0、前言
玩RDKx5碰到了不少坑……故有此贴记录一下。感谢社区诸位前辈留下的博客,还有超哥在交流群耐心给出的解答,这篇博客也算是做出点贡献,让后人能够轻松一些。
本帖的路线为,yolo训练(大佬的博客代劳) → yolo转onnx及校准数据集准备 → docker中模型格式转换 → 模型部署上板 → tros部署yolo
为了避免重复造轮子的操作(就是本人比较懒), 所以我在这里列出一份前辈大佬写好的yolov10从数据集构建,到yolo训练,再到使用模型进行推理的博客,免得鄙人这种蒟蒻写出来有一堆bug的东西,误人子弟就不好了。
但也先别急着把本帖关掉,虽然说不会有什么大问题,但是你知道的,干开发最日常的就是每一步都是按教程走的然后报了一堆奇奇妙妙的错误。
所以本文会记录一些我在跟着教程训练yolov10碰到的奇怪的问题,以及一些微调模型提高模型性能的方法,但是因为帖主是蒟蒻,所以微调模型方面我只知道这样调整有用,但为什么有用,我说不出来。-
(求放过.jpg
容我再吐糟一句,yolov10官方那边yolov10的资料偏少,而且散装教程,部署的时候我是挂着三份文档看着的,而且还不太好找……
1、yolo训练可能的问题和补充
1.1、AMD的电脑
这一块我也很迷惑,在上述的教程中使用的cudatoolkit是11.7版本的,在intel处理器的电脑上完全没有问题,但是在AMD的电脑上就会报出如下错误:-
OSError: [WinError 193] %1 不是有效的 Win32 应用程序。
原因不清楚,但因为我给AMD配环境的过程中遭受了非人的折磨,所以我自以为是的认为AMD个人不支持11.7这么生僻的版本,而在我更换为11.8 的版本时问题解决了。所以基于上述原因,我个人建议,不论啥电脑,都用11.8的版本吧。-
conda install cudatoolkit=11.8-
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
1.2、预训练权重
预训练权重的位置在右边栏目里的release里面,点进去下载,我不知道教程为什么要这么指路,我那个时候找了挺久的。因为帖主是蒟蒻,所以不具备github的基础知识,找不着也很正常(狗头保命)-
1.3、Makesense
打标工具其实不建议用它原本设计的那个,我觉得不好用还挺容易崩溃的,还有python版本适配的问题。而如果你会魔法,我建议是使用Makesense在线网页打标工具。-
Makesense网站-
如果你不会魔法,其实也有中文版的网站,我这里挂一篇博客,顺便带点基础操作。-
MakeSense中文版使用手册
1.4、微调模型相关的参数
# 当我们采用微调模型的时候,就一定要有一个预训练权重,这是我的预训练权重的路径
pretrained: C:\My_things\ProgramData\YOLOv10\pre_model\yolov10n.pt
# (bool | str) whether to use a pretrained model (bool) or a model to load weights from (str)
# 使用余弦退火(Cosine Annealing)学习率调度器。它根据余弦函数来调整学习率,帮助模型收敛,可以打开。
cos_lr: True # (bool) use cosine learning rate scheduler
# 冻结层,其他可以不管,这个一定要设置好,保持权重的前几层可以有效提高我们微调的模型的精度
freeze: [0, 1, 2] # (int | list, optional) freeze first n layers, or freeze list of layer indices during training
# 启动多尺度训练,帮助模型更好地处理不同尺寸的输入图像,可以打开
multi_scale: True # (bool) Whether to use multiscale during training
