1.概述
语义分割是视觉场景理解的一项基本任务,目的是将输入图像中的每个像素分配给特定的类别标签。随着人工智能应用需求的不断增长,语义分割已经成为自动驾驶、医学成像诊断和遥感图像等应用的基本感知组件。最近,学术界提出了许多基于双分支网络(Two-Branch Network,TBN)的新颖且有前景的模型,并实现了速度和精度之间的SOTA均衡。但是,双分支网络直接融合了高分辨率空间细节和低频上下文信息,导致细节特征被周围的上下文信息淹没,限制了现有双分支模型的分割准确性的提高。PIDNet将CNN和自动控制领域的PID控制器(Proportional-Integral-Derivative,PID)联系起来,提出了基于注意力机制引导的实时语义分割网络架构,解决当前双分支网络细节特征被上下文信息淹没的不足。
最终,PIDNet的精度超过了所有具有相似推理速度的现有模型,在Cityscapes和CamVid两个主流的道路场景解析数据集上实现了最佳的推理速度和准确度的平衡。其中:
- 基于RTX 3090,PIDNet-S在Cityscapes数据集上的推理速度为 93.2 FPS(输入大小为1024x2048),mIOU 为0. 786;
- 基于RTX 3090,CamVid数据集上的推理速度为 153.7 FPS(输入大小为720x960),同时 mIOU 为 0.801。

鉴于PIDNet模型精度和性能的优异表现,本文将介绍PIDNet_S网络在地平线征程5计算平台(J5)的部署流程。
2.性能精度指标

deeplabv3plus_efficientnetm2参考算法数据来源:地平线参考算法版本发布帖
3.环境准备
3.1 代码库下载与解压
从https://github.com/XuJiacong/PIDNet下载官方代码库,然后解压,解压后的目录如下所示:
#PIDNet-main
├─configs #config文件
│ ├─camvid
│ ├─cityscapes
│ └─__pycache__
├─data #数据集
│ ├─camvid
│ │ ├─images
│ │ └─labels
│ ├─cityscapes
│ └─list
│ ├─camvid
│ └─cityscapes
├─datasets
├─figs
├─models #模型源码
│ ├─others
│ ├─speed
│ ├─__init__.py
│ ├─model_util.py
│ └─pidnet.py
├─pretrained_models #预训练模型
│ ├─camvid
│ ├─cityscapes
│ └─imagenet
├─samples #图像示例
├─tools
│ ├─_init_paths.py
│ ├─custom.py
│ ├─eval.py #评估脚本
│ ├─train.py #浮点训练脚本
│ └─__pycache__
└─README.md
└─utils
权重下载链接在README.md中
3.2 数据集准备
本文将基于Cityscapes 数据集进行开发。
-
下载 Cityscapes 数据集之前需要在 官方网站 注册一个账号:-
-
然后在 下载页面 下载需要的数据集文件, 这里我们只需要下载 gtFine_trainvaltest.zip 和 leftImg8bit_trainvaltest.zip 两个文件。
-
将 gtFine_trainvaltest.zip 和 leftImg8bit_trainvaltest.zip 解压至PIDNet-main/data/cityscapes文件夹下,目录结构如下所示:
├── data
│ ├── camvid
│ │ ├── images
│ │ ├── labels
│ │ └── readme.txt
│ ├── cityscapes
│ │ ├── gtFine
│ │ ├── leftImg8bit
│ │ └── readme.txt
│ └── list
│ ├── camvid
│ └── cityscapes
3.3 环境部署
本文将基于地平线算法工具链的OE1.1.68的Docker进行开发。
- 访问地平线开发者社区中的OpenExplorer算法工具链 版本发布帖,下载OE1.1.68的GPU Docker:
- 参考用户手册完成Docker环境的部署:
-
此外,还需要在OE1.1.68的Docker中安装以下两个库:
pip3 install tensorboardX
pip3 install yacs
4. PIDNet网络结构
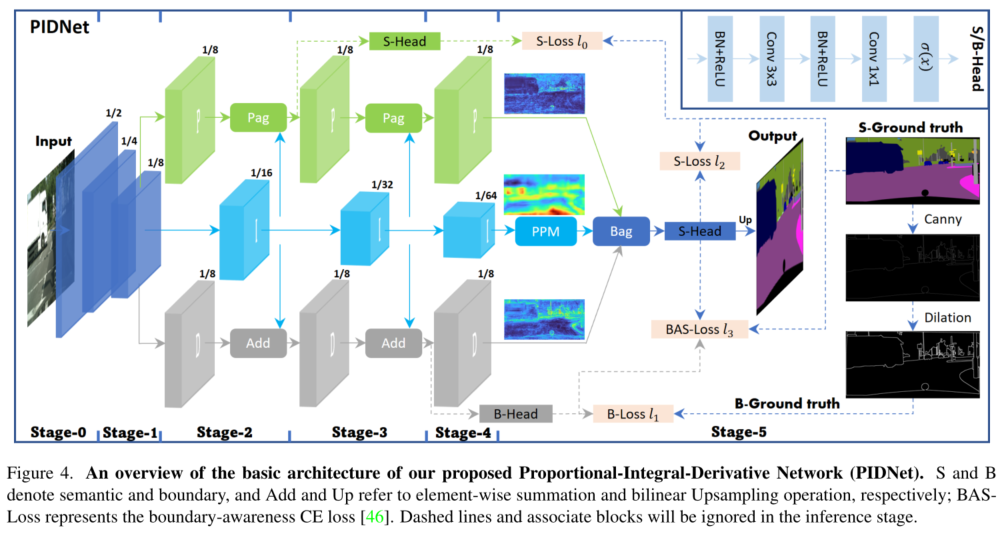
PIDNet 网络主要由P、I、D分支、Pag、PAPPM和Bag模块组成,下面将分别对其进行介绍。
4.1 P、I、D分支
P、I、D分支具有互补的职责:
- 比例分支P负责解析和保留高分辨率特征图中的详细信息;
- 积分分支I负责聚合局部和全局的上下文信息以捕获远距离依赖;
- 微分分支D负责提取高频特征以预测边界区域。-
PIDNet采用了级联残差块作为Backbone。此外,为了更加高效,作者将 P、I 和 D 分支的深度设置为较浅、适中和较深。因此可以通过加深和加宽模型来生成不同大小的 PIDNet 模型,即PIDNet-S、PIDNet-M和PIDNet-L。-
代码路径:PIDNet-main/models/pidnet.py
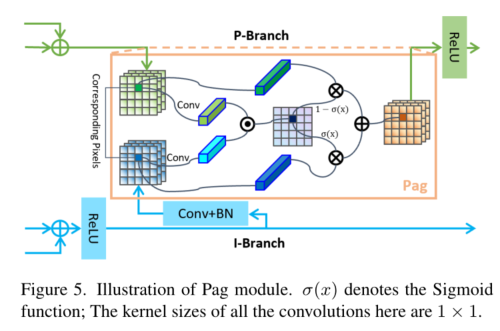
4.2 Pag:选择性学习高级语义信息
