1 前言
对于J5这样的中高计算能力平台,小分辨率输入或者小计算量的模型往往不能达到较高的计算效率,对此可以通过batch模式部署模型(batch>1),一次推理多张图片,从而提高计算/访存比。J5支持在模型转换时配置yaml文件中的input_shape或者input_batch参数编译batch模型。J5也支持在板端部署时对batch模型做推理,本文将会对batch模型的编译和部署做详细说明。
2 Batch模型编译
编译Batch模型需要正确配置yaml文件的参数input_shape和input_batch。根据原模型种类,又分为动态输入模型和非动态输入模型两种情况。-
对于动态输入模型,比如输入为?x3x224x224,必须使用input_shape参数指定模型输入信息。当配置input_shape为1x3x224x224且是单输入模型时, 想编译得到多batch的模型,可以使用 input_batch 参数,当配置input_shape的第一维为大于1的整数时,原模型本身将会认定为多batch模型,将无法使用 input_batch 参数。-
对于非动态输入的模型,当输入的input shape[0]为1 且是单输入模型时,可以使用 input_batch 参数,当输入的input shape[0]不为1,则不支持使用 input_batch 参数。换句话说,input_batch 参数仅在单输入且 input_shape 第一维为1的时候可以使用。如果想以batch方式编译多输入模型,需要在原本的开源框架(pytorch,tensorflow等)导出onnx时就设定好模型不同输入分支的batch参数,地平线工具链支持多个输入分支有相同batch和不同batch的情况。-
此外,对于动态输入的模型,如果配置input_shape的第一维为大于1的整数时,那么校准数据的shape需要和此时的input_shape对齐。在其他情况下,校准数据的shape不需要特殊处理,为1x3x224x224即可。
3 Batch模型部署
3.1 示例介绍
OE包的ddk/samples/ai_toolchain/horizon_runtime_sample目录包含了板端部署的大量基础示例,该目录的文件结构如下:
+---horizon_runtime_sample
├── code
│ ├── 00_quick_start
│ ├── 01_api_tutorial
│ ├── 02_advanced_samples
│ │ ├── custom_identity
│ │ ├── multi_input
│ │ ├── multi_model_batch
│ │ └── nv12_batch
│ ├── 03_misc
│ ├── build_j5.sh
│ ├── build_x86.sh
│ ├── CMakeLists.txt
│ ├── CMakeLists_x86.txt
│ └── deps_gcc9.3
├── j5