# 以下是我调不明白的参数,欢迎各位炼丹师去查相关资料来尝试,以下均是默认值
lr0: 0.01 # (float) initial learning rate (i.e. SGD=1E-2, Adam=1E-3)
lrf: 0.01 # (float) final learning rate (lr0 * lrf)
weight_decay: 0.0005 # (float) optimizer weight decay 5e-4
hsv_h: 0.015 # (float) image HSV-Hue augmentation (fraction) 0
hsv_s: 0.7 # (float) image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # (float) image HSV-Value augmentation (fraction)
mosaic: 0.8 # (float) image mosaic (probability)
mixup: 0.2 # (float) image mixup (probability)
放一下微调和非微调的对比图吧
非微调-

微调-

效果还是挺明显的。
2、RDKx5部署yolov10
2.0、前言和准备
帖主尽蒟蒻所能把散装的资料整合起来,希望没有什么bug……末尾会放上资料的来源,方便想进一步查阅的朋友。
根据yolo守恒定律,我们要部署yolo在RDKx5上,前提是我们先有一个yolo模型
我们需要准备的东西有:
- docker(进官方网址下载就好)
- 烧录好最新镜像并且更新好源的RDKx5(注意是最新,不然tros部署可能出问题)
- wget下载 挂一篇博客,下载x86就好
- 官方OE包,镜像文件(CPU还是GPU看你自己)官方论坛下载处
- 你的已经训练好的确定效果不错的pt模型
2.0.0、If 出了点什么意外……
说句别的,如果你的电脑是AMD的,打开docker的时候出现了以下问题,那就听我啰嗦一会儿,没有的话往下跳就好了。-
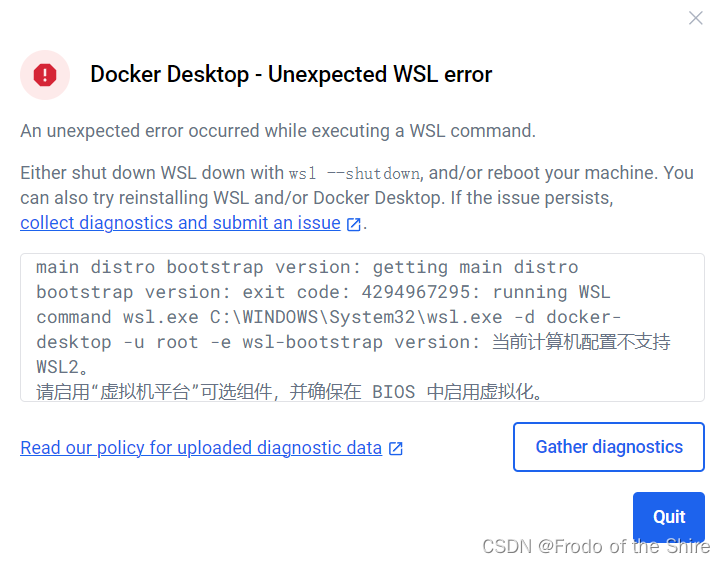
图片源自博客
里面也提到了怎么解决,不过我个人的建议是按以下完整流程跑一遍(谁知道会不会像我一样折磨
-
首先打开你的任务管理器看看有没有打开虚拟化(一般来讲是打开的……没有就去拷打卖你电脑的客服吧
-
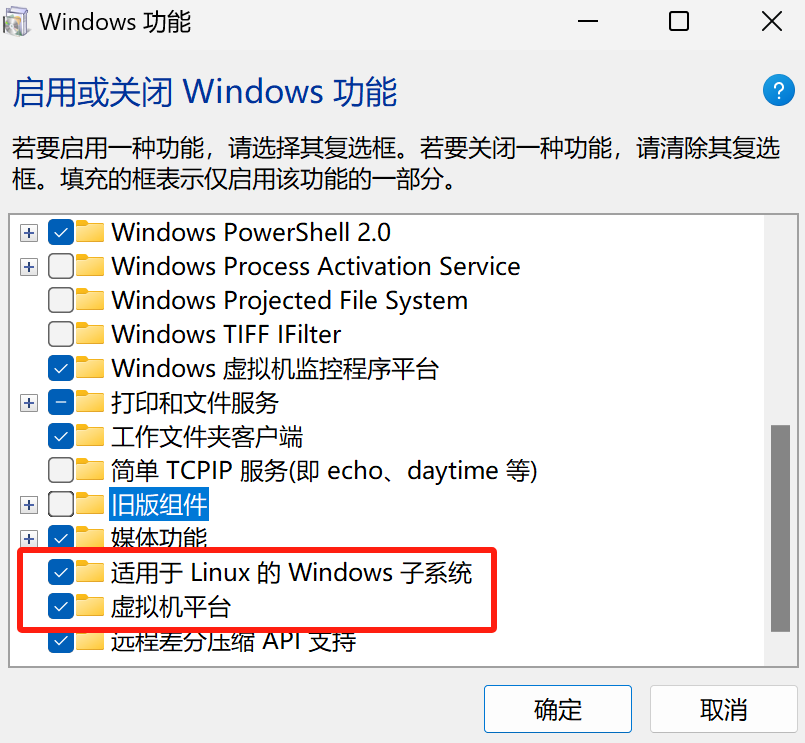
按下你的win键,搜索“启动或关闭Windows功能”确认“虚拟机平台”,“适用于 Linux的Windows子系统”的状态,以及看看有没有“hyper-v”这个东西,这些都要打开。
-
如果没有hyper-v,我们打开命令行,win+R写入cmd,进入终端后写入下面这行命令。-
dism.exe /online /get-features /format:table-
着重关注以下几个参数:需要启用的功能包:
-
VirtualMachinePlatform (已启用)
- 这是 WSL 2 所必需的虚拟化平台。
-
HypervisorPlatform (已禁用)
- 这对于运行 WSL 2 以及启用虚拟化功能(如 Hyper-V)非常重要。需要启用。
-
Microsoft-Windows-Subsystem-Linux (已启用)
- 用于支持 Linux 子系统的功能。
-
NetFx3 (已启用)
- 用于启用 .NET Framework 3.5 的支持,部分 WSL 工具可能需要这个。
-
NetFx4-AdvSrvs (已启用)
- 用于启用 .NET Framework 4.x 的高级服务。可以被一些 WSL 工具所依赖。
-
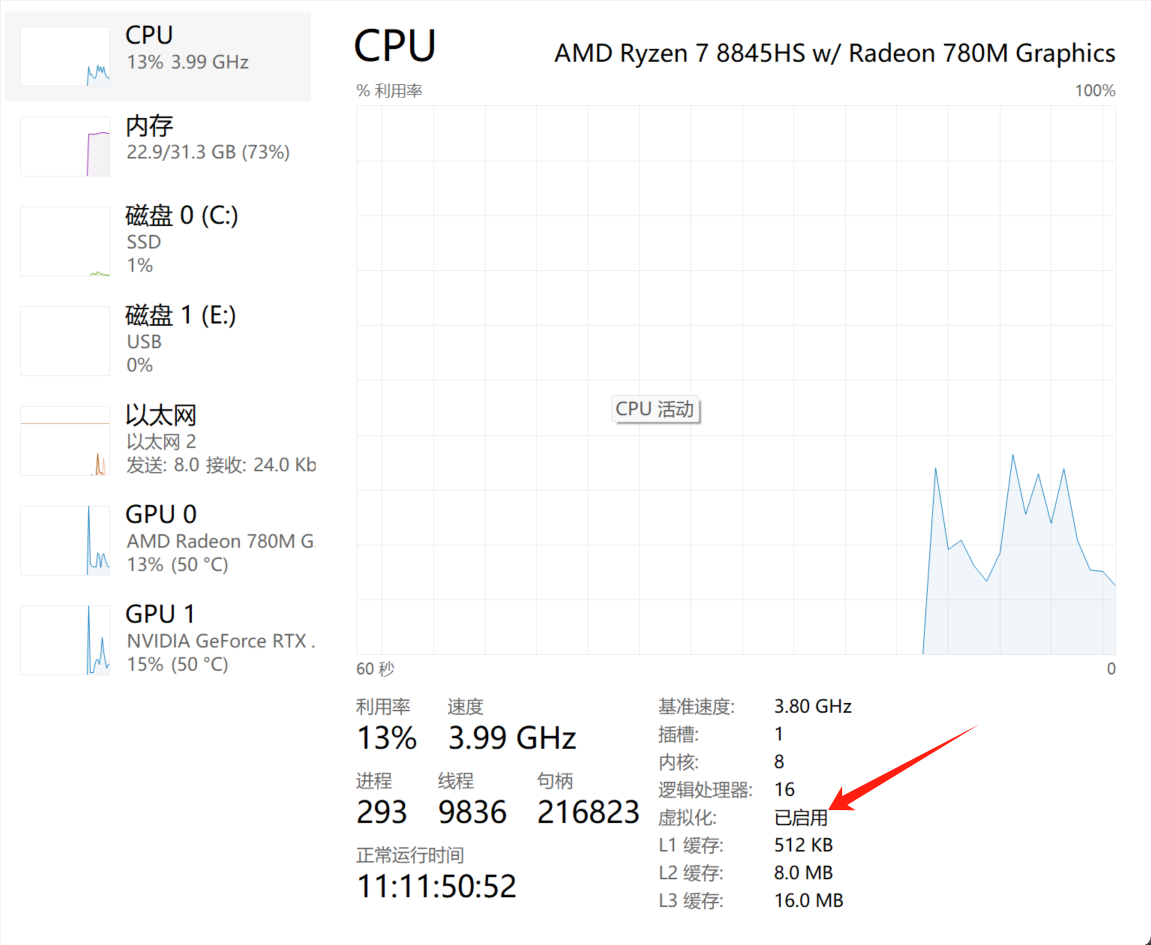
你也可以直接把这部分东西扔给AI,让它帮你排查WSL2的依赖还有哪些没有打开。
