0 概述
立体匹配是一个经典的计算机视觉问题,它涉及从两个轻微位移的图像中估计深度,也就是通过计算双目系统的“视差“,基于三角测量原理计算像素的深度值。作为从3D重建到定位和跟踪等任务的核心,双目深度估计的应用涵盖了其它不同的研究领域,包括室内地图和建筑、自动驾驶汽车以及行人和面部跟踪。本文为地平线双目深度估计参考算法StereoNetPlus的介绍和使用说明。
1 性能精度指标
StereoNetPlus模型配置:
DataSet
Input_Shape
Backbone
Head
Post_Process
SceneFlow
2x3x544x960
StereoNetNeck
StereoNetHead
StereoNetPostProcess
性能精度表现:
EPE(float/int)
J5双核FPS
Infer耗时/ms
post process耗时/ms
1.1271/1.1352
249.68
6.602
15.807
EPE(End-Point Error)是以像素为单位的平均视差误差。
2 模型介绍
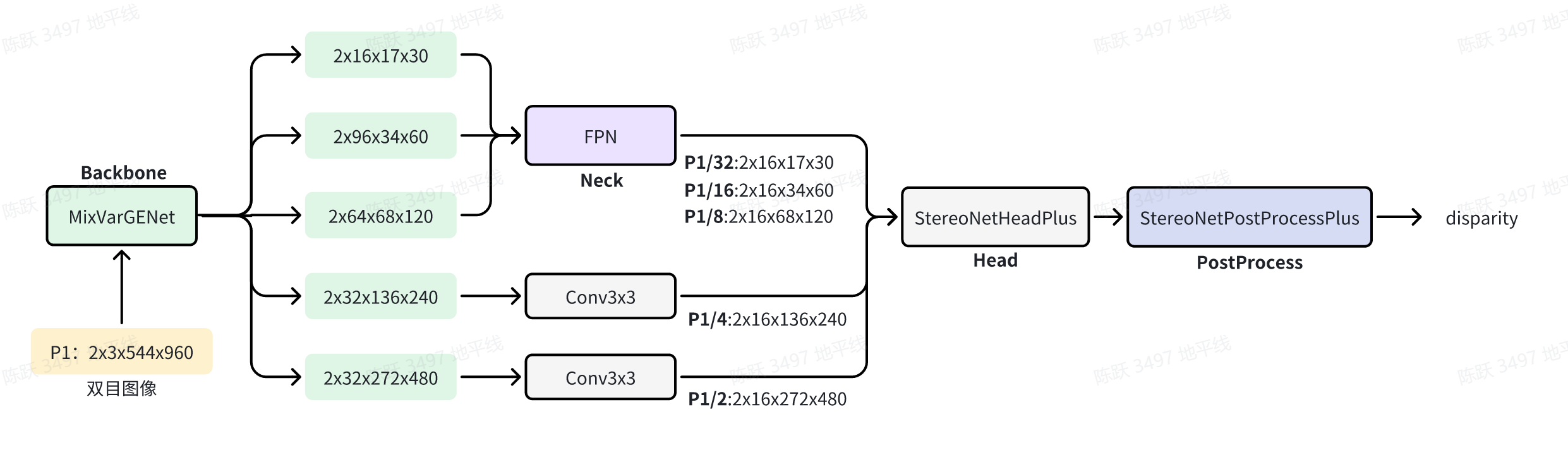
StereoNetPlus是一种双目深度估计的方法:首先,我们使用共享权重的MixVarGENet和FPN来提取双目图像的多尺度特征;然后,通过在相应尺度上关联左右特征来构建多尺度cost volumes; 原始cost volumes由六个堆叠的自适应聚合模块(AAModule)聚合,其中AAModule由3个尺度内聚合(ISA)模块和3个金字塔级别的跨尺度聚合(CSA)模块组成; 最后,对多尺度视差预测进行回归,基于三角测量原理,使用获取的视差值计算像素的深度值。
- Backbone:使用共享权重的MixVarGENet来提取双目图像的多尺度特征;
- Neck:在原图1/8、1/16、/1/32特征级别使用FPN网络,提取每个尺度的特征,然后用以构建cost volume;
- Head:使用内积计算左右特征图的相关性,构建左右图像视差cost volume,然后做Adaptive intra-scale aggregation和Adaptive cross-scale aggregation,最后预测优化视差;另外,将左图像的1/2、1/4和1/8尺度特征融合并做上采样,用于视差细化;
- Post Process:根据head中获取的视差和cost volume计算最终的视差。
2.1 模型优化点
在网络结构上,相比于公版实现,地平线做了如下更改:
- Backbone: 将公版的孪生网络替换为地平线进行针对性优化的MixVarGENet,获得了性能和精度的提升;
- cost volume构建与融合:采用了AANet基于相关性的多尺度cost volume构建方式,并将1/8, 1/16, 1/32原图尺度下(AANet为1/4, 1/8, 1/16尺度)的多层correlation cost volume进行融合,最终使用融合后的1/8视差做refinement,实现了精度和性能的最佳平衡;
- 初略视差到精细视差:采用了CoEx的思路,将左图进行超像素上采样,从而获得原始分辨率的视差图,然后与融合后的cost volume联合预测视差;
- 将后处理中的unfold操作优化为conv进行计算,实现了在BPU上的加速。
2.2 源码说明
2.2.1 Config文件
configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py为 stereonetplus的配置文件,定义了模型结构、数据集加载,和整套训练流程,所需参数的说明在算子定义中会给出。配置文件主要内容包括:
task_name = "stereonet_plus"
data_num_workers = 2
march = March.BAYES
#模型权重路径
ckpt_dir = "./tmp_models/%s" % task_name
#训练阶段每个gpu的batchsize配置
train_batch_size_per_gpu = 8
#测试阶段每个gpu的batchsize配置
test_batch_size_per_gpu = 2
#gpu id配置
device_ids = [0, 1]
...
convert_mode = "fx"
#loss函数权重
loss_weights = [1 / 3, 2 / 3, 1.0]
maxdisp = 192
bias = False
bn_kwargs = {}
refine_levels = 3
base_lr = 0.002
num_epochs = 200
model = dict(
type="StereoNetPlus",
backbone=dict(
type="MixVarGENet",
net_config=[
[
MixVarGENetConfig(
...