在PIDNet中,I分支的网络深度相对于P和D分支较深,其提供的丰富而准确的语义信息对于P和D分支的细节解析和边界检测至关重要。PIDNet将I分支视为其它两个分支的备份,并使其能够向它们提供所需要的信息。为了P分支能更好地融合I分支的语义信息,引入了Pag模块。-
作用:-
Pixel-attention-guided fusion, Pag, 即像素注意力引导模块,就是将比例P和积分I分支的特征利用一个注意力机制进行交互增强。-
结构:-
模型结构如下图所示:
代码路径:PIDNet-main/models/model_utils.py
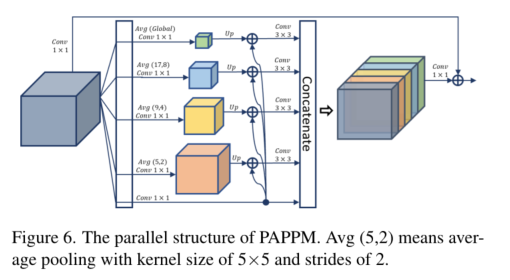
4.3 PAPPM:上下文的快速聚合
Pyramid Pooling Module, PPM,主要用于构建全局场景的先验信息。PPM首先对不同尺度的特征图进行池化操作,然后将不同尺度的池化特征图进行拼接,形成局部和全局上下文的表示。虽然PPM能够很好地嵌入上下文信息,但它的计算过程无法并行化,非常耗费计算时间,而且对于轻量级模型来说,PPM 包含的每个尺度的通道数太多,可能会超过这些模型的表示能力。-
作用:-
Parallel Aggregation PPM, PAPPM,即并行聚合PPM,基于DAPPM中修改了其中的连接,使其可以并行化,并且将每个尺度的通道数量从128减少至96,提升了计算速度。-
结构:
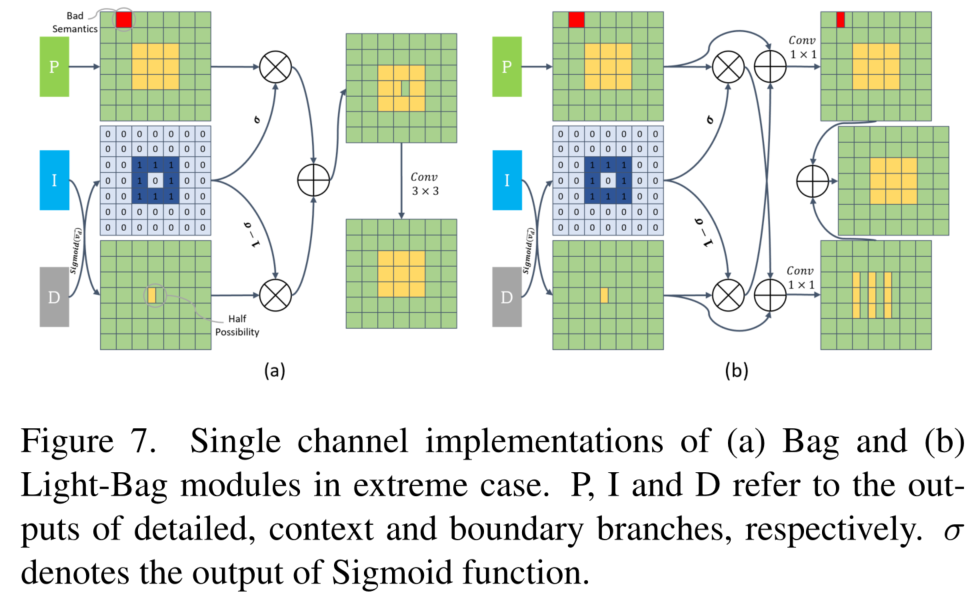
4.4 Bag :平衡细节特征和上下文
给定ADB提取的边界特征,使用边界注意力来指导细节(P)和上下文(I)表示的融合,即设计了一个边界注意力引导的融合模块(Boundary-attention-guided,Bag)。-
作用:-
上下文分支I在语义上是准确的,但它丢失了太多的空间和几何细节,尤其是对于边界区域和小目标。细节特征分支P更好地保留了空间细节,所以迫使模型沿着边界区域更多地信任细节分支P,并利用上下文特征来填充其他区域。-
结构:
5. 浮点训练
从PIDNet的官方代码库提供的链接下载ImageNet预训练模型PIDNet_S_Cityscapes_val.pt,并将其放入PIDNet-main/pretrained_models/imagenet目录下。然后在Cityscapes上训练PIDNet-S,在2个GPU上训练batchsize为12的PIDNet-S,参考命令如下:
python tools/train.py --cfg configs/cityscapes/pidnet_small_cityscapes.yaml GPUS (0,1) TRAIN.BATCH_SIZE_PER_GPU 6
本文没有重新进行浮点训练流程,直接使用了官方代码库链接中提供的PIDNet的pt。
6. 浮点模型精度验证
浮点模型训练完成以后,通过指定训练好的TEST.MODEL_FILE 来评估模型在验证集/测试集上的精度。在官方代码库提供的链接中下载PIDNet_S在CityScapes验证集下的权重PIDNet_S_Cityscapes_val.pt,将其放在PIDNet-main/pretrained_models/cityscapes目录下。-
然后运行以下命令:
python tools/eval.py --cfg configs/cityscapes/pidnet_small_cityscapes.yaml TEST.MODEL_FILE pretrained_models/cityscapes/PIDNet_S_Cityscapes_val.pt
命令运行结束后,在终端会打印PIDNet_S在CityScapes验证集下的精度,如下所示:

7. Calibration
浮点模型训练完成且已经满足精度要求后,那么我们就可以开始模型的量化编译流程了。-
为了精度更加有保障,我选择了地平线算法工具链的QAT链路来实现模型的量化编译。地平线开发者社区中的关于QAT的资料还是不少的,我这里参考了QAT快速入门手册和OE开发包ddk/samples/ai_toolchain/horizon_model_train_sample/plugin_basic目录下的QAT(fx模式)基本示例,对PIDNet模型做了一些必要的改造,以及编写了做calibration的脚本calibration.py。
7.1 模型改造
在做QAT前,需要对浮点模型做必要的改造,除了要在模型输入前后插入分别 QuantStub和 DequantStub这样的基本操作外,还要对fx模式下模型中不支持的结构进行替换。
7.1.1 插入 QuantStub和 DequantStub节点
进入到PIDNet-main/models/pidnet.py代码中,在PIDNet类的forward代码中插入QuantStub()和 DeQuantStub(),如下所示:
#1. import QuantStub和DeQuantStub
from torch.quantization import DeQuantStub
from horizon_plugin_pytorch.quantization import QuantStub
class PIDNet(nn.Module):
def __init__(self, m=2, n=3, num_classes=19, planes=64, ppm_planes=96, head_planes=128, augment=True):
super(PIDNet, self).__init__()
#2.初始化QuantStub和DeQuantStub
self.quant = QuantStub()
self.dequant = DeQuantStub()
...