- 该打开的开好之后, 最后检查一个东西,还是命令行里,写入以下命令-
bcdedit /enum | findstr -i hypervisorlaunchtype-
你应该会看到Off,写入以下命令把它改成Auto-
bcdedit /set hypervisorlaunchtype Auto-
改完了可以再检查一下,然后我们重启
重启之后docker应该可以正常使用了,如果还不行,再检查一下最后一步,大概率是它又变成Off了,改回来就好了。(别问我怎么知道的,真的折磨)
2.1、模型格式转换和校准数据集准备
首先,我们再PyCharm的终端行里-
pip uninstall ultralytics-
(如果删不掉,就去官方的github仓库里的modelzoo的YOLOv10的readme文件看操作,还有办法)
再进入nn文件夹,点开module文件夹,点开里面的head文件-
大概在里面521行,隶属class v10Detect,把forward一整个函数注释掉。-
然后粘贴上官方的给的forward代码,修改输出的onnx模型的输出头。-
(主要看隶属的class正确就可以,行数只是方便你定位。)-
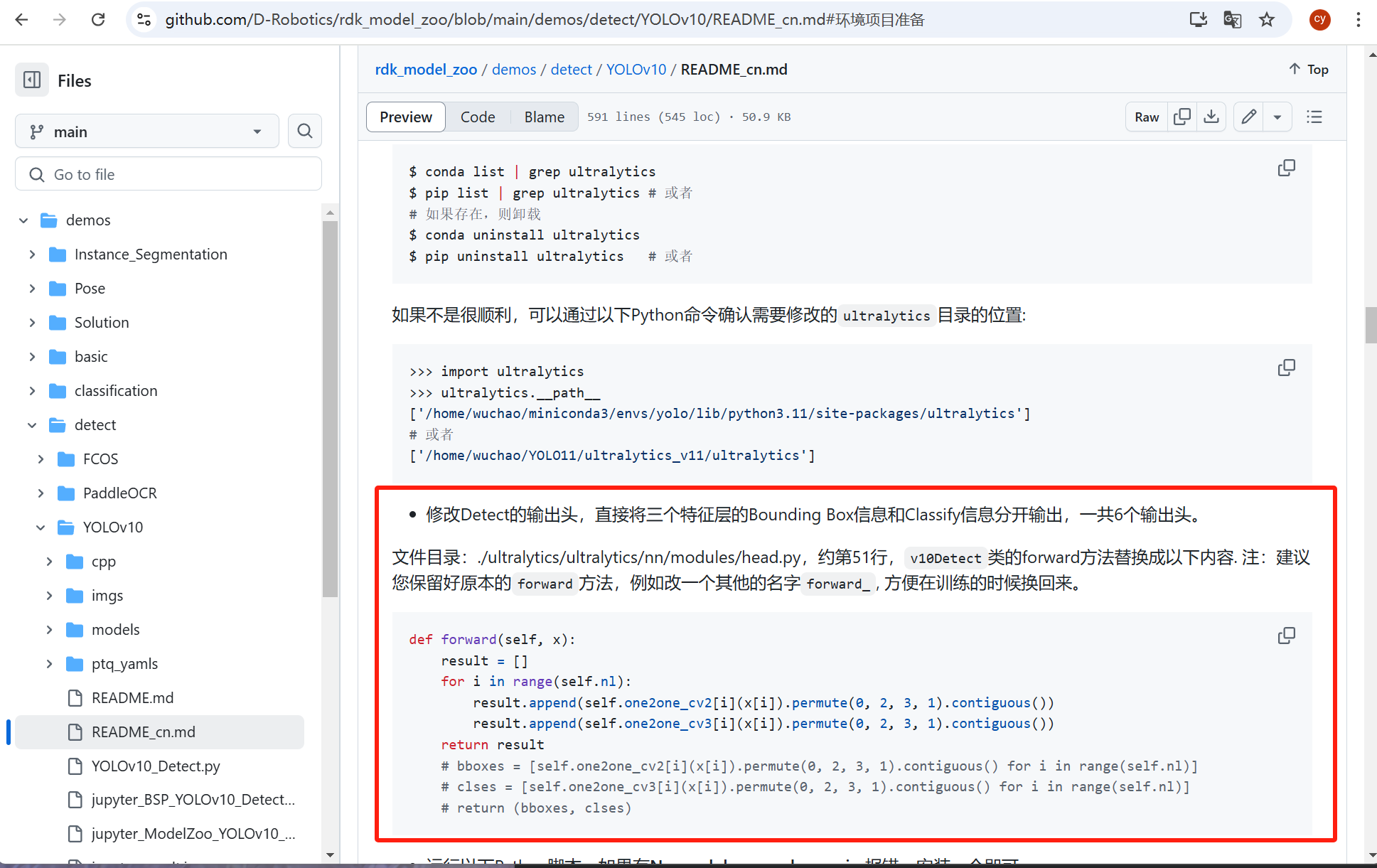
图片来自官方的github仓库里的modelzoo的YOLOv10的readme文件,链接我会放在最后。
但是!我不建议直接使用官方的代码,我的建议是用我的这份,没啥区别,只是进一步调整了输出头的顺序。(cv3和cv2换了一下而已)-
因为我们后面还要用tros部署,为了对上输出头的顺序所以做出的修改。产生的影响还有后续使用modelzoo里的推理代码时输出头顺序的更改(虽然你不动也得改……)
def forward(self, x):
result = []
for i in range(self.nl):
result.append(self.one2one_cv3[i](x[i]).permute(0, 2, 3, 1).contiguous())
result.append(self.one2one_cv2[i](x[i]).permute(0, 2, 3, 1).contiguous())
return result
# bboxes = [self.one2one_cv2[i](x[i]).permute(0, 2, 3, 1).contiguous() for i in range(self.nl)]
# clses = [self.one2one_cv3[i](x[i]).permute(0, 2, 3, 1).contiguous() for i in range(self.nl)]
# return (bboxes, clses)
我们再开一个新的python文件,把这串代码复制进去。
from ultralytics import YOLO
YOLO('你的pt文件的路径').export(imgsz=640, format='onnx', simplify=True, opset=11)
然后我们就得到了一个后续用于模型转换的onnx模型文件
然后我挂一篇博客,后面提到了准备校准数据集的方法,末尾挂了代码。这篇博客还提到了另外一篇大神的文章,对BPU感兴趣的可以去看看,但注意,里面的东西是面向x3的,具体的操作不要搬过来,领会精神就好。-
流程可以参考,但是推理代码按我后面的来,他的是yolov11的
在输出你的校准数据集之前,我们先找一个文件夹用来放你的模型文件和校准数据集,你找一个空一点的地方开一个新的文件夹就行,到时候我们要把它们都挂载进docker里。
这里简单地不太严谨解释一下吧,我们的docker镜像本质是在我们的电脑里放了一个容器,跟我们的电脑是相对独立的。然后我们对文件进行的处理需要依赖这个容器里的环境,但是文件不在里面啊,我们就要想办法把文件放进去处理好,再拿出来。
于是我们就需要把我们电脑里的文件夹挂载进去,这样在docker里面可以操作我们电脑的文件,而操作得到的结果也可以回到我们的电脑中,都在这个文件夹里面实现。