│ ├── data
│ ├── model
│ ├── script
│ └── script_x86
└── README.md
其中code文件夹包含了示例的C++代码以及编译相关文件,j5文件夹包含示例运行脚本及编译生成的可执行文件,预置了数据和相关模型,在开发板上运行script目录的脚本就可以执行对应的模型推理示例。-
本文示例位于02_advanced_samples目录下的nv12_batch,该示例会运行一个batch为4的googlenet_4x224x224_nv12.bin分类模型,读取4张jpg图片进行两次前向推理,两次前向推理的区别在于内存分配的方式不同,最终经过后处理得到两组Top5分类结果。
在正式学习代码前,希望开发者已经熟悉地平线提供的板端部署API,这部分可以查看工具链手册的BPU SDK API章节,这个章节除了详细介绍API接口,还全面介绍了板端部署有关的数据类型、数据接口等信息,以及数据排布与对齐规则、错误码等等。您也可以一边阅读示例代码,一边翻看API手册进行学习。-
此外,建议刚开始接触工具链的开发者优先阅读《模型推理快速上手》一文,该文对horizon_runtime_sample的示例代码00_quick_start做了细致的解读,由于nv12_batch的代码结构与00_quick_start相近,因此本篇教程的重点会放在batch模型相关的部分。
3.2 程序结构
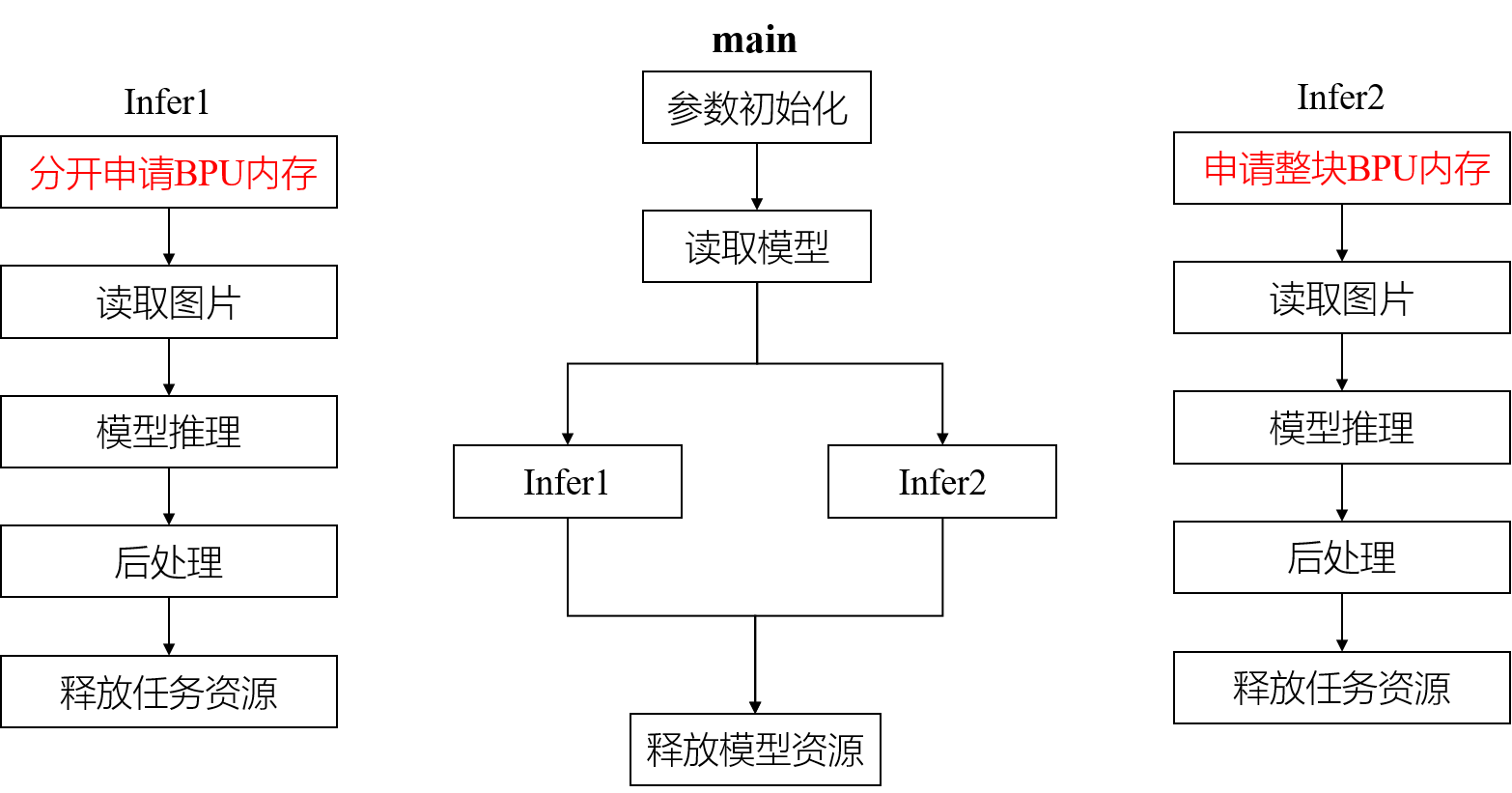
源码中,main函数的主要步骤如上图所示。该示例一共做了两次前向推理,主要区别在于:Infer1为4张输入图片分别申请了BPU内存,使用了不连续的4块内存存放输入张量,而Infer2为4张输入图片申请了一整块连续的BPU内存,依次存放所有数据。-
两种方法都属于batch模型推理,开发者可以针对不同的使用场景选择不同的内存分配方法。比方说,如果在J5上部署了一个batch为4的模型,用于处理4个摄像头采集的数据,那么考虑到1帧数据的4张图会存放在不连续的4块内存上,因此需要使用Infer1的方法做batch模型的推理。再比方说,如果只是做回灌,读取本地已有图片做推理,那么就可以使用Infer2的方式,将4张图存在一整片连续的内存空间中再进行batch模型的推理。-
接下来,分别对Infer1和Infer2的关键代码进行分析。
3.3 Infer1代码解读
对于Infer1,核心代码是自定义函数prepare_tensor_batch_separate和read_image_2_tensor_as_nv12_batch_separate。
int prepare_tensor_batch_separate(std::vector<hbDNNTensor> &input_tensor,
std::vector<hbDNNTensor> &output_tensor,
hbDNNHandle_t dnn_handle) {
......
