目录
- 前言
- 为什么要用人工智能
- 不必了解原理,先从会用开始
- 环境搭建
- 基本环境的搭建
- 英伟达显卡驱动安装
- Anaconda安装
- yolov5源码获取
- 环境安装
- 准备训练集
- 图片准备
- 图片标注
- 格式转换
- 训练模型
- 获取模型权重
- 训练文件配置
- 训练参数配置
- 训练模型和常见报错
- 使用模型进行目标检测
-
总结-
前言
为什么要用人工智能
在使用python进行对图片的处理时,经常使用到OpenCV,pillow等图像处理库,这些python三方库能够解决绝大多数的图像处理项目需求。
但其实这些图像处理方法都是通过写死固定代码,然后再计算,输出结果。
假如我给你不同的猫咪的照片,我需要你用代码去把他框出,而每张照片中的猫咪,其数量,品种,姿态等各不相同,不使用模型推理,单纯使用OpenCV等图像处理方式是99%做不出来的。-

但你有没有想过:为什么人眼可以立刻就快速通过眼睛的观测而快速计算出这些信息?
想必你一定听过这些词汇:人工智能,机械学习,深度学习,神经网络…
没错,既然人脑的计算如此强大,那我们为何不尝试开发一种计算方式去模拟人大脑中神经元的计算方式?
这便是人工智能的基本原理:神经网络
当然,人脑的运算方式并不可能这么简单,并且人工智能的算法同样也是“写死”的算法,并不具有主观智能性,目前有神经网络这个名词,只是最初的发明者想通过这种方式让电脑能够“看起来”相对智能一点,想通过制作一个“模型”,去比拟人脑强大运算。但就光结果而言,他成功了!
不必了解原理,先从会用开始
关于深度学习模型,常用的有:
- 自然语言处理模型 --可以处理文字信息,进行对话等操作
- 目标检测模型 --正和开头说的一样,把指定物品在图片中的位置,范围识别出来
- 图片分类模型 --例如:给一张猫或狗的图片,模型可以反馈给你识别到的类别-
除此之外还有音频处理,视频追踪等模型,有兴趣的同志可以自行了解
而深度学习的原理又涉及:神经网络结构,数据处理等大量复杂数学原理
因此许多人直接打了退堂鼓
但我想告诉你,大量模型都是有被开源的,我们可以用别人做好的框架,训练自己的模型,而且根本不需要什么基础!我们只需要学会使用大佬们为我们做好的“工具”,就可以将其投入到开发项目中了。
那么接下来,我将会带大家通过开源的yolov5框架,完成:环境搭建,训练集制作,框架参数调整,训练模型和目标检测测试这几个步骤,来让大家训练出自己的模型。
环境搭建
在人工智能的学习中,环境是十分重要的,就打个比方:
小Y是一名教师(开发者),小Y不能直接把学生带回家,在自己家里上课吧?所以小Y会选择去教室,并且上不同的课需要不同的工具,例如语文课需要语文书,体育课需要体育器件或场地,生物实验课需要生物标本,物理实验课需要物理实验器材…
这些教室啊,书啊,器材啊,就分别相当于开发者用到的不同库,其组合相当于是开发者在进行不同开发的过程种要用到的不同环境。如果小Y直接把学生带回家上课,那这么多学生,这么多课程,他的教学工具是不是会堆的乱七八糟?这就相当于我在电脑原始环境里装各种工具,也会导致开发中出现各种问题。
所以,我们需要通过环境管理工具,去制作不同的“教室”,这样开发才会有条不紊
基本环境的搭建
那么理解了之后,我们先来建一座教学楼吧!
PS:看我这篇文章的同学,建议先去了解一下linux系统和ubuntu系统
这里的“教学楼”指的是系统大环境,这边我推荐大家使用WSL2:Ubuntu子系统-

我在我的电脑里安装了一个子系统,并且分配了一定的储存空间给它,我的大部分开发目前基本上在这个系统中完成。
从开发者的角度来说,ubuntu系统(linux系统)是更加适合开发的,但其中水比较深。直接安装ubuntu为主系统,或者使用双系统模式的话,如果是英伟达的显卡(大部分都是),训练深度学习模型需要用到英伟达显卡驱动,在ubuntu系统中安装这个很麻烦,一不小心就会让系统直接崩溃。
所以子系统就成为了一个很好的选择,不仅可以无条件使用主机的资源,还不用像平行双系统那样麻烦的切换系统,特别方便。
安装方式可以参考这篇:http://t.csdnimg.cn/Ln3Pq
WSL是微软(和你的windows系统同根同源)推出的工具,大家可以放心安装
当然,对ubuntu系统有自信的同学可以跳过这步,直接用自己的原装系统,或者嫌麻烦也可以直接在windows中操作,当然可能需要你自行适配一下
英伟达显卡驱动安装
看到这里建议读者先去了解一下,你的电脑是何种显卡,如果只有集成显卡就可以跳过本小节了;如果是intel的独立显卡(不常见),驱动安装方法可能需要读者自行搜索;如果有英伟达独立显卡(市面上大部分独立显卡都是英伟达)请阅读本节
有些电脑可能自带英伟达驱动,在命令行中验证一下,输入nvidia-smi,有以下输出说明有驱动,否则没有-

和我一样是子系统,或者直接在windows中开发的同志,直接把显卡驱动装在windows里即可,参考:http://t.csdnimg.cn/7pLW2
需要直接在原生Ubuntu系中安装驱动的同志,参考这篇是最保险的:http://t.csdnimg.cn/Pt9tC-
PS:Ubuntu系统装英伟达驱动可能会崩,请提前备份文件
安装完成后输入nvidia-smi,有前文所示的输出表示安装完成
Anaconda安装
前文提到环境管理工具,Anaconda就是一个主流的环境管理工具,你可以创建不同的环境,并在不同的环境中安装不同的python版本,不同的三方库版本…
二话不说,直接开始安装教程
输入指令wget https://repo.anaconda.com/archive/Anaconda3-2021.11-Linux-x86_64.sh ,wget下载安装包,稍作等待-

完成之后可以看见路径下已经有安装包了-

赋予脚本执行权限并且执行-
![]()
接下来一路回车即可-



再次回到命令行后就安装完成了-
验证是否安装-

如果命令行输出的是conda:command not found,说明没有将conda添加到环境路径上,编辑~/.bashrc文件-
![]()
在最后一行加上-

要注意这里不能直接复制,要和自己的安装路径对的上
输入conda activate,进入基本环境-

至此,conda安装完毕
yolov5源码获取
看到这有些同志可能会问:为什么不先把环境搭建完再获取yolov5源码?
这个问题后面我会解释,请大家先跟随我进行这一步
yolov5模型训练框架在github上有开源:https://github.com/ultralytics/yolov5-
但是我不建议大家使用官方的源代码
官方这边目前推出了很多个版本,每一次迭代都有不同程度的优化,按照最优化思想来看,最好使用v7.0版本-
但是后续我还会更新博客,基于本篇博客将yolov5目标检测模型部署在X3pi开发板上,并通过BPU加速推理,但目前只有v2.0的tag支持加速推理,所以我建议大家使用v2.0版本
缺点也有,v2.0的版本直接跑,没法跑通,代码上存在一些bug,对此我把自己修改完bug的版本同样上传了,并且附带了所有尺寸的模型权重(这样就无需再另外下载了)
leaf修改版yolov5-v2.0源码:https://github.com/hachi-leaf/horizon_yolov5
进入网站,zip打包-


将源代码解压到需要的路径中(这边为了方便直接用命令行,普通的文件操作)-
![]()

环境安装
首先进入刚刚下载的yolov5源码(可以用VScode打开)-

打开目录中的requirements.txt,这其中包含了库名称,我们可以通过pip一键安装,这就是为什么我在安装环境之前先获取代码-
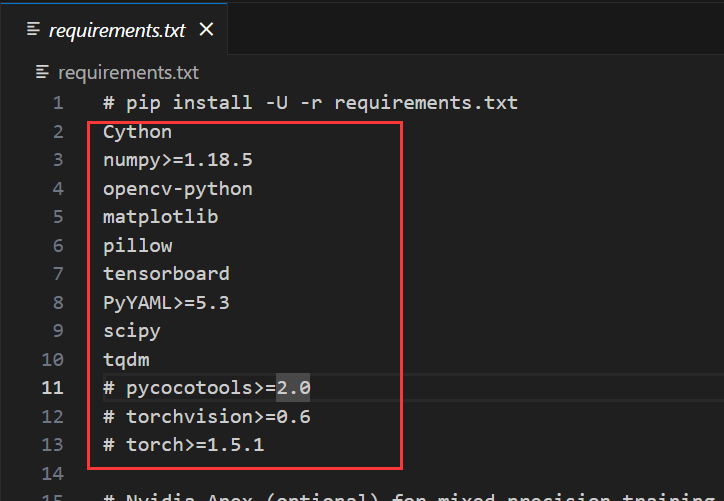
*截图中torch被我注释了,但实际上我的仓库中的该文件和本次的不同(没有注释torch),本处是我的编辑错误,无视即可
命令行输入conda create -n yolov5 python==3.11创建conda环境,python版本可以不一样,要在3.8以上-