然后我们把校准数据集和模型文件都放进去,这个时候我们创建一个新的yaml文件,就是新建文件后缀改为yaml就好了,这个时候你的文件夹里应该有onnx模型文件,yaml文件,数据集文件夹。
可以参考我的yaml文件,但最好是直接看前面提到github里面的yaml文件(nv12的)-
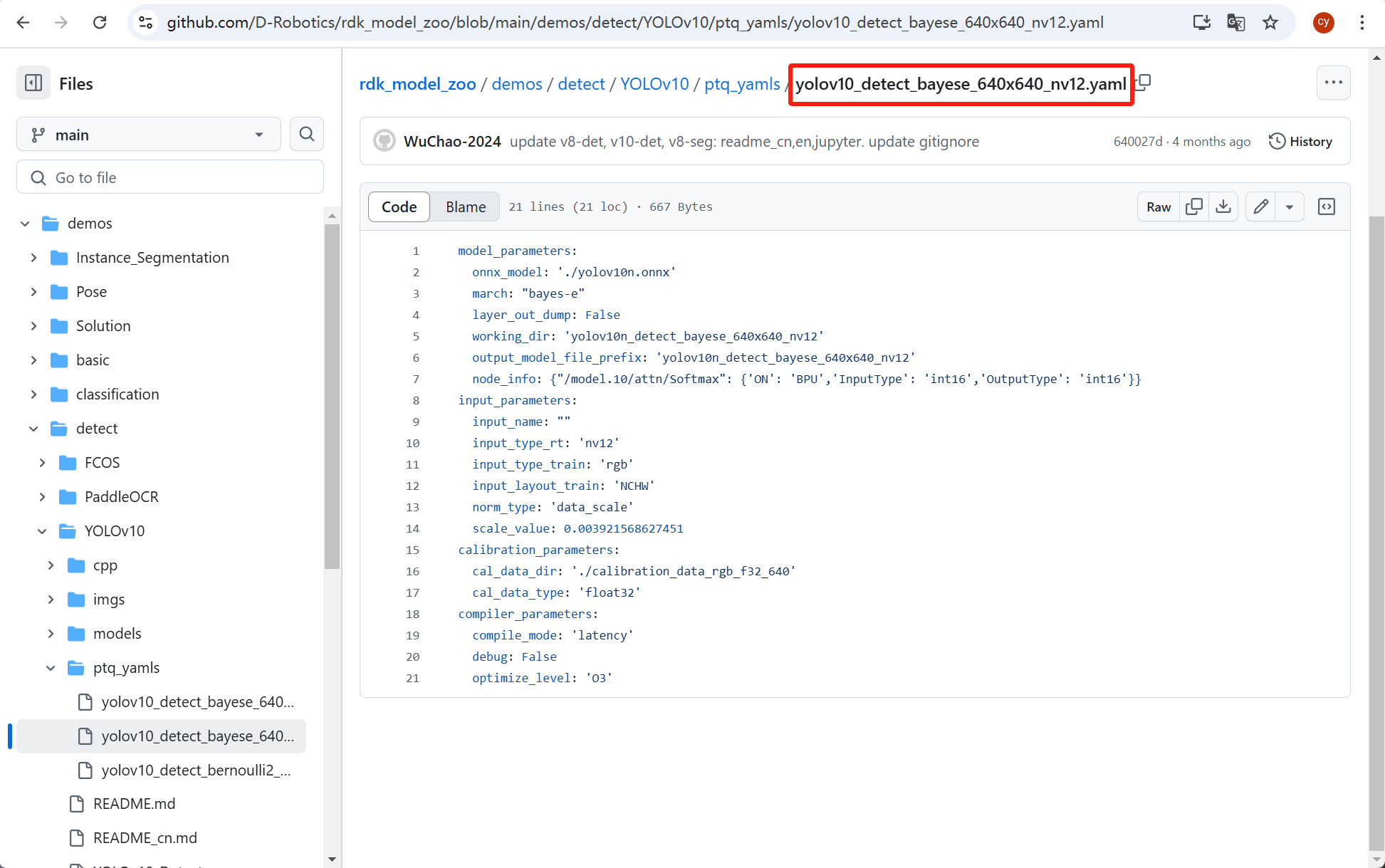
model_parameters:
onnx_model: './L_mix_800.onnx' # 你onnx模型文件的路径
march: "bayes-e" # 不用改,这个参数的意思是板子的BPU架构
layer_out_dump: False
working_dir: 'yolov10l_mix_bayes-e_640x640_nv12' # 输出的文件夹名字
output_model_file_prefix: 'L_mix_800' # 输出的bin文件名
node_info: {"/model.10/attn/Softmax": {'ON': 'BPU','InputType': 'int16','OutputType': 'int16'}} # 需要更改的节点,后面会提到,但是大概率是不用变的
input_parameters:
input_name: ""
input_type_rt: 'nv12'
input_type_train: 'rgb'
input_layout_train: 'NCHW'
norm_type: 'data_scale'
scale_value: 0.003921568627451
calibration_parameters:
cal_data_dir: './blinary' # 你的校准数据集的路径
cal_data_type: 'float32'
compiler_parameters:
compile_mode: 'latency'
debug: False
optimize_level: 'O3'
如果,你想了解更多的参数和具体的意思,去地平线的算法工具链的手册的6.2.2.2.3配置文件模版里面看。链接我会放在最后。-
(知道为什么我说是散装教程了吧)
2.2、部署docker镜像并挂载文件夹
打开命令行,win+R写入cmd回车进入,然后找到你下载好的镜像文件,输入以下命令-
docker load -i 你的镜像文件地址,一直到文件,以.tar.gz收尾
GPU要等挺久的,印象里有十分钟左右,等不及了可以按一下回车看看当前情况,但建议安心等着,除非过了半个小时,那就Ctrl+c强行终止再来一次。先别着急关你的命令行,还要用的。
加载好了之后你的docker的image界面应该是可以看到这个镜像的,启动它,按过就可以了,不用在意为什么图标变回去了。(因为我在意这玩意儿捣鼓了半个小时发现已经启动了)
回到命令行,根据图片里的命令键入进去就好了,这张图来自地平线算法工具链手册,链接会放末尾。-
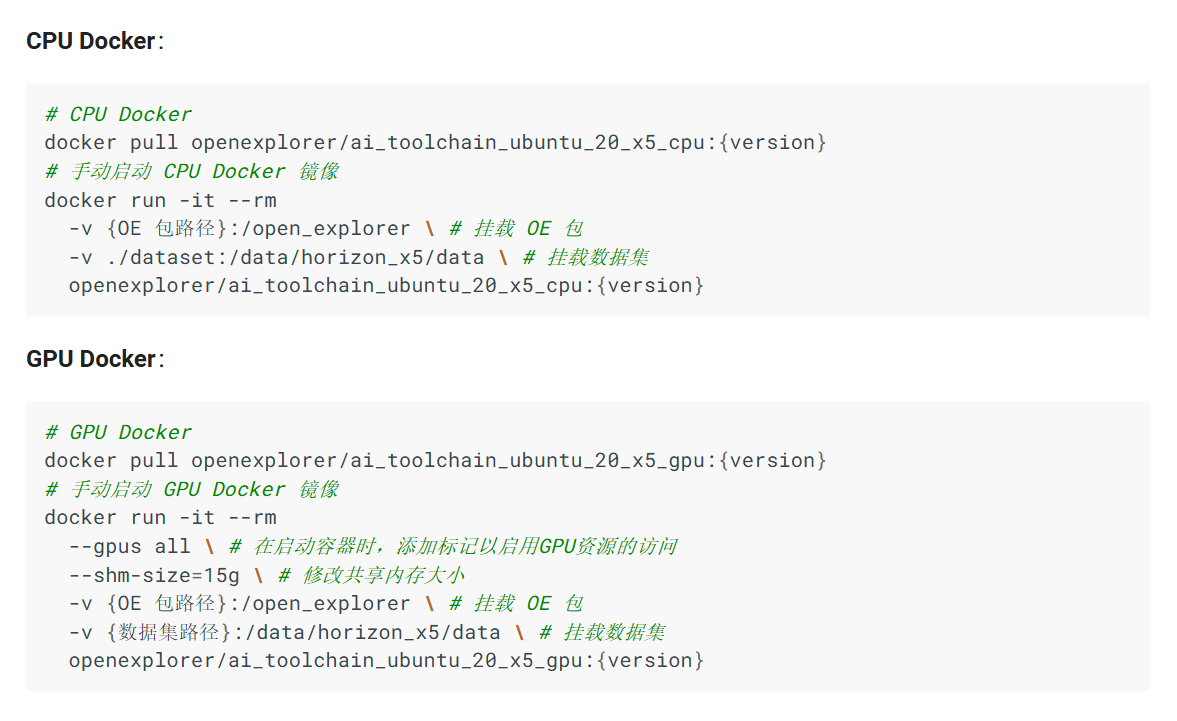
cpu的
docker run -it --rm -v 你的OE包路径:/open_explorer -v 我们要挂载的文件夹的路径:/data/horizon_x5 你docker里Image界面镜像的名字(样式参考图片)
gpu的
docker run -it --rm --gpus all --shm-size=15g -v 你的OE包的路径:/open_explorer -v 我们要挂载的文件夹的路径:/data/horizon_x5 你docker里Image界面镜像的名字
我就不分行了,容易出错,复制下来改好之后再放进命令行里
当你加载完后看到了
就说明OK了,可以直接开始操作了。
2.3、模型转换
docker加载进来一开始会在算法工具链的文件夹里,我们先出来,进到/data/horizon_x5里面,你的三个文件应该都在里面(不会Linux命令的查一查就好了)-