)]]
),
neck=dict(
type="FPN",
...
),
head=dict(
type="StereoNetHeadPlus",
...
),
post_process=dict(
type="StereoNetPostProcessPlus",
maxdisp=maxdisp,
),
loss=dict(type="SmoothL1Loss"),
loss_weights=loss_weights,
)
deploy_model = dict(
type="StereoNetPlus",
backbone=dict(
type="MixVarGENet",
...
),
neck=dict(
type="FPN",
...
),
head=dict(
type="StereoNetHeadPlus",
...
),
)
deploy_inputs = dict(
img=torch.randn((2, 3, 544, 960)),
)
#训练数据data_loader
data_loader = dict(
type=torch.utils.data.DataLoader,
dataset=dict(
type="SceneFlow",
#训练数据路径
data_path="./tmp_data/SceneFlow/train_lmdb",
#数据增强
transforms=[
...
],
),
sampler=dict(type=torch.utils.data.DistributedSampler),
batch_size=train_batch_size_per_gpu,
pin_memory=True,
shuffle=False,
num_workers=data_num_workers,
collate_fn=collate_disp_cat,
)
#验证集加载
val_data_loader = dict(
type=torch.utils.data.DataLoader,
dataset=dict(
type="SceneFlow",
data_path="./tmp_data/SceneFlow/test_lmdb",
...
)
...
#不同stage的trainer
float_trainer = dict(...)
calibration_trainer = dict(...)
qat_trainer=dict(...)
int_infer_trainer=dict(...)
#不同阶段的predictor
float_predictor = dict(...)
calibration_predictor = dict(...)
qat_predictor=dict(...)
int_infer_predictor=dict(...)
#编译相关配置
compile_dir = os.path.join(ckpt_dir, "compile")
compile_cfg = dict(
march=march,
name=task_name,
out_dir=compile_dir,
hbm=os.path.join(compile_dir, "model.hbm"),
layer_details=True,
input_source=["pyramid"],
)
#推理及可视化相关配置
infer_transforms = [
dict(
type="Pad",
divisor=32,
...
]
infer_ckpt = int_infer_trainer["model_convert_pipeline"]["converters"][1][
"checkpoint_path"
]
#仿真上板精度验证相关配置
align_bpu_data_loader = dict(
...
)
align_bpu_predictor = dict(
type="Predictor",
model=model,
...
)
#推理及可视化脚本输入的前、后处理代码
def process_inputs(infer_inputs, transforms):
...
return model_input, vis_inputs
#基于几何法,根据模型预测的视差计算深度
def process_outputs(model_outs, viz_func, vis_inputs):
preds = model_outs.squeeze(0).cpu().numpy()
f = float(vis_inputs["f"])
baseline = float(vis_inputs["baseline"])
img = vis_inputs["img"]
depth = baseline * f / preds
preds = viz_func(img, preds, depth)
return None
#推理及可视化脚本的配置
infer_cfg = dict(
model=model,
infer_inputs=dict(
imgl="./tmp_orig_data/SceneFlow/FlyingThings3D/frames_finalpass/TEST/A/0000/left/0006.png",
imgr="./tmp_orig_data/SceneFlow/FlyingThings3D/frames_finalpass/TEST/A/0000/right/0006.png",
baseline="0.54",
f="1050",
),
...
)
#导出onnx相关配置
onnx_cfg = dict(
model=deploy_model,
stage="qat",
...