输入y-
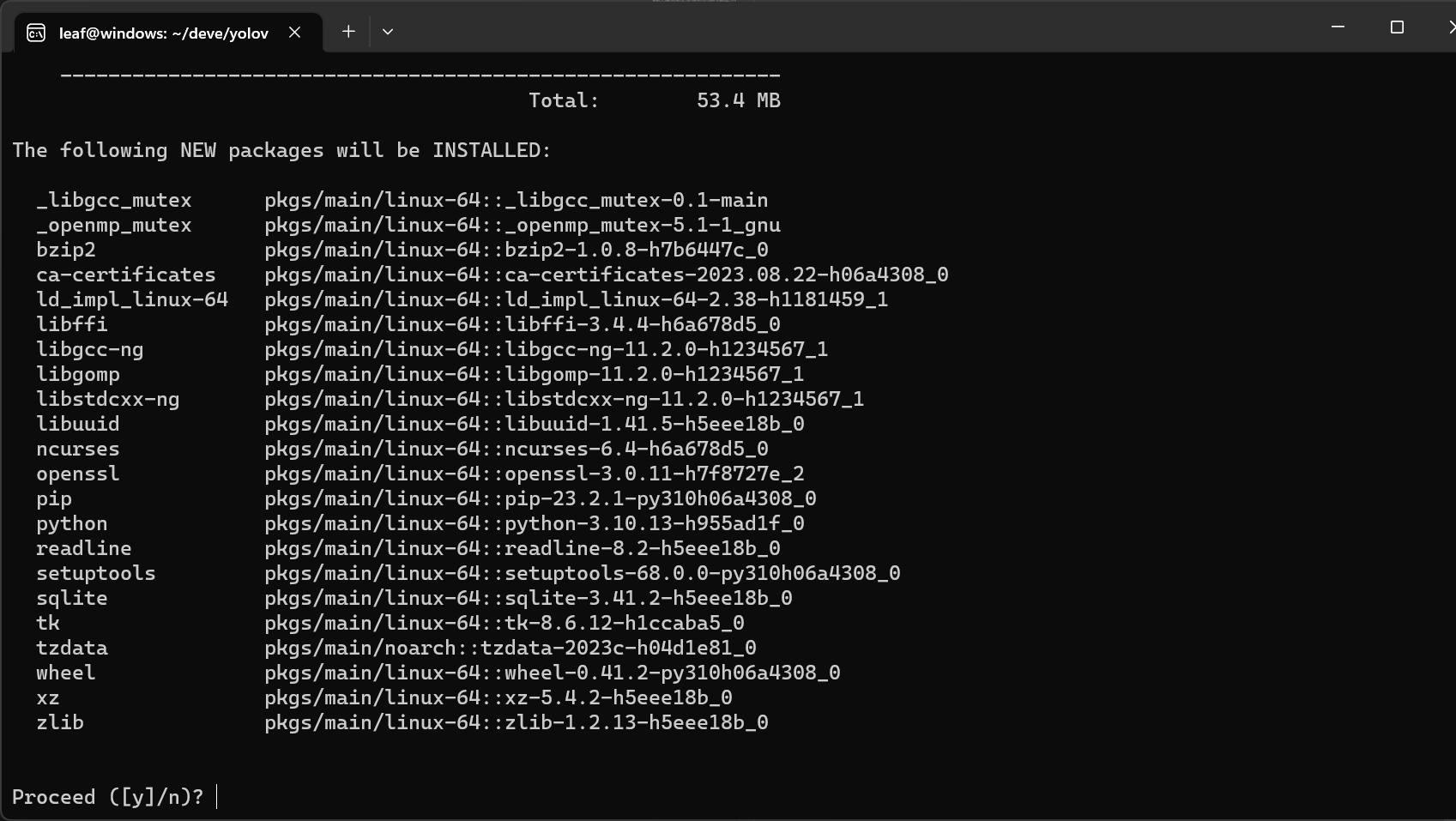
安装完成,输入conda avtivate yolov5进入环境(后续进行的操作都要在现在创建的这个环境里面进行)-
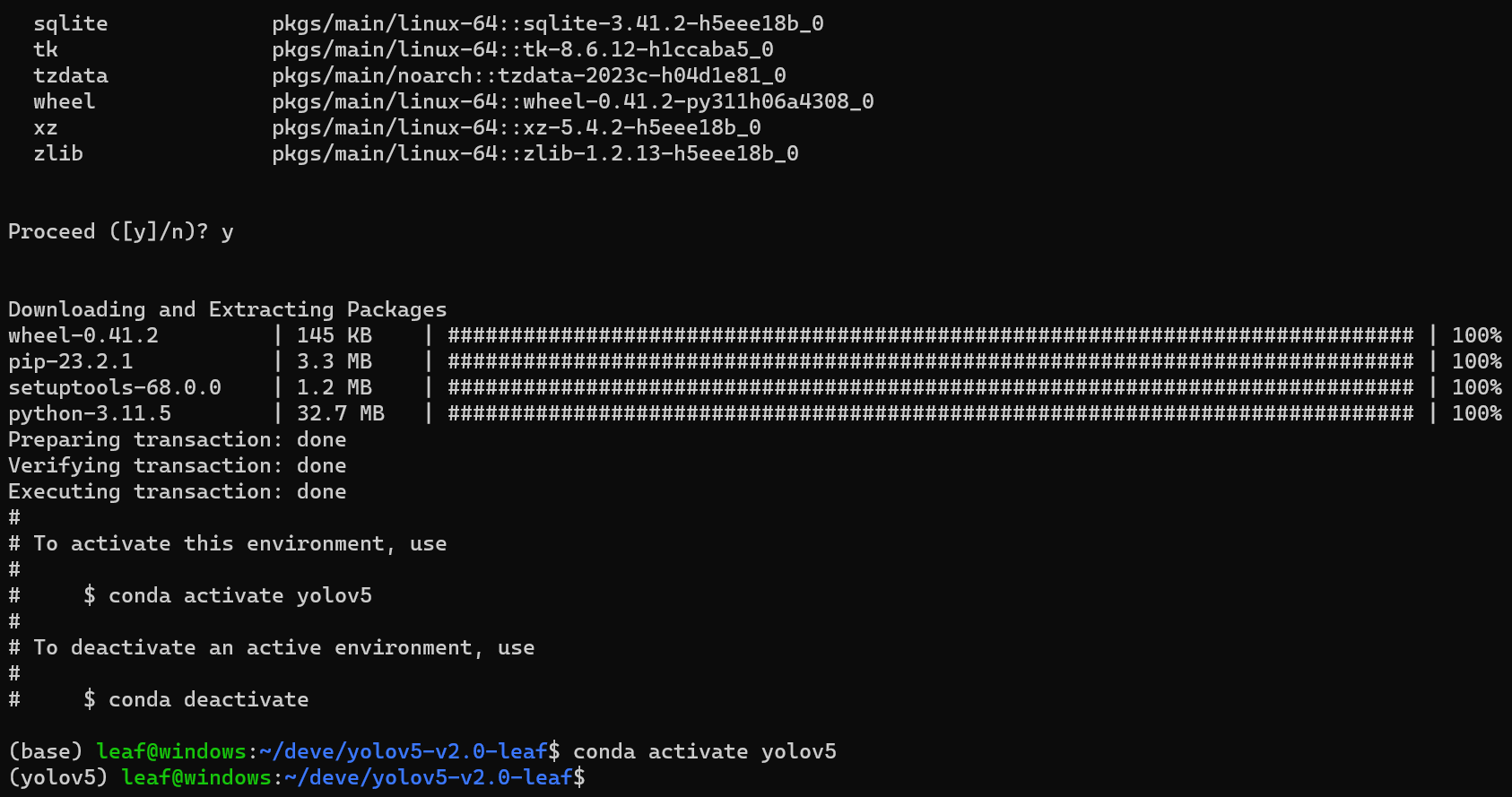
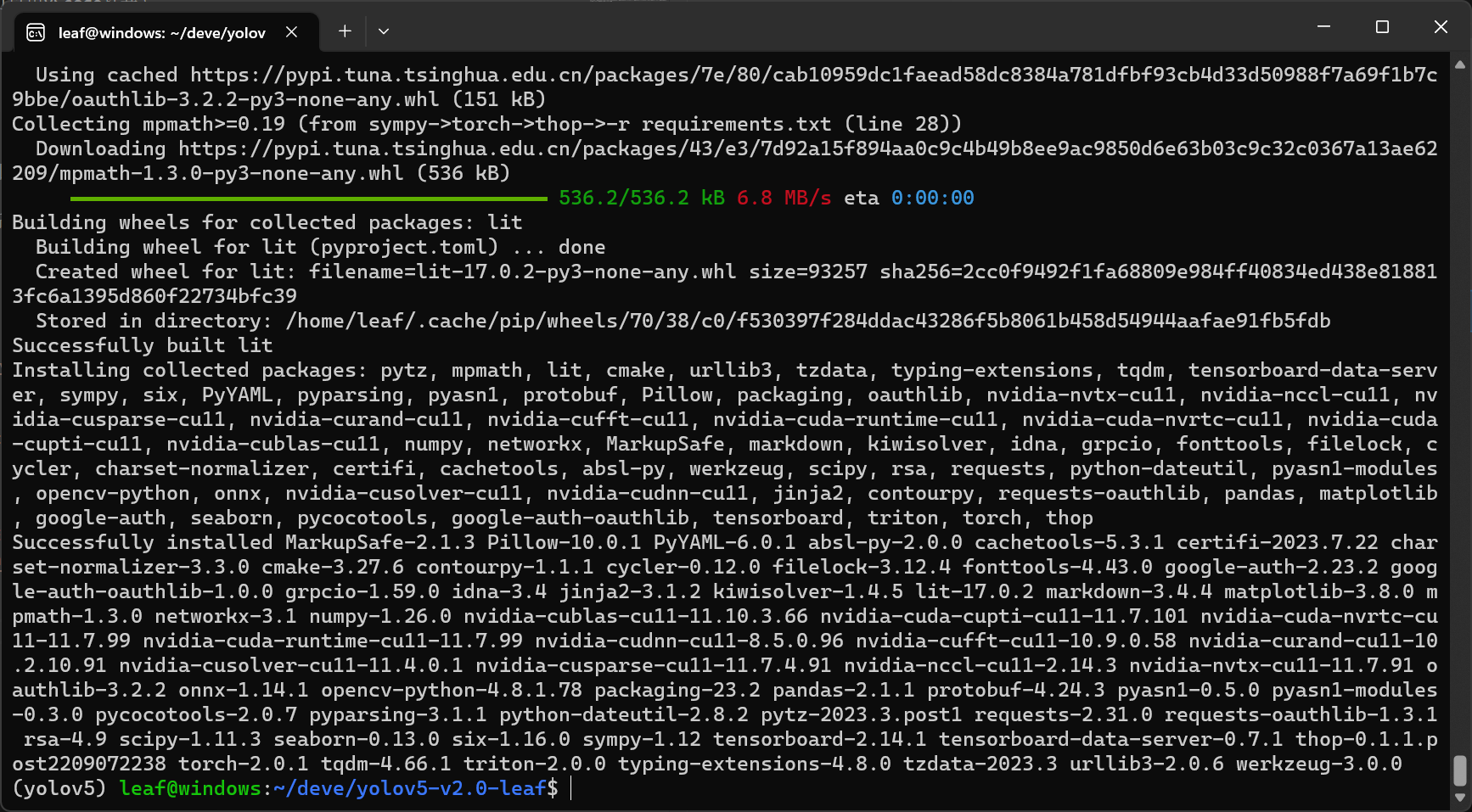
一定要先进入环境,输入pip install -r requirements.txt,通过该文本安装环境,注意不要加sudo,否则不会装在conda环境中-
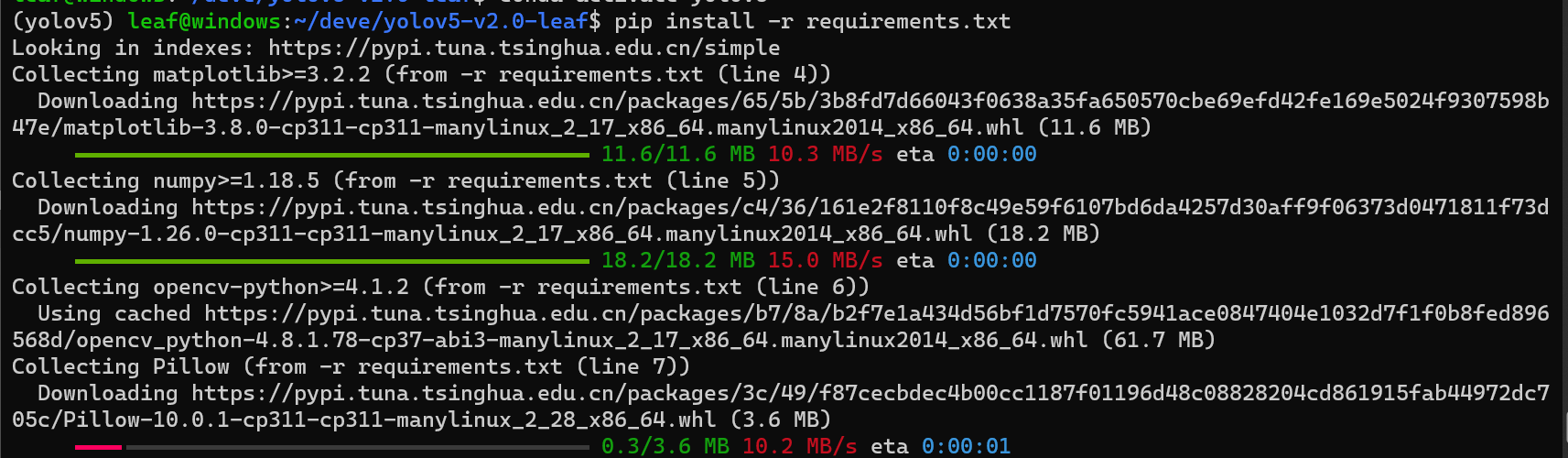
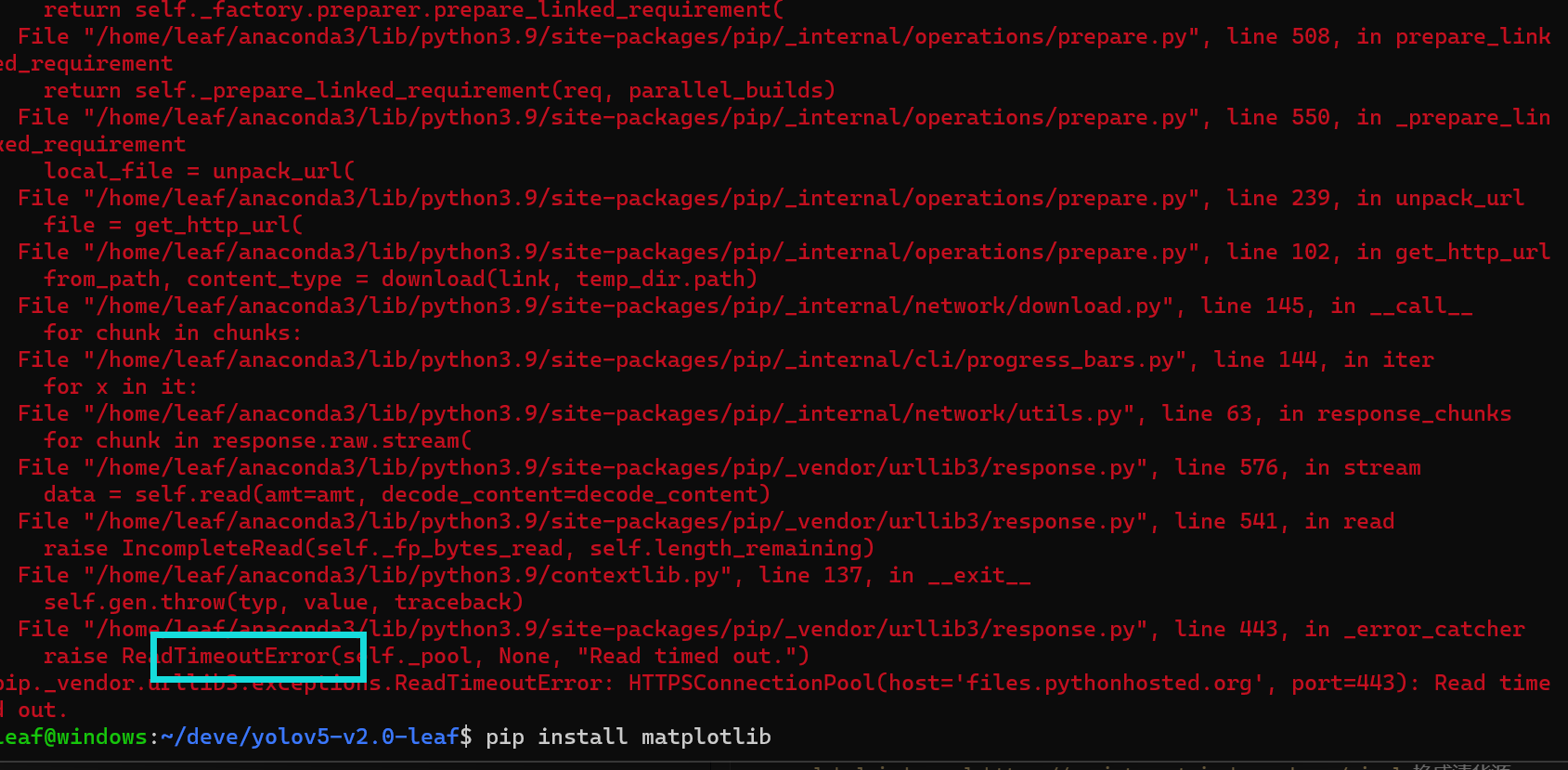
如果下载太慢,或者报错TimeoutError,大概率是因为从国外源下载,速度太慢下载超时了,输入pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple换成清华源-
等待一段时间,下载完成-
但是先别急,我们还需要验证以下torch版本是GPU版本还是CPU版本,在命令行输入python,引用包并查看版本,如果都类似以下的输出(xxx+cuxxx),说明安装的是GPU版本,即cuda版本-