比如之前的我
2.3.1、模型检验
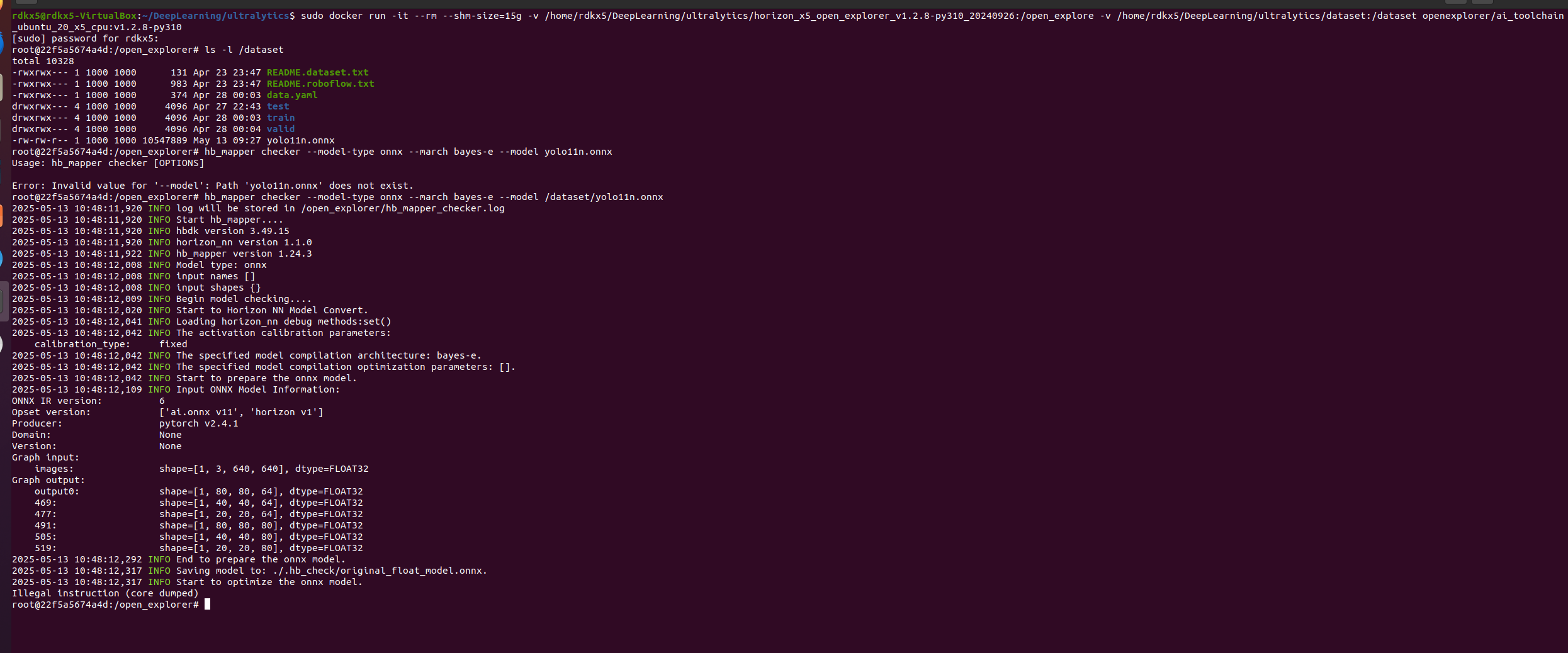
首先我们来检查我们的onnx模型是否符合要求,写入以下命令:-
hb_mapper checker --model-type onnx --march bayes-e --model 模型名字.onnx
然后你就会看到好长好长的INFO信息,你只需要关注有没有ERROR出现就好了,没有说明你的模型是正常,如果有报错,那就倒回去看看你到底是哪个流程没搞对。
- ultralytics卸载没有
- 输出头更改没有
- yaml文件写的对不对
- 进netron的网站把你的模型扔进去看看是不是六个输出头
如果都看了没问题还是寄了……-
出门左转地平线论坛捞技术人员吧,我的寄术搞不定(我倒.jpg
尤其关注一个地方:
/model.10/attn/MatMul BPU id(0) HzSQuantizedMatmul int8/int8
/model.10/attn/Mul BPU id(0) HzSQuantizedConv int8/int32
/model.10/attn/Softmax CPU -- Softmax float/float
/model.10/attn/Transpose_1 BPU id(1) Transpose int8/int8
/model.10/attn/MatMul_1 BPU id(1) HzSQuantizedMatmul int8/int8
model.10的Softmax,确认清楚这个使用CPU的算子名字是不是和前面yaml文件里的那个一模一样,因为就是要动它,把它改为使用BPU进行计算。
就是这句:-
node_info: {"/model.10/attn/Softmax": {'ON': 'BPU','InputType': 'int16','OutputType': 'int16'}} # 需要更改的节点,后面会提到,但是大概率是不用变的-
如果你的不一样,第一个大扩号里面的名字“/model.10/attn/Softmax”改成你的日志里面的名字,其他不要动。
虽然大概率是一样的。
2.3.2、转换为bin
如果顺利通过了检验,我们接着在命令行里写入以下命令:-
hb_mapper makertbin --model-type onnx --config 你的yaml文件名(不是路径,带上后缀)-
好,我们又可以看到很长很长的日志
一般来讲能过检验就不会在这里报错了……-
(报错了去摇工程师.jpg)
Windows环境下要挺久的,去吃个饭吧,吃完饭回来就好了。-
Linux环境下会快很多,但是没有也没关系,不影响后续操作。
吃完饭了回来了,现在你的文件夹里应该还有一个文件夹,就是你yaml文件里设置的那个名字(大概率也就多那一个)你的bin模型文件就在里面,
现在我们要对这个模型做进一步的检查和处理,流程参照gituhub的readme文件。
首先我们要检查整一个bin文件的输出头,命令行写入以下命令,注意你的路径要有bin文件。-
hb_model_modifier 你的bin模型文件名(包括后缀
这个时候bin模型在的文件夹里应该会出现一个新的文件‘hb_model_modifier.log’,点进去,找到里面带dim:64的输出头,位置在很靠前的地方,比如我这里就是
2024-12-09 12:56:38,181 file: hb_model_modifier.py func: hb_model_modifier line No: 403 name: "870"
type {
elem_type: FLOAT
dim: 1
dim: 80
dim: 80
dim: 64
}
这种输出头一共有三个,记住它的name,比如这里是870,还有另外两个。
然后往下滑,划到大概中间位置,看到这一大串的时候。