def forward(self, x):
width_output = x.shape[-1] // 8
height_output = x.shape[-2] // 8
#3.输入端插入QuantStub
x = self.quant(x)
x = self.conv1(x)
...
x_ = self.final_layer(self.dfm(x_, x, x_d))
#4.输出端插入DeQuantStub
x_ = self.dequant(x_)
if self.augment:
x_extra_p = self.seghead_p(temp_p)
x_extra_d = self.seghead_d(temp_d)
return [x_extra_p, x_, x_extra_d]
else:
return x_
7.1.2 替换fx模式下不支持的结构
进入到PIDNet-main/models/model_utils.py代码中,对代码进行以下4处修改:
改动1:
修改Pagfm类中的forward函数,将torch.sum()函数中的keepdim参数配置为True:
sim_map = torch.sigmoid(self.up(x_k * y_q))
else:
# 改动1
# sim_map = torch.sigmoid(torch.sum(x_k * y_q, dim=1).unsqueeze(1))
sim_map = torch.sigmoid(torch.sum(x_k * y_q, dim=1,keepdim=True))
J5硬件平台对算子支持为4维支持,所以在做sum计算时需要配置keepdim参数为True保证输出Tensor为4维,否则在calibration时会报错。
改动2:-
修改Pagfm类中的forward函数,替换(1-x)的计算为(x+(-1))*(-1):
y = F.interpolate(y, size=[input_size[2], input_size[3]],
mode='bilinear', align_corners=False)
#改动2
# x = (1-sim_map)*x + sim_map*y
x=(sim_map+(-1))*(-1)*x + sim_map*y
模型中如果存在(1-x)这种第一个数是常量的计算,fx模式下的逻辑是不自动进行算子替换,所以需要对类似的计算做一下替换,即将(1-x)的操作修改为(x+(-1))*(-1)。
改动3:-
和改动2类似,修改Light_Bag类中的forward函数,替换(1-x)的计算为(x+(-1))*(-1):
def forward(self, p, i, d):
edge_att = torch.sigmoid(d)
#改动3
# p_add = self.conv_p((1-edge_att)*i + p)
p_add = self.conv_p((edge_att+(-1))*(-1)*i + p)
i_add = self.conv_i(i + edge_att*p)
return p_add + i_add
改动4:-
和改动2类似,修改DDFMv2类中的forward函数,替换(1-x)的计算为(x+(-1))*(-1):
def forward(self, p, i, d):
edge_att = torch.sigmoid(d)
#改动4
# p_add = self.conv_p((1-edge_att)*i + p)
p_add = self.conv_p((edge_att+(-1))*(-1)*i + p)
i_add = self.conv_i(i + edge_att*p)
return p_add + i_add
7.1.3 calibration.py脚本
模型改造完成以后,在PIDNet-main/tools文件夹下创建calibration.py脚本来做模型的Calibration,代码如下所示:
import argparse
import os
import pprint
import copy
import logging
import timeit
import numpy as np
from horizon_plugin_profiler import check_qconfig
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
import torch.optim
from tensorboardX import SummaryWriter
import _init_paths
import models
import datasets
from configs import config
from configs import update_config
from utils.criterion import CrossEntropy, OhemCrossEntropy, BondaryLoss
from utils.function import train, validate
from utils.utils import create_logger, FullModel
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.quantization import (
QuantStub,
convert_fx,
prepare_qat_fx,
set_fake_quantize,
FakeQuantState,
check_model,
compile_model,
perf_model,
visualize_model,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_calib_8bit_fake_quant_qconfig,
default_qat_8bit_fake_quant_qconfig,
default_qat_8bit_weight_32bit_out_fake_quant_qconfig,
default_calib_8bit_weight_32bit_out_fake_quant_qconfig,
)
from typing import Optional, Callable, List, Tuple
def parse_args():
parser = argparse.ArgumentParser(description='Train segmentation network')
parser.add_argument('--cfg',"-c",
help='experiment configure file name',
default="configs/cityscapes/pidnet_small_cityscapes.yaml",
type=str)
parser.add_argument('--save_path',"-s",
help='path for save calibration ckpt',
default="./calibration",
type=str)
parser.add_argument('--seed', type=int, default=304)
parser.add_argument('opts',
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER)
args = parser.parse_args()
update_config(config, args)
return args
def load_pretrained(model, pretrained):
pretrained_dict = torch.load(pretrained, map_location='cpu')
if 'state_dict' in pretrained_dict:
pretrained_dict = pretrained_dict['state_dict']
model_dict = model.state_dict()
pretrained_dict = {k[6:]: v for k, v in pretrained_dict.items() if (k[6:] in model_dict and v.shape == model_dict[k[6:]].shape)}
msg = 'Loaded {} parameters!'.format(len(pretrained_dict))
# print('Attention!!!')
print(msg)
print('Over!!!')
