0 前言
YOLO (You Only Look Once) 系列模型在端到端(end-to-end)实时目标检测(Real-time Object Dectection)任务中得到了广泛应用,得益于其在识别速度和识别精度上达到的平衡。同时YOLO也是目标识别One-Stage方法中的典型模型。-
YOLOv8是由Ultralytics公司开发并开源的前沿state-of-the-art (SOTA) 模型,YOLOv8是YOLO系列的最新模型,在以前成功的YOLO版本基础上,引入了新的功能和改进,进一步提升了其性能和灵活性。YOLOv8基于快速、准确和易于使用的设计理念,使其成为广泛的目标检测、图像分割和图像分类任务的绝佳选择。YOLOv8开源项目获取:Ultralytics。-
随着YOLOv8模型代码的开源,对于YOLOv8在端侧部署的探索持续进行,端侧的计算平台往往有着算力、存储和带宽等的诸多限制,因此在尝试直接将公版YOLOv8模型部署在地平线芯片上的过程中,并未取得预期的性能和量化精度保持结果。因此在社区优秀开发者的启发下,结合地平线高效模型的设计经验,地平线对YOLOv8模型进行了修改和适配。
- 本文以MS COCO数据集训练的2D目标检测模型为例,对于其他任务场景,读者可参考并自主适配;
- 本文模型改动和设计基于X3,对于J3和J5的用户,同样可以参考本文的模型设计;
- 本文性能数据来源:x3sdbx3-samsung2G-3200板端实测,Latency为单核单线程(不包含后处理),FPS为双核八线程(不包含后处理);
- 本文精度数据为X86端Python环境测得。
适配地平线的YOLOv8项目源码获取:model zoo
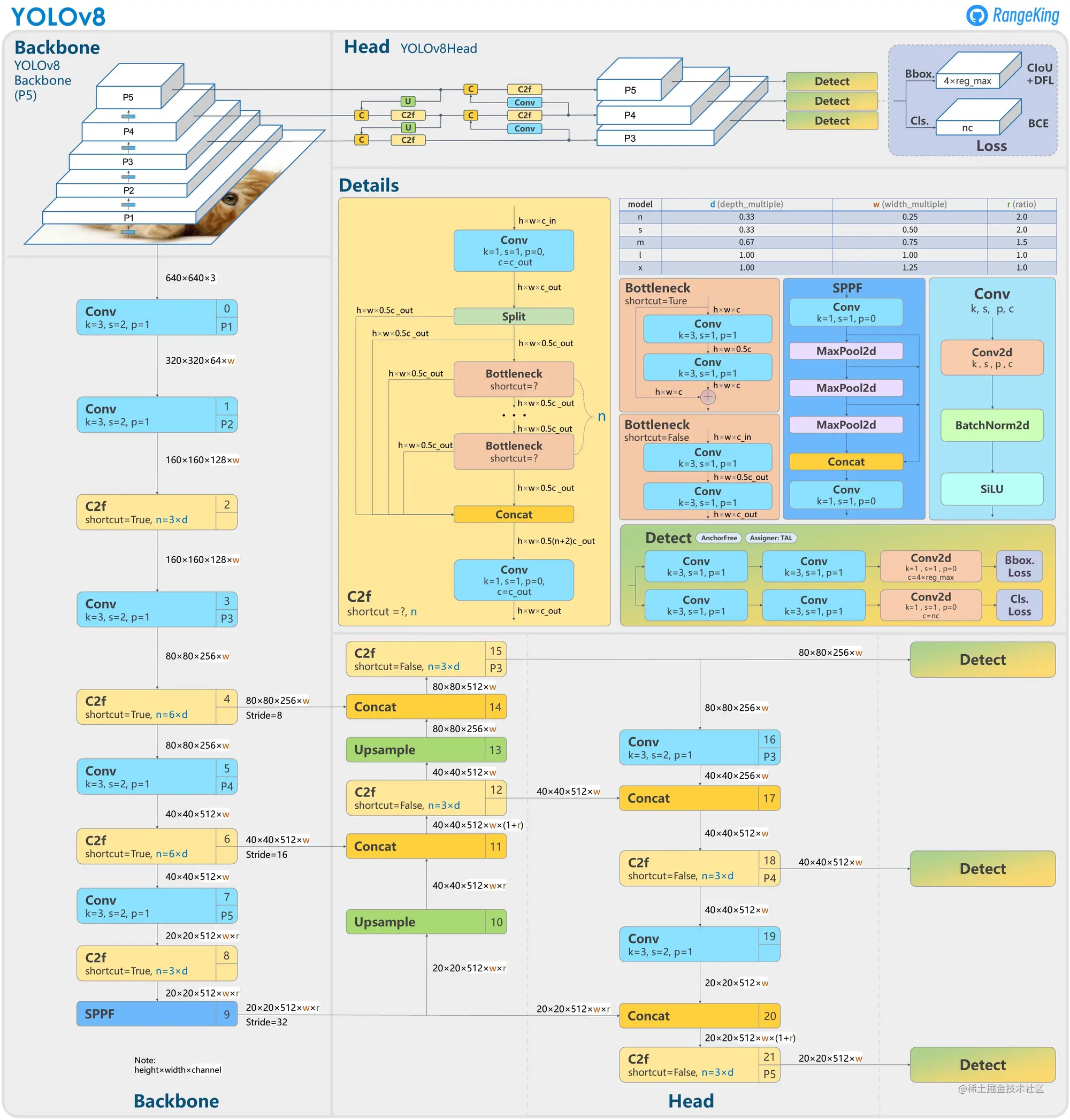
1 模型结构
YOLOv8模型结构图可参考:
2 模型改动
2.1 Head
公版模型检测头会包含bbox和cls的特征解码,也就是下图红框内的内容:
-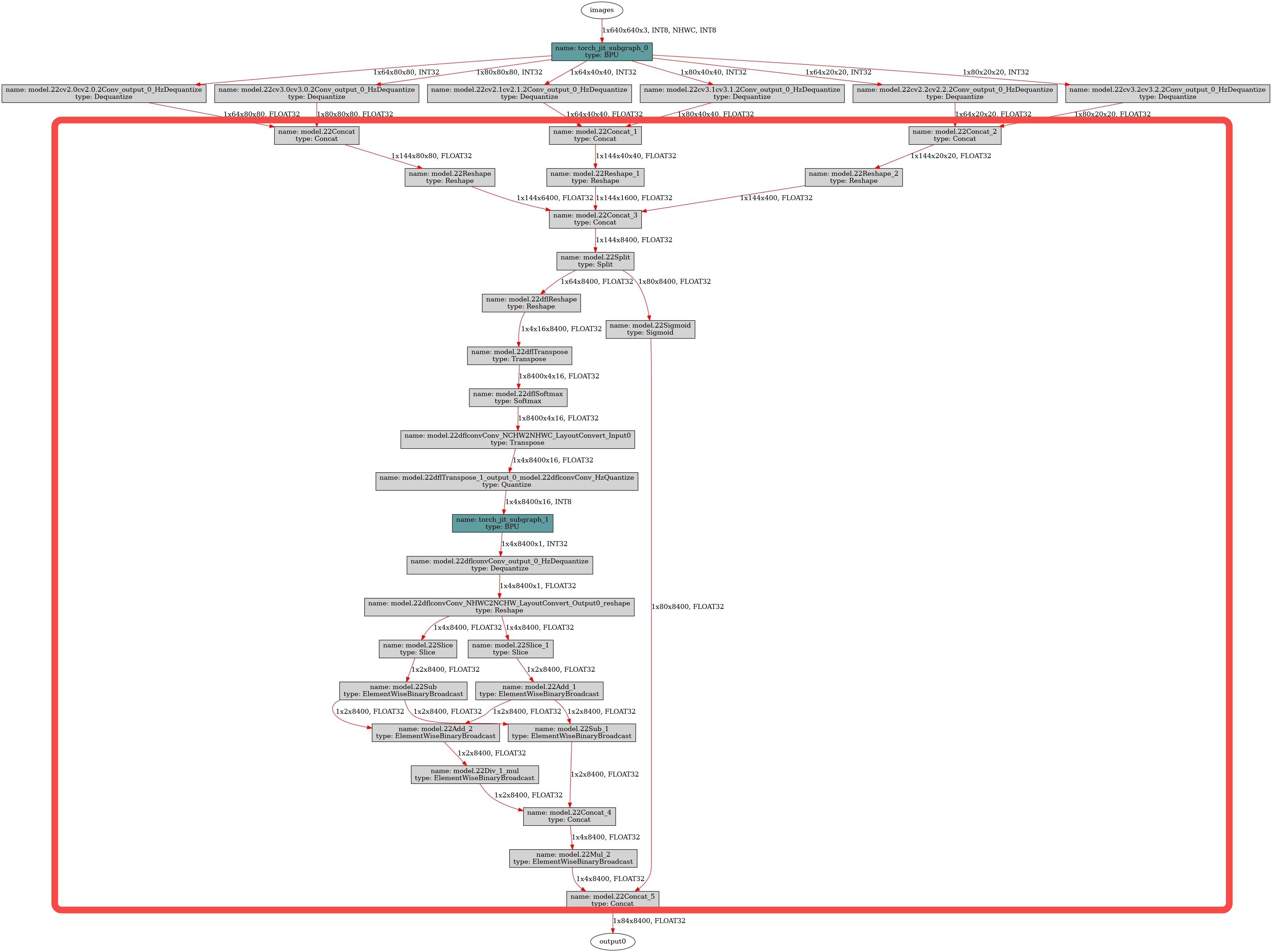
在X3上,特征解码的这部分内容:
- 存在BPU不支持的算子如Transpose和Reshape等,BPU无法加速,会由CPU执行并计算;
- 存在数据搬运类算子如Concat等,BPU支持并不高效;
- 存在一个BPU子图,其前后的量化反量化算子为CPU计算并且无法删除,结构上不友好。
出于性能优化的考虑,将特征解码部分的内容从模型中删除,放到后处理中,性能收益参考如下板端实测数据(只进行Head部分改动,模型其他部分和公版相同):
特征解码删除前Latency (ms)
特征解码删除后Latency (ms)
特征解码删除前FPS
特征解码删除后FPS
412.5
309.8
11.7
16.6
代码改动:
# 原代码
class Detect(nn.Module):
...
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
shape = x[0].shape # BCHW
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training:
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV ops
box = x_cat[:, :self.reg_max * 4]
cls = x_cat[:, self.reg_max * 4:]
else:
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
if self.export and self.format in ('tflite', 'edgetpu'):
# Normalize xywh with image size to mitigate quantization error of TFLite integer models as done in YOLOv5:
# https://github.com/ultralytics/yolov5/blob/0c8de3fca4a702f8ff5c435e67f378d1fce70243/models/tf.py#L307-L309
# See this PR for details: https://github.com/ultralytics/ultralytics/pull/1695
img_h = shape[2] * self.stride[0]
img_w = shape[3] * self.stride[0]
img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1)
dbox /= img_size
y = torch.cat((dbox, cls.sigmoid()), 1)
return y if self.export else (y, x)
# 修改后
class Detect(nn.Module):
...
def forward_horizon(self, x):
results = []
for i in range(self.nl):
dfl = self.cv2[i](x[i]).permute(0, 2, 3, 1).contiguous()
cls = self.cv3[i](x[i]).permute(0, 2, 3, 1).contiguous()
results.append(cls)
results.append(dfl)
return results
代码路径:ultralytics/ultralytics/nn/modules/head.py
2.2 Block
2.2.1 激活函数
二维卷积模块中的激活函数由公版的SiLU替换为ReLU,和前序的Conv节点融合,在BPU上进行的查表操作速度最快,大大优化了性能;此外ReLU算子的输入输出数据量化精度要高于SiLU,对于量化也是友好的。同时保留了对量化友好的BatchNorm操作,二维卷积模块采用Conv+BatchNorm+ReLU的结构。-
代码改动:
# 原代码
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
...
