_bgr_image(imgpath)
models = dnn.load(binpath)
# 图像数据预处理,这里对几个地方进行解释:
# models[0]:BPU支持加载多个模型,这里只有一个unet,因此[0]表示访问第一个模型
# inputs[0]:模型输入可能多种,unet的输入只有一个,因此[0]表示获取第一个输入的参数
model_h, model_w = get_hw(models[0].inputs[0].properties)
datain = preprocess_onboard(img, model_h, model_w) # 1x256x256x3
# 模型推理:相比于onnx推理,这里不用再重新构造一个inputs
t1 = cv2.getTickCount()
outputs = models[0].forward(datain)
t2 = cv2.getTickCount()
print('time consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency()))
# 后处理并保存结果,这里对几个地方进行解释
# outputs数据类型为tuple,每个元素的数据类型是pyDNNTensor
# 因此想要获取输出的矩阵的话,需要调用buffer
pred = postprocess(outputs[0].buffer) # outputs[0].buffer: (1, 2, 256, 256)
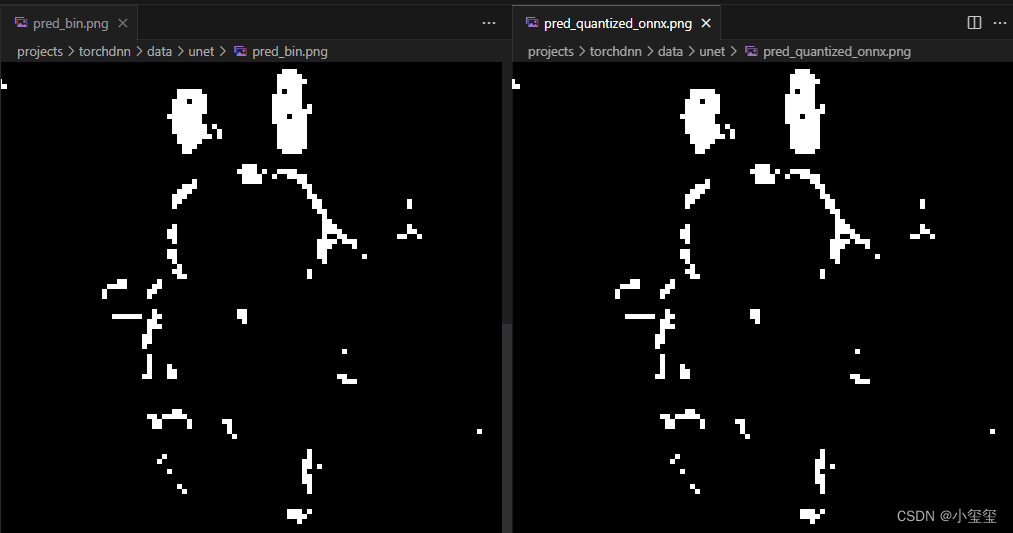
cv2.imwrite(os.path.join(dataroot, "pred_bin.png"), pred[0])
对比unet.bin和unet_quantized_model.onnx,结果是一模一样的,所以,转换模型后,在docker里就可以直接验证我们的量化模型是否可以用在开发板上。
2.3.2 校验流程
如果本阶段的构建流程无法得到有效推理结果,则需要按照下面的校验项依序处理,只要校验不通过,说明unet_quantized_model.onnx转unet.bin的过程除了问题,在地平线社区反馈问题交给技术人员检查。
PS:如果校验都通过,那就认真检查下推理的前后处理吧,肯定是某个细节写错了→_→。
其实这里的校验流程应该需要补充个unet_quantized_model.onnx在开发板的校验,但是推理这个onnx,依赖from horizon_nn import horizon_onnxruntime,这个包只能在docker中运行,不能在开发板运行(里面有个so文件依赖docker)。(希望官方后续能在开发板支持horizon_nn的使用)
① BIN量化模型上板校验
这里的校验BIN,就是直接输入推理数据,与理论的输出数据进行对比(datain和dataout是阶段2校验③中生成的校验数据),解除前后处理的耦合影响。代码细节见detect_bin.py,在torchdnn的根目录下执行sudo python demos/unet/check_bin_onboard.py(这个代码只能在开发板中运行)。
dataroot = "data/unet"
data = np.load(os.path.join(dataroot, "unet_checkstage2.npz"))
datain = data["datain"]
dataout = data["dataout"]
###### 检查量化BIN有效性
binpath = os.path.join(dataroot, "model_output/unet.bin")
models = dnn.load(binpath)
outputs = models[0].forward(datain)
check_matrix_equal(outputs[0].buffer, dataout, 1e-4, dataroot, "onnxonboard")
