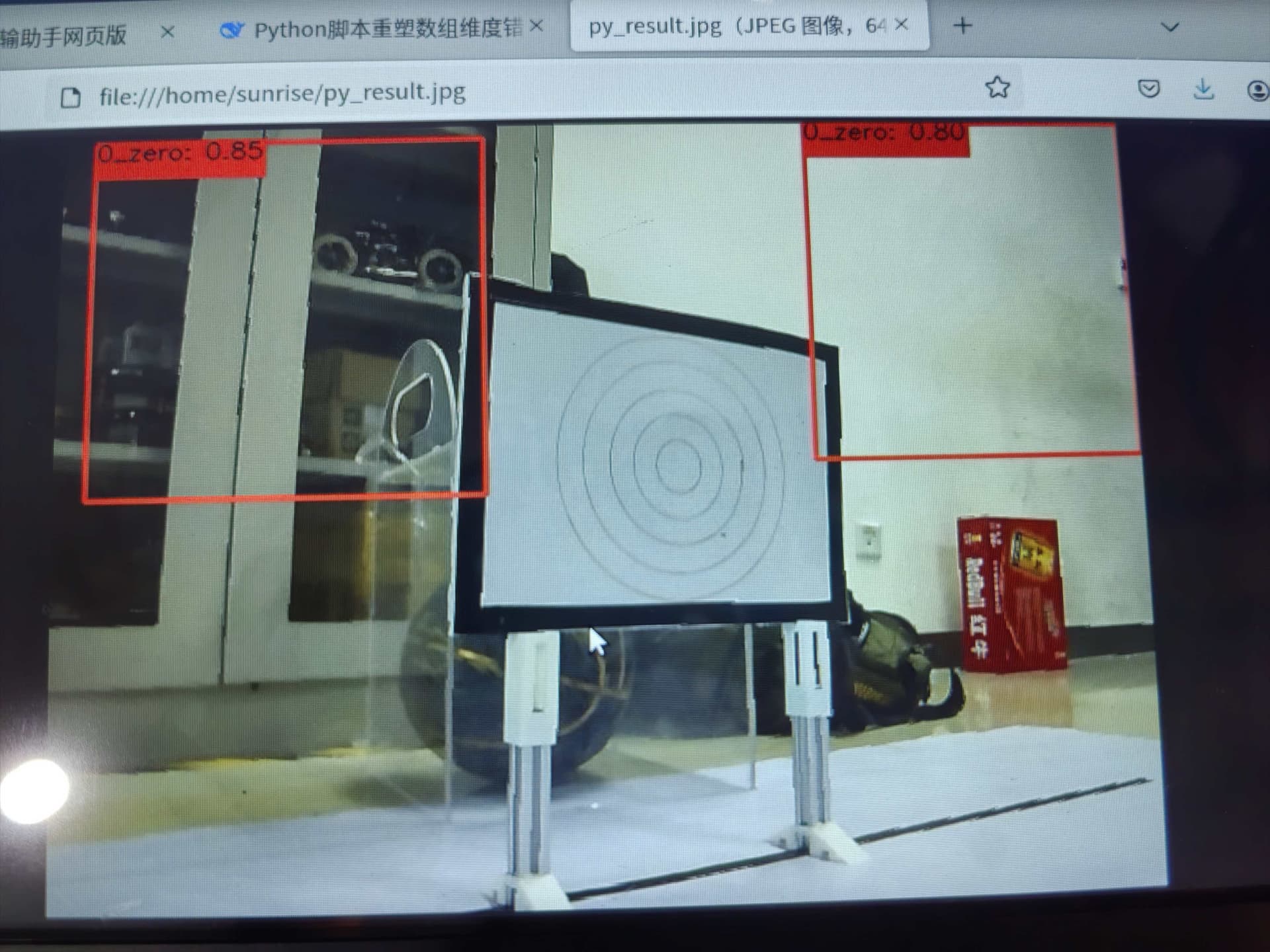
自训练的onnx可以成功识别机器人手上的零件,但是量化后的hbm的检测框都在图片上方
一、onnx模型信息
📥 输入信息:
- 输入名称: images
- 输入形状: [1, 3, 640, 480]
- 输入尺寸: 480x640
- 输入通道数: 3
📤 输出信息:
- 输出名称: ['output0']
- 输出数量: 1
- 输出0 (output0): [1, 8, 6300]
⚙️ 模型参数:
- 类别数量: 4
- 类别列表: ['part', 'labeled_part', 'part_in_hand', 'labeled_in_hand']
- 置信度阈值: 0.5
- IoU阈值: 0.45
🎨 颜色映射:
- part: RGB(0, 255, 0)
- labeled_part: RGB(0, 0, 255)
- part_in_hand: RGB(255, 0, 0)
- labeled_in_hand: RGB(0, 255, 255)
二、量化文件的使用
2.1 输入图像预处理: fix_uv_format_v3.py
root@ubuntu:/userdata/deploy_new# python3 fix_uv_format_v3.py test_img_new.jpg
处理图片: test_img_new.jpg
原始尺寸: 4000x3000
直接缩放后尺寸: 480x640 (宽x高)
目标尺寸: 480x640 (宽x高)
Y分量形状: (640, 480)
UV分量形状: (320, 480)
Y分量已保存: yolo11_input_y.bin ((640, 480)) - 307200 bytes
UV分量已保存: yolo11_input_uv.bin ((320, 480)) - 153600 bytes
2.2 编译并运行 :yolo11_board_test.cc
./yolo11_board_test yolo11_0724_new.hbm yolo11_input_y.bin yolo11_input_uv.bin 4000 3000
[UCP]: log level = 3
[UCP]: UCP version = 3.7.3
[VP]: log level = 3
[DNN]: log level = 3
[HPL]: log level = 3
[UCPT]: log level = 6
🎯 YOLO11 板端测试程序
📁 模型文件: yolo11_0724_new.hbm
📁 Y输入文件: yolo11_input_y.bin
📁 UV输入文件: yolo11_input_uv.bin
📏 原图尺寸: 4000x3000
============================================================
🔄 Step 1: 获取模型句柄...
[BPU][[BPU_MONITOR]][281473725593824][INFO]BPULib verison(2, 1, 2)[0d3f195]!