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict, strict = False)
return model
def dataloader(config):
# cudnn related setting
cudnn.benchmark = config.CUDNN.BENCHMARK
cudnn.deterministic = config.CUDNN.DETERMINISTIC
cudnn.enabled = config.CUDNN.ENABLED
gpus = list(config.GPUS)
batch_size = config.TRAIN.BATCH_SIZE_PER_GPU * len(gpus)
# prepare data
crop_size = (config.TRAIN.IMAGE_SIZE[1], config.TRAIN.IMAGE_SIZE[0])
train_dataset = eval('datasets.'+config.DATASET.DATASET)(
root=config.DATASET.ROOT,
list_path=config.DATASET.TRAIN_SET,
num_classes=config.DATASET.NUM_CLASSES,
multi_scale=config.TRAIN.MULTI_SCALE,
flip=config.TRAIN.FLIP,
ignore_label=config.TRAIN.IGNORE_LABEL,
base_size=config.TRAIN.BASE_SIZE,
crop_size=crop_size,
scale_factor=config.TRAIN.SCALE_FACTOR)
trainloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=config.TRAIN.SHUFFLE,
num_workers=config.WORKERS,
pin_memory=False,
drop_last=True)
test_size = (config.TEST.IMAGE_SIZE[1], config.TEST.IMAGE_SIZE[0])
test_dataset = eval('datasets.'+config.DATASET.DATASET)(
root=config.DATASET.ROOT,
list_path=config.DATASET.TEST_SET,
num_classes=config.DATASET.NUM_CLASSES,
multi_scale=False,
flip=False,
ignore_label=config.TRAIN.IGNORE_LABEL,
base_size=config.TEST.BASE_SIZE,
crop_size=test_size)
testloader = torch.utils.data.DataLoader(
test_dataset,
batch_size=config.TEST.BATCH_SIZE_PER_GPU * len(gpus),
shuffle=False,
num_workers=config.WORKERS,
pin_memory=False)
return trainloader,testloader
def calibration_trainer(calib_model,config):
args = parse_args()
calib_model.eval()
#set calibration model state
set_fake_quantize(calib_model, FakeQuantState.CALIBRATION)
#data loader
train_data_loader, eval_data_loader =dataloader(config)
if not os.path.exists(args.save_path):
os.mkdir(args.save_path)
with torch.no_grad():
cnt = 0
for idx, batch in enumerate(train_data_loader):
image, label, bd_gts, _, _ = batch
size = label.size()
image = image.cuda()
print("img size:",image.shape)
label = label.long().cuda()
# print("input image size:",image.shape)
bd_gts = bd_gts.float().cuda()
cnt+=1
pred= calib_model(image)
if cnt%10==0:
torch.save(calib_model.state_dict(),os.path.join(args.save_path, "calib-checkpoint.ckpt"))
print("--------save calib ckpt ok--------")
print("--------"+str(cnt)+"--------")
print("------calibration end------")
calib_model.eval()
set_fake_quantize(calib_model, FakeQuantState.VALIDATION)
# calib_model = FullModel(calib_model, sem_criterion, bd_criterion)
torch.save(
calib_model.state_dict(),
os.path.join(args.save_path, "calib-checkpoint-last.ckpt"),
)
print("------save calibration ckpt ok------")
def get_model_fx(
march=March.BAYES,
) -> nn.Module:
'''
The function is used to transforms float model to calibration model.
'''
float_model = models.pidnet.get_pred_model('pidnet_s', 19)
#浮点训练权重的路径
float_ckpt_path ="./pretrained_models/cityscapes/PIDNet_S_Cityscapes_val.pt"
assert os.path.exists(float_ckpt_path)
#配置model为bayes架构(J5)
set_march(march)
ori_float_model = float_model
float_model = copy.deepcopy(ori_float_model)
#加载浮点权重
float_model = load_pretrained(float_model, float_ckpt_path)
#prepare calibration model
calib_model = prepare_qat_fx(
float_model,
{
"": default_calib_8bit_fake_quant_qconfig,
"module_name": {
#配置模型尾部的conv为int32高精度输出
"final_layer.conv2": default_calib_8bit_weight_32bit_out_fake_quant_qconfig,
},
},
)
return calib_model
def main():
args = parse_args()
if args.seed > 0:
import random
print('Seeding with', args.seed)
random.seed(args.seed)
torch.manual_seed(args.seed)
logger, final_output_dir, tb_log_dir = create_logger(
config, args.cfg, 'train')
logger.info(pprint.pformat(args))
logger.info(config)
# cudnn related setting
cudnn.benchmark = config.CUDNN.BENCHMARK
cudnn.deterministic = config.CUDNN.DETERMINISTIC
cudnn.enabled = config.CUDNN.ENABLED
gpus = list(config.GPUS)
#获取calibration model
model = get_model_fx().cuda()
print("------get calibration model ok ------")
#start to calibration
calibration_trainer(model,config)
if __name__ == '__main__':
main()
模型高精度输出详细配置方式见附录。
7.2 Calibration命令
完成上述准备工作后,运行calibration命令:
python3 tools/calibration.py -c configs/cityscapes/pidnet_small_cityscapes.yaml
calibration完成后,会在save_path文件夹下生成calib-checkpoint-last.ckpt,即calibration model的权重。
8. 精度验证
8.1 精度验证脚本编写及推理代码修改
8.1.1 精度验证脚本编写
为了简化精度验证的步骤,在PIDNet-main/tools文件夹下创建predictor.py脚本来做float模型、calibration模型、量化模型的精度验证,代码如下所示:
import argparse
import os
import pprint
import logging
import timeit
import numpy as np
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
import _init_paths
import models
import datasets
from configs import config
from configs import update_config
from utils.function import testval, test
from utils.utils import create_logger
from train_fx import get_model_fx
from horizon_plugin_pytorch.quantization import (
QuantStub,
convert_fx,
prepare_qat_fx,
set_fake_quantize,
FakeQuantState,
check_model,
compile_model,
perf_model,
visualize_model,
)
def parse_args():
parser = argparse.ArgumentParser(description='Train segmentation network')
parser.add_argument('--cfg','-c',
help='experiment configure file name',
default="experiments/cityscapes/pidnet_small_cityscapes.yaml",
type=str)
parser.add_argument('--stage','-s',
help='float,calib,qat',
default="float",
type=str)
parser.add_argument('opts',
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER)
args = parser.parse_args()
update_config(config, args)
return args
def load_pretrained(model, pretrained):
pretrained_dict = torch.load(pretrained, map_location='cpu')
if 'state_dict' in pretrained_dict:
pretrained_dict = pretrained_dict['state_dict']
model_dict = model.state_dict()
pretrained_dict = {k[6:]: v for k, v in pretrained_dict.items() if (k[6:] in model_dict and v.shape == model_dict[k[6:]].shape)}
msg = 'Loaded {} parameters!'.format(len(pretrained_dict))
print('Attention!!!')
print(msg)
print('Over!!!')