如果返回以下结果,说明默认安装了cpu版本的torch-

需要注意的是,请先检查你的电脑是何种显卡:-
1.如果是集成显卡,那么你可以安装cuda的版本的pytorch但无法使用gpu加速训练过程,所以装哪个版本都没问题-
2.如果是独立显卡,应该安装cuda版torch,如果默认安装了cpu版(如上情况),需要依照以下步骤重新安装
首先回到命令行,输入pip uninstall torch torchvision,卸载当前的torch,提示是否删除输入Y-

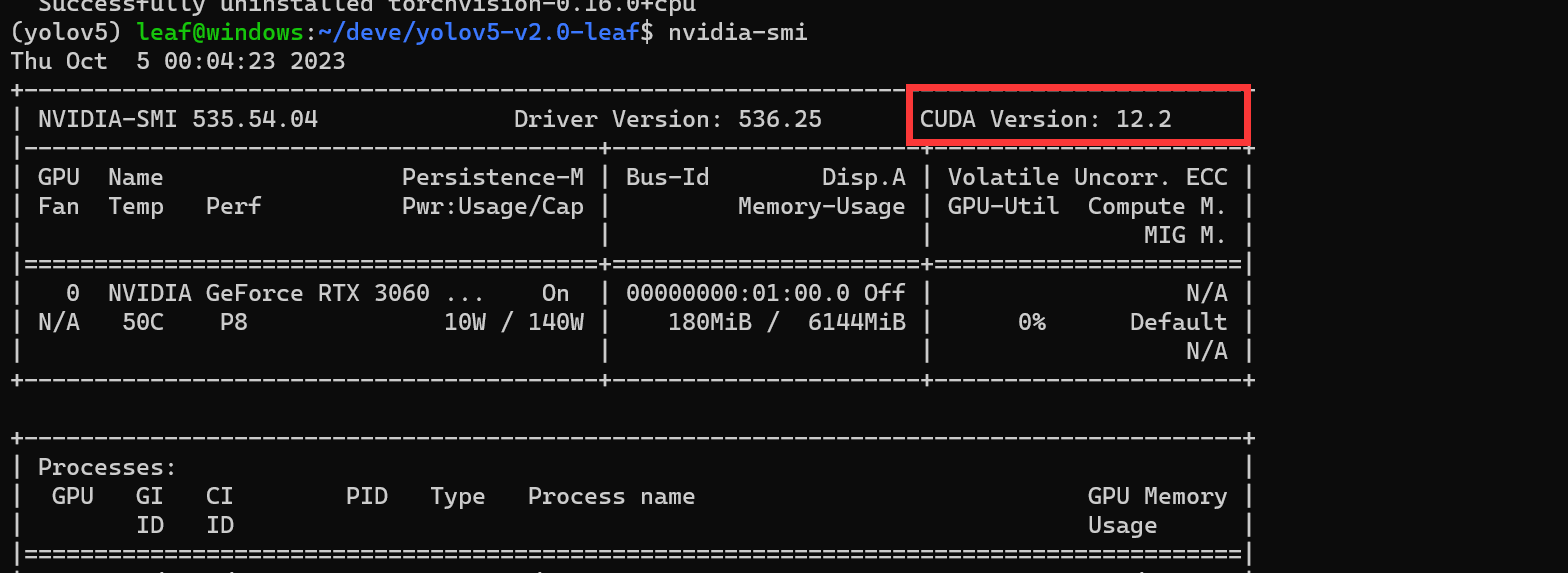
输入nvidia-smi,记住你系统的cuda版本支持-
进入pytorch官网:https://pytorch.org (国外网站,有时候可能需要多等待一会)
下滑,到以下部分,Ubuntu系统选择Linux,直接在windows中操作的选择Windows,选择一个CUDA版本(需要保证此处选择的版本<=刚刚指令查看系统的cuda版本),其他选项不变,复制下方命令-
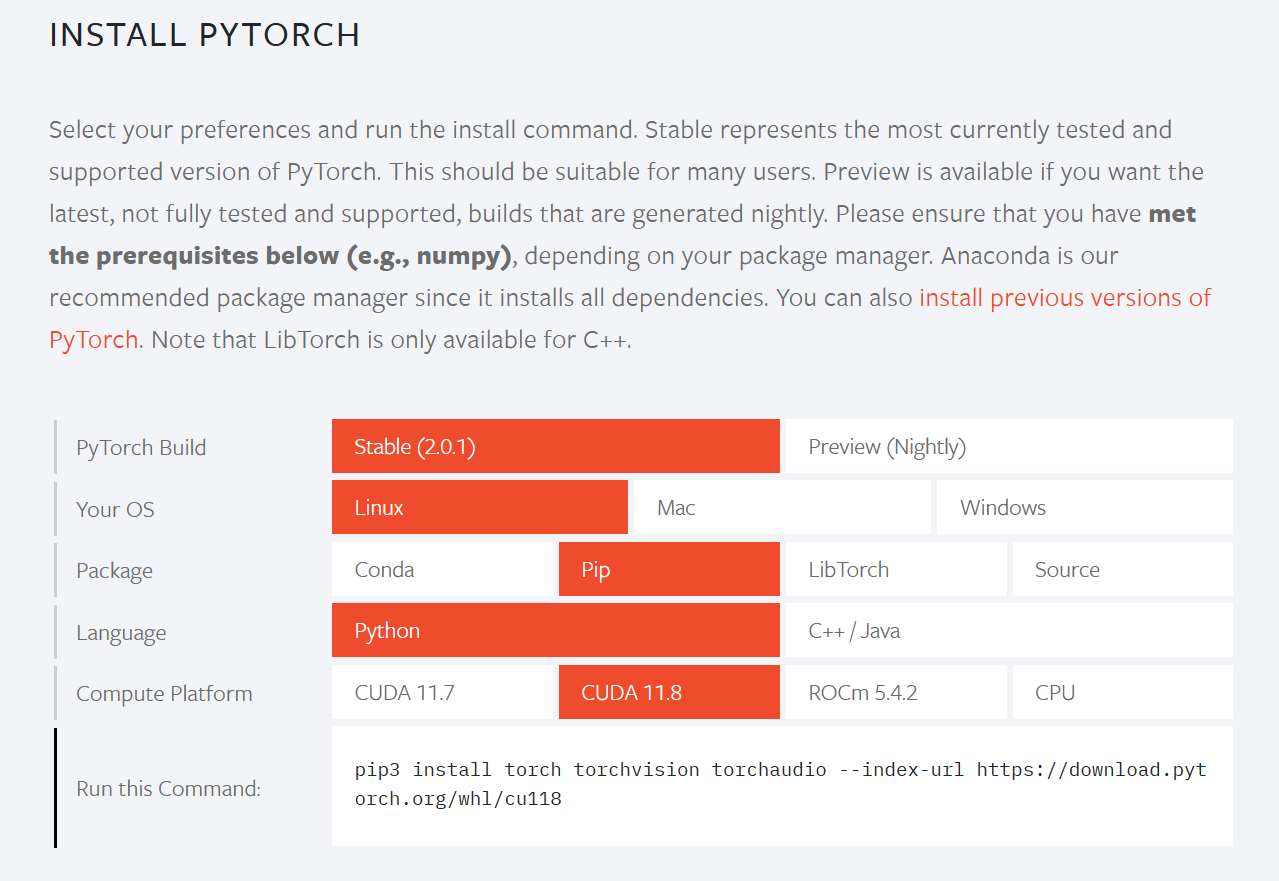
粘贴到命令行,开始下载,等待下载完成-

下载完成后,再次验证版本,方法和前文一致
PS:为了验证所有包都部署到位,你可以再次输入pip install -r requirements.txt,如果全屏无报错,就说明OK了-
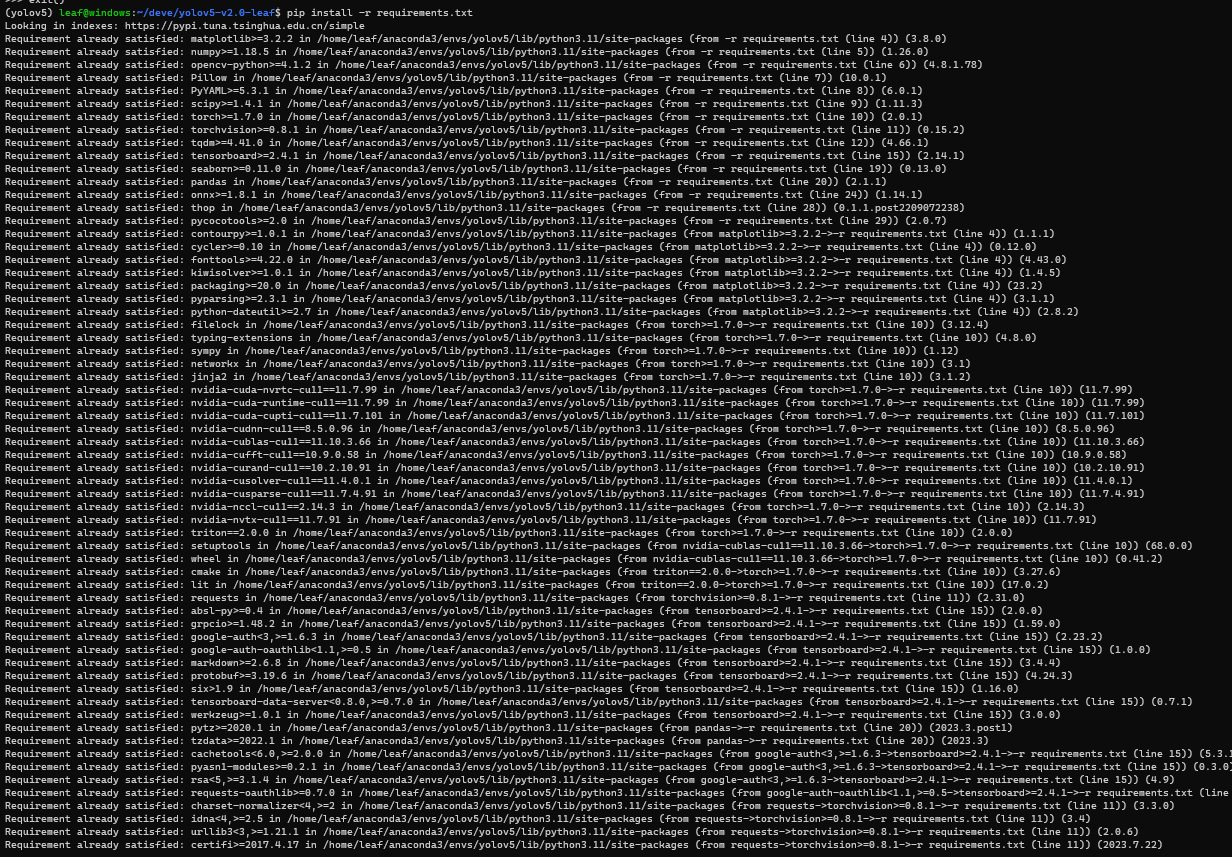
至此,你已经完成了所有环境的准备,并且所有的python第三方库都安装在了刚刚创建的conda环境中,可以轻松通过conda工具与其他环境进行切换
准备训练集
开始训练我们自己的模型前,你需要了解一下深度学习框架的基本使用模式,流程图如下图-