[DNN] HBTL_EXT_DNN log level:6
[DNN]: 3.7.3_(4.2.11 HBRT)
✅ 模型句柄获取成功
🔄 Step 2: 准备输入输出tensor...
输入tensor数量: 2
输出tensor数量: 1
输入0: [1, 640, 480, 1], 大小: 307200 bytes
输入1: [1, 320, 240, 2], 大小: 153600 bytes
输出0 (output0): [1, 8, 6300], 大小: 101376 bytes
✅ 输入输出tensor准备完成
🔄 Step 3: 设置输入数据到tensor...
Y分量数据复制完成
UV分量数据复制完成
✅ 输入数据设置完成
🔄 Step 4: 运行模型推理...
✅ 模型推理完成
🔄 Step 5: 保存输出数据到文件...
输出数据大小: 50688 个int16_t值
输出tensor形状: [1, 8, 6300]
实际有效元素数: 50400 个int16_t值
实际有效字节数: 100800 字节
对齐字节数: 101376 字节
填充字节数: 576 字节
✅ 输出数据已保存到: yolo11_output.bin
保存了 50400 个有效int16_t值
输出数据范围: [0, 32568]
前10个输出值: 258 517 775 1292 1809 2326 2585 3102 3360 3619
✅ 量化系数信息已保存到: yolo11_scale.txt
✅ 输出数据保存完成
🎯 推理完成,输出数据已保存
📁 输出文件: yolo11_output.bin
📁 输入文件: yolo11_input_y.bin, yolo11_input_uv.bin
📏 原图尺寸: 4000x3000
💡 请使用Python脚本进行后处理
🔄 Step 6: 释放所有资源...
✅ 所有资源释放完成
🎉 板端测试程序执行完成!
2.3 后处理: postprocess_hbm_output.py
识别效果:

具体输出为:
🎯 HBM模型输出后处理
============================================================
📁 输出文件: yolo11_output.bin
📏 原图尺寸: 4000x3000
🎯 置信度阈值: 0.6
🎯 IoU阈值: 0.45
🐛 调试模式: 开启
🖼️ 原始图像: test_img_new.jpg
🎨 可视化: 启用
============================================================
📁 读取输出文件: yolo11_output.bin
📊 读取到 50400 个int16_t量化值
🔄 开始反量化处理...
坐标反量化系数: 0.0193229
类别概率反量化系数: 0.0193229
反量化后数据范围: [0.000000, 629.308228]
✅ 输出数据读取成功
形状: (1, 8, 6300)
数据类型: float32
数据范围: [0.000000, 629.308228]
🔄 开始后处理...