)
注: 如果需要复现精度,config中的训练策略最好不要修改。否则可能会有意外的训练情况出现。
2.2.2 Backbone
StereoNetPlus参考算法将backbone由公版的共享权重的孪生神经网络替换为了地平线进行针对性优化的MixVarGENet。MixVarGEBlock包括head op, stack op,downsample layers,fusion layers四个基本模块,其中后三个模块都是可选模块。如下为MixVarGEBlock的结构图:
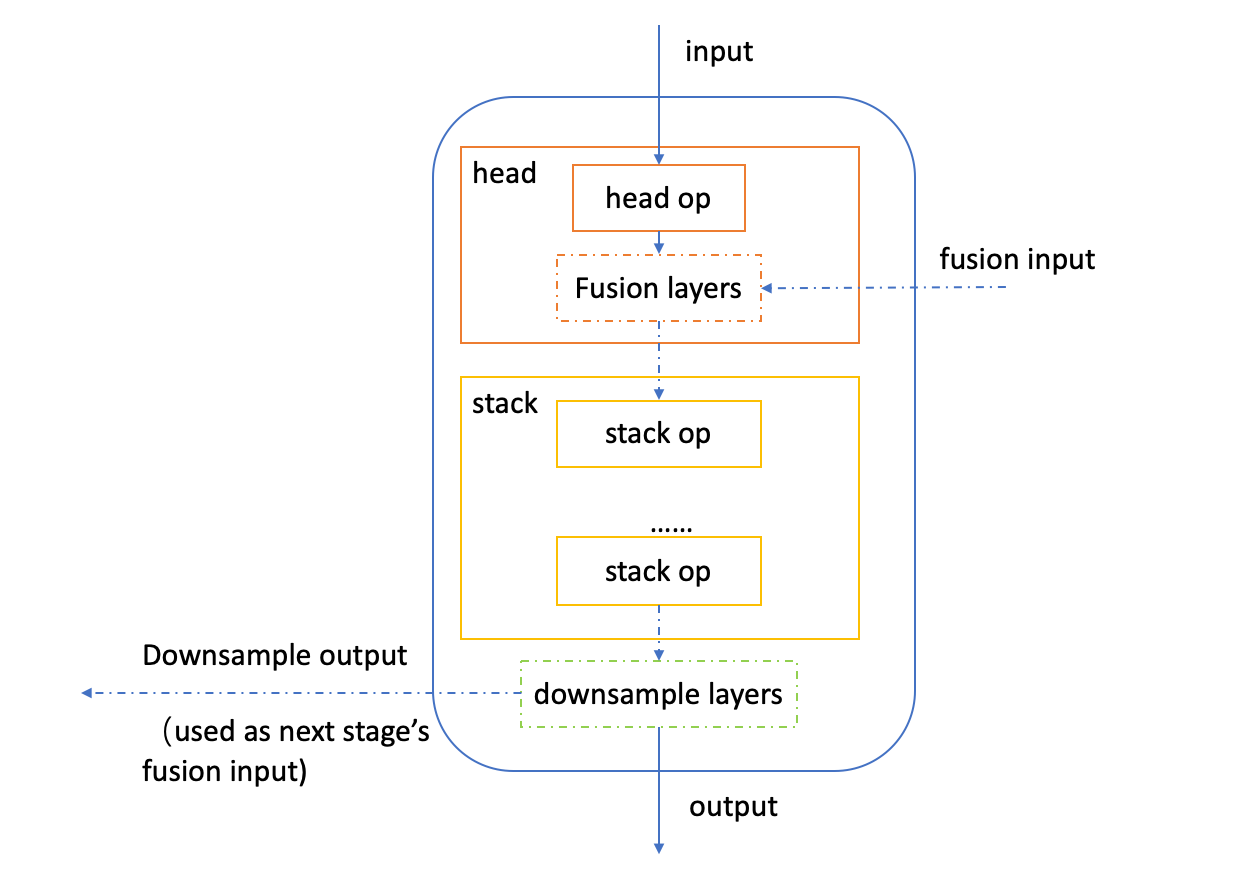
并且,head_op 和stack_op都是由BasicMixVarGEBlock(如mixvarge_f2,mixvarge_f4,mixvarge_f2_gb16)这样的基本单元构成。-
代码路径:/usr/local/lib/python3.8/dist-packages/hat/models/backbones/MixVarGENet.py-
介绍文档:【参考算法】地平线 MixVarGENet参考算法-
2.2.3 Neck
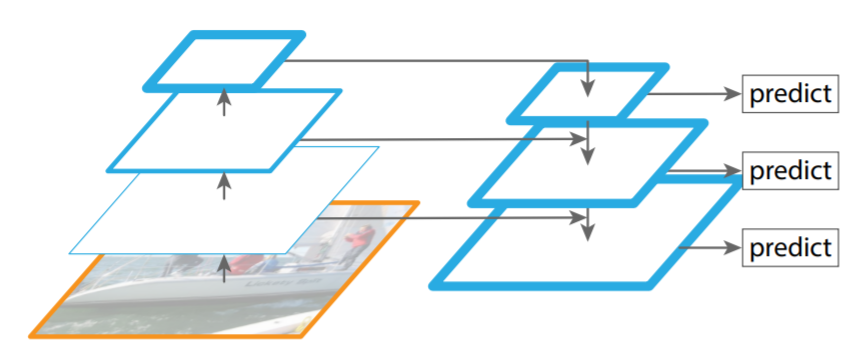
StereoNetPlus的Neck网络采用特征金字塔网络FPN(Feature Pyramid Networks),它采用自顶向下的层次结构来提取多尺度的高层语义特征。FPN网络结构如图所示:
代码路径:/usr/local/lib/python3.8/dist-packages/hat/models/necks/fpn.py
2.2.4 Head
提取双目图像的多尺度特征之后,借鉴AANet的思想,在1/8、1/16、1/32原图尺度下基于相关性构建多尺度cost volume;然后进行cost volume的自适应尺度内聚合(Adaptive intra-scale aggregation)和自适应跨尺度聚合(Adaptive cross-scale aggregation),并且使用融合后的1/8视差做refinement;最后将多尺度特征上采样至原图分辨率进行视差的预测。
2.2.4.1 cost volume构建
cost volume用于在双目匹配中衡量左右图像像素匹配的程度,StereoNetPlus通过计算左右视图的相关性来构建cost volume,计算公式如下:

- FlsF_l^sFls和FrsF_r^sFrs:双目图像的多尺度左、右特征;
- Cs(d,h,w)C^s(d,h,w)Cs(d,h,w):视差候选d在像素位置(h,w)处的匹配代价;
- NNN:图像特征通道数;
相关代码如下:
def build_aanet_volume(self, refimg_fea, maxdisp, offset, idx):
B, C, H, W = refimg_fea.shape
num_sample = B // 2
tmp_volume = []
#maxdisp:最大预测视差
for i in range(maxdisp):
if i > 0:
#计算左右视图特征的相关性
cost = self.gc_mul[i + offset].mul(
refimg_fea[:num_sample, :, :, i:],
refimg_fea[num_sample:, :, :, :-i],
)
#取均值
tmp = self.gc_mean[i + offset].mean(cost, dim=1)
#padding
tmp_volume.append(self.gc_pad[i + offset](tmp))
else:
#计算左右视图特征的相关性
cost = self.gc_mul[i + offset].mul(
refimg_fea[:num_sample, :, :, :],
refimg_fea[num_sample:, :, :, :],
)
#取均值
tmp = self.gc_mean[i + offset].mean(cost, dim=1)
tmp_volume.append(tmp)
volume = (
self.gc_cat_final[idx]