2.3.3 pyeasy_dnn内容分析
Python版本的推理包hobot_dnn是C++推理的封装,只留下了简单的推理过程,因此在实际落地应用时,建议使用C++部署。hobot_dnn里面只有一个pyeasy_dnn.so,存放地址/usr/local/lib/python3.8/dist-packages/hobot_dnn/pyeasy_dnn.so。利用from hobot_dnn import pyeasy_dnn as dnn导入包之后,执行print(help(dnn))可以看到dnn内部的注释信息。
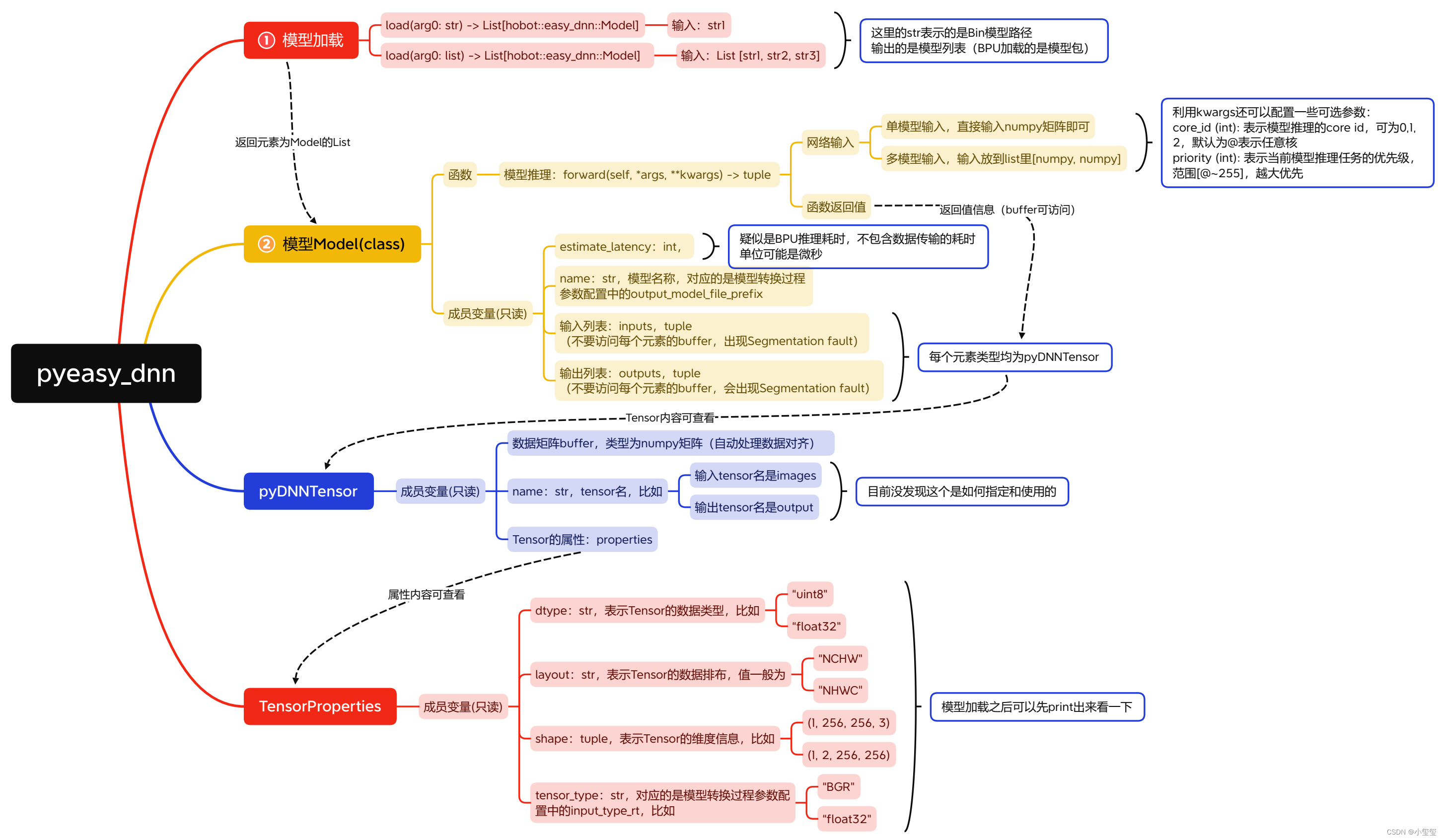
为了更好的理解dnn里面都有哪些内容,我在这里进行了详细分析,官网手册《5.4. 模型推理接口说明》里给出了简单的介绍。我个人觉得pyeasy_dnn的设计还是可以的,至少用户在操作时,不需要掌握太多的新知识(学习成本低)。里面有三种数据类型Model,TensorProperties,pyDNNTensor。
为了更好的理解所有Class和Functions之间的关系,我下面给出一个思维导图,利用这张图在部署时候,就能随意调取相关的属性,完成自己的算法落地。
2.4 阶段4 模型上板:C++推理部署与校验
Python适用于快速算法验证,验证无误后,需要转换为C++落地。任何嵌入式应用基本都无法脱离C++,因为相比于Python,C++执行的速度更快,能够节省嵌入式本来就有限的资源。BPU提供的SDK是C接口,可以根据自己的需求做优化。BPU的相关API文档参考链接:5.2. BPU SDK API手册。
C语言接口,在提高了开发灵活性的同时,也降低了开发的安全性。因为操作基于指针,内存的分配与释放、数据对齐拷贝由用户来管理,很容易出现部署失败但不知如何Debug出问题,本节会讲清楚C语言部署/校验的流程。
此外,考虑到部署的不安全性,我自己在C接口的基础上,补充了一个C++的API,以减少学习成本,提高部署安全性,这个会在下一章节(wdr::BPU部署)介绍。
2.4.1 编译配置
大部分Linux的代码都通过CMake进行编译,C++推理依赖项整理如下:
- 头文件:BPU部署相关的头文件存放在
/usr/include/dnn/,配置时候不需要利用include_directories指定头文件目录,大部分的BPU部署直接在代码中添加下面两行代码即可#include <dnn/hb_dnn.h>和#include <dnn/hb_sys.h>。若有函数找不到,就去dnn根目录下查找对应的函数头文件。 - 库文件:BPU相关的库文件存放在
/usr/lib/hbbpu/中,因此需要在CMakeList.txt中补充库目录link_directories(/usr/lib/hbbpu/),编译最终可执行文件时,在target_link_libraries中补充相关库-ldnn -lcnn_intf -lhbrt_bernoulli_aarch64。(PS:除了这个还有libhlog.so,这个就是打印日志用的,我觉得可以用glog替代,就不使用这个了。)
博客里相关的C++代码都放置在github上:https://github.com/Li-Zhaoxi/OpenWanderary,编译流程如下:
# 安装OpenCV:不要用X3自带的opencv,版本低,不完整。
sudo apt-get install libopencv-dev
# 安装boost:如果编译出错,再安装这两个libboost-filesystem1.71-dev libboost-wave1.71-dev
sudo apt-get install libboost1.71-all-dev
git clone https://github.com/Li-Zhaoxi/OpenWanderary.git
cd OpenWanderary
mkdir build && cd build
cmake -DCMAKE_BUILD_TYPE=Release ..