训练集(trains):不同的用途的深度学习算法训练集不同。在目标检测模型中,训练集就是几十或上万图片(image),并且通过一些方法将目标在每张图片中的位置标注(label)出来
训练框架:通俗的说就是代码文件,但不深入学习数据处理和神经网络等方面知识的我们是写不出其代码的,所以可以直接在网上找开源的源代码,前文中下载的便是yolov5开源框架(被我修改过一部分)
训练得到的模型:我们做训练的目的就是为了在有其中存在目标的新图片出现时,也能够找出其中目标的位置;我们训练得到的模型包含了训练优化的所有权重(weights)信息;简单来说,就是记录了这些目标的特征
推理(infer):这些特征人是不太能读懂的,因为他储存的格式就是为了给计算机看的,所以我们还需要推理代码。在进行推理时,会在代码中加载模型,也就是告诉代码:“我要你在代码中帮我找一个叫cat的东西,它四肢着地,竖着短耳朵…”,相应的推理代码会利用模型进行计算,把他认为可能性最高的目标的位置范围返回给你
知道了这些后,我们可以开始准备我们的训练集了
图片准备
拿我前段时间做光电比赛的骨牌为例
首先你需要足够的清晰目标图片-

在实际识别骨牌或其他目标时,会遇到光影,色差,角度不同等问题,因此如果你想让你的模型在相对极端环境下也能正确识别目标,你就需要拍摄极端环境下的图片,例如下面这张图片,极端还原了复杂环境-

并且最好考虑到模糊程度,大小不同等情况-

图片不一定要多,但你的模型的泛化能力取决于这些图片包含的不同环境是否全面
入门体验的话,你可以先找找身边结构较为简单的物品,拍摄100张图片左右即可
有一点特别需要注意:待会进行训练时,训练框架会自动把你的图片尺寸修改成640x640像素,所以你没必要拍摄太高像素的图片浪费内存,甚至如果你的识别物结构比较简单,尺寸还可以再小一些
图片标注
图片准备好了,你需要告诉计算机哪一部分是你需要让他认识到的目标,因此就需要对图片进行标注(俗称“打标”),在这里需要借助打标工具
这里我推荐一款国产的打标工具:精灵标注助手;相比大部分标注工具,它的界面,功能,体验更为简单-

官网地址:http://www.jinglingbiaozhu.com/
我在Ubuntu系统中尝试安装过,但没能成功启动,不知道是不是系统兼容原因。用Ubuntu系统的同学如果有遇到相同问题建议还是在Windows中安装并使用
打标前,把你的图片放在一个文件夹中(路径不要出现中文和特殊标点符号,最好是纯英文和下划线_组成),这里我简单放20张做个示范-

打开精灵标注助手,新建项目-
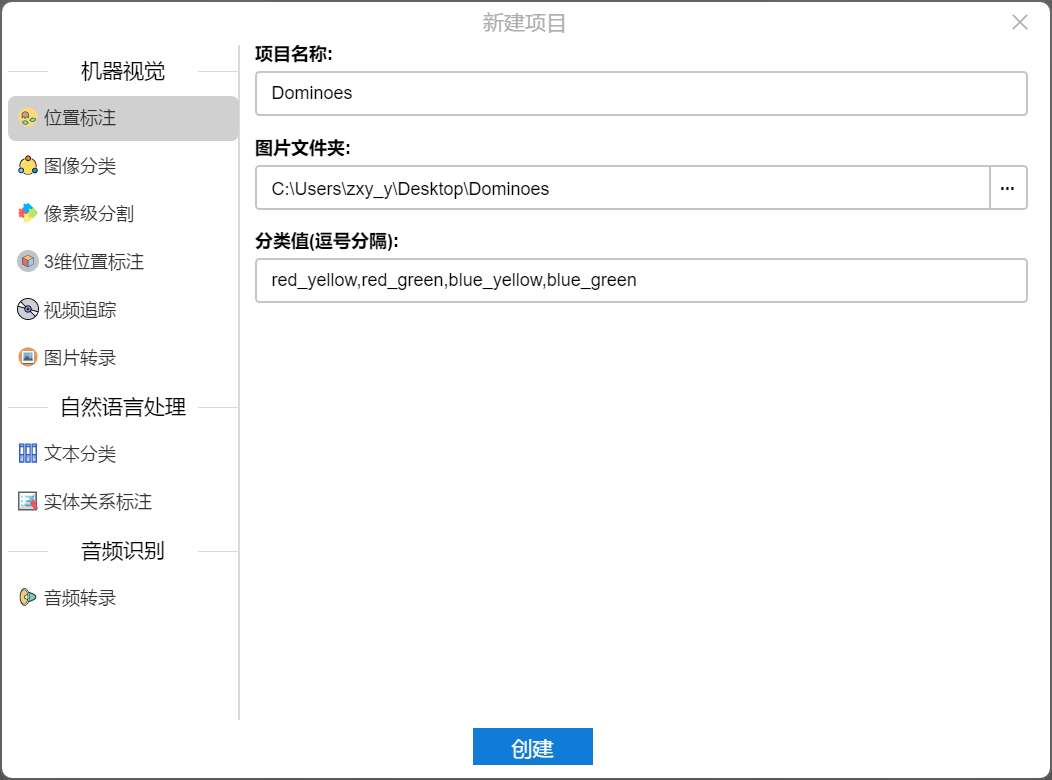
自定义一个项目名称,图片文件夹选择刚刚提到的(如果路径上有中文,就移动一下你的图片文件夹位置到路径没有中文的位置),然后输入分类值。-
需要注意:-
1、分类值输入时切换输入法为英文-
2、不同的分类用英文逗号隔开,不要加空格-
3、使用全英文或数字分类名称-
4、这里的顺序一定要记好-
点击创建,切记!!!创建完成后,在你真的开始训练前,最好不要移动,删除或重命名这个文件夹,否则可能造成你的标注丢失(白打标了)-
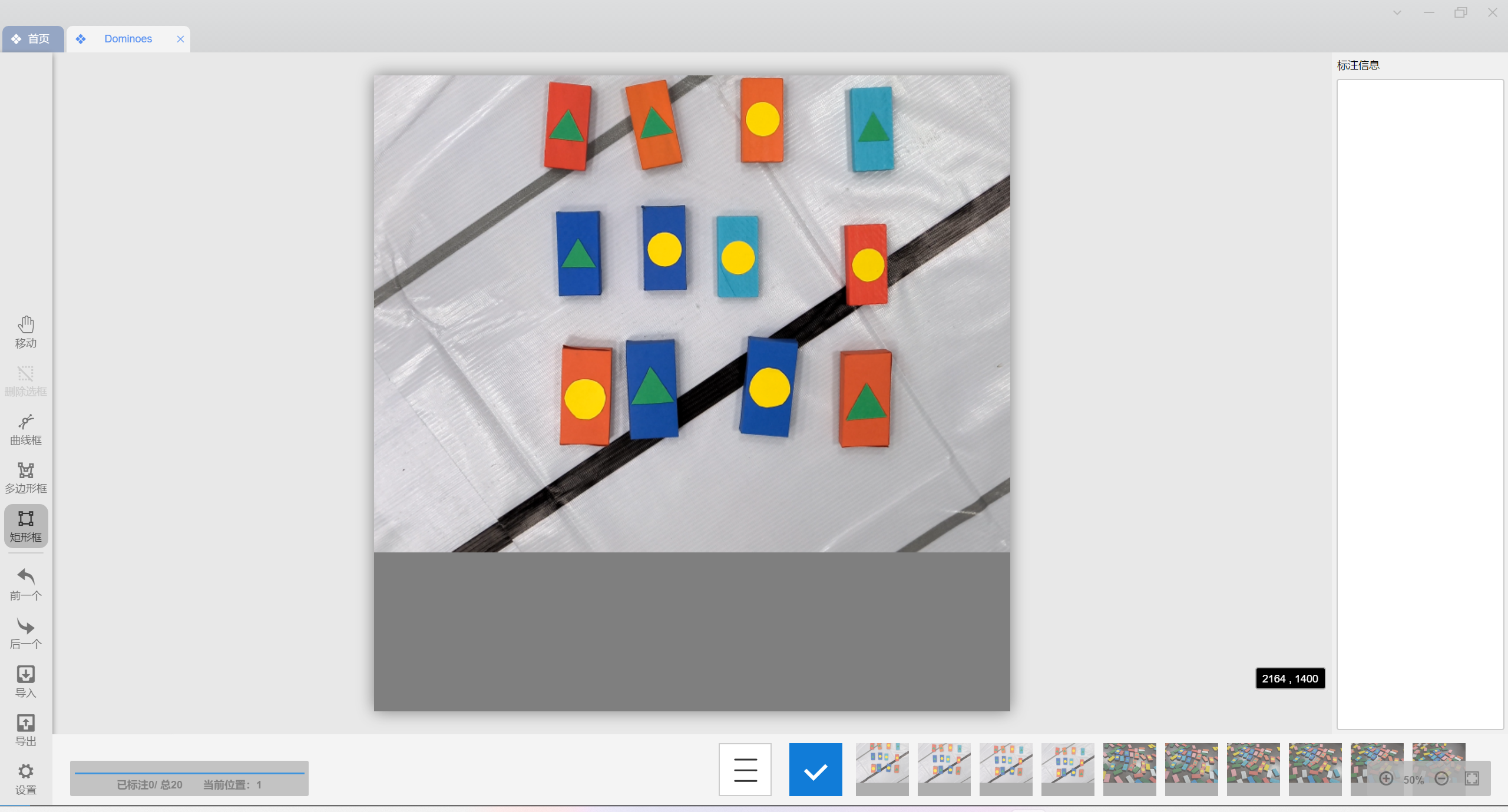
光标移动到左侧矩形框,可以发现给出了快捷键R的提示,在我们进入到一张新照片时会自动开启矩形框,但需要在照片中反复标注时就要反复唤起矩形框了,用快捷键会方便不少-

随后我们移动光标到目标轮廓处,按下,拖动,松开即可完成一个目标位置的标注-


标注框可以超过图片边界,我在后续会介绍我写的修正代码-

然后在右侧标注类别-

用光标拖动矩形框可调整位置,拖动角落可调整大小,可以用电脑快捷键DELETE或DEL快捷删除矩形框
注意矩形框可以框到外物上,但要在保证目标整体都处于矩形框内部的同时让框最小-