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict, strict = False)
return model
def main():
args = parse_args()
logger, final_output_dir, _ = create_logger(
config, args.cfg, 'test')
logger.info(pprint.pformat(args))
logger.info(pprint.pformat(config))
# cudnn related setting
cudnn.benchmark = config.CUDNN.BENCHMARK
cudnn.deterministic = config.CUDNN.DETERMINISTIC
cudnn.enabled = config.CUDNN.ENABLED
# build model
stage=args.stage
#浮点模型精度验证
if stage=="float":
model = models.pidnet.get_pred_model(name="pidnet_s",num_classes=19)
float_path="./pretrained_models/cityscapes/PIDNet_S_Cityscapes_val.pt"
model = load_pretrained(model, float_path).cuda()
model.eval()
#calibration模型精度验证
if stage=="calib":
model=get_model_fx(stage)
calib_ckpt_path="./calibration/calib-checkpoint-last.ckpt"
calib_model_dict=torch.load(calib_ckpt_path, map_location='cpu')
model.load_state_dict(calib_model_dict)
model=model.cuda()
model.eval()
set_fake_quantize(model, FakeQuantState.VALIDATION)
#quantized模型精度验证
if stage=="int_infer":
model=get_model_fx("calib")
calib_ckpt_path="./calibration/calib-checkpoint-last.ckpt"
calib_model_dict=torch.load(calib_ckpt_path, map_location='cpu')
model.load_state_dict(calib_model_dict)
model.eval()
set_fake_quantize(model, FakeQuantState.VALIDATION)
model = convert_fx(model)
print("model:",model)
model=model.cuda()
# prepare data
test_size = (config.TEST.IMAGE_SIZE[1], config.TEST.IMAGE_SIZE[0])
test_dataset = eval('datasets.'+config.DATASET.DATASET)(
root=config.DATASET.ROOT,
list_path=config.DATASET.TEST_SET,
num_classes=config.DATASET.NUM_CLASSES,
multi_scale=False,
flip=False,
ignore_label=config.TRAIN.IGNORE_LABEL,
base_size=config.TEST.BASE_SIZE,
crop_size=test_size)
testloader = torch.utils.data.DataLoader(
test_dataset,
batch_size=1,
shuffle=False,
num_workers=0,
pin_memory=True)
print("------testloader ok------")
start = timeit.default_timer()
mean_IoU, IoU_array, pixel_acc, mean_acc = testval(config,
test_dataset,
testloader,
model)
msg = 'MeanIU: {: 4.4f}, Pixel_Acc: {: 4.4f}, \
Mean_Acc: {: 4.4f}, Class IoU: '.format(mean_IoU,
pixel_acc, mean_acc)
logging.info(msg)
logging.info(IoU_array)
end = timeit.default_timer()
logger.info('Mins: %d' % np.int((end-start)/60))
logger.info('Done')
if __name__ == '__main__':
main()
8.1.2 推理代码修改
运行predictor.py脚本前,需要修改config文件和推理代码:
-
修改PIDNet-main/configs/cityscapes/pidnet_small_cityscapes.yaml中TEST字段中的OUTPUT_INDEX为0;
-
修改PIDNet-main/datasets/base_dataset.py中inference函数的代码,如下:
def inference(self, config, model, image):
size = image.size()
pred = model(image)if config.MODEL.NUM_OUTPUTS > 1: pred = pred[config.TEST.OUTPUT_INDEX] #在interpolate函数中对pred做unsqueeze(0)操作 pred = F.interpolate( pred.unsqueeze(0), size=size[-2:], mode='bilinear', align_corners=True) return pred.exp()
8.2 Calibration精度验证
完成上述准备工作后,运行精度验证脚本:
python3 tools/predictor.py -c configs/cityscapes/pidnet_small_cityscapes.yaml -s calib
命令运行结束后,在终端会打印Calibration模型在CityScapes验证集下的精度,如下所示:
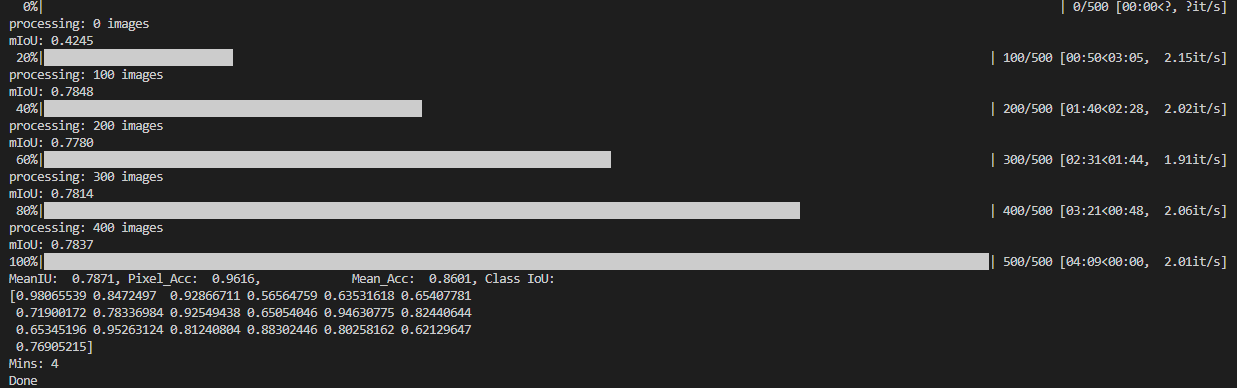
可以看出,calibration模型的精度(MeanIU 0.7871)是浮点模型的精度(MeanIU 0.7876)的99.94%,满足精度要求,那么我们就直接走量化编译的流程。 如果calibration模型的精度比浮点模型精度低很多,建议参考手册继续进行量化感知训练。
8.3 量化模型精度验证
calibration模型满足精度要求后,我们首先使用convert_fx接口将其转化为量化模型,然后运行predictor.py 脚本验证其在CityScapes验证集下的精度,如下所示:
python3 tools/predictor.py -c configs/cityscapes/pidnet_small_cityscapes.yaml -s int_infer
命令运行结束后,在终端会打印量化模型在CityScapes验证集下的精度,如下所示:
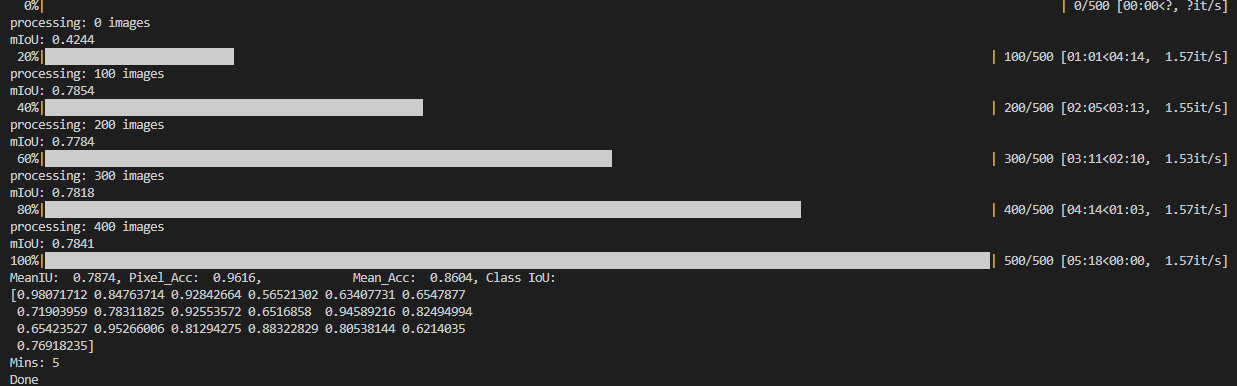
可以看出,量化模型的精度(MeanIU 0.7874)是浮点模型的精度(MeanIU 0.7876)的99.975%,满足量化精度要求,下面我们直接进行编译。
如果量化模型精度不及浮点模型精度的99%,建议使用地平线QAT中的精度debug工具来进行精度问题排查和调优。
9. 模型编译及板端性能实测
9.1 编译脚本编写
在PIDNet-main/tools文件夹下创建compile_perf.py脚本来实现模型的编译、静态perf和模型结构可视化,代码如下所示:
import os
import torch
import torch.nn as nn
from horizon_plugin_pytorch.functional import centered_yuv2rgb,centered_yuv2bgr
from train_fx import get_model_fx
from horizon_plugin_pytorch.quantization import (
QuantStub,
convert_fx,
prepare_qat_fx,
set_fake_quantize,
FakeQuantState,
check_model,
compile_model,
perf_model,
visualize_model,
)
def main():