# 根据内存情况选择-j4还是-j2
# 这里编译会编译所有项目,后续会补充选择性编译的功能,欢迎关注OpenWanderary仓库
make -j4
2.4.2 构建流程
下面我们开始着手写C++部署代码,代码细节见infer_unet_standalong.cpp中的函数void infer_unet(),在OpenWanderary的根目录下执行sudo ./build/examples/BPU/infer_unet_standalong --mode infer(这个代码只能在开发板中运行)。
下面对代码中的一些关键内容进行讲解。
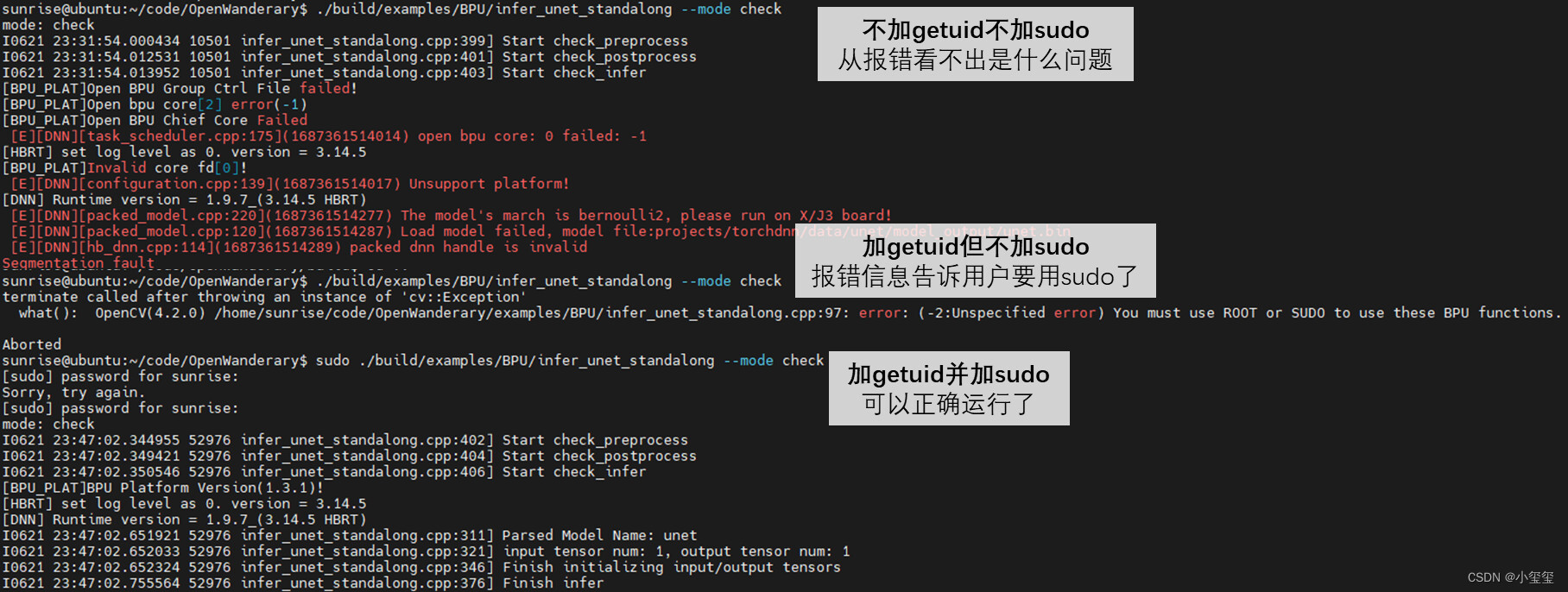
① 通过代码判断代码执行是否用了sudo。在介绍正式内容之前,我先说下咱们开发常遇见的一个坑:调用BPU是需要sudo权限的,但我们经常会忘记用sudo。使用getuid函数(在#include <unistd.h>里) 可以避免这个问题,在main函数里面第一行加入如下代码
int main(int argc, char **argv)
{
if (getuid())
CV_Error(cv::Error::StsError, "You must use ROOT or SUDO to use these BPU functions.");
/// 各种代码
}
这样当我们忘记使用sudo时候,代码就可以直接反馈错误信息
② 构建C++版本的预/后处理函数。对比着前面Python版本的预处理函数preprocess_onboard和后处理函数postprocess,复现对应的C++版本,关键代码细节如下所示。具体细节没什么好说的,我这里特别介绍下C++代码里多维矩阵定义和使用的技巧。
void preprocess_onboard(const cv::Mat img, int modelh, int modelw, cv::Mat &datain)
{
cv::Mat tmp;
// Python: img = cv2.resize(img, (modelw, modelh))
cv::resize(img, tmp, cv::Size(modelw, modelh));
// Python: img = np.expand_dims(img, 0)
// Python: img = np.ascontiguousarray(img)
std::vector<int> dims = {1, tmp.rows, tmp.cols, tmp.channels()};
datain.create(dims.size(), dims.data(), CV_MAKETYPE(img.depth(), 1));
memcpy(datain.data, tmp.data, tmp.total() * tmp.elemSize());
}
void postprocess(const cv::Mat outputs, cv::Mat &pred)
{
// 格式检查:保证outputs的维度是[b,2,h,w],数据类型为float
CV_Assert(outputs.size.dims() == 4 && outputs.channels() == 1 && outputs.type() == CV_32F);
int b = outputs.size[0], c = outputs.size[1], h = outputs.size[2], w = outputs.size[3];
CV_Assert(c == 2);
// Python: y_list = softmax(outputs, axis = 1)[:, 1, :, :]
// Python:y_list = (y_list > 0.5).astype(np.uint8) * 255
// 这里可以简化为,比较[:, 1, :, :]和[:, 0, :, :]的大小,若前景大于背景,Label给255
std::vector<int> dims = {b, h, w};
pred.create(dims.size(), dims.data(), CV_8UC1);
for(int i = 0; i < b; i++)
{
float *_bdata = ((float*)outputs.data) + i * c * h * w; // 背景指针
float *_fdata = _bdata + h * w; // 前景指针
unsigned char *_label = pred.data + i * h * w;
int total_hw = h * w;
for(int k = 0; k < total_hw; k++, _label++, _bdata++, _fdata++)
*_label = *_fdata > *_bdata ? 255 : 0;
}
}
多维矩阵的构建 。正常的opencv矩阵的宽高通过其中的rows和cols访问,通道数调用channels()这个函数获取。对于多维矩阵,比如1x256x256x3的矩阵,我们就得用下面这种方式定义:
cv::Mat datain;
std::vector<int> dims = {1, 256, 256, 3}; // 定义矩阵维度信息
datain.create(dims.size(), dims.data(), CV_32FC1); // 构建多维矩阵,C1固定不要变
如果用了这种方式构建矩阵,有一些地方需要注意下:
datain.rows和datain.cols的值均为-1,维度个数可通过datain.size.dims()获取,其第k维大小可通过datain.size[k]获取。datain.at<float>(i,j)这种访问元素的形式失效。只能利用数据指针(float*)datain.data来访问元素。
③ C++部署调用API详解。下面给出调用BPU的C接口API进行推理的完整流程,下面我给出BPU部署的代码流程图,各位可以对着这个流程去看相关的代码。
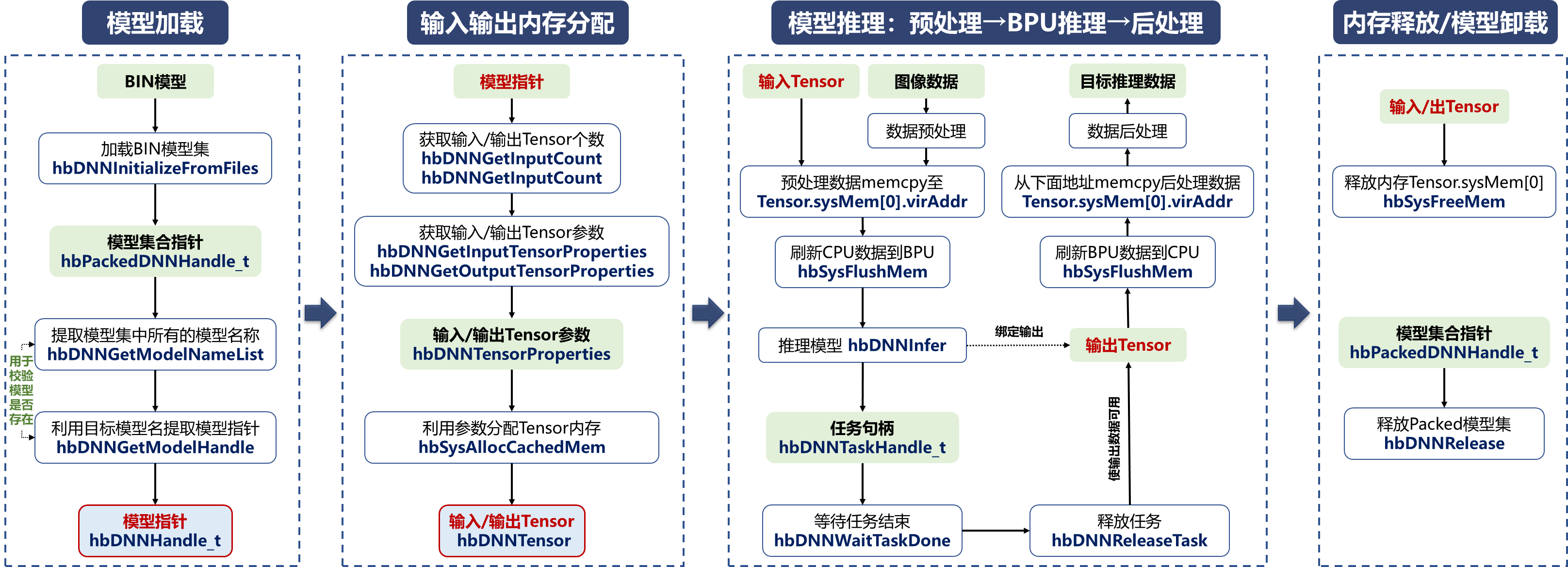
在给出代码细节之前,我先说几个注意点:
-
流程图中模型推理这一过程,绑定输出表示输出的Tensor作为参数输入到hbDNNInfer中。
-
在推理代码中,BPU推理API操作的是硬件,这里应该对每个BPU函数套用一个
HB_CHECK_SUCCESS来检查是否成功执行,比如HB_CHECK_SUCCESS(hbDNNInitializeFromFiles(&pPackedNets, cpaths, pathnum), "hbDNNInitializeFromFiles failed");,为了方便理解流程,下面的代码省去了HB_CHECK_SUCCESS。下面这个代码片给出的定义。#define HB_CHECK_SUCCESS(value, errmsg)
do {
/value can be call of function/
auto ret_code = value;
if (ret_code != 0) {
LOG(ERROR) << errmsg << “, error code:” << ret_code;
abort();
}
} while (0);
详细BPU的C++推理代码如下所示,执行之后会保存推理结果,推理结果跟Python版本推理结果是一样的,这里就不再展示了。
void infer_unet()
{
std::string dataroot = "projects/torchdnn/data/unet/";
std::string binpath = dataroot + "model_output/unet.bin";