原始输出形状:(1, 8, 6300)
输出数据类型:float32
输出数据范围:[0.000000, 629.308228]
📊 原始输出数据样本 (前5个anchor, 8维特征):
Anchor 0: [ 4.985308 0. 281.9018 201.36394 151.02779 0.
0. 0. ]
Anchor 1: [ 9.98994 0. 281.9018 201.36394 151.02779 0. 0.
0. ]
Anchor 2: [ 14.975247 0. 281.9018 191.2967 151.02779 0.
0. 0. ]
Anchor 3: [ 24.965187 0. 281.9018 191.2967 161.09502 0.
0. 0. ]
Anchor 4: [ 34.955128 0. 281.9018 191.2967 151.02779 0.
0. 0. ]
转置后形状:(6300, 8)
模型输出框数量:6300
坐标数据形状:(6300, 4)
类别概率形状:(6300, 4)
模型输出坐标范围:x∈[5.0, 469.5], y∈[0.0, 629.3]
宽高范围:w∈[0.0, 322.2], h∈[0.0, 249.7]
📊 前5个anchor的坐标和类别概率:
Anchor 0: 坐标=[ 4.985308 0. 281.9018 201.36394 ], 类别概率=[151.02779 0. 0. 0. ]
Anchor 1: 坐标=[ 9.98994 0. 281.9018 201.36394], 类别概率=[151.02779 0. 0. 0. ]
Anchor 2: 坐标=[ 14.975247 0. 281.9018 191.2967 ], 类别概率=[151.02779 0. 0. 0. ]
Anchor 3: 坐标=[ 24.965187 0. 281.9018 191.2967 ], 类别概率=[161.09502 0. 0. 0. ]
Anchor 4: 坐标=[ 34.955128 0. 281.9018 191.2967 ], 类别概率=[151.02779 0. 0. 0. ]
得分范围:[0.0000, 171.1622]
📊 前5个anchor的类别ID和得分:
Anchor 0: 类别ID=0, 得分=151.0278
Anchor 1: 类别ID=0, 得分=151.0278
Anchor 2: 类别ID=0, 得分=151.0278
Anchor 3: 类别ID=0, 得分=161.0950
Anchor 4: 类别ID=0, 得分=151.0278
过滤后保留框数量:108 (阈值=0.6)
开始坐标转换...
坐标转换完成,形状:(108, 4)
📊 前5个转换后的坐标 (xyxy格式,480x640范围内):
Box 0: [-135.96559 -100.68197 145.9362 100.68197]
Box 1: [-130.96095 -100.68197 150.94084 100.68197]
Box 2: [-125.97565 -95.64835 155.92615 95.64835]
Box 3: [-115.98571 -95.64835 165.91608 95.64835]
Box 4: [-105.99577 -95.64835 175.90602 95.64835]
/userdata/deploy_new/postprocess_hbm_output.py:282: RuntimeWarning: invalid value encountered in divide
return inter_area / union_area # IoU = 交集 / 并集
NMS后保留框数量:3 (IoU阈值=0.45)
🎯 最终检测结果:
1. part:坐标(-91,-95)-(220,95),中心(64,0),得分171.162
2. part:坐标(33,-95)-(355,95),中心(194,0),得分171.162
3. part:坐标(367,14)-(392,14),中心(379,14),得分161.095
✅ 后处理完成!
📊 检测到 3 个目标
============================================================
🎯 最终检测结果 (置信度 >= 0.5):
1. part: 置信度=171.162, 位置=(-91,-95)-(220,95)
2. part: 置信度=171.162, 位置=(33,-95)-(355,95)
3. part: 置信度=161.095, 位置=(367,14)-(392,14)
有效检测数量: 3/3
🎨 开始可视化...
✅ 成功读取原始图像: (3000, 4000, 3)
🎨 开始绘制检测结果...
原始图像尺寸: (3000, 4000, 3)
检测到 3 个目标
坐标转换比例: 宽=8.33, 高=4.69
1. part: 坐标(-758,-445)-(1833,445), 中心(533,0), 得分171.162
2. part: 坐标(275,-445)-(2958,445), 中心(1616,0), 得分171.162
3. part: 坐标(3058,65)-(3266,65), 中心(3158,65), 得分161.095
✅ 检测结果已保存到: hbm_detection_result.jpg
✅ 可视化完成!
📁 结果图像: hbm_detection_result.jpg
有没有成功部署yolo11模型的大佬解答一下是哪些步骤可能出错了呢?