前言
今年,人形机器人和机器狗频频出圈,成为热门话题。而对于这类机器人而言,运动控制无疑是核心技术之一。强化学习作为当前运动控制的主要方法之一,恰好也能充分发挥 RDK 系列板卡在模型推理方面的优势。因此,我们尝试在 RDK S100 上部署强化学习模型,并探索其在实际机器人平台上的应用。
本次实验机器人采用宇树科技的 Go2 机器狗,推理设备采用RDK S100(MLP模型小,资源占用极少,具体可见文末的资源占用),并选择复现 walk-these-ways-go2 项目。该项目基于 Walk These Ways 论文,该论文于 2022 年发表于_Conference on Robot Learning_。论文作者提出了一种新方法,即学习一个单一策略,该策略能够编码一组结构化的运动策略组,从不同角度解决训练任务。这种方法被称为行为多样性(Multiplicity of Behavior, MoB)。不同的运动策略在泛化能力上各有优势,使得机器人能够在实时任务或新环境中选择最合适的策略,而无需耗时的重新训练。此外,该项目提供了完整的工程实现,适合作为复现与优化的基础,因此我们最终选择了该方案进行部署与测试。整体流程分为三步:模型训练-—>模型量化-—>板端部署
1.模型训练
1.1 训练资源参考

1.2 环境搭建
搭建环境前请确认以下几点:
1. 确认用于训练的设备有GPU,且建议至少有8GB的显存(若希望看到训练过程,请使用带桌面的设备)
2. 确认显卡驱动已安装,且能够正常使用
3. 确认CUDA已安装,且能够正常使用
4. 建议安装使用conda。避免环境冲突
5. 显卡驱动、CUDA、conda安装可直接参考网上教程,此处不做赘述
#conda创建并激活环境,该工程使用python3.8环境,未尝试3.10
conda create -n IsaacGym python=3.8
conda activate IsaacGym
#下拉代码并安装所需软件
git clone https://github.com/wunuo1/RDK-walk-these-ways-go2.git -b s100
cd RDK-walk-these-ways-go2
pip install -e .
#下载IsaacGym并放到训练环境中解压,https://developer.nvidia.com/isaac-gym
#安装使用IsaacGym,可参考https://junxnone.github.io/isaacgymdocs/install.html
tar zxvf IsaacGym_Preview_4_Package.tar.gz
cd isaacgym/python
pip install -e .
pip show isaacgym
#torch与CUDA有版本对应关系,可从该链接查询并安装对应的版本(CUDA版本查询:nvcc -V)
conda install pytorch==2.4.1 torchvision==0.19.1 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install ml-logger ml-dash --upgrade --no-cache
1.3 训练
若不希望可视化训练过程,请在train.py的env = VelocityTrackingEasyEnv(sim_device='cuda:0', headless=False, cfg=Cfg)中设置headless=True 若期望看到训练过程,请将headless=False(系统有显示桌面),但开启显示会占用训练资源,导致训练速度下降。
无论是否开启可视化,训练过程中会有视频保存,路径RDK-walk-these-ways-go2/runs/gait-conditioned-agility/xxxx-xx-xx/train/xxxxxx/videos
#num_envs:训练环境中机器人个数(若显存不够,则减少数量,train.py的train_go2函数中增加Cfg.env.num_envs = xxx)
#num_learning_iterations:训练轮数(runner.learn(num_learning_iterations=10, init_at_random_ep_len=True, eval_freq=100))
python scripts/train.py
#训练完成后设置play.py中的模型路径和配置文件路径,可查看训练效果
python scripts/play.py
1.4 数据可视化
#可视化训练过程的各项奖励的数值变化
#开启新终端,开启ml_dash前端,默认占用3001端口
python -m ml_dash.app
#开启另一个终端,进入RDK-walk-these-ways-go2文件夹,打开ml_dash服务,默认占用8081
python -m ml_dash.server .