std::string imgpath = dataroot + "mra_img_12.jpg";
// -----------------模型加载部分--------------------
// 1. 加载BIN模型集
hbPackedDNNHandle_t packed_dnn_handle; // 模型集合指针
const char *model_file_name = binpath.c_str();
hbDNNInitializeFromFiles(&packed_dnn_handle, &model_file_name, 1);
// 2. 提取模型集中所有的模型名称
const char **model_name_list;
int model_count = 0;
hbDNNGetModelNameList(&model_name_list, &model_count, packed_dnn_handle);
for (int k = 0; k < model_count; k++) // 输出提取出的所有模型的名称
LOG(INFO) << "Parsed Model Name: " << std::string(model_name_list[k]);
// 3. 利用目标模型名提取模型指针
hbDNNHandle_t dnn_handle; // ※模型指针
hbDNNGetModelHandle(&dnn_handle, packed_dnn_handle, model_name_list[0]);
// -----------------输入输出内存分配--------------------
// 1. 获取输入/输出Tensor个数
int input_tensornum = 0, output_tensornum = 0;
hbDNNGetInputCount(&input_tensornum, dnn_handle);
hbDNNGetOutputCount(&output_tensornum, dnn_handle);
LOG(INFO) << "input tensor num: " << input_tensornum << ", output tensor num: " << output_tensornum;
// 2. 获取输入/输出Tensor参数
std::vector<hbDNNTensorProperties> input_properties, output_properties; // 输入/输出Tensor参数
input_properties.resize(input_tensornum), output_properties.resize(output_tensornum);
for (int k = 0; k < input_tensornum; k++)
hbDNNGetInputTensorProperties(&input_properties[k], dnn_handle, k);
for (int k = 0; k < output_tensornum; k++)
hbDNNGetOutputTensorProperties(&output_properties[k], dnn_handle, k);
// 3. 利用参数分配Tensor内存
std::vector<hbDNNTensor> input_tensors, output_tensors; // ※输入/输出Tensor
input_tensors.resize(input_tensornum), output_tensors.resize(output_tensornum);
for (int k = 0; k < input_tensornum; k++)
{
const auto &property = input_properties[k];
input_tensors[k].properties = property;
hbSysAllocCachedMem(&input_tensors[k].sysMem[0], property.alignedByteSize);
}
for (int k = 0; k < output_tensornum; k++)
{
const auto &property = output_properties[k];
output_tensors[k].properties = property;
hbSysAllocCachedMem(&output_tensors[k].sysMem[0], property.alignedByteSize);
}
LOG(INFO) << "Finish initializing input/output tensors";
//////// Tensor详细属性信息如下:
// input[0]:
// valid shape: (1,256,256,3,)
// aligned shape: (1,256,256,4,)
// tensor type: HB_DNN_IMG_TYPE_BGR
// tensor layout: HB_DNN_LAYOUT_NHWC
// quanti type: SHIFT
// shift data: 0,0,0,
// output[0]:
// valid shape: (1,2,256,256,)
// aligned shape: (1,2,256,256,)
// tensor type: HB_DNN_TENSOR_TYPE_F32
// tensor layout: HB_DNN_LAYOUT_NCHW
// quanti type: NONE
// -----------------模型推理:预处理→BPU推理→后处理--------------------
cv::Mat img, datain, dataout, pred;
// 1. 加载图像&&图像预处理
get_bgr_image(imgpath, img);
cv::Size tensorhw = get_hw(input_tensors[0].properties);
LOG(INFO) << "Loaded img size: " << img.size() << ", target size: " << tensorhw;
preprocess_onboard(img, tensorhw.height, tensorhw.width, datain);
LOG(INFO) << "Finish preprocess_onboard";
// 由于输入和BPU的Tensor存在不对齐问题,因此需要配置为自动对齐
// input_tensors[0]: valid shape: (1,256,256,3,),aligned shape: (1,256,256,4,)
auto &tensor = input_tensors[0];
tensor.properties.alignedShape = tensor.properties.validShape;
// 2. 预处理数据memcpy至BPU
memcpy(tensor.sysMem[0].virAddr, datain.data, datain.total() * datain.elemSize());
// 3. 刷新CPU数据到BPU
hbSysFlushMem(&tensor.sysMem[0], HB_SYS_MEM_CACHE_CLEAN);
// 4. 推理模型
hbDNNTaskHandle_t task_handle = nullptr; // 任务句柄