全部标注完就是这样了,点击下方的勾保存,看见左下角的保存成功后方可进行下一张图片的标注(切换图片就会清除当前未保存的标注信息,所以切换图片前一定要点保存)-
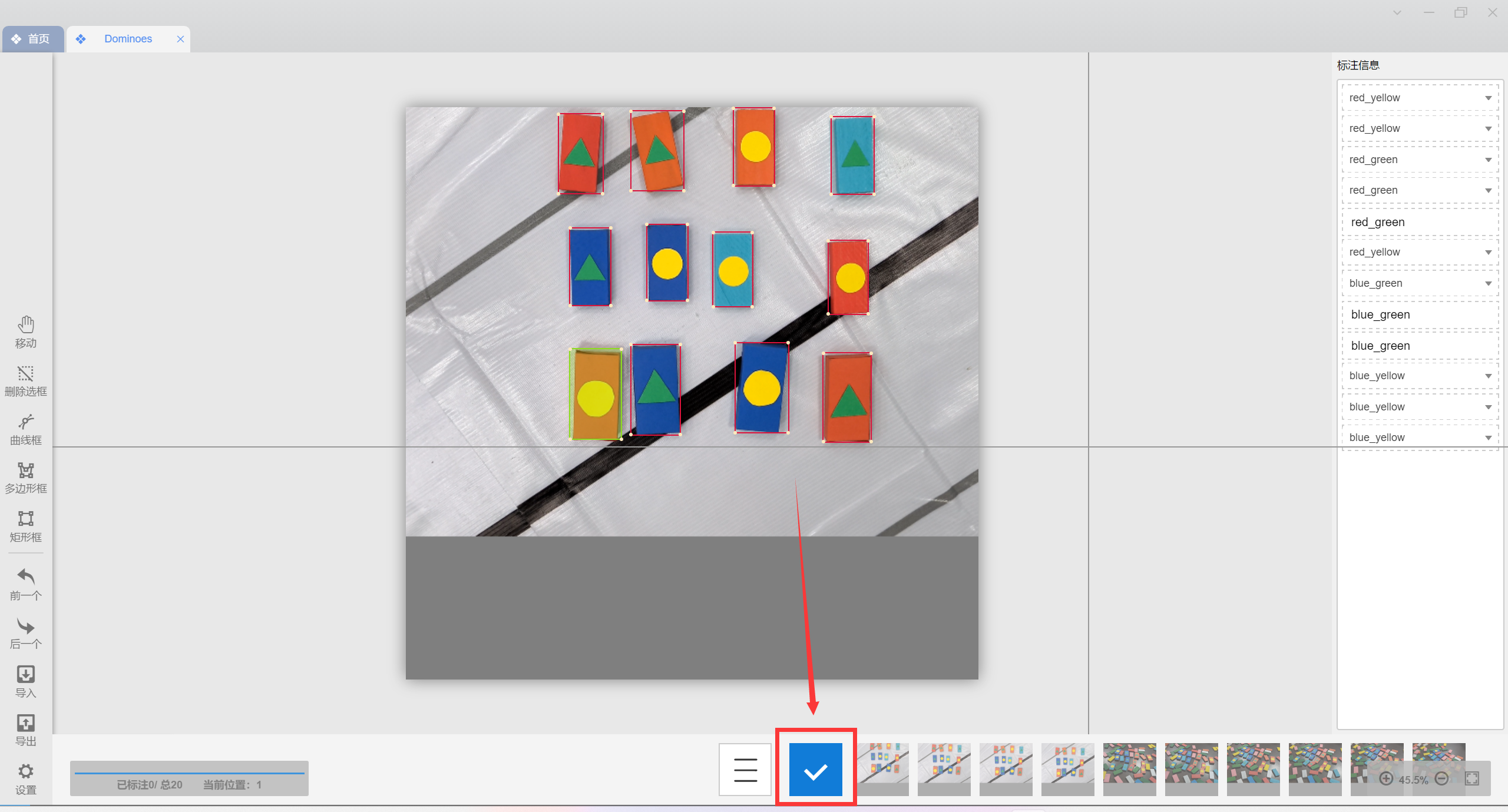

全部标注完成,保存并检查后,点击左下角“导出”,选择pascal-voc格式,选择一个路径输出标注数据,确定导出-

可以看见路径下生成了一个叫output的文件夹,里面存放了和图片数量相同的.xml后缀文件-


.xml后缀文件中记录了刚刚标注的位置和类别信息(看不懂也没关系)-

但目前这个格式不是yolov5训练的标准格式,接下来我来介绍格式转换
格式转换
首先打开yolov5源码下,我放置的voc_tools文件夹,里面的python脚本均是我做出来用于格式处理的-

在转换开始前,需要创建一个训练集文件夹,结构如下,位置随意(路径中不能出现中文),由于我经常使用各种版本的yolov5,所以我习惯把训练集放在yolov5源码目录之外-

1.图片格式转换
图片格式常用的就是.jpg和.png,这里如果不统一格式不方便后续转换,所以统一把.png格式改成.jpg
打开png_to_jpg.py,将file_src路径修改为你的图片储存路径,将file_dst修改为刚刚创建的训练集路径下的images/train,前面的r不能删,如图-

运行,程序输出处理完毕,可以看见训练集路径下的images/train已经有修改好格式的图片了-


2.标注格式转换
前面提到,标注工具输出的格式并不是yolov5需要的格式,现在我们使用xml_to_yolo.py进行转换
打开xml_to_yolo.py,往下滑,找到主函数入口。将classes修改为你的目标类别(注意要和前文说要记住的顺序一样);将xml_file后的路径修改为前面标注助手输出的output文件夹;txt_file修改为训练集文件夹下的labels/train-

运行,可以看见训练集文件夹下的labels/train生成了相同数量的txt文本-


这些文本中便是需要的标注信息格式,他们的文件名和对应照片名字相同,每一行分别记录了一个目标类别,位置信息-
3.标注信息修正
标注的时候我提到,可以把框打到图片外,这会导致刚刚生成的标注文件中的标注框坐标出现负值,可能会导致yolov5训练时报错,所以我们使用Labels_corrct.py,将标注框位置修正回图片范围内
打开Labels_corrct.py,将path修改成txt文件的位置,运行即可-


4.验证集的抽取
至此训练集和标注已经基本配置到位了,还差最后一步:从训练集中抽取验证集
yolov5训练时,内部各种参数的更新是有随机性的,所以需要一部分验证集来引导这份随机性
打开train_to_val.py,拉到最底下的主程序入口(if __name__ == '__main__':),在对应位置分别输入训练集文件夹下的images/train,images/val,labels/train,labels/val文件夹,记得用绝对路径-
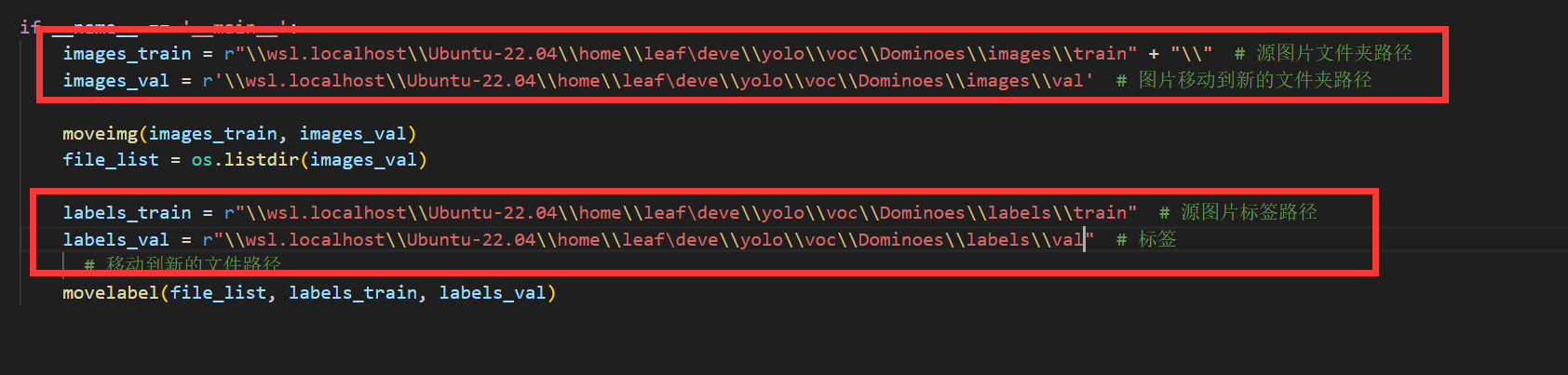
运行脚本,可以发现图片和标注已经被移动了,默认移动20%-

*Keep_duplicates.py
voc_tools中还有一个脚本名为Keep_duplicates.py,这个脚本的作用是:使用网络上的训练集时,有些训练集数据有丢失,图片和标注文件不对应,该脚本可以删除不对应的部分的图片或标注,有需要的读者自行使用
至此,训练集的准备也到位了
训练模型
现在我们可以开始训练模型了,但在训练模型前,我们还要完成一些关于模型的配置
获取模型权重
训练前需要获取yolov5权重,在yolov5的github官网上下载速度可能比较慢,所以我放在了百度网盘上-
百度网盘链接:https://pan.baidu.com/s/1gxHLHz83bT6KxuBxJggVmA-
提取码:leaf
这边的权重有4种,小白初次体验只需要下载yolov5s就够了-

四个尺寸的权重(s,m,l,x),文件大小依次增大,识别精度依次增大,运算速度依次变得缓慢
下载完成后,放在yolov5目录下的weights文件夹中(没有就创建一个)-

训练文件配置
训练框架没法知道你想训练哪种尺寸的模型,也无法知道你想训练的模型的目标类数量和训练集路径,所以我们需要配置训练文件,来将这些信息传递给代码,文件不多,只有2个
首先来到yolov5目录下的data文件夹,打开voc.yaml,train和val后面的参数分别改成训练集文件夹下的images/train和images/val文件夹绝对路径,nc改为你的目标数量,names改成目标类别,要和打标时的类别一一对应,然后记得保存-

然后来到yolov5目录下的models文件夹,可以看见有以下文件,分别对应各个尺寸的模型权重-

把需要训练的尺寸的模型权重对应的文件复制一份,这里以yolov5s为例-

然后打开,只需要把第一行这个nc改成你训练的类别数量就好了,其他的不要动,保存-
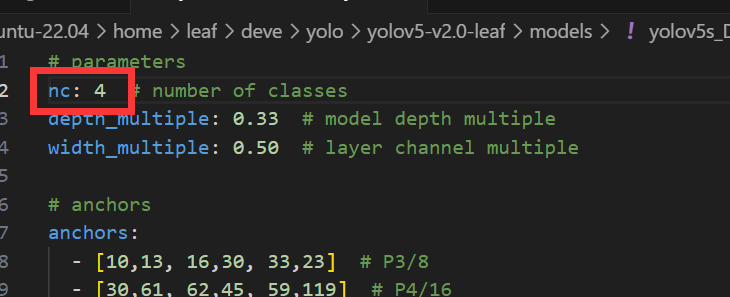
两个训练文件已经配置好
训练参数配置
离训练模型已经很近了,接下来还需要配置好训练参数
打开yolov5目录下的train.py,往下拉到400行左右的主函数入口处-
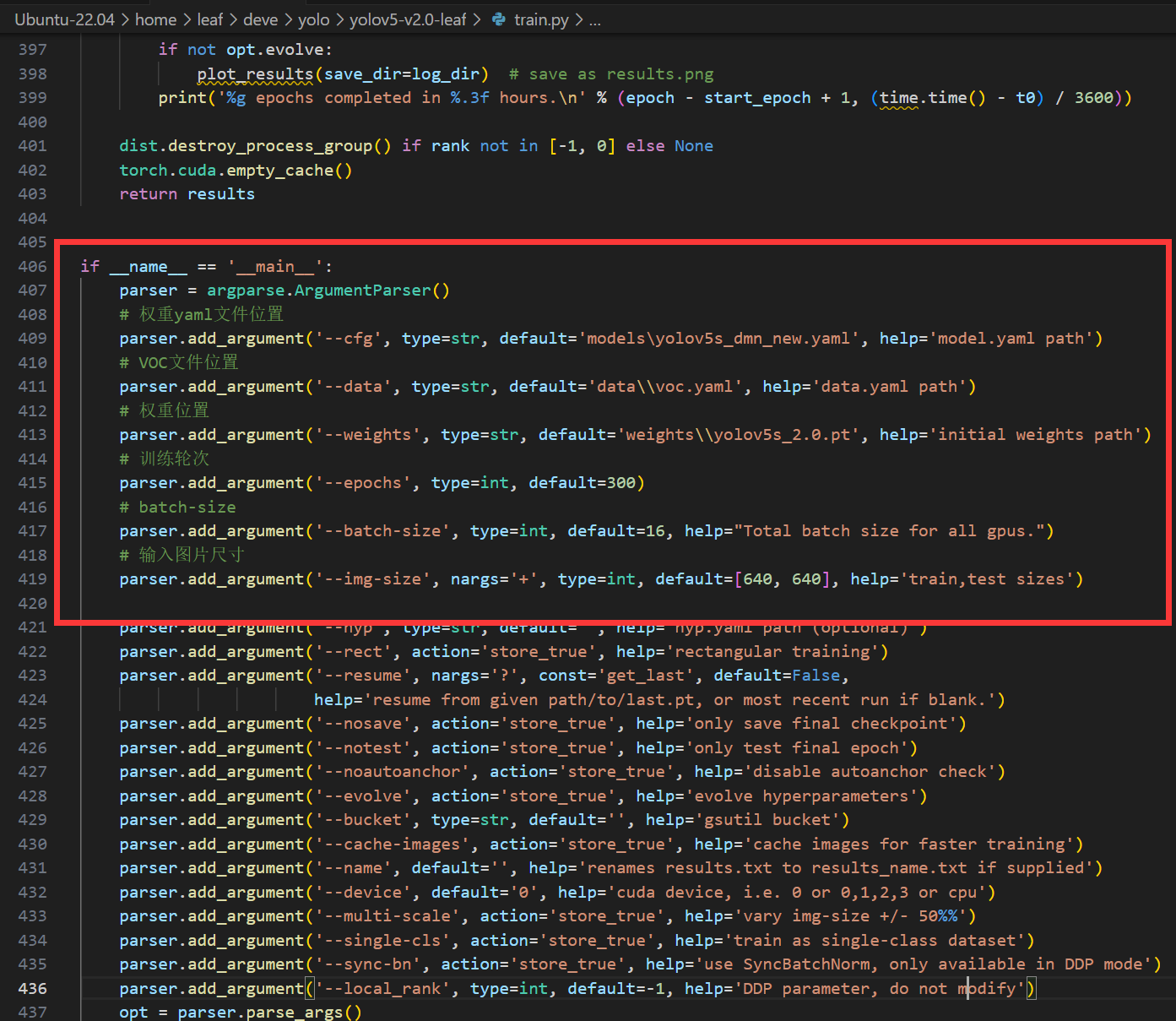
重要参数我已经注释出,把VOC文件位置和权重yaml文件位置的参分别改成刚刚配置的两个文件,这里用相对位置或者绝对位置都可以(不同系统要注意斜杠)-