2024-12-09 12:56:38,186 file: hb_model_modifier.py func: hb_model_modifier line No: 407 --------node----------
2024-12-09 12:56:38,187 file: hb_model_modifier.py func: hb_model_modifier line No: 409 input: "images"
output: "/model.23/one2one_cv2.0/one2one_cv2.0.2/Conv_output_0_quantized"
output: "/model.23/one2one_cv3.0/one2one_cv3.0.2/Conv_output_0_quantized"
output: "/model.23/one2one_cv2.1/one2one_cv2.1.2/Conv_output_0_quantized"
output: "/model.23/one2one_cv3.1/one2one_cv3.1.2/Conv_output_0_quantized"
output: "/model.23/one2one_cv2.2/one2one_cv2.2.2/Conv_output_0_quantized"
output: "/model.23/one2one_cv3.2/one2one_cv3.2.2/Conv_output_0_quantized"
name: "torch_jit_subgraph_0"
op_type: "BPU"
它的下面就是我们要找的,你就可以看到这个东西。
2024-12-09 12:56:38,187 file: hb_model_modifier.py func: hb_model_modifier line No: 409 input: "/model.23/one2one_cv2.0/one2one_cv2.0.2/Conv_output_0_quantized"
input: "/model.23/one2one_cv2.0/one2one_cv2.0.2/Conv_x_scale"
output: "870"
name: "/model.23/one2one_cv2.0/one2one_cv2.0.2/Conv_output_0_HzDequantize"
op_type: "Dequantize"
attribute {
name: "axis"
type: INT
i: 3
}
attribute {
name: "output_data_format"
type: STRING
s: "NHWC"
}
attribute {
name: "num_args"
type: INT
i: 2
}
它的output是870,说明是我们要找的那个,把它的name记下来。-
“/model.23/one2one_cv2.0/one2one_cv2.0.2/Conv_output_0_HzDequantize”
再往下看,一共三个,都要记下来。再和下面命令的后三行对比,不一样的改成你的,一样就不用管了,把你的bin文件写上去,移除掉这三个输出头的反量化节点。然后会生成一个新的bin文件。
hb_model_modifier 你的bin文件 \
-r "/model.23/one2one_cv2.0/one2one_cv2.0.2/Conv_output_0_HzDequantize" \
-r "/model.23/one2one_cv2.1/one2one_cv2.1.2/Conv_output_0_HzDequantize" \
-r "/model.23/one2one_cv2.2/one2one_cv2.2.2/Conv_output_0_HzDequantize"
我们再检查一下新模型的输出头信息,命令行写入以下命令:-
hrt_model_exec model_info --model_file 你的bin文件