hbDNNInferCtrlParam infer_ctrl_param;
HB_DNN_INITIALIZE_INFER_CTRL_PARAM(&infer_ctrl_param);
auto ptr_outtensor = output_tensors.data();
hbDNNInfer(&task_handle, &ptr_outtensor, input_tensors.data(), dnn_handle, &infer_ctrl_param);
// 5. 等待任务结束
hbDNNWaitTaskDone(task_handle, 0);
// 6. 释放任务
hbDNNReleaseTask(task_handle);
// 7. 刷新BPU数据到CPU
hbSysFlushMem(&(output_tensors[0].sysMem[0]), HB_SYS_MEM_CACHE_INVALIDATE);
// 8. 从Tensor地址memcpy后处理数据
dataout.create(output_tensors[0].properties.alignedShape.numDimensions,
output_tensors[0].properties.alignedShape.dimensionSize, CV_32FC1);
memcpy(dataout.data, (unsigned char *)output_tensors[0].sysMem[0].virAddr, dataout.total() * dataout.elemSize());
LOG(INFO) << "Finish infer";
// 9. 数据后处理+保存最终分割结果
postprocess(dataout, pred);
int offset = pred.size[1] * pred.size[2] * pred.elemSize();
for(int k = 0; k < pred.size[0]; k++)
{
cv::Mat batchpred(pred.size[1], pred.size[2], CV_8UC1, pred.data + k * offset);
cv::imwrite(dataroot + "pred_bin_cpp_b" + std::to_string(k) + ".png", batchpred);
}
//////////// 模型推理:预处理→BPU推理→后处理 ////////////
// 1. 释放内存
for (auto &input : input_tensors)
hbSysFreeMem(&(input.sysMem[0]));
for (auto &output : output_tensors)
hbSysFreeMem(&(output.sysMem[0]));
// 2. 释放模型
hbDNNRelease(packed_dnn_handle);
}
2.4.3 校验流程
从Python代码转C++代码,一下次就成功是很难的,这里的校验就非常关键了。这阶段的校验过程包含三个阶段:预处理、后处理、BIN模型校验,相比于其他几个阶段,这里的校验相互独立。
这个阶段的校验流程如下所示,所有校验过程存在infer_unet_standalong.cpp中的函数void check_all()中,在OpenWanderary的根目录下执行sudo ./build/examples/BPU/infer_unet_standalong --mode check保存所属有输出结果为npy文件,之后在torchdnn的根目录下执行python3 demos/unet/check_cpp_onboard.py完成各个阶段的输出数据校验。

值得注意,npz文件在python下的读写很简单,但在校验过程中,大部分代码在C++中实现,有npz文件读写的需求。因此我们使用了一个库cnpy来满足我们的需求,github地址为:https://github.com/rogersce/cnpy。我将其中的核心代码复制到OpenWanderary/3rdparty/cnpy中,编译时候已经链接了这个库了。void check_all()的代码细节如下所示,所有的校验过程代码都记录在这里。
void check_all()
{
std::string dataroot = "projects/torchdnn/data/unet/";
std::string npzpath = dataroot + "unet_checkstage2.npz";
std::string binpath = dataroot + "model_output/unet.bin";
std::string savepath = dataroot + "unet_checkcppresults.npz";
// 加载各阶段理论值npz文件
cnpy::npz_t datanpz = cnpy::npz_load(npzpath);
cv::Mat datain, dataout, pred;
// (1) 预处理校验过程:输入理论图像数据,返回预处理结果
LOG(INFO) << "Start check_preprocess";
// 通过字符串可直接访问npz中的数据,返回cnpy::NpyArray
check_preprocess(datanpz["image"], datain);
// (2) 后处理校验过程:输入推理理论输出,返回后处理预测结果
LOG(INFO) << "Start check_postprocess";
check_postprocess(datanpz["dataout"], pred);
// (3) 推理校验过程:输入推理所需的理论值,返回推理结果
LOG(INFO) << "Start check_infer";
check_infer(binpath, datanpz["datain"], dataout);
// 保存各个阶段的输出值到npz文件
LOG(INFO) << "Start saving results";
cnpy::npz_save(savepath, "datain", (unsigned char*)datain.data, get_shape(datain), "w");
cnpy::npz_save(savepath, "dataout", (float*)dataout.data, get_shape(dataout), "a");
cnpy::npz_save(savepath, "pred", (unsigned char*)pred.data, get_shape(pred), "a");
LOG(INFO) << "Finish saving results in " << savepath;
}
① C++板端预处理校验
板端预处理校验就是检查C++版的preprocess_onboard是否正确,函数输入是标准的图像格式(不是多维矩阵的构造方式),也就是img.rows>0。
arr_image的输入维度我们是预先知道的,矩阵排布为���_HWC_,数据类型为uint8,因此利用img.create(arr_image.shape[0], arr_image.shape[1], CV_MAKETYPE(CV_8U, arr_image.shape[2]));完成图像矩阵的定义,假如图像为3通道,则CV_MAKETYPE(CV_8U, arr_image.shape[2])等价于CV_8UC3。
img.total() * img.elemSize()是这个矩阵的总共字节数,利用memcpy实现内存的拷贝。