for (int i = 0; i < input_count; i++) {
......
if (input.properties.tensorType == HB_DNN_IMG_TYPE_NV12) {
int32_t batch = input.properties.alignedShape.dimensionSize[0];
int32_t batch_size = input.properties.alignedByteSize / batch;
//Modify properties batch as 1 and modify alignedByteSize.
input.properties.alignedByteSize = batch_size;
input.properties.validShape.dimensionSize[0] = 1;
input.properties.alignedShape = input.properties.validShape;
for (int j{0}; j < batch; j++) {
HB_CHECK_SUCCESS(hbSysAllocCachedMem(&input.sysMem[0], batch_size),
"hbSysAllocCachedMem failed");
input_tensor.push_back(input);
}
} else if (input.properties.tensorType == HB_DNN_IMG_TYPE_NV12_SEPARATE) {
......
} else {
......
}
}
......
return 0;
}
在函数prepare_tensor_batch_separate中,以nv12数据类型为例,变量batch指的是模型编译时设置的batch数,变量batch_size指的是单batch数据对齐后的字节大小。-
对于Infer1这种分开申请内存的推理方法,需要重新配置当前tensor的对齐后字节大小和有效shape第一维的数值,前者需要将input.properties.alignedByteSize配置为batch_size,即单个输入数据的对齐后字节大小,后者需要将input.properties.validShape.dimensionSize[0]设置为1。这样在实际推理的时候,板端推理库才能正确解析输入tensor的信息。-
在j和batch的for循环中,每次循环都会使用地平线封装的内存分配接口hbSysAllocCachedMem为输入tensor分配batch_size大小的内存空间,循环的次数为batch。也就是说,prepare_tensor_batch_separate函数用于循环和batch相同的次数为每个输入数据分别申请内存。
int32_t read_image_2_tensor_as_nv12_batch_separate(
std::string &image_file, std::vector<hbDNNTensor> &input_tensor) {
......
for (int32_t i{0}; i < input_tensor.size(); i++) {
hbDNNTensor &input = input_tensor[i];
hbDNNTensorProperties &Properties = input.properties;
int input_h = Properties.validShape.dimensionSize[2];
int input_w = Properties.validShape.dimensionSize[3];
cv::Mat bgr_mat = cv::imread(input_image_file[i], cv::IMREAD_COLOR);
// convert to YUV420
// copy y data
// copy uv data
......
}
return 0;
}
函数read_image_2_tensor_as_nv12_batch_separate使用循环的方式,重复batch次数依次读取该batch内每个张量的长宽信息(input_tensor.size()和batch相等),之后再依次将每份输入数据拷贝进对应的内存空间。
3.4 Infer2代码解读
对于Infer2,核心代码是自定义函数prepare_tensor_batch_combine和read_image_2_tensor_as_nv12_batch_combine。
int prepare_tensor_batch_combine(std::vector<hbDNNTensor> &input_tensor,
std::vector<hbDNNTensor> &output_tensor,
hbDNNHandle_t dnn_handle) {
......
for (int i = 0; i < input_count; i++) {
hbDNNTensor input;
HB_CHECK_SUCCESS(
hbDNNGetInputTensorProperties(&input.properties, dnn_handle, i),
"hbDNNGetInputTensorProperties failed");
HB_CHECK_SUCCESS(
hbSysAllocCachedMem(&input.sysMem[0], input.properties.alignedByteSize),
"hbSysAllocCachedMem failed");
input.properties.alignedShape = input.properties.validShape;
input_tensor.push_back(input);
}
......
return 0;
}
prepare_tensor_batch_combine函数用于一次为batch内所有输入数据申请整块的连续内存,变量input.properties.alignedByteSize为所有输入数据对齐后在内存上占用的字节大小的总和。
int32_t read_image_2_tensor_as_nv12_batch_combine(
std::string &image_file, std::vector<hbDNNTensor> &input_tensor) {
hbDNNTensor &input = input_tensor[0];
hbDNNTensorProperties &Properties = input.properties;
int batch = Properties.alignedShape.dimensionSize[0];
int input_h = Properties.validShape.dimensionSize[2];
int input_w = Properties.validShape.dimensionSize[3];
......