看一看是不是有其中三个输出头它的scale data特别特别长,如果是,那就对了。然后别急着跑,这记住这些被移除反量化节点的输出头是output[几],后面用得上的。
output[0]:
name: output0
valid shape: (1,80,80,64,)
aligned shape: (1,80,80,64,)
aligned byte size: 1638400
tensor type: HB_DNN_TENSOR_TYPE_S32
tensor layout: HB_DNN_LAYOUT_NHWC
quanti type: SCALE
stride: (1638400,20480,256,4,)
scale data: 0.000208803,0.000214107,0.000245535,0.000279321,0.000208999,0.000179928,0.000128562,0.000169321,9.2223e-05,0.000111276,7.99953e-05,5.43123e-05,6.85534e-05,6.40355e-05,6.09909e-05,8.82944e-05,0.000287374,0.000205464,0.000225303,0.000201044,0.000191517,0.000163625,0.000184151,0.000145455,0.000161758,8.65265e-05,9.61024e-05,8.69194e-05,8.22051e-05,6.90445e-05,5.69641e-05,7.30221e-05,0.000230214,0.000232178,0.000212928,0.000225892,0.000184839,0.00017708,0.000186803,9.02587e-05,0.000122276,8.13703e-05,6.96337e-05,7.62141e-05,7.65087e-05,6.11873e-05,5.10713e-05,6.89953e-05,0.000203892,0.00020841,0.000178946,0.000180714,0.000156357,0.000166866,0.000158419,0.000115794,0.000156848,9.75756e-05,7.8915e-05,7.6656e-05,6.73748e-05,5.93704e-05,5.08258e-05,7.09105e-05,
quantizeAxis: 3
长上面这样,记住最开头的那个ouput[0],一共三个这样的输出头,记住这些数字,后面要改推理代码的。
好,如果上述你非常顺利的完成了下来,那离成功就不远了。
2.4、模型上板
怎么把模型拷进板子里,U盘还是SSH,怎么下载怎么启动程序我就不管了.jpg
总之我们现在要把下载RDKx5的模型仓库下进板子里,我直接挂链接了,这个按官方的操作就好,没啥问题的。(たぶん……)-
RDKx5开发手册(散装啊散装)
下好了,我们直接进去YOLOv10的文件夹,里面的Detect那个py文件就是我们用的代码,把它复制出来,我们在它的基础上魔改就好。
不过这个是要启动摄像头的,理论上你不动它的推理部分的代码,其他地方你是读取视频还是读取图片可以自己发挥,自己debug就是了。
我们开始魔改代码,除了标记了的地方,其他可以不用动。爱折腾的搞就对了,实在不行还能摇人。
arser = argparse.ArgumentParser()
parser.add_argument('--model-path', type=str, default='改成你的模型文件路径',
help="""Path to BPU Quantized *.bin Model.
RDK X3(Module): Bernoulli2.
RDK Ultra: Bayes.
RDK X5(Module): Bayes-e.
RDK S100: Nash-e.
RDK S100P: Nash-m.""")