# 修改后
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.ReLU() # default activation
代码路径:ultralytics/ultralytics/nn/modules/conv.py
2.2.2 可变组卷积
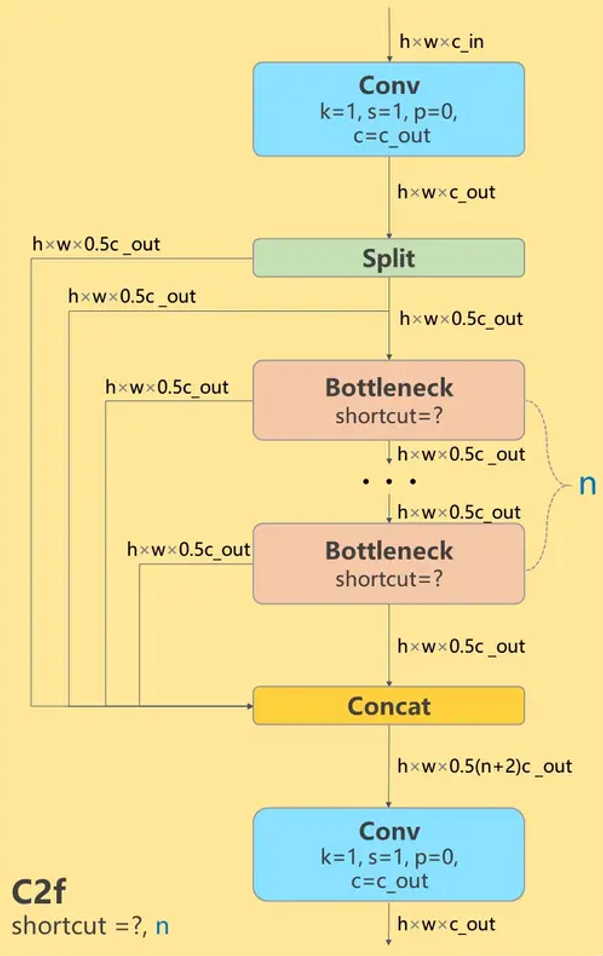
公版YOLOv8模型在Backbone、Neck和Head中都引入了大量C2f模块,该模块可以提供丰富的梯度流,有益于模型精度的提升:
-
-
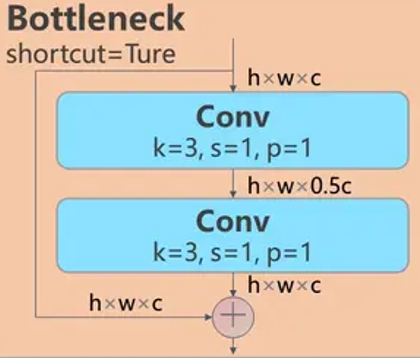
为了提高其中主要的Bottleneck结构计算/访存比,将Bottleneck结构优化为地平线高效实现的可变组卷积结构,参考VarGNet。-
代码改动:
# 添加模块
class SGConv(nn.Module):
"""Sperable Group Conv"""
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, c3=None, factor=1.0, act=True):
super().__init__()
if c3 is None:
c3 = c1
tmp = int(c3 * factor)
# Conv(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
self.dw = Conv(c1, tmp, k, s, p, g, d, act) # DepthWise
self.pw = Conv(tmp, c2, 1, 1, None, 1, 1, True) # PointWise
def forward(self, x):
return self.pw(self.dw(x))
class VarGBlock(nn.Module):
"""Variable Group Conv Block"""
def __init__(self, c1, c2, shortcut=True, group_base=8, k=(3, 3), e=0.5, factor=1.0):
super().__init__()
c_ = int(c2 * e) # hidden channels
g = c1 // group_base
self.cv1 = SGConv(c1, c_, k[0], 1, g=g, factor=factor)
self.cv2 = SGConv(c_, c2, k[1], 1, g=g, factor=factor)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
# 改动模块
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=8, e=0.5, factor=2.0): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
# 改动点,原来的Bottleneck替换为VarGBlock,self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
self.m = nn.ModuleList(VarGBlock(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0, factor=factor) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
代码路径:ultralytics/ultralytics/nn/modules/block.py
3 浮点模型训练
3.1 数据集准备
我们使用MS COCO的全量数据集进行训练,数据集配置文件的路径为ultralytics/ultralytics/cfg/datasets/coco.yaml:
# 数据集存放路径,修改为自定义路径
path: /.../datasets/coco
训练时若指定路径无数据集,程序会自动从MS COCO官网拉取,往往会出现连接出错,因此建议提前在本地下载并准备好:train2017.zip、val2017.zip、test2017.zip和coco2017labels.zip。-
数据集结构如下:
|-- coco
|-- labels
|-- val2017
`-- train2017
|-- images
|-- val2017
|-- train2017
`-- test2017
|-- annotations
`-- instances_val2017.json
|-- val2017.txt
|-- train2017.txt
|-- test-dev2017.txt
|-- README.txt
`-- LICENSE
3.2 环境搭建
执行如下命令安装相关依赖:
pip install -r ultralytics/requirements.txt
每次修改模型文件后,都需执行如下命令重新安装YOLOv8以生效:
pip uninstall ultralytics
python3 ultralytics/setup.py install
3.3 模型训练
浮点模型训练阶段建议复用官方的训练策略和损失函数,只需确保Head还原为公版原代码。执行以下命令训练:
yolo detect train model=yolov8s.yaml data=coco.yaml epochs=500 patience=0 device=0 batch=16
命令行参数说明:ultralytics/ultralytics/cfg/default.yaml
3.4 导出ONNX模型
得到训练好的pt模型后,需要导出ONNX模型来进行后续的PTQ方案模型量化,导出之前需要加入模型Head部分改动。执行如下脚本:
# 导入 YOLOv8
from ultralytics import YOLO
# 载入预训练权重
model = YOLO("best.pt")
# 对 Head 做修改,指定 opset=11,并且导出 ONNX
success = model.export(format="onnx", opset=11, simplify=True)
4 模型量化与评测
4.1 Version1
浮点模型配置:
- YOLOv8s;
- Head、Block(ReLU激活函数+可变组卷积);
- 100 epochs
量化配置(主要参数):
# model_parameters
remove_node_type: "Quantize;Dequantize"
# input_parameters
norm_type: 'data_scale'
scale_value: 0.003921568627451
# calibration_parameters
calibration_type: 'default'
# compiler_parameters
compile_mode: 'latency'
optimize_level: 'O3'
评测数据:
2D检测模型
输入尺寸
浮点精度[IoU=0.50:0.95]
定点精度(精度保持率)[IoU=0.50:0.95]
FPS
YOLOv8s
1x640x640x3
0.365
0.363(99.5%)
38.54
4.2 Version2
浮点模型配置:
- YOLOv8s;
- Head、Block(ReLU激活函数+可变组卷积);
- 500 epochs
**量化配置(主要参数):**和Version1相同-
评测数据:
2D检测模型
输入尺寸
浮点精度[IoU=0.50:0.95]
定点精度(精度保持率)[IoU=0.50:0.95]
FPS
YOLOv8s
1x640x640x3
0.399
0.398(99.7%)
38.38