.cat(tmp_volume, dim=1)
.view(num_sample, maxdisp, H, W)
)
return volume
在计算cost volume之前,判断i是否为正数。i为正时需要对cost_volume做padding。-
代码路径:usr/local/lib/python3.8/dist-packages/hat/models/task_modules/headplus.py
2.2.4.2 Adaptive Aggregation
构建cost volume后,然后用几个堆叠的自适应聚合模块来聚合原始cost volume,其中自适应聚合模块由3个自适应尺度内聚合(Intra-Scale Aggregation , ISA)模块和用于3个金字塔级别的自适应跨尺度聚合(Cross-Scale Aggregation ,CSA)模块组成。ISA和CSA的示意图如下所示:

ISA-
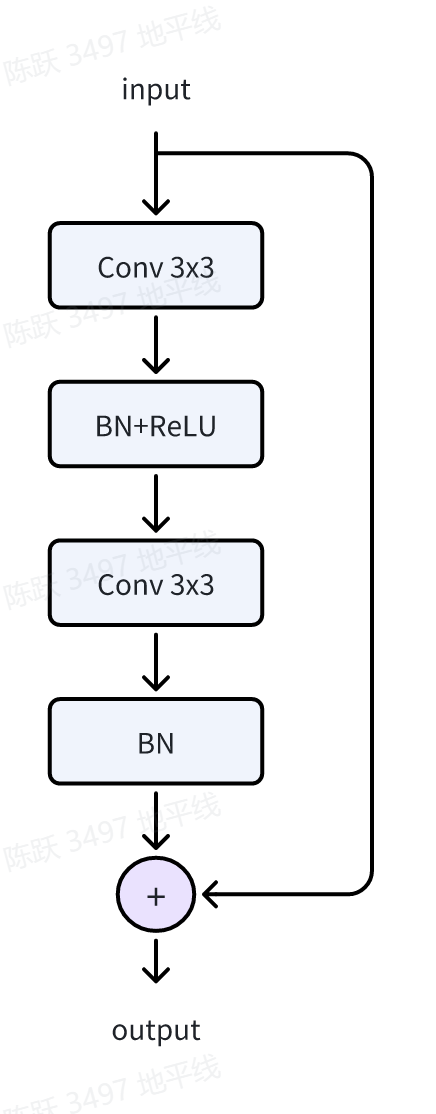
在视差非连续时,边缘位置总会有一圈连续的错误匹配值,为了缓解这种edge-fattening问题,使用3个残差模块 BasicResBlock对每个尺度的cost volume进行聚合,BasicResBlock的结构图如下所示:
相关代码:
# Adaptive intra-scale aggregation
#num_scales:The num of cost volume:3
#max_disp: The max value of disparity
for i in range(self.num_scales):
#max_disp:24
num_candidates = max_disp // (2 ** i)
branch = nn.ModuleList()
for _ in range(num_blocks):
# if simple_bottleneck:
branch.append(
BasicResBlock(num_candidates, num_candidates, bn_kwargs={})
)
self.branches.append(nn.Sequential(*branch))
self.fuse_layers = nn.ModuleList()
CSA-
双目图像进行下采样后,在相同的patch尺寸下,纹理信息将更具鉴别性,所以跨尺度成本聚合算法中引入了多尺度交互。最终的cost volume是通过对不同尺度的成本聚合结果进行自适应组合得到的,公式如下:

- C^s\hat{C}^sC^s: 是跨尺度cost聚合后的最终cost volume;
- C~k\tilde{C}^kC~k: 尺度为k的cost volume的尺度内聚合;
- fkf_kfk:用于实现每个尺度的cost volume的自适应组合的函数;-
fkf_kfk取决于cost volume C~k\tilde{C}^kC~k和C^s\hat{C}^sC^s的分辨率,对于cost volume C^s\hat{C}^sC^s:
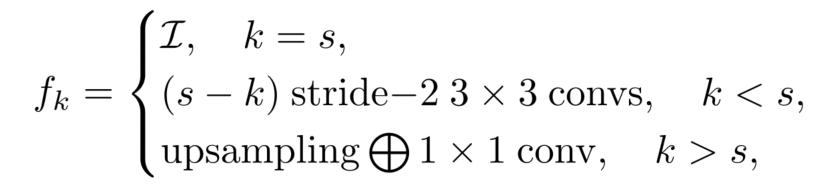
下面将对公式中的3种情况进行说明:
- I\mathcal{I}I:identity函数;
- (s−k)stride−2 3×3convs(s-k)stride-2 3\times3 convs(s−k)stride−2 3×3convs:为了保证不同尺度的cost volume分辨率一致,使用(s-k)个stride为2 的conv3x3做下采样;
- upsampling ⨁ 1x1 convupsampling \bigoplus 1\mathrm{x}1 convupsampling ⨁ 1x1 conv:采用双线性上采样将cost volume到相同的分辨率,然后采用1x1卷积对齐通道数;
相关代码如下:
class AdaptiveAggregationModule(nn.Module):
"""
Adaptive aggregation module for optimizing disparity.