#获取calibration model
model=get_model_fx("calib")
#calibration模型ckpt路径
calib_ckpt_path="./calibration/calib-checkpoint-last.ckpt"
calib_model_dict=torch.load(calib_ckpt_path, map_location='cpu')
model.load_state_dict(calib_model_dict)
model.eval()
#将calibration model转为quantized model
quantized_model = convert_fx(model)
quantized_model=quantized_model.cpu()
# print("quantized model:",quantized_model)
example_input=torch.randn(1,3,1024,2048).cpu()
#trace model
script_model = torch.jit.trace(quantized_model, example_input)
print("script_model:",script_model)
#编译模型保存路径
model_path="./compile"
if not os.path.exists(model_path):
os.mkdir(model_path)
torch.jit.save(script_model, os.path.join(model_path, "int_model.pt"))
print("------save pt ok -------")
# 模型检查
check_model(script_model, example_input)
print("-----check model ok------")
#模型编译
compile_model(
script_model,
[example_input],
hbm=os.path.join(model_path, "model.hbm"),
input_source="ddr",
opt=3,
)
print("-----compile model ok------")
#模型静态性能预估
perf_model(
script_model,
[example_input],
out_dir=os.path.join(model_path, "perf_out"),
input_source="ddr",
opt=3,
layer_details=True,
)
print("-----perf model ok------")
#生成模型结构SVG图
visualize_model(
script_model,
[example_input],
save_path=os.path.join(model_path, "pidnet-s.svg"),
show=False,
)
print("-----visual model ok------")
if __name__ == '__main__':
main()
9.2 编译命令及产出物
完成脚本创建后,运行编译命令:
python3 tools/compile_perf.py
运行完成后,在model_path下会有以下产出物:
│ ├── int_model.pt
│ ├── model.hbir #hbir:用来编译hbm模型
│ ├── model.hbm #上板部署hbm模型
│ ├── model.pt
│ ├── pidnet-s.svg #模型可视化图
│ └── perf_out #静态perf性能html
│ ├── PIDNet.html
│ └── PIDNet.json
9.3 板端性能实测
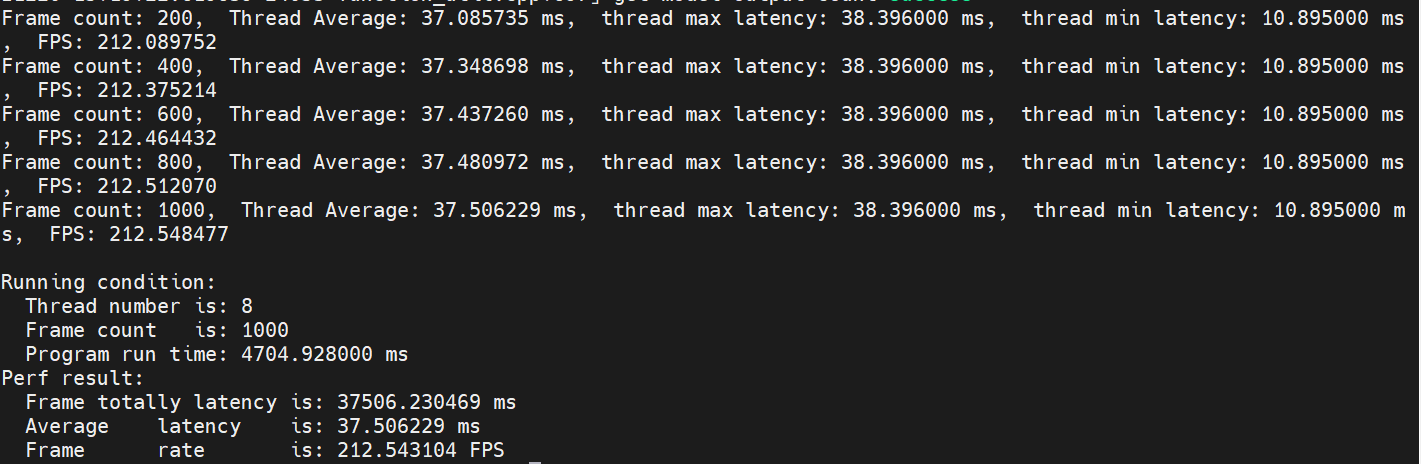
编译完成后,可以使用地平线提供的hrt_model_exec perf工具在J5板端实测hbm模型的双核FPS,参考命令如下:
hrt_model_exec perf --model_file model.hbm --core_id 0 --frame_count 1
000 --thread_num 8 --profile_path "./"
运行结果:
10. 单帧可视化
为了便于查看不同阶段的模型推理单帧图像的可视化结果,编写了PIDNet-main/tools/infer.py脚本来实现浮点模型、calibration模型和量化模型单帧推理结果的可视化,infer.py脚本代码如下:
import glob
import argparse
import cv2
import os
import numpy as np
import _init_paths
import models
import torch
import torch.nn.functional as F
from PIL import Image
from train_fx import get_model_fx
from horizon_plugin_pytorch.quantization import (
QuantStub,
convert_fx,
prepare_qat_fx,
set_fake_quantize,
FakeQuantState,
check_model,
compile_model,
perf_model,
visualize_model,
)
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
color_map = [(128, 64,128),
(244, 35,232),
( 70, 70, 70),
(102,102,156),
(190,153,153),
(153,153,153),
(250,170, 30),
(220,220, 0),
(107,142, 35),
(152,251,152),
( 70,130,180),
(220, 20, 60),
(255, 0, 0),
( 0, 0,142),
( 0, 0, 70),
( 0, 60,100),
( 0, 80,100),
( 0, 0,230),
(119, 11, 32)]
def parse_args():
parser = argparse.ArgumentParser(description='Custom Input')
parser.add_argument('--a', help='pidnet-s, pidnet-m or pidnet-l', default='pidnet-s', type=str)
parser.add_argument('--c', help='cityscapes pretrained or not', type=bool, default=True)
parser.add_argument('--stage','-s', help='float,calib or int_infer', default='float', type=str)
parser.add_argument('--p', help='dir for pretrained model', default='./pretrained_models/cityscapes/PIDNet_S_Cityscapes_val.pt', type=str)
parser.add_argument('--r', help='root or dir for input images', default='./input_sample/', type=str)
parser.add_argument('--t', help='the format of input images (.jpg, .png, ...)', default='.png', type=str)
args = parser.parse_args()
return args
def input_transform(image):
image = image.astype(np.float32)[:, :, ::-1]
image = image / 255.0
image -= mean
image /= std
return image
def load_pretrained(model, pretrained):
pretrained_dict = torch.load(pretrained, map_location='cpu')
if 'state_dict' in pretrained_dict:
pretrained_dict = pretrained_dict['state_dict']
model_dict = model.state_dict()
pretrained_dict = {k[6:]: v for k, v in pretrained_dict.items() if (k[6:] in model_dict and v.shape == model_dict[k[6:]].shape)}
msg = 'Loaded {} parameters!'.format(len(pretrained_dict))
print('Attention!!!')