# parser.add_argument('--test-img', type=str, default='/home/sunrise/a_shoe/shoe2.jpg', help='Path to Load Test Image.')
# parser.add_argument('--img-save-path', type=str, default='jupyter_result.jpg', help='Path to Load Test Image.')
parser.add_argument('--classes-num', type=int, default=改成你的类个数, help='Classes Num to Detect.')
parser.add_argument('--reg', type=int, default=16, help='DFL reg layer.')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IoU threshold.')
parser.add_argument('--conf-thres', type=float, default=0.3, help='confidence threshold.')
coco_names = [
按照他的格式改成你的东西,注意要和你训练yolo模型时的检测类的先后顺序一致,不然检测标签会打错。比如我的:
"cred", "cyellow", "cgreen", "pred", "cgreen"
]
接下来就是我前面提到的要记住的几个特别的输出头起作用的地方,也包括一些标记的地方要改。-
我的特殊输出头是0,2,4这三个,所以outputs选择的就是[0], [2], [4]。而不是原本的0,1,2。
又因为我们一开始调换了cv3和cv2的位置,所以你们也有可能是1,3,5。没有关系,把特殊的写上去就好了。
class YOLO11_Detect(BaseModel):
def __init__(self,
model_file: str,
conf: float,
iou: float
):
super().__init__(model_file)
# 将反量化系数准备好, 只需要准备一次
# prepare the quantize scale, just need to generate once
self.s_bboxes_scale = self.quantize_model[0].outputs[0].properties.scale_data[np.newaxis, :]
self.m_bboxes_scale = self.quantize_model[0].outputs[2].properties.scale_data[np.newaxis, :]
self.l_bboxes_scale = self.quantize_model[0].outputs[4].properties.scale_data[np.newaxis, :]
logger.info(f"{self.s_bboxes_scale.shape=}, {self.m_bboxes_scale.shape=}, {self.l_bboxes_scale.shape=}")
这里三句代码的意思是从这三个输出头中取出三个反量化系数。我们之前的操作是对这三个输出头移除了反量化节点,因此就会有反量化系数留下来,这里就要把它取出来。-
至于你问我为什么取出来,有什么用……-
不要为难一只蒟蒻好吗……
def postProcess(self, outputs: list[np.ndarray]) -> tuple[list]:
begin_time = time()
# reshape
s_bboxes = outputs[0].reshape(-1, 64)
m_bboxes = outputs[2].reshape(-1, 64)
l_bboxes = outputs[4].reshape(-1, 64)
s_clses = outputs[1].reshape(-1, 你检测类的个数)
m_clses = outputs[3].reshape(-1, 你检测类的个数)
l_clses = outputs[5].reshape(-1, 你检测类的个数)
这里是为了让输出头可以和代码对齐进行的修改,可以回顾一下之前的hb_model_modifier.log-
你会发现六个输出头的结尾分别是64,和你设置的检测类的个数,所以我们在这里要让他对齐。保证取出来的东西没有发生错位。错位了要么就检测不到,要么就检测框乱飞。-
(你猜我为什么又知道)-
按顺序由上往下填就好了,上面一半是反量化的输出头,下面一般是没有处理过的输出头。
现在你可以试着在这个基础上,编写你自己的main函数,运行你自己的python代码了,不论是读入视频也好,读入图片也好,启动摄像头也好,自由发挥,模型推理应该是没有问题了。
2.5、使用tros部署yolov10
如果你成功跑起来了,那恭喜你完成了复现。接下来怎么魔改可以去找找其他大佬的文章或者有大佬指点也行,总之我这个蒟蒻魔改的水平有限……(くそっ,ここまでですか)
你跑起来的时候应该会发现当你开到1080p的时候帧率巨低,但是地平线宣传的时候可不是这么说的哦。这里应有某个表情包(#¥*,退钱!.jpg)
这其实是我们应用的方法导致的,python就是这么慢,这里就必须在请出前面提到过的一位大佬的另一篇文章文章,为表敬意,我再挂在这里。-
BPU部署教程,万字长文!通透解读模型部署端到端大流程——以终为始,以行为知
里面提到了用C++部署,速度会快很多。蒟蒻身边有人试过了,据说能有一百多帧……-
(やっぱり、何もできないんですか)
而提高帧率还有一种方法,就是使用tros部署我们的yolov10,官方也有提到过这部分内容。-
挂一篇超哥的文章,流程可以参考,具体操作不照搬,那是v8的
确认好你的RDKx5的板子是最新的系统,以及已经更新过源了,没有的话我把命令挂在这里。
sudo apt update
sudo apt upgrade
RDK_x5的开发手册里第五部分就是关于tros的,但是我不建议全盘照搬,尤其是前面系统安装,现在你只要完成前面两条命令的更新,你应该是可以在根目录找到opt这个文件夹的。不用再按教程走安装了,装不了的,似乎是文档没更新。-
(又是半个小时.jpg)
然后把板子里opt里面的的config文件夹复制出来,注意你的路径,复制到你当前在的路径里的。-
cp -r /opt/tros/humble/lib/dnn_node_example/config .
然后你应该是可以在当前路径看到一个config文件夹,点进去之后应该会有一个’yolov10workconfig’和一个coco.list文件,复制一份出来自己修改,可以参考我的配置。
workconfig
{
"model_file": "/home/sunrise/Downloads/L_mix_tros.bin", # 你的模型的路径
"dnn_Parser": "yolov10", # 你用的yolo的版本
"model_output_count": 6,
"reg_max": 16,
"class_num": 5, # 你的检测类的个数
"cls_names_list": "config/light.list", # 你的list文件路径
"strides": [8, 16, 32],
"score_threshold": 0.25,
"top_k": 300
}
coco.list文件按照它的格式去写就好了,记得要和你的最前面训练模型时检测类的顺序一致。
首先配置tros.b环境-
source /opt/tros/humble/setup.bash
配置USB/MIPI摄像头 (选其中一个就好)-
export CAM_TYPE=usb/mipi
启动launch文件-
ros2 launch dnn_node_example dnn_node_example.launch.py dnn_example_config_file:=你的config文件路径
在PC端的浏览器输入http://IP:8000 即可查看图像和算法渲染效果(IP为RDK的IP地址)
3、结语和参考资料
到此我玩RDK_5一个多月的进程算是结束了,基本都是复现,魔改的地方比较浮于表面,比如说利用c++部署,比如说深入tros看看到底是怎么启用的,留给以后的自己吧。
最后,衷心希望我这一个多月积累下来的这一篇短短的博客能够为碰到问题的小伙伴提供一些帮助,若是文中存在错漏之处敬请斧正,帖主蒟蒻顿首.jpg
开源万岁,互联网精神万岁。
RDK_model_zoo_README-
地平线x5算法工具链手册-
RDKx5开发手册
到此应该把官方的参考资料都挂齐了,若有补充就更好了。-
其他版本的yolo模型部署上板可以先去modelzoo的github上面看,有的话用官方的README作参考,会好一些。