权重位置,就是刚刚百度云下载的文件位置-

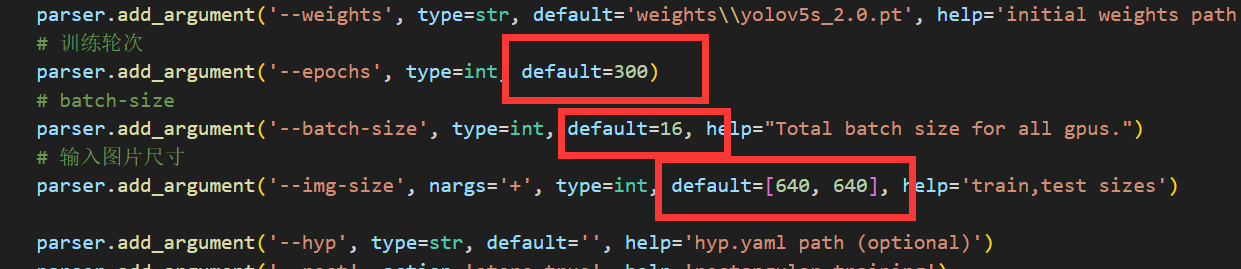
接下来是训练时的3个参数,我依次进行说明-
-
训练轮次(epochs):顾名思义就是模型训练迭代的次数,一般可以先默认300,追求速度可以调成100,不过模型精度会下降
-
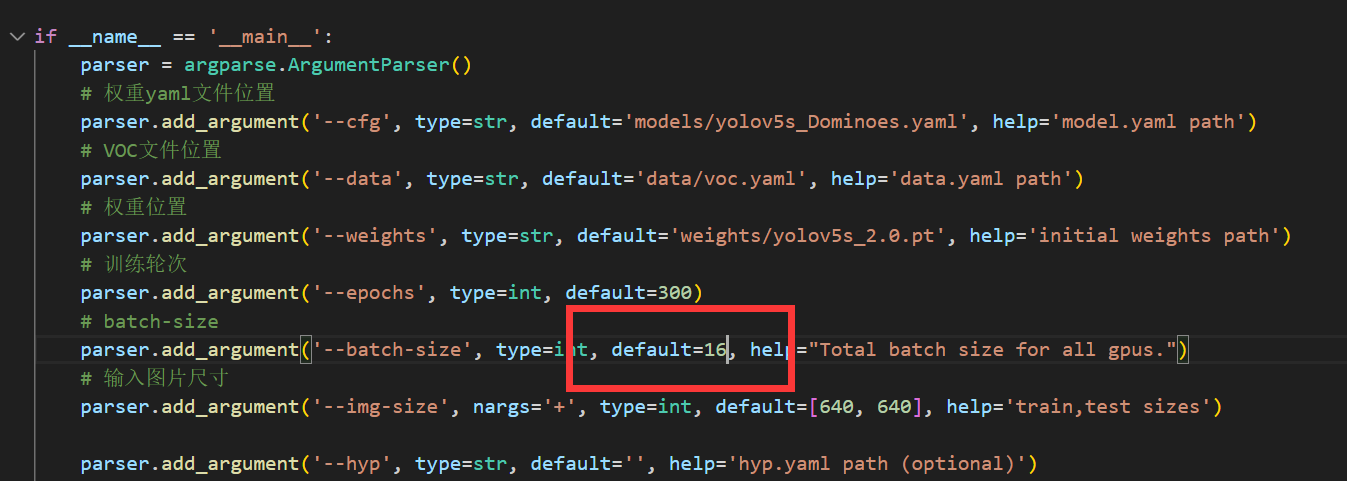
batch-size:这个所谓的size,指的是每次训练投入的样本数量,同理:过小的话模型训练不到位,精度不够;过大的话内存和显存扛不住就会报错,这个参数还是因配置而异,可以先用16试试。需要注意的是batch-size的值最好是2的幂次数(2,4,8,16…)。如果电脑配置不行,batch-size不够,那就必须提高epoch数量,这就是所谓的时间换空间。(电脑配置好的话就是空间换时间)
-
输入图片尺寸(image-size):这个size指的是输入给模型的图片大小,框架会自动resize,入门体验的话不要动这个。
训练模型和常见报错
保存好配置后,可以直接运行这个train.py了(记得先进入前面用conda创建的环境),在此我简述一下可能遇到的报错
提示未找到文件时,基本上是两个原因:1.路径写错了;2.斜杠问题-
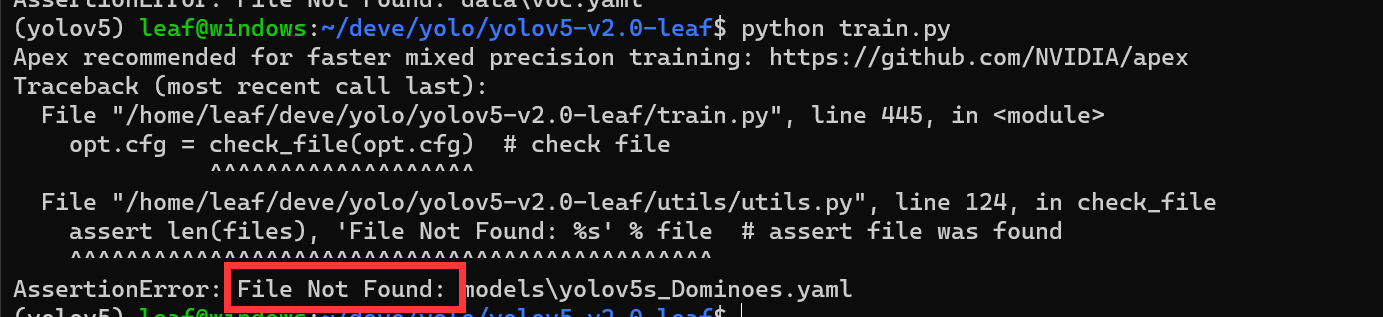
路径需要自己检查,需要注意的是斜杠,Windows下用反斜杠,但反斜杠又是python转义符,所以双写消除转义,如下-

Ubuntu下一个正斜杠即可-

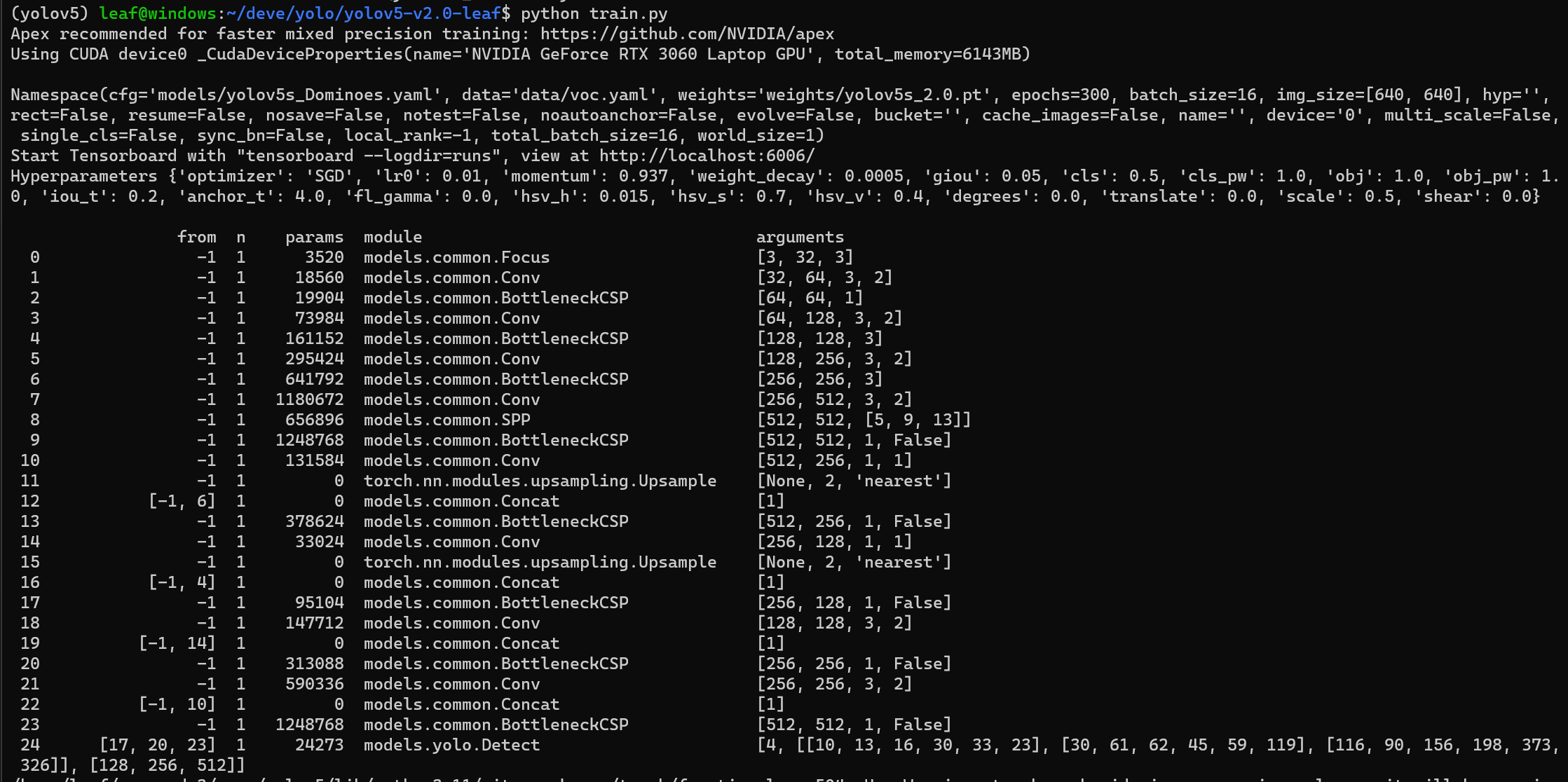
解决完这个报错,再次运行,发现输出了以下信息(这是yolov5模型的层结构),表示训练脚本能跑了-
接着发生报错如下-
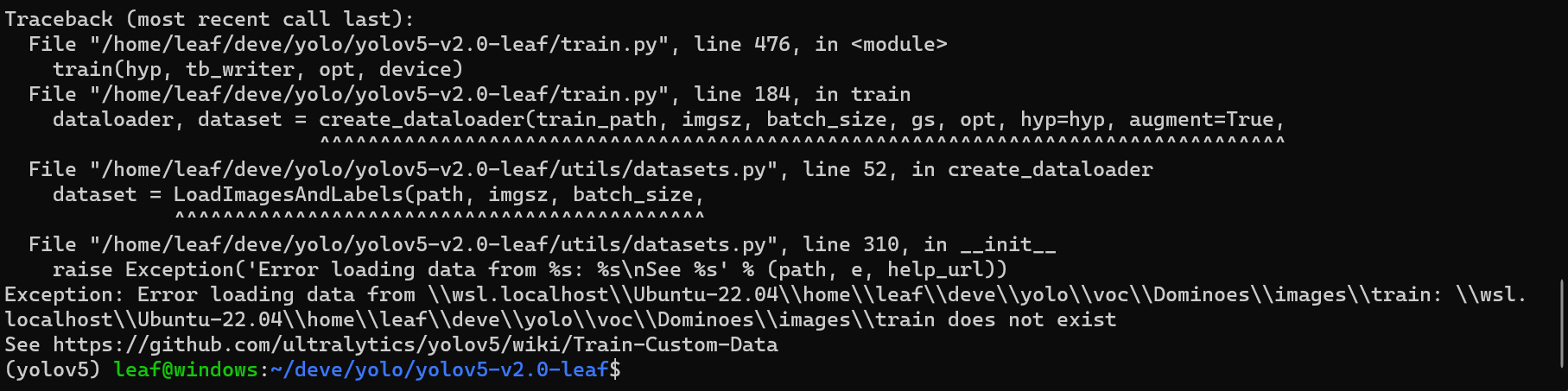
这是因为之前配置的voc.yaml中的斜杠问题,我用的是ubuntu系统,所以要改成正斜杠并去除子系统标识,所以windows不会发生这个报错-