Args:
num_scales: The num of cost volume.
num_output_branches: The num branch for outputs.
max_disp: The max value of disparity.
num_blocks: The num of block.
"""
def __init__(
self,
num_scales: int,
num_output_branches: int,
max_disp: int,
num_blocks: int = 1,
):
super(AdaptiveAggregationModule, self).__init__()
...
# Adaptive intra-scale aggregation
for i in range(self.num_scales):
num_candidates = max_disp // (2 ** i)
branch = nn.ModuleList()
for _ in range(num_blocks):
# if simple_bottleneck:
branch.append(
BasicResBlock(num_candidates, num_candidates, bn_kwargs={})
)
self.branches.append(nn.Sequential(*branch))
self.fuse_layers = nn.ModuleList()
# Adaptive cross-scale aggregation
# For each output branch
for i in range(self.num_output_branches):
self.fuse_layers.append(nn.ModuleList())
# For each branch (different scale)
for j in range(self.num_scales):
if i == j:
# Identity函数
self.fuse_layers[-1].append(nn.Identity())
elif i < j:
#使用stride为2的conv3x3下采样
self.fuse_layers[-1].append(
nn.Sequential(
ConvModule2d(
in_channels=max_disp // (2 ** j),
out_channels=max_disp // (2 ** i),
kernel_size=1,
stride=1,
padding=0,
bias=False,
norm_layer=nn.BatchNorm2d(
max_disp // (2 ** i)
),
act_layer=None,
)
),
)
elif i > j:
#使用conv1x1进行通道维度对齐
layers = nn.ModuleList()
for _ in range(i - j - 1):
layers.append(
nn.Sequential(
ConvModule2d(
in_channels=max_disp // (2 ** j),
out_channels=max_disp // (2 ** j),
kernel_size=3,
stride=2,
padding=1,
bias=False,
norm_layer=nn.BatchNorm2d(
max_disp // (2 ** j)
),
act_layer=nn.ReLU(inplace=True),
)
)
)
layers.append(
nn.Sequential(
ConvModule2d(
in_channels=max_disp // (2 ** j),
out_channels=max_disp // (2 ** i),
kernel_size=3,
stride=2,
padding=1,
bias=False,
norm_layer=nn.BatchNorm2d(
max_disp // (2 ** i)
),
act_layer=None,
)
)
)
self.fuse_layers[-1].append(nn.Sequential(*layers))
self.relu = nn.LeakyReLU(0.2, inplace=True)
self.fuse_add = nn.ModuleList()
for _ in range(len(self.fuse_layers) * len(self.branches)):
self.fuse_add.append(hpp.nn.quantized.FloatFunctional())
...
@fx_wrap()
#双线性插值函数
def interpolate_exchange(self, x_fused, exchange, i, idx):
if exchange.size()[2:] != x_fused[i].size()[2:]:
exchange = F.interpolate(
exchange,
size=x_fused[i].size()[2:],
mode="bilinear",
align_corners=False,
)
return self.fuse_add[idx].add(exchange, x_fused[i])
ISA和CSA的forward函数为:
def forward(self, x):
assert len(self.branches) == len(x)
#ISA尺度内聚合
for i in range(len(self.branches)):
branch = self.branches[i]
for j in range(self.num_blocks):
dconv = branch[j]
x[i] = dconv(x[i])
x_fused = []
idx = 0
#CSA跨尺度聚合
for i in range(len(self.fuse_layers)):
for j in range(len(self.branches)):
if j == 0:
x_fused.append(self.fuse_layers[i][0](x[0]))
else:
exchange = self.fuse_layers[i][j](x[j])
#双线性插值实现上采样
x_fused[i] = self.interpolate_exchange(
x_fused, exchange, i, idx
)
idx = self.update_idx(idx)
for i in range(len(x_fused)):
x_fused[i] = self.relu(x_fused[i])
return x_fused
代码路径:-
/usr/local/lib/dist-packages/hat/models/task_modules/stereonet/headplus.py
预测视差-
获取到多尺度融合的Cost volume后,首先使用softmax函数将其转化为视差的分布;然后使用Conv代替Unfold操作进行张量的切分,这样就获得了视差预测,相关操作如下所示:
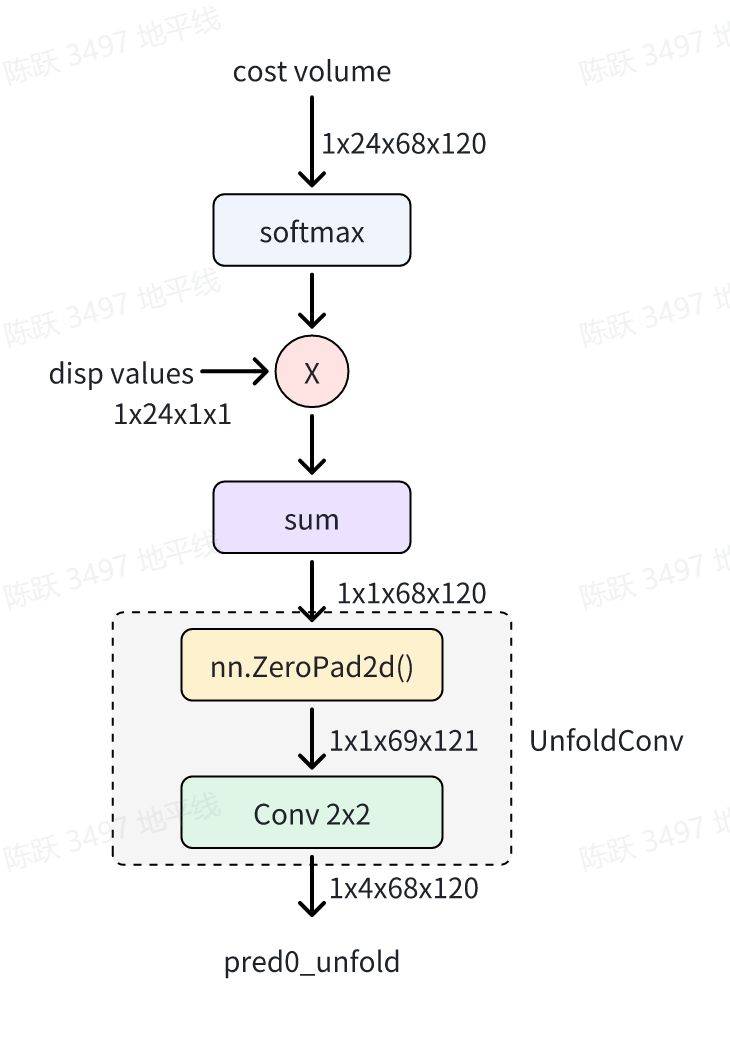
> 上图中nn.ZeroPad2d()函数的作用是为了保证Conv2x2计算后的shape为68x120,即1/8原图尺度。
相关代码:
def forward(
self, features_inputs: List[List[torch.Tensor]]
) -> List[torch.Tensor]:
...