预处理函数校验的代码细节如下所示:
void check_preprocess(const cnpy::NpyArray &arr_image, cv::Mat &datain)
{
// Load image
cv::Mat img;
CV_Assert(arr_image.shape.size() == 3);
img.create(arr_image.shape[0], arr_image.shape[1], CV_MAKETYPE(CV_8U, arr_image.shape[2]));
memcpy(img.data, arr_image.data<unsigned char>(), img.total() * img.elemSize());
// Get datain
preprocess_onboard(img, 256, 256, datain);
}
② C++板端后处理校验
板端后处理校验就是检查C++版的postprocess是否正确。要注意,函数输入是多维矩阵,这时构造的后处理输入矩阵dataout.rows<0。
我们已经预先知道了后处理输入是一个4维float的矩阵,因此数据类型指定为CV_32FC1即可,后处理函数校验的代码细节如下所示:
void check_postprocess(const cnpy::NpyArray &arr_dataout, cv::Mat &pred)
{
// Load dataout
cv::Mat dataout;
std::vector<int> dims = get_dims(arr_dataout);
dataout.create(dims.size(), dims.data(), CV_32FC1);
memcpy(dataout.data, arr_dataout.data<unsigned char>(), dataout.total() * dataout.elemSize());
// Get pred
postprocess(dataout, pred);
}
③ C++板端推理校验
板端推理校验就是检查C++版的BPU推理是否正确,我们只需要给它推理输入即可。要注意,函数输入是多维矩阵,这时构造的后处理输入矩阵dataout.rows<0。我们已经预先知道了后处理输入是一个4维float的矩阵,因此数据类型指定为CV_32FC1即可。
这个校验过程的代码包含一堆BPU模型加载/初始化/释放相关的代码,为了减少冗余,我只放上不一样的地方。
void check_infer(const std::string &binpath, const cnpy::NpyArray &arr_datain, cv::Mat &dataout)
{
// Load datain
cv::Mat datain;
CV_Assert(arr_datain.shape.size() == 4);
std::vector<int> dims = get_dims(arr_datain);
datain.create(dims.size(), dims.data(), CV_8UC1);
memcpy(datain.data, arr_datain.data<unsigned char>(), datain.total() * datain.elemSize());
....... // 省略模型加载/Tensor初始化等代码
// 预处理数据memcpy至BPU。在推理过程:这里是要加载图像→预处理得到 datain。
memcpy(tensor.sysMem[0].virAddr, datain.data, datain.total() * datain.elemSize());
....... // 省略模型推理,任务释放等代码
// 记录模型推理输出到dataout。在推理过程:这里需要利用dataout进行后处理得到最终pred推理结果。
dataout.create(output_tensors[0].properties.alignedShape.numDimensions,
output_tensors[0].properties.alignedShape.dimensionSize, CV_32FC1);
memcpy(dataout.data, (unsigned char *)output_tensors[0].sysMem[0].virAddr, dataout.total() * dataout.elemSize());
....... // 省略模型释放/Tensor内存释放等代码
}
三 基于wdr::BPU的模型部署方案
从上面内容的介绍,我们可以了解了整体BPU的部署方案,整个方案是比较长的,特别是C++部署。
- 官方提供的BPU函数接口是C语言的。C语言是面向过程的语言,因此对于开发者来说,就存在很多不安全地方:操作是指针,内存分配和释放由用户指定,因此需要较多的学习和Debug成本。
- C++是面向对象的。既然是面向对象,就要考虑到开发者可能面临的一些错误,也就意味着C语言中存在的一些不安全性要从工具/代码的角度主动避免。
为了降低部署BPU的各种不安全性和开发成本,我总结了自己开发过程中遇到的一些问题,设计了一个BPU部署工具OpenWanderary(WDR)。WDR开发了2个月,利用业余时间开发完成,代码量接近3k行,开发模式参考了Effective C++,尽可能参考其中的条款。WDR的设计,是简化用户操作难度,加速部署效率,我走过的坑不希望你们重复走。剩下的时间做些更有意义的事情。
这套工具具有以下几个优点:
-
不需要开发者特意去学习更多的数据类型。数据操作以OpenCV的Mat为主,只要OpenCV用的比较熟,就很容易理解这个框架的使用方法。
-
大量重载运算符来意会功能。
-
比如访问第i个网络,直接用
net[i]即可。 -
若想将推理输入Mat矩阵
datain输入到第i个tensor中,则bpumats[i] << datain即可。将第i个tensor数据输出到Mat矩阵dataout中,则bpumats[i] >> dataout即可。这样极大降低用户操作成本。 -
规避了大量潜在的用户操作成本。
-
代码中大量使用
CV_Error来判断用户的输入是否合法,不合法的输入将会给出详细的报错信息。 -
代码中也补充了大量开发者可能需要的API,矩阵/推理的基本操作都已经实现了。输入Tensor存在数据对齐问题,用户通过指定某个变量维true,交给工具完成自动对齐。
-
Mode和Tensor的内存是自动释放的。在使用时,我们只需要初始化一下Tensor即可,在代码结束后,释放工作由库自动调用析构函数完成。
-
提供了多个功能的独立API函数,方便做更灵活的二次开发(目前还在测试中,后续会根据自己的需求不断完善)。
WDR中由三个关键的Class,这里简要说明下其作用,更多功能可以查看wanderary/BPU/bpu.h。
BpuNets:多模型加载,初始化Tensor,以及推理。BpuMats:模型的输入/输出组,用于推理。BpuMat:每个Tensor的数据交互,BpuMats[idx]返回的就是BpuMat类型。
这个工具目前还在不断优化中,这里会给出一些demo来展示开发的库的方便性,文档之类的,待经过大量验证, 成熟了之后会单独发版,如果各位在使用时候出现Bug,欢迎反馈,一起调试。(业余时间开发的,时间很紧张,使用时候出现的问题求各位轻喷 ? )
下面基于WDR工具,给出两种C++部署功能。
3.1 利用WDR打印模型参数信息