auto data = reinterpret_cast<uint8_t *>(input.sysMem[0].virAddr);
auto batch_size = Properties.alignedByteSize / batch;
for (int32_t i{0}; i < batch; i++) {
cv::Mat bgr_mat = cv::imread(input_image_file[i], cv::IMREAD_COLOR);
// convert to YUV420
// copy y data
// copy uv data
......
data += batch_size;
}
return 0;
}
函数read_image_2_tensor_as_nv12_batch_combine使用循环的方式,循环batch次,依次将每份输入数据存进整块连续的内存空间中,其中变量data表示每份数据在内存中的首地址,batch_size表示每份数据占有的对齐后的字节大小。
3.5 板端运行
batch模型推理示例的板端运行非常简单,先执行code文件夹下的build_j5.sh脚本,执行完毕后会在j5文件夹下生成文件及相关依赖,我们将整个j5文件夹复制到板端,再进入j5/script/02_advanced_samples目录,运行run_nv12_batch.sh脚本,即可在开发板上运行batch模型推理示例了。-
这个示例在J5开发板上运行的终端打印信息如下:
I0000 00:00:00.000000 21511 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3[BPU_PLAT]BPU Platform Version(1.3.3)!
[HBRT] set log level as 0. version = 3.15.18.0
[DNN] Runtime version = 1.17.2_(3.15.18 HBRT)
I0705 11:39:43.429180 21511 nv12_batch.cc:151] Infer1 start
I0705 11:39:43.488143 21511 nv12_batch.cc:166] read image to tensor as nv12 success
I0705 11:39:43.491156 21511 nv12_batch.cc:201] Batch[0]:
I0705 11:39:43.491211 21511 nv12_batch.cc:203] TOP 0 result id: 340
I0705 11:39:43.491240 21511 nv12_batch.cc:203] TOP 1 result id: 83
I0705 11:39:43.491266 21511 nv12_batch.cc:203] TOP 2 result id: 41
I0705 11:39:43.491298 21511 nv12_batch.cc:203] TOP 3 result id: 912
I0705 11:39:43.491324 21511 nv12_batch.cc:203] TOP 4 result id: 292
I0705 11:39:43.491348 21511 nv12_batch.cc:201] Batch[1]:
I0705 11:39:43.491374 21511 nv12_batch.cc:203] TOP 0 result id: 282
I0705 11:39:43.491398 21511 nv12_batch.cc:203] TOP 1 result id: 281
I0705 11:39:43.491422 21511 nv12_batch.cc:203] TOP 2 result id: 285
I0705 11:39:43.491447 21511 nv12_batch.cc:203] TOP 3 result id: 287
I0705 11:39:43.491472 21511 nv12_batch.cc:203] TOP 4 result id: 283
I0705 11:39:43.491497 21511 nv12_batch.cc:201] Batch[2]:
I0705 11:39:43.491514 21511 nv12_batch.cc:203] TOP 0 result id: 340
I0705 11:39:43.491539 21511 nv12_batch.cc:203] TOP 1 result id: 83
I0705 11:39:43.491564 21511 nv12_batch.cc:203] TOP 2 result id: 41
I0705 11:39:43.491587 21511 nv12_batch.cc:203] TOP 3 result id: 912
I0705 11:39:43.491612 21511 nv12_batch.cc:203] TOP 4 result id: 292
I0705 11:39:43.491637 21511 nv12_batch.cc:201] Batch[3]:
I0705 11:39:43.491662 21511 nv12_batch.cc:203] TOP 0 result id: 282
I0705 11:39:43.491685 21511 nv12_batch.cc:203] TOP 1 result id: 281
I0705 11:39:43.491710 21511 nv12_batch.cc:203] TOP 2 result id: 285
I0705 11:39:43.491734 21511 nv12_batch.cc:203] TOP 3 result id: 287
I0705 11:39:43.491760 21511 nv12_batch.cc:203] TOP 4 result id: 283
