天工开物开发包OpenExplorer版本:J5_OE_1.1.60
最开始希望使用pointpillars进行多类别3D检测,但是在pointpillars那篇文章下建议使用centerpoint。现在我修改了相应的参数,使用kitti类型的数据集进行centerpoint训练,发现经过过滤后数据全没了。这种情况应该怎么修改呢?
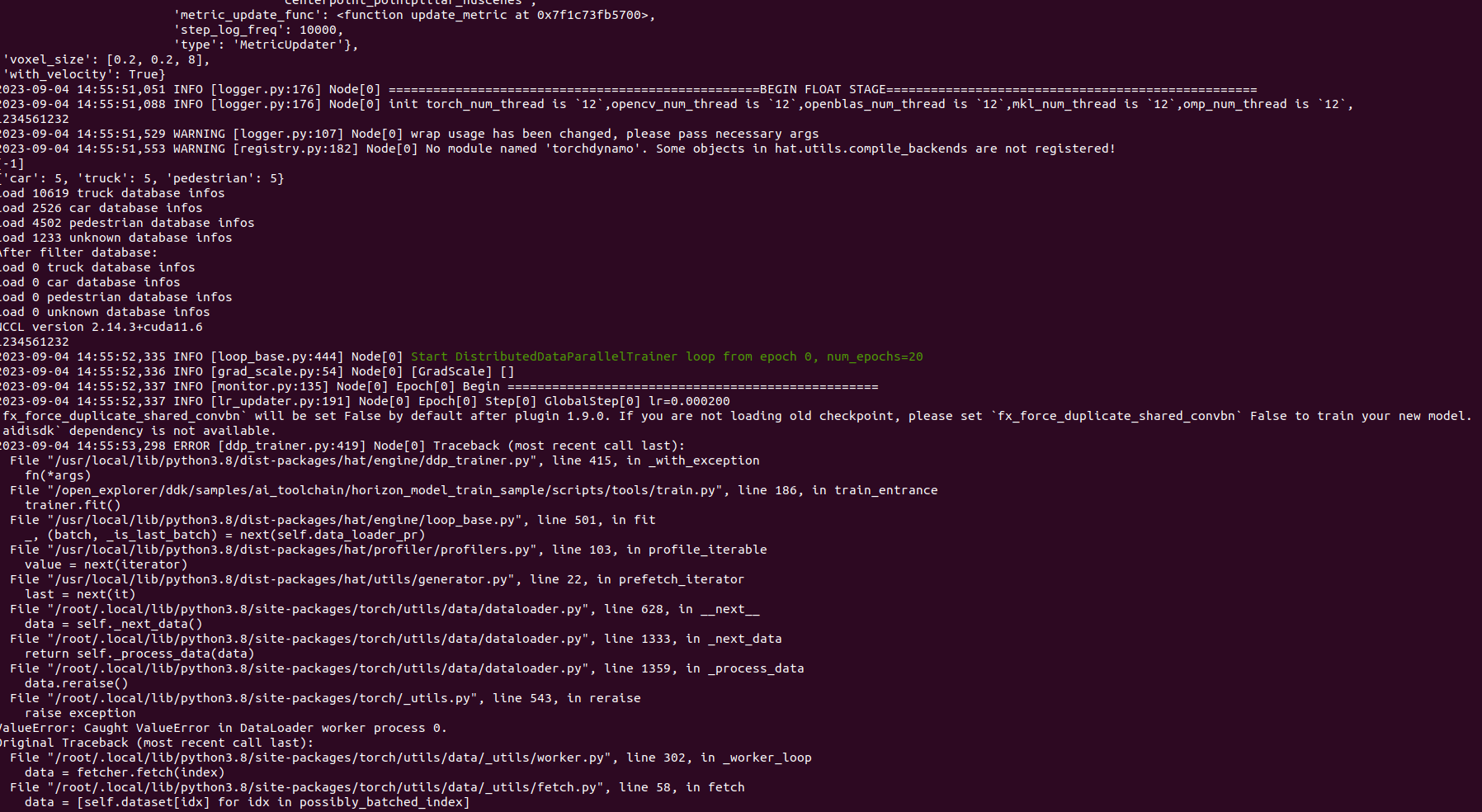
2023-09-04 14:55:51,051 INFO [logger.py:176] Node[0] ==================================================BEGIN FLOAT STAGE==================================================
2023-09-04 14:55:51,088 INFO [logger.py:176] Node[0] init torch_num_thread is `12`,opencv_num_thread is `12`,openblas_num_thread is `12`,mkl_num_thread is `12`,omp_num_thread is `12`,
1234561232
2023-09-04 14:55:51,529 WARNING [logger.py:107] Node[0] wrap usage has been changed, please pass necessary args
2023-09-04 14:55:51,553 WARNING [registry.py:182] Node[0] No module named ‘torchdynamo’. Some objects in hat.utils.compile_backends are not registered!