代码细节见examples/BPU/print-infos.cpp中的函数test_class,在OpenWanderary的根目录下执行sudo ./build/examples/BPU/print-infos --binpath projects/torchdnn/data/unet/model_output/unet.bin --mode class,即可输出模型的各种信息。
int test_class(const boost::filesystem::path &binpath)
{
// 0. 加载模型
wdr::BPU::BpuNets nets;
nets.readNets({binpath.string()}); // 加载模型
// 1. 打印模型个数,以及模型名称
std::stringstream ss;
ss << "model num: " << nets.total() << ", model names: ";
for (int k = 0; k < nets.total(); k++)
ss << nets.index2name(k) << ", ";
LOG(INFO) << ss.str(), ss.clear();
// I0623 18:25:22.159559 1268383 print-infos.cpp:61] model num: 1, model names: unet
// 2. 打印第一个模型的输入Tensor的第一个Tensor
LOG(INFO) << nets[0][wdr::BPU::NET_INPUT][0];
// I0623 18:25:22.159651 1268383 print-infos.cpp:64] [hbDNNTensorProperties] List Properties:
// {
// "alignedShape": "[hbDNNTensorShape] dim: 4 [1x256x256x4]",
// "quantiType": 262144,
// "scale": "[hbDNNQuantiScale] scaleLen: 0, scaleData: 0 [], zeroPointLen: 0, zeroPointData: []",
// "shift": "[hbDNNQuantiShift] shiftLen: 3, shiftData: [ 0, 0, 0]",
// "tensorLayout": "[hbDNNTensorLayout]: HB_DNN_LAYOUT_NHWC",
// "tensorType": "[hbDNNDataType]: HB_DNN_IMG_TYPE_BGR",
// "validShape": "[hbDNNTensorShape] dim: 4 [1x256x256x3]"
// }
// 3. 打印第一个模型的输出Tensor的第一个Tensor
LOG(INFO) << nets[0][wdr::BPU::NET_OUTPUT][0];
// I0623 18:25:22.160048 1268383 print-infos.cpp:67] [hbDNNTensorProperties] List Properties:
// {
// "alignedShape": "[hbDNNTensorShape] dim: 4 [1x2x256x256]",
// "quantiType": 524288,
// "scale": "[hbDNNQuantiScale] scaleLen: 0, scaleData: 0 [], zeroPointLen: 0, zeroPointData: []",
// "shift": "[hbDNNQuantiShift] shiftLen: 0, shiftData: []",
// "tensorLayout": "[hbDNNTensorLayout]: HB_DNN_LAYOUT_NCHW",
// "tensorType": "[hbDNNDataType]: HB_DNN_TENSOR_TYPE_F32",
// "validShape": "[hbDNNTensorShape] dim: 4 [1x2x256x256]"
// }
// 4. 打印所有模型参数信息
for (int k = 0; k < nets.total(); k++)
LOG(INFO) << nets.index2name(k) << ", " << nets[k];
// I0623 18:25:22.160290 1268383 print-infos.cpp:71] unet, [Net] All Input && Output Tensor Properties:
// {
// "Input": [
// {
// "alignedShape": "[hbDNNTensorShape] dim: 4 [1x256x256x4]",
// "quantiType": 262144,
// "scale": "[hbDNNQuantiScale] scaleLen: 0, scaleData: 0 [], zeroPointLen: 0, zeroPointData: []",
// "shift": "[hbDNNQuantiShift] shiftLen: 3, shiftData: [ 0, 0, 0]",
// "tensorLayout": "[hbDNNTensorLayout]: HB_DNN_LAYOUT_NHWC",
// "tensorType": "[hbDNNDataType]: HB_DNN_IMG_TYPE_BGR",
// "validShape": "[hbDNNTensorShape] dim: 4 [1x256x256x3]"
// }
// ],
// "Output": [
// {
// "alignedShape": "[hbDNNTensorShape] dim: 4 [1x2x256x256]",
// "quantiType": 524288,
// "scale": "[hbDNNQuantiScale] scaleLen: 0, scaleData: 0 [], zeroPointLen: 0, zeroPointData: []",
// "shift": "[hbDNNQuantiShift] shiftLen: 0, shiftData: []",
// "tensorLayout": "[hbDNNTensorLayout]: HB_DNN_LAYOUT_NCHW",
// "tensorType": "[hbDNNDataType]: HB_DNN_TENSOR_TYPE_F32",
// "validShape": "[hbDNNTensorShape] dim: 4 [1x2x256x256]"
// }
// ],
// "name": "unet"
// }
return 0;
}
3.2 利用WDR实现UNet推理
代码细节见examples/BPU/infer-unet.cpp中的函数test_class,在OpenWanderary的根目录下执行sudo ./build/examples/BPU/infer-unet --mode class,即可输出模型的各种信息。
int test_class()
{
const std::string modelname = "unet";
// 1. 加载模型
wdr::BPU::BpuNets nets;
nets.readNets({binpath});
int idxmode = nets.name2index(modelname);
LOG(INFO) << "model index: " << idxmode;