print(msg)
print('Over!!!')
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict, strict = False)
return model
if __name__ == '__main__':
args = parse_args()
images_list = glob.glob(args.r+'*'+args.t)
sv_path = args.r+args.stage
stage=args.stage
#load 浮点模型
if stage=="float":
model = models.pidnet.get_pred_model(args.a, 19 if args.c else 11)
model = load_pretrained(model, args.p).cuda()
model.eval()
#load calibration模型
if stage =="calib":
model=get_model_fx(stage)
calib_ckpt_path="./calibration/calib-checkpoint.ckpt"
calib_model_dict=torch.load(calib_ckpt_path, map_location='cpu')
model.load_state_dict(calib_model_dict)
model=model.cuda()
model.eval()
#load量化模型
if stage=="int_infer":
model=get_model_fx("calib")
calib_ckpt_path="./calibration/calib-checkpoint.ckpt"
calib_model_dict=torch.load(calib_ckpt_path, map_location='cpu')
model.load_state_dict(calib_model_dict)
model.eval()
model = convert_fx(model)
model=model.cuda()
with torch.no_grad():
for img_path in images_list:
img = cv2.imread(img_path,cv2.IMREAD_COLOR)
sv_img = np.zeros_like(img).astype(np.uint8)
img = input_transform(img)
img = img.transpose((2, 0, 1)).copy()
img = torch.from_numpy(img).unsqueeze(0).cuda()
pred = model(img)
print(pred.shape)
pred1=pred.cpu().numpy()
# np.save("output_pc.npy",pred1)
# print("------save output ok")
pred = F.interpolate(pred, size=img.size()[-2:],
mode='bilinear', align_corners=True)
print(pred.shape)
pred = torch.argmax(pred, dim=1).squeeze(0).cpu().numpy()
# print(pred.shape,pred)
for i, color in enumerate(color_map):
for j in range(3):
sv_img[:,:,j][pred==i] = color_map[i][j]
sv_img = Image.fromarray(sv_img)
if not os.path.exists(sv_path):
os.mkdir(sv_path)
img_name = img_path[-20:]