#打开浏览器,输入localhost:3001,等待界面开启
#用户名:runs API:http://localhost:8081 访问令牌:不用输入
#点击新生成的Profile,选择想看到的训练数据,点击红框位置显示各项奖励的数值变化
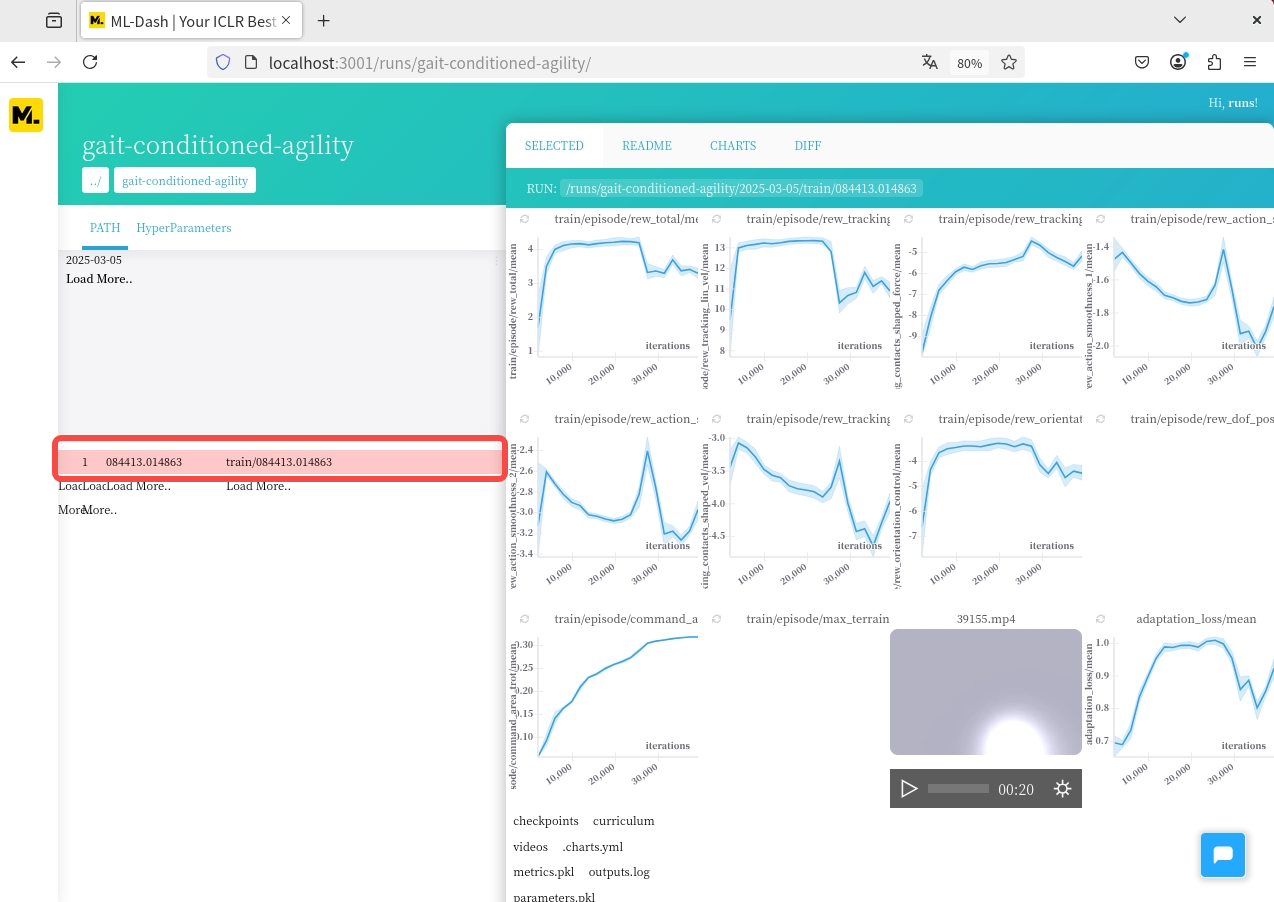
1.5 获取模型并导出onnx文件
训练过程中会保存不同迭代次数的ac_weights、最新的ac_weights、最新的adaptation_module模型和最新的body模型,所以需要提取效果最好的adaptation_module模型和body模型(实验大概在两万四千轮左右获得总奖励最高模型)
#运行tool文件夹下的tool.py,运行时指定要转换的ac_weights_xxxx.pt(根据数据选择总奖励最高,即rew_total最高值的ac_weights_xxxx.pt)的路径
#该脚本会从ac_weights_xxxx.pt中抽取出adaptation_module和body两个模型,并导出为onnx格式
python3 tool.py path_of_ac_weights_xxxx.pt
模型结构与数据处理流程如下:
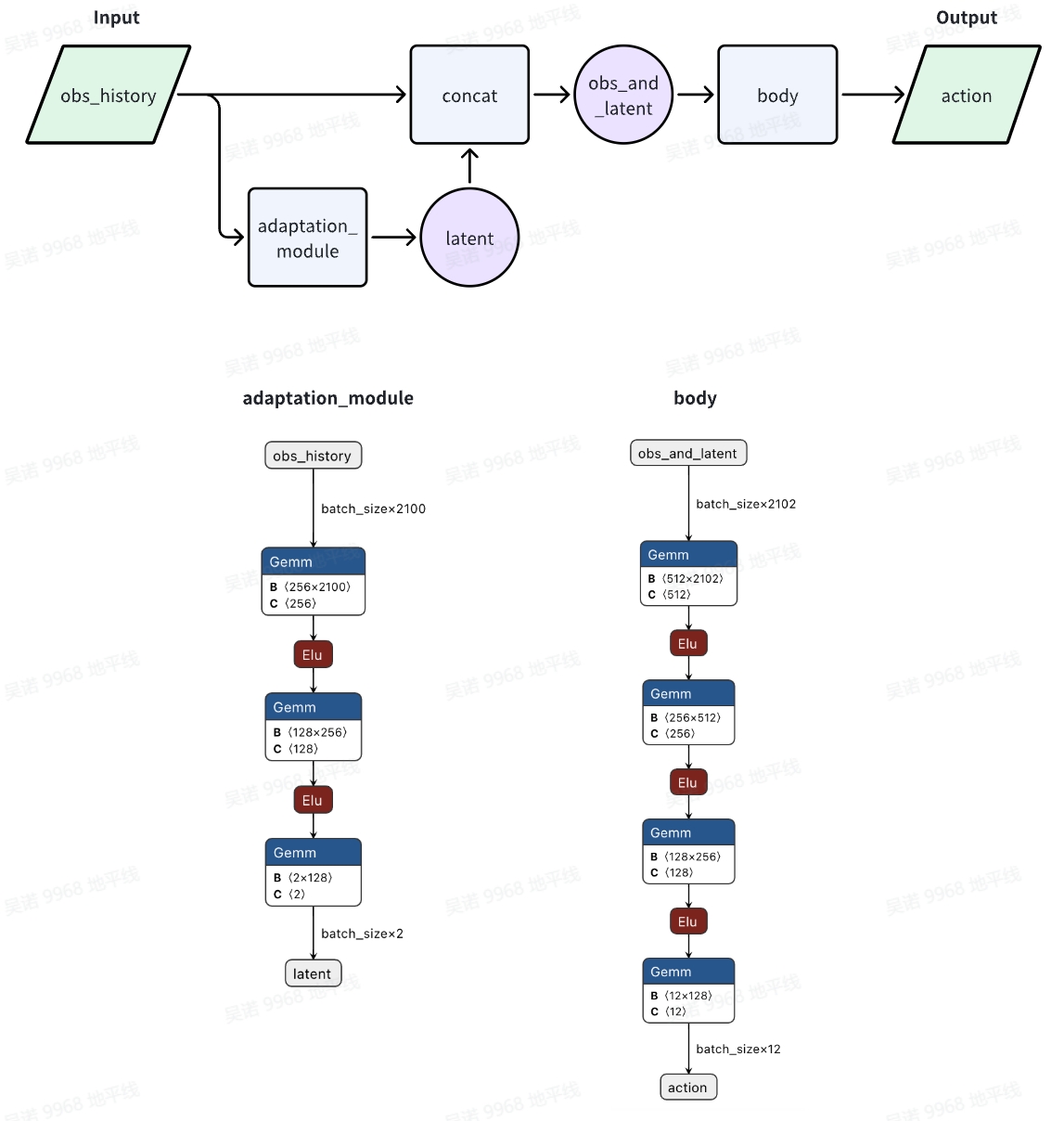
1.6 奖励函数说明

奖励函数位于RDK-walk-these-ways-go2/go2_gym/envs/rewards/corl_rewards.py,可仿照函数格式增加新的奖励函数(_reward_xxx),同时需要在RDK-walk-these-ways-go2/go2_gym/envs/base/legged_robot_config.py的reward_scales类中设置对应的权重系数(xxx),权重系数为0时,奖励不生效。
2. 模型量化
2.1 环境准备
#拉取S100工具链docker镜像([docker镜像与OE包](https://developer.d-robotics.cc/rdk_doc/rdk_s/Advanced_development/toolchain_development/overview/))
#拉取用于模型量化的文件夹解压,见文末附件(该文件夹中包含量化需使用的配置文件以及校准数据)
#将导出的onnx模型放到量化用的文件夹下(确保模型名称与配置文件中一致),并将该文件夹挂在至docker环境中,创建容器