接着有可能发生报错Could not load library libcudnn_cnn_infer.so.8.-
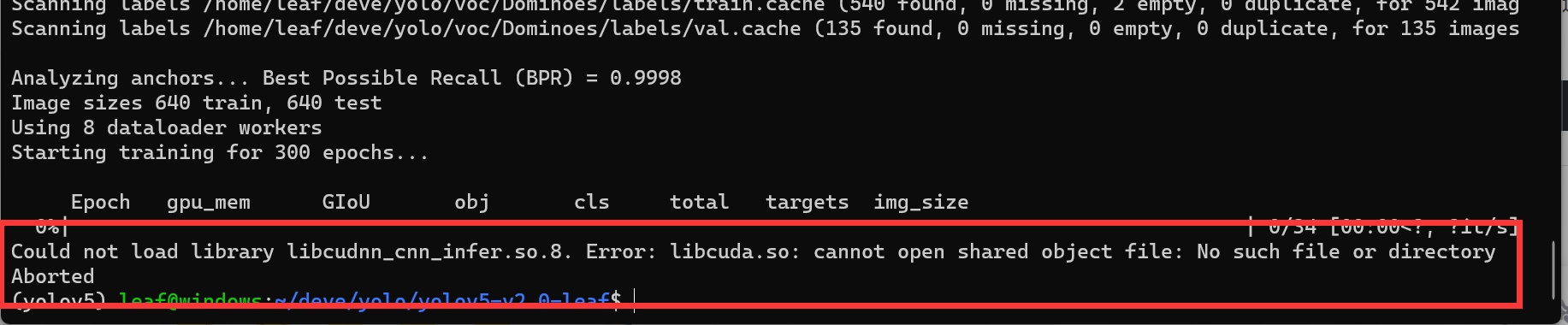
这是因为没有安装cudnn,Ubuntu在命令行输入sudo apt install nvidia-cudnn,并输入sudo密码,输入Y,等待漫长的安装…在此期间你需要保持良好的网速避免下载超时-

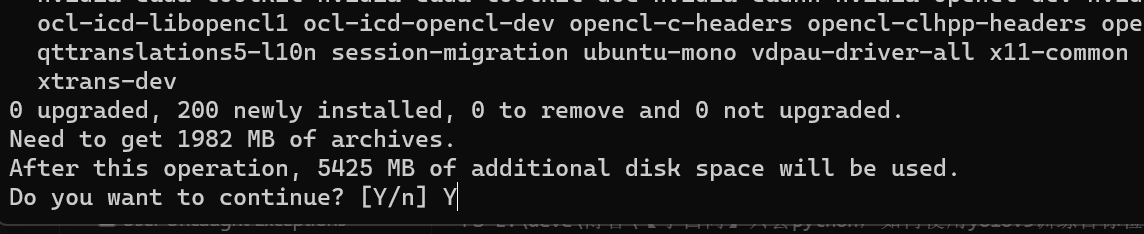
下载完成后界面会变成下面这样,用依次TAB选择OK,I Agree,进行安装,安装完成即可正常训练-




如果报错RuntimeError或torch.cuda.OutOfMemoryError,说明train.py中的batch-size参数太大-
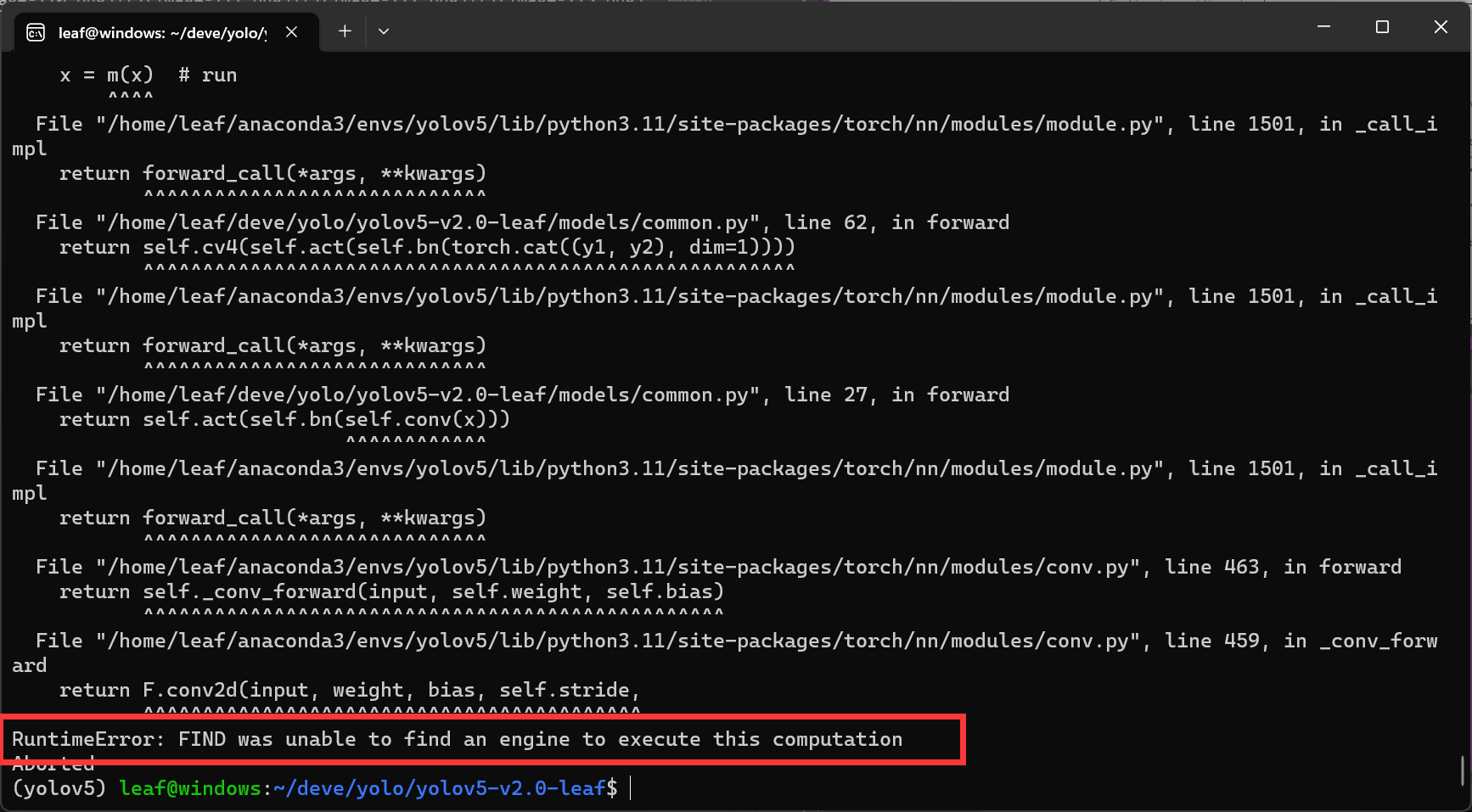

将其减小(最好还是2的幂次数)即可正常训练-
看见输出了两三个训练进度条就说明在正常训练了,注意每个epoch的用时,纬我的3060大概半分钟一个epoch,如果你也是独立显卡,并且用时超过了一分钟左右,那么可能出了某些问题导致你的GPU没有在加速训练-