sv_img.save(sv_path+"/"+img_name)
参数介绍:
- --a:模型规格,默认pidnet-s
- --c:是否加载预训练模型,默认True
- --stage ,-s:配置推理模型的阶段,可选float,calib or int_infer,默认”float“
- --p:load浮点模型的路径
- --r:输入图像路径,默认是’./input_sample’
- --t:输入图像的格式,默认是“.png”
可视化运行命令:
#浮点模型可视化
#浮点模型推理可视化
python3 tools/infer.py --stage float
#calibration 模型推理可视化
python3 tools/infer.py --stage calib
#量化模型推理可视化
python3 tools/infer.py --stage int_infer
可视化结果:-
这里重点关注浮点模型和量化模型单帧推理可视化结果的差异,如果差异较大,那可能就是量化带来了较大的精度损失,建议结合地平线提供的精度分析工具进行问题排查。
11. 附录
问题1
prepare_qat_fx报错:
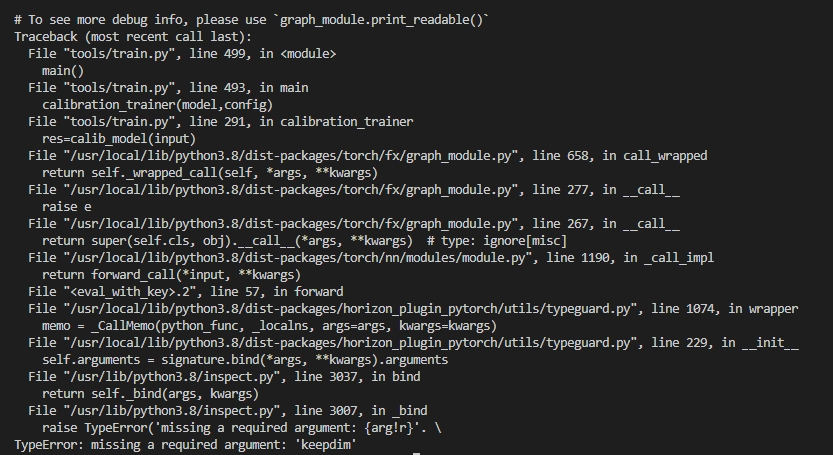
解决办法:-
答:修改torch.sum算子的keepdim参数为True,对应7.1.2节改动1。
问题2
calibration时forward报错:
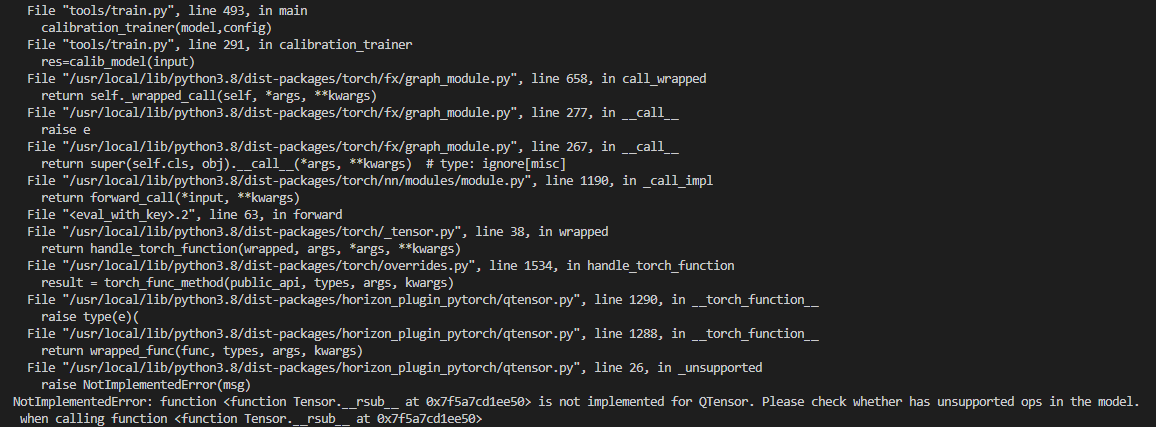
**报错原因:** fx目前的逻辑是如果减法中的被减数是常量,就不自动进行算子替换了。
解决办法:-
答:把减法改成加法,对应7.1.2节改动2,改动3,改动4。-
问题3-
Calibration 模型forward报错:
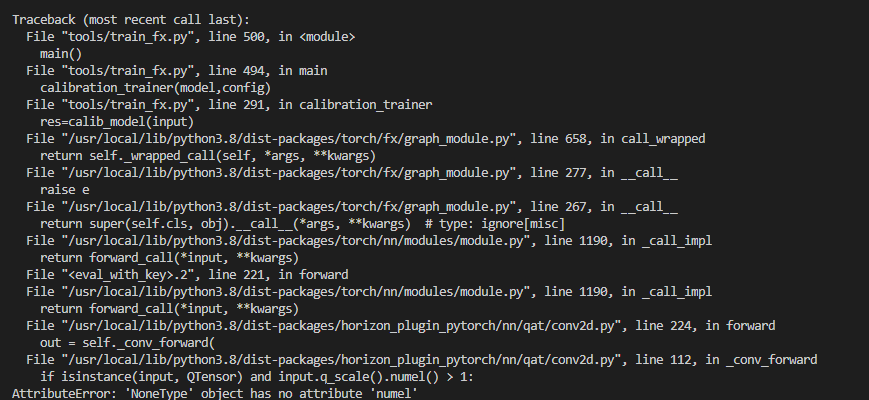
报错原因:-
int32高精度层配置错误,导致中间层的conv出现了int32的输入-
解决办法:-
打印浮点模型,查看模型尾部conv的name,如下所示:

可以看出,输出层的name是final_layer.conv2,那么我们就对应修改prepare_qat_fx中的配置:
calib_model = prepare_qat_fx(
float_model,
{
"": default_calib_8bit_fake_quant_qconfig,
"module_name": {
"final_layer.conv2": default_calib_8bit_weight_32bit_out_fake_quant_qconfig,
},
},
)
除此之外,还可以借助地平线提供的量化配置检查工具check_qconfig(from horizon_plugin_profiler import check_qconfig),从输出的qconfig_info.txt中来查看模型最后一层的名称:
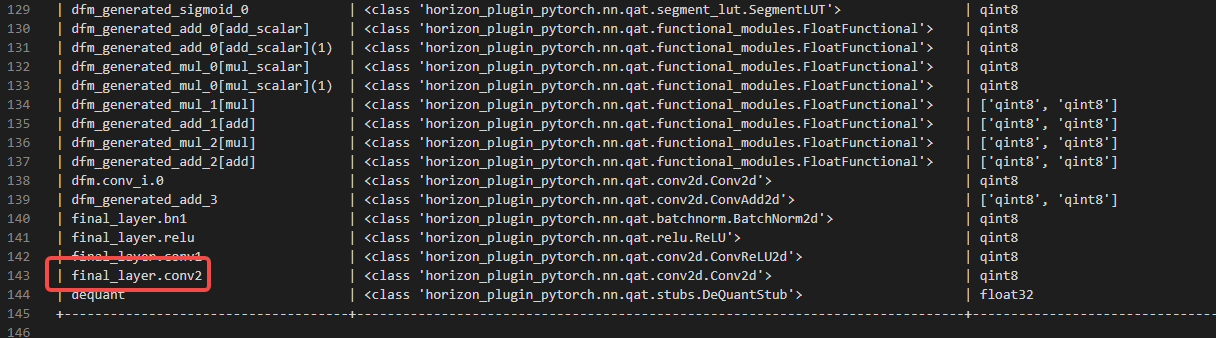
如何确定final_layer.conv2已被成功配置为了int32输出?-
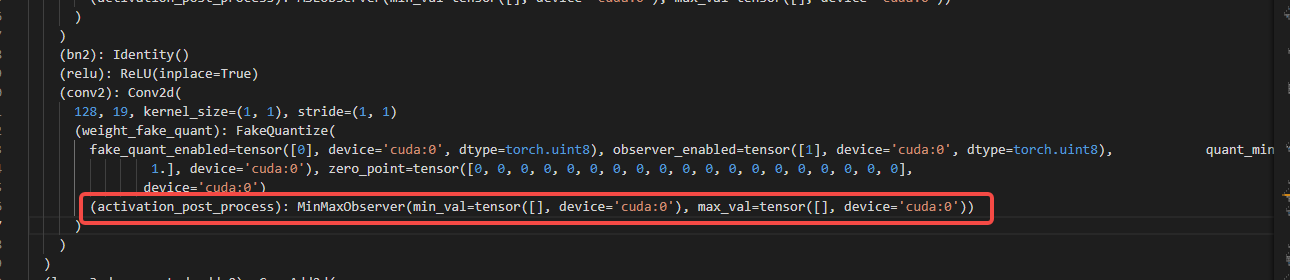
答:打印calibration model,查看final_layer的conv2算子是否有(activation_post_process): FakeQuantize,如果没有,那么已经成功配置为了int32输出。下面为成功配置为int32高精度输出的情况:
12. 参考资料
https://zhuanlan.zhihu.com/p/626535727-
https://github.com/XuJiacong/PIDNet-
https://developer.horizon.cc/api/v1/fileData/horizon_j5_open_explorer_cn_doc/plugin/source/quick_start/quick_start.html