for i in range(len(self.fusions)):
fusion = self.fusions[i]
aanet_volumes = fusion(aanet_volumes)
#1x1卷积
cost0 = self.final_conv(aanet_volumes[0])
#使用softmax将cost volume转化为概率分布
pred0 = self.softmax(cost0)
pred0 = self.dis_mul(pred0)
#通道维度相加
pred0 = self.dis_sum(pred0)
#使用卷积代替unfold操作
pred0_unfold = self.unfold(pred0)
...
return (
self.dequant(pred0),
self.dequant(pred0_unfold),
self.dequant(spx_pred),
)
使用Conv代替Unfold操作的代码为:
class UnfoldConv(nn.Module):
"""
A unfold module using conv.
Args:
in_channels: The channels of inputs.
kernel_size: The kernel_size of unfold.
"""
def __init__(self, in_channels: int = 1, kernel_size: int = 2):
super(UnfoldConv, self).__init__()
self.kernel_size = kernel_size
self.conv = nn.Conv2d(
in_channels=in_channels,
out_channels=self.kernel_size ** 2,
kernel_size=self.kernel_size,
stride=1,
bias=False,
)
self.pad = nn.ZeroPad2d(padding=(1, 0, 1, 0))
self.init_weights()
def init_weights(self):
...
def forward(self, x):
#填充特征图
x = self.pad(x)
#conv代替unfold操作
x = self.conv(x)
return x
代码路径:-
/usr/local/lib/dist-packages/hat/models/task_modules/stereonet/headplus.py
2.2.4.3 超像素上采样
在上采样分辨率中的每个像素处的最终视差估计是通过其周围的“超像素”的加权平均值获得的。StereoNetPlus参考算法借鉴了CoEx的做法,将1/2、1/4、1/8分辨率下的左图特征进行上采样获得原始图像分辨率的视差图。-
如下为超像素上采样的网络结构示意图,首先使用DeconvResModule融合金字塔特征P1/2、P1/4、P1/8的左边特征,DeconvResModule的结构图如右侧所示,它首先使用Convtranspose将小尺寸特征图input1上采样至input2大小,然后将二者的特征进行相加、Conv等操作;最后使用ConvTranspose将融合的特征图上采样至原图大小544x960。如下为流程图:

代码路径:-
/usr/local/lib/dist-packages/hat/models/task_modules/stereonet/headplus.py
2.2.5 Post Process
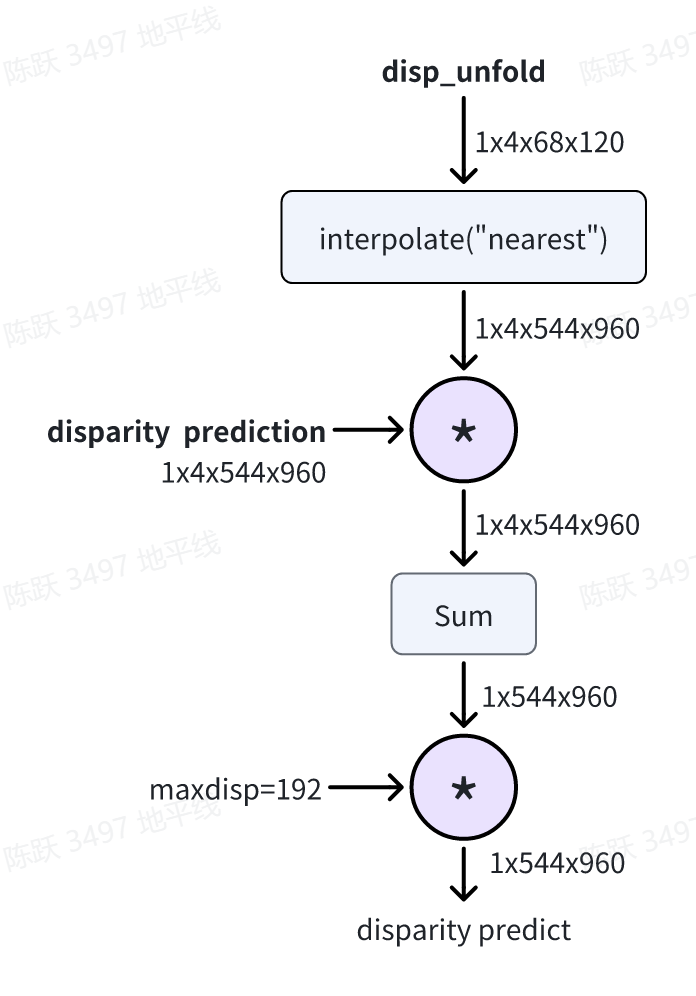
获取到原图尺寸视差估计后,基于cost volume中的视差分布信息获取最终的视差预测。首先,使用最近邻插值将1/8原图分辨率下的cost volume上采样至原图分辨率下(544x960);然后将其与上采样后的超像素对应点相乘并求和,这样就获得了每个像素处的最终视差估计;最后,乘以最大视差192就获得最终的视差,相关流程如下图所示:
相关代码:
class StereoNetPostProcessPlus(nn.Module):
def __init__(self, maxdisp: int = 192, low_max_stride: int = 8):
...