训练完所有epoch后,训练完成,终端会输出模型存放的地址和训练耗费时长-
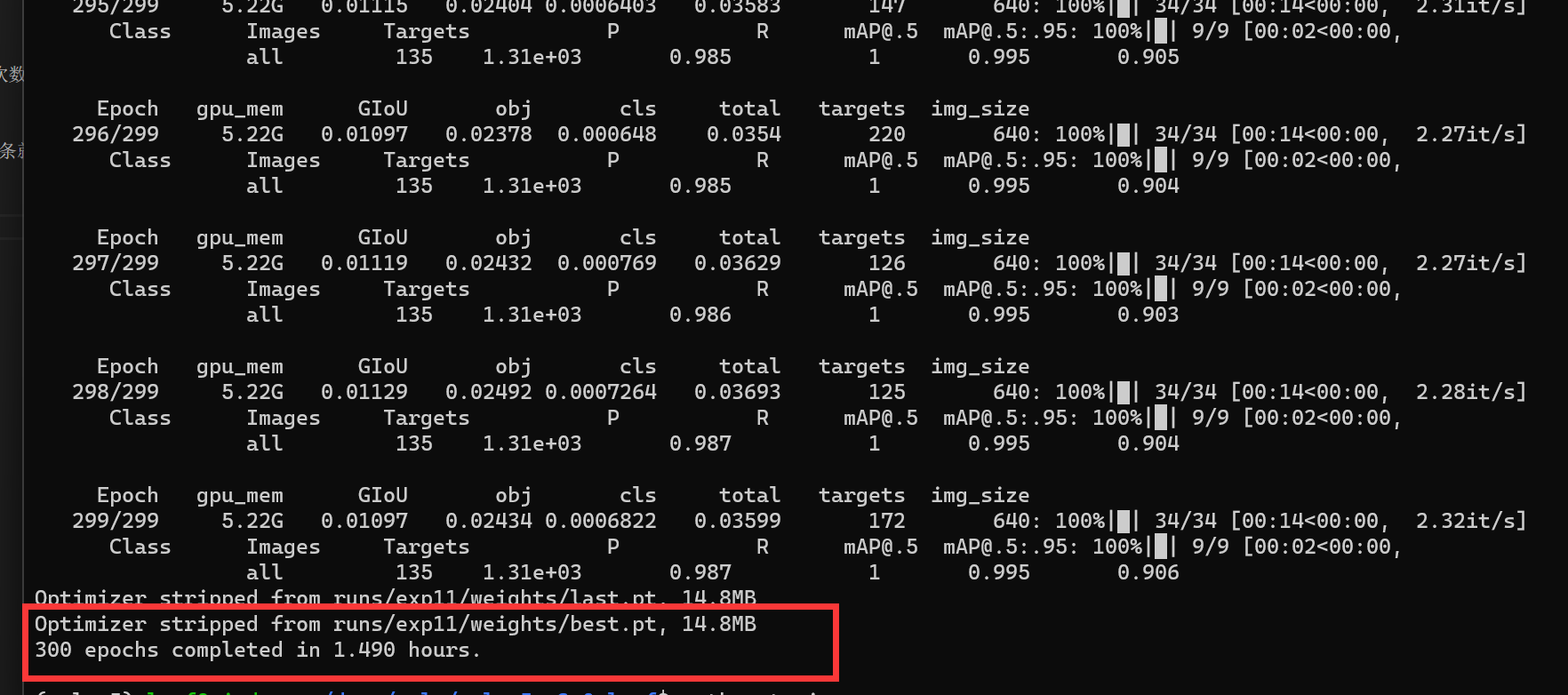
值得一提的是,前面也说过这份代码是我改过的,yolov5-v2.0代码本身存在一些错误被我修改了,所以如果你在训练的过程中遇到上面没有提到的报错,不妨看看我在地平线开发者社区投稿的另外一篇帖子:【模型提速】如何在X3pi使用yolov5模型50ms推理,这篇文章中提到了更多关于yolov5-v2.0的代码bug
使用模型进行目标检测
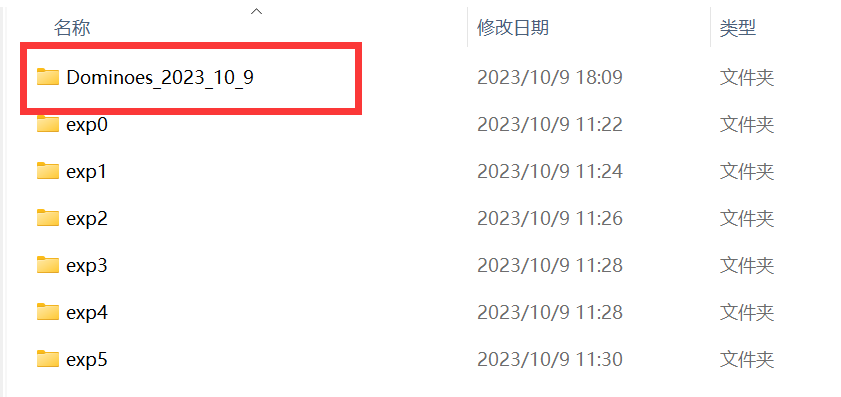
打开yolov5目录下runs文件夹,如果我没猜错你的文件夹里肯定有很多exp文件夹-
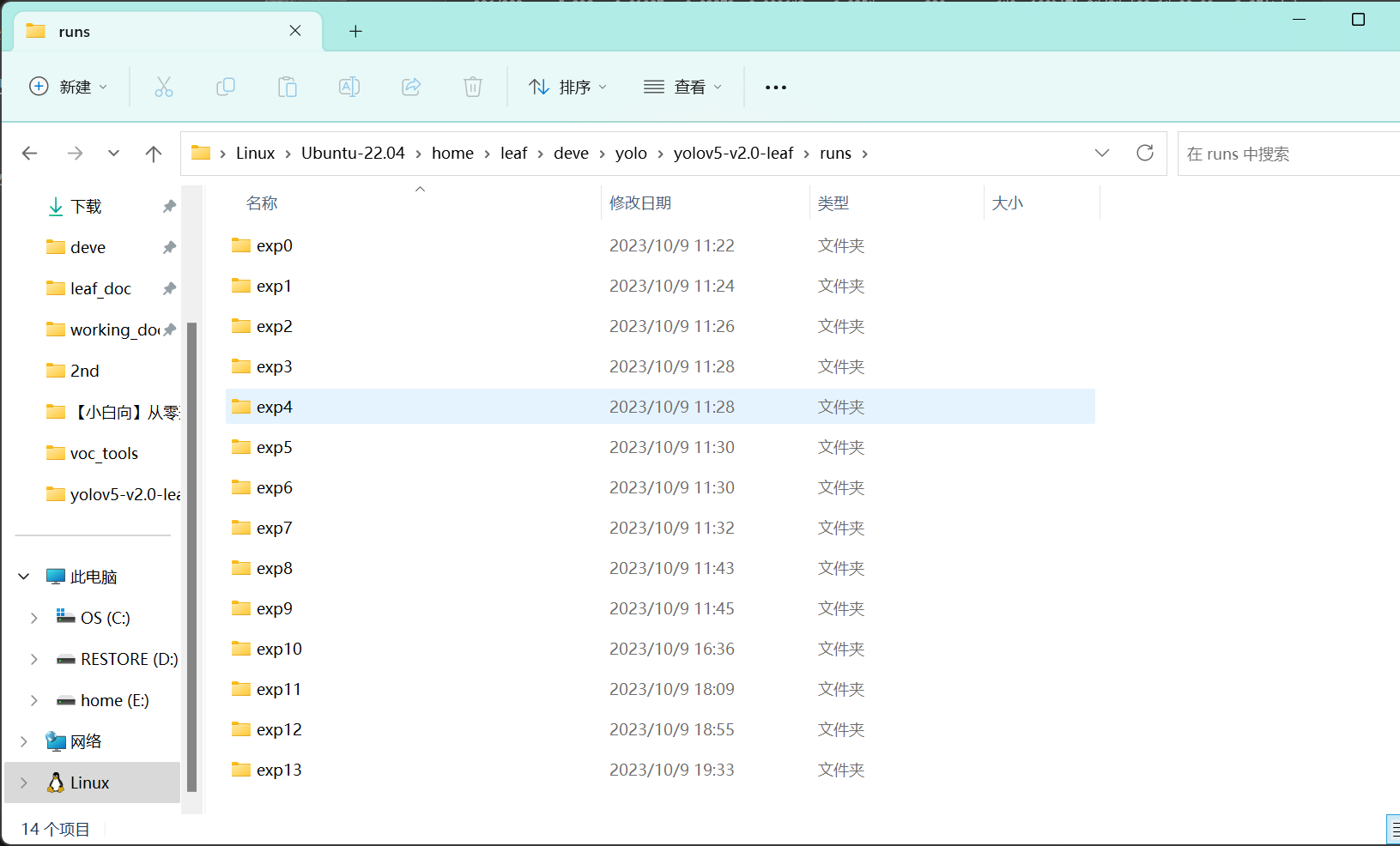
这是因为每次运行train.py都会生成一个exp,不论是否完整训练结束,在外面刚刚修改bug的时候已经自动生成了很多文件夹了
但是别忘了训练完成的时候终端给我们输出了模型保存路径-
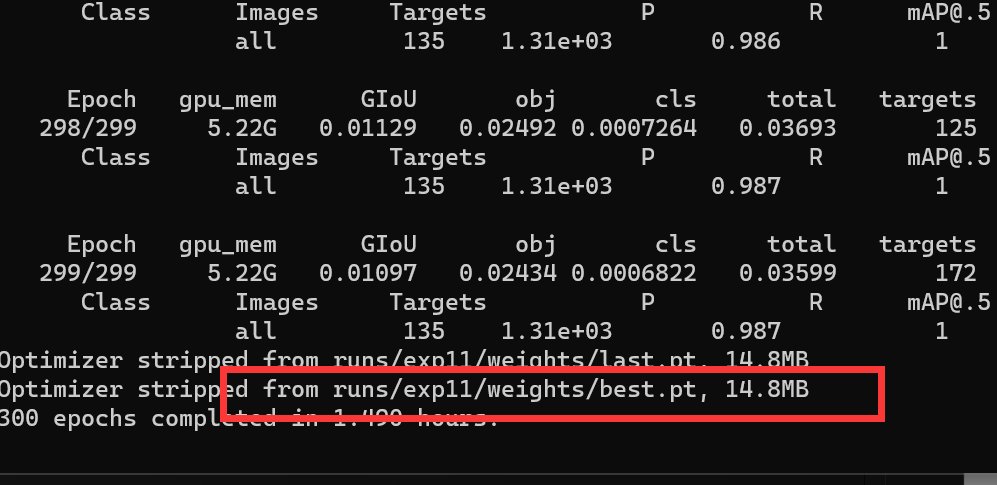
打开对应的exp编号文件夹,发现有很多文件,这些都是训练时的各个参数输出,方便调优-

而我们训练出的模型,就是weights文件夹中的best.pt-

为了记住他,你可以将这个exp文件夹重命名-
接下来我们开始体验目标检测,打开yolov5目录下的detect.py,来到主函数入口-
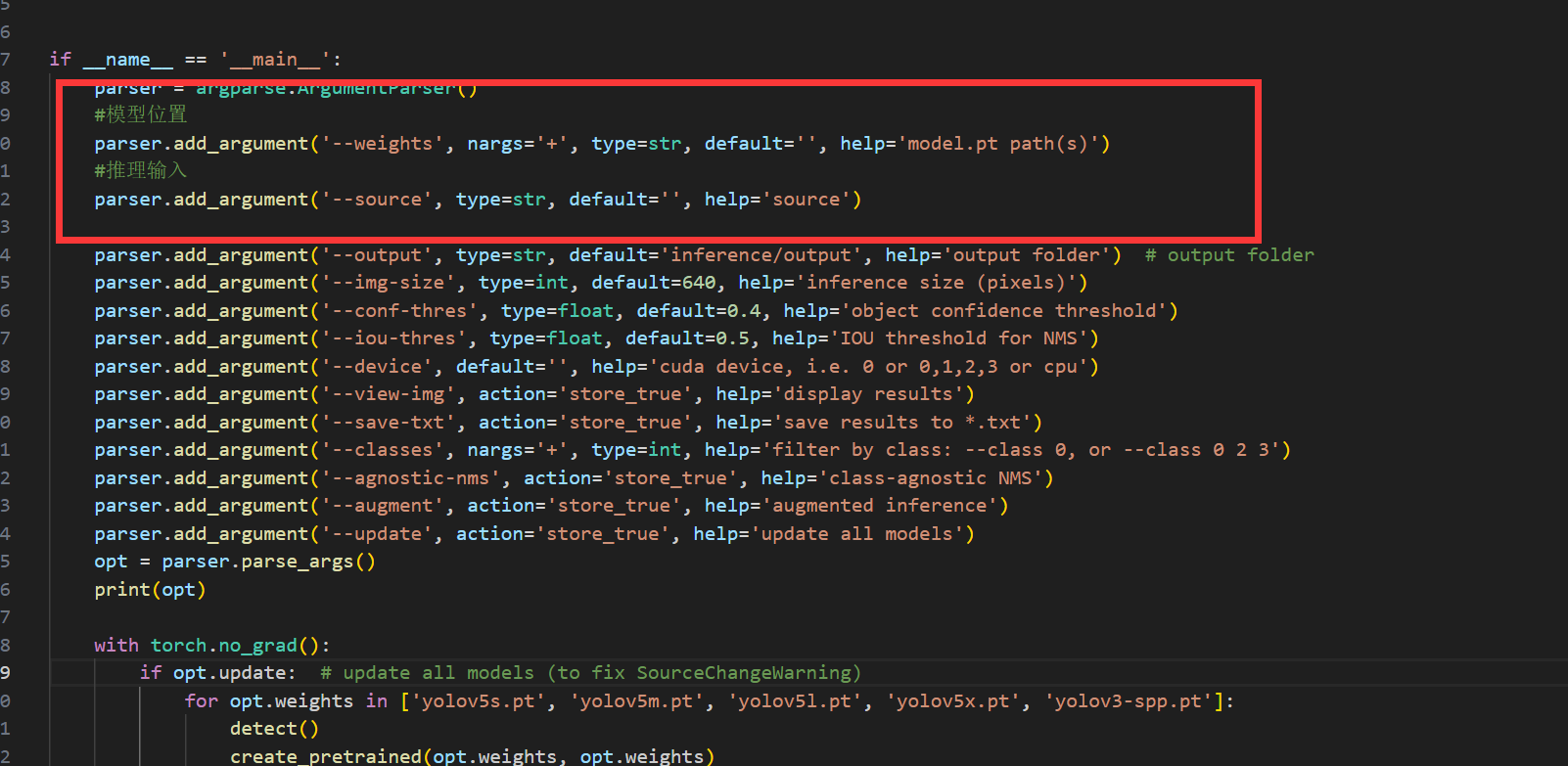
重要参数我也标注出来了,分别在参数处放上刚刚训练的模型的路径(best.py)和需要进行推理的图片-

我们用一张模型还没见过的图片来测试-

运行detect.py,输出无报错即可-
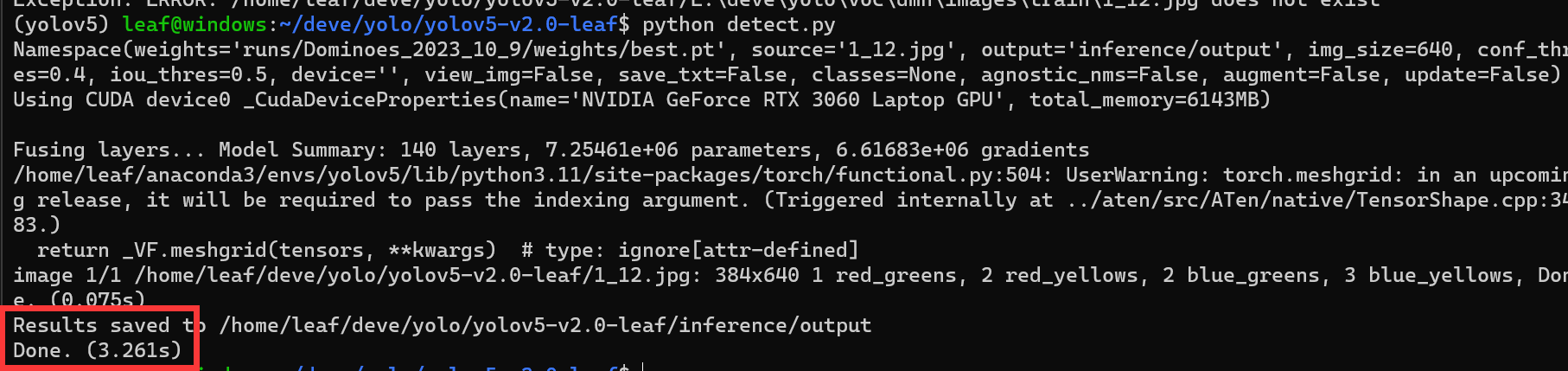
可以发现yolov5文件夹下生成了名为inference的文件夹,里面有刚刚推理的渲染结果-

可以发现,对于这张没见过的图片yolov5也能很好的识别并给出相应置信度,这就是模型的泛化能力
如果把推理输入的路径改成‘0’,就会调用设备的摄像头来进行连续推理(Ubuntu子系统可能无法正常打开摄像头,但无伤大雅)-

总结
跟着我的“流水账”,你已经完成了yolov5目标检测模型的训练,并且体验到了其推理功能。
我的这篇博客是面向零基础小白的,并且使用yolov5-v2.0v版本进行改版并说明是为了后续的帖子教程:在地平线RDK X3开发板上部署模型并加速推理
本篇博客编辑时长大约一周半左右,许多地方可能没有时间上的连续性,如果有疑问或建议,欢迎给我发送邮件:zxy_yys_leaf@163.com
接下来我也会尽快肝出部署教程,敬请期待