CV_Assert(idxmode >= 0);
// 2. 加载图像
cv::Mat img;
wdr::get_bgr_image(imgpath, img);
LOG(INFO) << "Finish load bgr image";
// 3. 内存分配
wdr::BPU::BpuMats input_mats, output_mats;
nets.init(idxmode, input_mats, output_mats, true);
LOG(INFO) << "input tensor num: " << input_mats.size() << ", output tensor num: " << output_mats.size();
// 3. 构造预处理输出,模型输入是256,256
cv::Mat datain;
cv::Size modsize = input_mats[0].size(false);
LOG(INFO) << "Input model size: " << modsize;
wdr::preprocess_onboard_NHWC(img, modsize.height, modsize.width, datain);
input_mats[0] << datain; // datain数据拷贝到Tensor里
input_mats.bpu(); // 更新数据到BPU中
LOG(INFO) << "Finish preprocess";
// 4. 模型推理
cv::Mat dataout;
nets.forward(idxmode, input_mats, output_mats);
output_mats.cpu(); // 从BPU中下载数据
output_mats[0] >> dataout; // 从Tensor里拷出数据到dataout
LOG(INFO) << "Finish infer";
// 5. 构造后处理数据,并保存最终预测结果
std::vector<cv::Mat> preds;
wdr::parseBinarySegmentResult(dataout, preds);
for (int k = 0; k < preds.size(); k++)
cv::imwrite(saveroot + "pred_cpp_wdr_" + std::to_string(k) + ".png", preds[k]);
// 6. 保存校验数据
std::string savepath = saveroot + "unet_check_wdrresults.npz";
LOG(INFO) << "Start saving results";
cnpy::npz_save(savepath, "datain", (unsigned char *)datain.data, wdr::get_shape(datain), "w");
cnpy::npz_save(savepath, "dataout", (float *)dataout.data, wdr::get_shape(dataout), "a");
cnpy::npz_save(savepath, "pred", (unsigned char *)preds[0].data, wdr::get_shape(preds[0]), "a");
LOG(INFO) << "Finish saving results in " << savepath;
// 内存释放由代码的析构函数自动完成,无需主动调用
return 0;
}
代码执行之后,会输出如下信息,预测结果图保存在projects/torchdnn/data/unet/pred_cpp_wdr_0.png,校验信息存在projects/torchdnn/data/unet/unet_check_wdrresults.npz,通过调用projects/torchdnn/demos/unet/check_wdr_onboard.py,确保了C++推理结果和Python版本的推理结果是一致的。
I0623 18:30:25.858119 1282517 infer-unet.cpp:38] mode: class
[BPU_PLAT]BPU Platform Version(1.3.1)!
[HBRT] set log level as 0. version = 3.14.5
[DNN] Runtime version = 1.9.7_(3.14.5 HBRT)
I0623 18:30:26.150298 1282517 infer-unet.cpp:58] model index: 0
I0623 18:30:26.158201 1282517 infer-unet.cpp:64] Finish load bgr image
I0623 18:30:26.158665 1282517 infer-unet.cpp:69] input tensor num: 1, output tensor num: 1
I0623 18:30:26.158731 1282517 infer-unet.cpp:74] Input model size: [256 x 256]
I0623 18:30:26.161554 1282517 infer-unet.cpp:79] Finish preprocess
I0623 18:30:26.261695 1282517 infer-unet.cpp:86] Finish infer
I0623 18:30:26.266692 1282517 infer-unet.cpp:96] Start saving results
I0623 18:30:26.274824 1282517 infer-unet.cpp:100] Finish saving results in projects/torchdnn/data/unet/unet_check_wdrresults.npz
四 总结
去年11月-6月,历时8月,凝练出这个博客。创作空间统计的字数是4w+,预估阅读时间超过1个小时,哈哈哈。为了讲明白一件事,我自己不断的优化文案,废弃的文案也大概1w了。不断在打磨,就是在想办法提供给读者干货,删了一堆,最开始我想讲怎么配置cmake,vscode插件,C接口api也要想写个文档。后来发现,这没意义,我需要提供个各位的是部署意识,而不是字典类型的博客。从表达上也可能直接说清楚。
个人认为BPU部署三部曲,足够让不了解BPU的人能够踏入开发的大门。本系列的结束,是另一个内容的开始。这段时间内的整理,也发现BPU部署工具中存在一些地方可以优化,优化后可以让每个开发者轻松上阵,优化点整理如下:
- 从pytorch到bin模型这个阶段应该有一个可靠的工具。最终的目标就是谁都可以用,不需要了解太多,类似GPT一样,我需要什么就能给我什么。
- 要不断打磨底层API接口。目前用起来还行,除了数据对齐这个问题坑了一段时间。文档手册每个函数最好都能提供一个example来讲清楚用法。
- 模型转换过程存在不完备的验证。量化的onnx和板端的bin文件能确保结果一致吗,最好在开发板上也能安装
horizon_nn。 - 简化部署/校验流程。流程多那就补充个可视化界面,每个工具,把明确输入+明确差异,写清楚,就几段话的事情。我开发时候经常面临问都不知道咋问的情况。
对于部署的未来工作:
- 不断打磨WDR库,修复其中的bug,而且对于工具链的更新也会尽可能做好适配。
- 将历史博客部署的一些算法的预处理和后处理用wdr实现推理。
博客内容较多,可能会存在一些错误,错误修复后我会及时更新在WDR仓库里,希望各位多多关注。