[-1]
{‘car’: 5, ‘truck’: 5, ‘pedestrian’: 5}
load 10619 truck database infos
load 2526 car database infos
load 4502 pedestrian database infos
load 1233 unknown database infos
After filter database:
load 0 truck database infos
load 0 car database infos
load 0 pedestrian database infos
load 0 unknown database infos
NCCL version 2.14.3+cuda11.6
1234561232
2023-09-04 14:55:52,335 INFO [loop_base.py:444] Node[0] Start DistributedDataParallelTrainer loop from epoch 0, num_epochs=20
2023-09-04 14:55:52,336 INFO [grad_scale.py:54] Node[0] [GradScale] []
2023-09-04 14:55:52,337 INFO [monitor.py:135] Node[0] Epoch[0] Begin ==================================================
2023-09-04 14:55:52,337 INFO [lr_updater.py:191] Node[0] Epoch[0] Step[0] GlobalStep[0] lr=0.000200
`fx_force_duplicate_shared_convbn` will be set False by default after plugin 1.9.0. If you are not loading old checkpoint, please set `fx_force_duplicate_shared_convbn` False to train your new model.
`aidisdk` dependency is not available.
2023-09-04 14:55:53,298 ERROR [ddp_trainer.py:419] Node[0] Traceback (most recent call last):
File “/usr/local/lib/python3.8/dist-packages/hat/engine/ddp_trainer.py”, line 415, in _with_exception
fn(*args)
File “/open_explorer/ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/train.py”, line 186, in train_entrance
trainer.fit()
File “/usr/local/lib/python3.8/dist-packages/hat/engine/loop_base.py”, line 501, in fit
_, (batch, _is_last_batch) = next(self.data_loader_pr)
File “/usr/local/lib/python3.8/dist-packages/hat/profiler/profilers.py”, line 103, in profile_iterable
value = next(iterator)
File “/usr/local/lib/python3.8/dist-packages/hat/utils/generator.py”, line 22, in prefetch_iterator
last = next(it)
File “/root/.local/lib/python3.8/site-packages/torch/utils/data/dataloader.py”, line 628, in __next__
data = self._next_data()
File “/root/.local/lib/python3.8/site-packages/torch/utils/data/dataloader.py”, line 1333, in _next_data
return self._process_data(data)
File “/root/.local/lib/python3.8/site-packages/torch/utils/data/dataloader.py”, line 1359, in _process_data
data.reraise()
File “/root/.local/lib/python3.8/site-packages/torch/_utils.py”, line 543, in reraise
raise exception
ValueError: Caught ValueError in DataLoader worker process 0.
Original Traceback (most recent call last):
File “/root/.local/lib/python3.8/site-packages/torch/utils/data/_utils/worker.py”, line 302, in _worker_loop
data = fetcher.fetch(index)
File “/root/.local/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py”, line 58, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File “/root/.local/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py”, line 58, in
data = [self.dataset[idx] for idx in possibly_batched_index]
File “/usr/local/lib/python3.8/dist-packages/hat/data/datasets/kitti3d.py”, line 715, in __getitem__
sample_info = self.transforms(sample_info)
File “/root/.local/lib/python3.8/site-packages/torchvision/transforms/transforms.py”, line 95, in __call__
img = t(img)
File “/usr/local/lib/python3.8/dist-packages/hat/data/transforms/lidar_utils/lidar_transform_3d.py”, line 140, in __call__
sampled_dict = self.db_sampler.sample_all(
File “/usr/local/lib/python3.8/dist-packages/hat/data/transforms/lidar_utils/sample_ops.py”, line 196, in sample_all
sampled_cls = self.sample_class_v2(
File “/usr/local/lib/python3.8/dist-packages/hat/data/transforms/lidar_utils/sample_ops.py”, line 360, in sample_class_v2
sp_boxes = np.stack([i[“box3d_lidar”] for i in sampled], axis=0)
File “<__array_function__ internals>”, line 5, in stack
File “/usr/local/lib/python3.8/dist-packages/numpy/core/shape_base.py”, line 423, in stack
raise ValueError(‘need at least one array to stack’)
ValueError: need at least one array to stack
ERROR:__main__:train failed! process 0 terminated with exit code 1
Traceback (most recent call last):
File “tools/train.py”, line 287, in
raise e
File “tools/train.py”, line 273, in
train(
File “tools/train.py”, line 254, in train
launch(
File “/usr/local/lib/python3.8/dist-packages/hat/engine/ddp_trainer.py”, line 384, in launch
mp.spawn(
File “/root/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py”, line 240, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method=‘spawn’)
File “/root/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py”, line 198, in start_processes
while not context.join():
File “/root/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py”, line 149, in join
raise ProcessExitedException(
torch.multiprocessing.spawn.ProcessExitedException: process 0 terminated with exit code 1