def forward(self, modelouts, gt_disps=None):
if len(modelouts) == 3:
disp_low = modelouts[0]
else:
disp_low = None
#
disp_low_unfold = modelouts[-2]
#spg:精细视差
spg = modelouts[-1]
#对unfold后的视差分布概率最近邻插值至原图大小
disp_1 = F.interpolate(
disp_low_unfold, scale_factor=self.low_max_stride, mode="nearest"
)
#计算每个像素下的视差期望
disp_1 = (spg * disp_1).sum(1)
#将视差scale至原图视察分布尺度
#1x544x960
disp_1 = disp_1.squeeze(1) * self.maxdisp
if self.training:
...
else:
return disp_1.squeeze(1)
代码路径:-
/usr/local/lib/dist-packages/hat/models/task_modules/stereonet/post_process.py
3 浮点模型训练
3.1 Before Start
3.1.1 环境部署
Stereonetplus示例位于OE包中的ddk/samples/ai_toolchain/horizon_model_train_sample下,其结构为:
└── horizon_model_train_sample
├── scripts
├── configs #配置文件
`── tools #工具及运行脚本
拉取docker环境
docker pull openexplorer/ai_toolchain_ubuntu_20_j5_gpu: {version}
#启动容器,具体参数可根据实际需求配置
#-v 用于将本地的路径挂载到 docker 路径下
nvidia-docker run -it --shm-size="15g" -v `pwd`:/open_explorer openexplorer/ai_toolchain_ubuntu_20_j5_gpu: {version}
权重获取路径见:horizon_model_train_sample/scripts/configs/disparity_pred/stereonet/README.md
3.1.2 数据集下载
在开始训练模型之前,需要准备好数据集。首先下载 SceneFlow 数据集 , 然后在此处下载训练数据和验证数据集对应的文件列表 SceneFlow_finalpass_train.txt 和 SceneFlow_finalpass_test.txt 。-
下载后,解压并按照如下方式组织文件夹结构:
|-- SceneFlow
|-- Driving
|-- disparity
|-- frames_finalpass
|-- FlyingThings3D
|-- disparity
|-- frames_finalpass
|-- Monkaa
|-- disparity
|-- frames_finalpass
|-- SceneFlow_finalpass_test.txt
|-- SceneFlow_finalpass_train.txt
3.1.3 数据集打包
为了提升训练的速度,需要对数据信息文件进行打包,将其转换成lmdb格式的数据集。只需要运行下面的脚本,就可以成功实现格式转换:
#打包训练集
python3 tools/datasets/sceneflow_packer.py --src-data-dir ${src-data-dir} --split-name train --pack-type lmdb --num-workers 10 --target-data-dir ${target-data-dir}
#打包测试集
python3 tools/datasets/sceneflow_packer.py --src-data-dir ${src-data-dir} --split-name test --pack-type lmdb --num-workers 10 --target-data-dir ${target-data-dir}
src-data-dir为解压后的SceneFlow数据集目录,即解压后的数据集目录SceneFlow;-
target-data-dir为打包后数据集的存储目录;-
num-worker为执行线程数
数据集打包命令执行完毕后会在target-data-dir下生成train_lmdb和test_lmdb:
└── target-data-dir
|-- train_lmdb
|-- test_lmdb
3.1.4 config配置
在进行模型训练和验证之前,需要对configs文件中的部分参数进行配置,一般情况下,我们需要配置以下参数:
- device_ids、batch_size_per_gpu:根据实际硬件配置进行device_ids和每个gpu的batchsize的配置;
- ckpt_dir:float、calibration、qat的权重路径配置,权重下载链接在config文件夹下的README中;
- data_loader中的data_path:2.1.3节打包的train_lmdb数据集路径;
- val_data_loader中的data_path:2.1.3节打包的test_lmdb数据集路径;
- infer_cfg:指定模型输入,在infer.py脚本使用时需配置;
3.2 浮点模型训练
在configs/disparity_pred/stereonet/stereonetplus.py下配置参数,需要将相关硬件配置device_ids和权重路径ckpt_dir数据集路径data_rootdir配置修改后使用以下命令训练浮点模型:
python3 tools/train.py --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py --stage float
3.3 浮点模型精度验证
通过指定训好的float_checkpoint_path,使用以下命令验证已经训练好的模型精度:
python3 tools/predict.py --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py --stage float
4. 模型量化和编译
模型上板前需要将模型编译为.hbm文件, 可以使用compile的工具用来将量化模型编译成可以上板运行的hbm文件,因此首先需要将浮点模型量化,地平线对StereoNetPlus模型的量化采用horizon_plugin框架,通过Calibration+QAT量化训练和转换最终获得定点模型。
4.1 Calibration
为加速QAT训练收敛和获得最优量化精度,建议在QAT之前做calibration,其过程为通过batchsize个样本初始化量化参数,为QAT的量化训练提供一个更好的初始化参数,和浮点训练的方式一样,将checkpoint_path指定为训好的浮点权重路径。-
通过运行下面的脚本就可以开启模型的Calibration:
python3 tools/train.py --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py --stage calibration
4.2 Calibration 模型精度验证
calibration完成以后,可以使用以下命令验证经过calib后模型的精度:
python3 tools/predict.py --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py --stage calibration
验证完成后,会在终端输出calib模型在验证集上的EPE精度。
4.3 量化模型训练
Calibration完成后,就可以加载calib权重开启模型的量化训练。 量化训练其实是在浮点训练基础上的finetue,具体配置信息在config的qat_trainer中定义。量化训练的时候,初始学习率设置为浮点训练的十分之一,训练的epoch次数也大大减少。和浮点训练的方式一样,将checkpoint_path指定为训好的calibration权重路径。-
通过运行下面的脚本就可以开启模型的qat训练:
python3 tools/train.py --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py --stage qat
4.4 qat模型精度验证
量化训练完成后,通过运行以下命令验证qat模型的精度:
python3 tools/predict.py --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py --stage qat
4.5 量化模型精度验证
通过运行以下命令验证量化模型的精度:
python3 tools/predict.py --stage qat --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py --stage int_infer
4.6 仿真上板精度验证
除了上述模型验证之外,我们还提供和上板完全一致的精度验证方法,可以通过下面的方式完成:
python3 tools/align_bpu_validation.py --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py
4.6 量化模型编译
在训练完成之后,可以使用compile_perf工具用来将量化模型编译成可以上板运行的hbm文件,同时该工具也能预估在BPU上的运行性能,可以采用以下脚本:
python3 tools/compile_perf.py --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py --out-dir ./ --opt 3
opt为优化等级,取值范围为0~3,数字越大优化等级越高,运行时间越长。
运行后,out-dir的目录下会产出以下文件:
|-- compile
| |-- xxx.html #模型在bpu上的静态性能数据
| |-- xxx.json
| |-- model.hbm #板端部署的模型1
| |-- model.hbir #编译过程的中间文件
`-- model.pt #模型的pt文件
5. 其他工具
5.1 结果可视化
如果您希望查看定点模型通过双目图像估计视差和深度的效果,tools文件夹下面提供了预测及可视化的脚本infer.py,参考命令如下:
python3 tools/infer.py --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py --save-path ./res
参数说明:
- 输入图像的路径通过config文件中infer_cfg字段中的infer_inputs配置;
- --save-path:可视化结果保存路径。
可视化结果:

- 可视化结果从左至右为:left左图、right右图、disparity视差图、根据视差计算的depth深度图;
- 视差图中的颜色代表:颜色越红,视差值越小;颜色越蓝,视差值越大;
- 深度图中的颜色代表:颜色越红,对应的像素深度值则越小;颜色越蓝,对应的像素深度值则越大;
- 视差图到深度图的计算原理可参考【双目深度估计】—原理理解中的几何法,相应代码可以参考config文件中的process_outputs函数。
5.2 导出onnx
如果需要导出onnx模型,tools文件夹下面提供了onnx导出脚本export_onnx.py,参考命令如下:
python3 tools/export_onnx.py --config configs/disparity_pred/stereonet/stereonetplus_mixvargenet_sceneflow.py
导出的onnx模型为量化训练后的伪量化模型,保存在模型权重路径ckpt_dir目录下。
6 板端部署
本节将介绍hbm模型编译完成后,在板端使用dnn工具进行性能评测和运行AI-Benchmark示例进行性能和精度评测的流程。
6.1 上板性能实测
模型编译成功后,可以在板端使用hrt_model_exec perf工具评测hbm模型的FPS,参考命令如下:
hrt_model_exec perf --model_file {model}.hbm \
--thread_num 8 \
--frame_count 1000 \
--core_id 0 \
--profile_path '.'
命令运行结束后,会在本地会产出profile.log和profile.csv日志文件,用以分析算子耗时和调度耗时。
6.2 AI Benchmark示例
OE开发包中提供了StereoNetPlus的AI Benchmark示例,用以在板端进行性能和精度的评测,ddk/samples/ai_benchmark/j5/qat/script/disparity_pred/stereonet_plus 目录下提供了三个评测脚本:
-
fps.sh:实现多线程fps统计(多线程调度,用户可以根据需求自由设置线程数);
-
latency.sh:实现单帧延迟性能统计,包含模型推理和后处理延迟(单线程,单帧);
-
accuracy.sh:用于精度评测。-
AI Benchmark示例需要使用交叉编译工具编译后,然后将文件夹传输到板端运行,建议在docker中进行交叉编译流程。执行ddk/samples/ai_benchmark/code/ 目录下的build_qat_j5.sh脚本即可一键编译真机环境下的可执行程序:sh build_qat_j5.sh
编译完成后,将ai_benchmark/j5/qat文件夹拷贝至板端:
scp -r ddk/samples/ai_benchmark/j5/qat root@{board_ip}:/userdata/
然后在板端执行qat/script/disparity_pred/stereonet_plus文件夹下的评测脚本。进入到需要评测的模型目录下,运行latency.sh 即可测试出单帧延迟, 如下所示:
sh latency.sh
终端输出的延迟包含模型推理耗时(Infer latency)和后处理耗时(Post process)。
运行fps.sh 即可测试出双核多线程fps, 如下所示:
sh fps.sh
如果要进行精度评测,请参考开发者社区J5算法工具链产品手册进行数据的准备和模型的推理。