I0705 11:39:43.492235 21511 nv12_batch.cc:223] Infer1 end
I0705 11:39:43.492276 21511 nv12_batch.cc:228] Infer2 start
I0705 11:39:43.549713 21511 nv12_batch.cc:243] read image to tensor as nv12 success
I0705 11:39:43.552248 21511 nv12_batch.cc:278] Batch[0]:
I0705 11:39:43.552292 21511 nv12_batch.cc:280] TOP 0 result id: 340
I0705 11:39:43.552320 21511 nv12_batch.cc:280] TOP 1 result id: 83
I0705 11:39:43.552345 21511 nv12_batch.cc:280] TOP 2 result id: 41
I0705 11:39:43.552371 21511 nv12_batch.cc:280] TOP 3 result id: 912
I0705 11:39:43.552397 21511 nv12_batch.cc:280] TOP 4 result id: 292
I0705 11:39:43.552421 21511 nv12_batch.cc:278] Batch[1]:
I0705 11:39:43.552445 21511 nv12_batch.cc:280] TOP 0 result id: 282
I0705 11:39:43.552469 21511 nv12_batch.cc:280] TOP 1 result id: 281
I0705 11:39:43.552495 21511 nv12_batch.cc:280] TOP 2 result id: 285
I0705 11:39:43.552520 21511 nv12_batch.cc:280] TOP 3 result id: 287
I0705 11:39:43.552567 21511 nv12_batch.cc:280] TOP 4 result id: 283
I0705 11:39:43.552592 21511 nv12_batch.cc:278] Batch[2]:
I0705 11:39:43.552616 21511 nv12_batch.cc:280] TOP 0 result id: 340
I0705 11:39:43.552641 21511 nv12_batch.cc:280] TOP 1 result id: 83
I0705 11:39:43.552665 21511 nv12_batch.cc:280] TOP 2 result id: 41
I0705 11:39:43.552690 21511 nv12_batch.cc:280] TOP 3 result id: 912
I0705 11:39:43.552716 21511 nv12_batch.cc:280] TOP 4 result id: 292
I0705 11:39:43.552739 21511 nv12_batch.cc:278] Batch[3]:
I0705 11:39:43.552763 21511 nv12_batch.cc:280] TOP 0 result id: 282
I0705 11:39:43.552788 21511 nv12_batch.cc:280] TOP 1 result id: 281
I0705 11:39:43.552812 21511 nv12_batch.cc:280] TOP 2 result id: 285
I0705 11:39:43.552837 21511 nv12_batch.cc:280] TOP 3 result id: 287
I0705 11:39:43.552861 21511 nv12_batch.cc:280] TOP 4 result id: 283
I0705 11:39:43.553154 21511 nv12_batch.cc:300] Infer2 end
可以看到,终端打印了两次推理的Top5分类结果,并且结果是完全一致的。
4 性能对比
为了直观展示J5上batch模式对小模型带来的性能提升,这里提供几组实验数据以供参考。
4.1 实验条件
- J5系统软件版本:LNX5.10_REL_PL3.0_20221128-161022 release
- J5工具链版本:1.1.49b
- 模型来源:horizon_model_convert_sample/03_classification/02_googlenet
- 模型输入排布:NCHW
- 模型输入尺寸:1x3x224x224、8x3x224x224
- 性能测试工具:hrt_model_exec
4.2 单核单线程BPU占用率对比
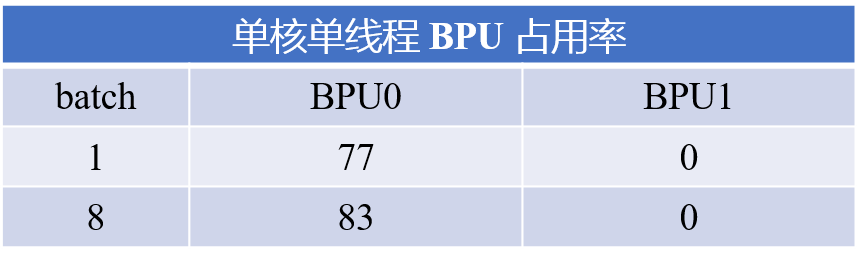
使用hrt_model_exec工具的perf功能,以单核单线程方式运行,并使用hrut_bpuprofile -b 2 -r 0指令查看BPU占用率。可以看到在batch=8的情况下,单核BPU占用率相比batch=1有明显提升。
4.3 单核单线程Latency对比

如果同样基于8张图对比,那么batch=1时,模型推理8张图的Latency为1.13ms * 8 = 9.04ms,时间显著长于batch=8的3.05ms。
4.4 双核八线程FPS对比

由于batch=8时,模型1帧会推理8张图,因此FPS实际为790*8=6320,远超batch=1的2703。
4.5 实验结论
对于小模型来说,batch模式能提升BPU占用率,降低算力浪费,同时Latency和FPS都显著优于单batch模型。