sudo docker run -it --entrypoint="/bin/bash" -v 主机文件夹路径:/go2_model_convert_s100 镜像ID
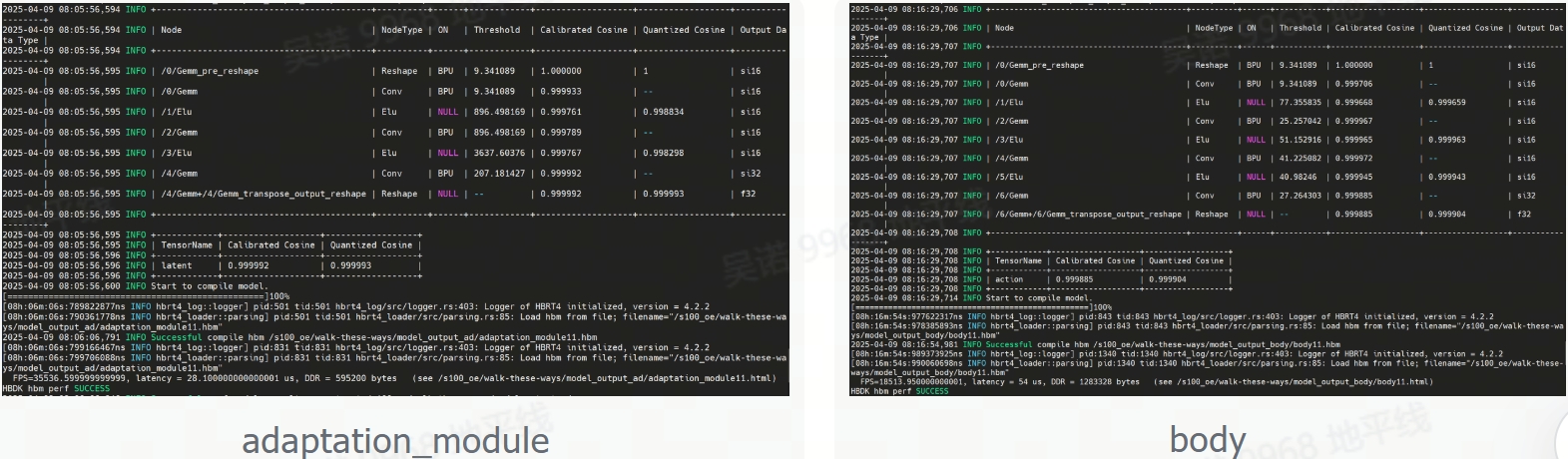
2.2 量化编译(Int16)
#进入文件夹
cd /go2_model_convert_s100
#量化adaptation_module,生成model_output_ad文件夹,存放.bin模型
hb_compile -c ad_config_bpu.yaml --march nash-e
#量化body,生成model_output_body文件夹,存放.bin模型
hb_compile -c body_config_bpu.yaml --march nash-e
3.板端部署
3.1 物料准备
3.1.1 物料清单

支架STL文件见RDK-walk-these-ways-go2的bracket文件夹
3.1.2 设备连接

3.2 环境准备
3.2.1 下拉代码,安装环境
git clone https://github.com/wunuo1/RDK-walk-these-ways-go2 -b s100
cd RDK-walk-these-ways-go2
pip install -e .
pip install torch==1.10.2 torchvision==0.11.3
3.2.2 编译lcm
git clone https://github.com/lcm-proj/lcm.git
cd lcm
mkdir build
cd build
cmake ..
make
sudo make install
3.2.3 编译Unitree SDK(使用RDK-walk-these-ways-go2中自带的SDK,宇树官方最新版本有接口变化)
cd RDK-walk-these-ways-go2/go2_gym_deploy/unitree_sdk2_bin/library/unitree_sdk2
rm -r build
sudo ./install.sh
mkdir build
cd build
cmake ..
make
3.2.4 编译lcm_position_go2
cd go2_gym_deploy
rm -r build
mkdir build
cd build
cmake ..
make -j4
3.2.5 通过网线接入四足狗
#设置静态IP,参考如下
vim /etc/netplan/01-hobot-net.yaml
eth0:
dhcp4: no
dhcp6: no
addresses:
- 192.168.123.100/24
gateway4: 192.168.123.1
#ping通四足狗,四足狗IP为192.168.123.161
ping 192.168.123.161
#查看网卡设置,确认网卡编号。我这里是eth0,用于后面启动lcm_position_go2功能
ifconfig
3.2.6 编译模型推理库
git clone https://github.com/wunuo1/model_task.git -b s100
cd model_task
mkdir build
cd build
cmake ..
make -j4
cp libmodel_task.so RDK-walk-these-ways-go2/go2_gym_deploy/scripts
3.3 运行
3.3.1 启动指令
#启动lcm_position_go2,用于与底层控制板通信,启动后根据log输出操作,按“Enter” ,注意:一定要Enter完,程序正常启动后在运行策略脚本
cd go2_gym_deploy/build
sudo ./lcm_position_go2 eth0
#另开一个终端,加载运行策略,启动后根据log输出操作,第一次按“R2” 变成静止站立状态,在次按“R2”开始控制
#提供onnx运行脚本,感兴趣可以使用deploy_policy_s100_onnx.py
python3 deploy_policy_s100.py
3.3.2 资源占用
3.3.2.1 使用bin模型推理
![]()
**模型推理+处理逻辑功能占用:**单核CPU 28.5%,内存 3.5%,BPU 1%
3.3.2.2 使用onnx模型直推
![]()
**模型推理+处理逻辑功能占用:**单核CPU 255.1%,内存 4.2%
更换int16模型后在CPU占用降低明显,BPU占用上升为1%。 两个模型在肉眼观测上运动效果无明显差别
3.3.3 效果展示
https://www.bilibili.com/video/BV154d2YTEn1/
4. 鸣谢
感谢地平线机器人实验室的大力支持!感谢王煜城、王凯辉二位的鼎力相助!
go2_model_convert_s100.zip (7.5 MB)