![]() 感谢地平线工具链同学以及地瓜生态同学的大力支持
感谢地平线工具链同学以及地瓜生态同学的大力支持
SEM:RoboOrchardLab/projects/sem/robotwin at master · HorizonRobotics/RoboOrchardLab · GitHub
飞书文档:https://horizonrobotics.feishu.cn/wiki/CT0dwlRDMiHkTNkypBLcYAM7nsb
1. 模型导出
-
你需要自行准备好你的浮点模型
-
如果没有在安装 robo_orchard_lab 时 pip install . 加上 -e 参数,则修改源码后需要重新安装,因此建议加上 -e 参数,以确保修改的源码可以被同步
-
参考 RoboOrchardLab/projects/sem/robotwin/onnx_scripts/export_onnx.py at master · HorizonRobotics/RoboOrchardLab · GitHub 导出 onnx 模型
1.1 量化友好修改
针对开源仓库中的 RoboOrchardLab-master/projects/sem/robotwin/onnx_scripts/export_onnx.py 中需要做如下修改,以对量化友好:
- 具有物理含义的枚举型输入在不溢出的情况下维持 int8/int16 定点输入:joint_relative_pos 和 timestep
...
data["joint_relative_pos"] = data["joint_relative_pos"].to(torch.int8)
...
timestep = timestep.to(torch.int16)
...
- 去除量化不友好的数值,对应修改两处,将
float("-inf")改-15:
- RoboOrchardLab/robo_orchard_lab/models/sem_modules/layers.py at 3c8897ddaa169a4d7e8ad9e9894671e686f25c84 · HorizonRobotics/RoboOrchardLab · GitHub
- RoboOrchardLab/robo_orchard_lab/models/sem_modules/layers.py at 3c8897ddaa169a4d7e8ad9e9894671e686f25c84 · HorizonRobotics/RoboOrchardLab · GitHub
- 导出 onnx 模型
python3 onnx_scripts/export_onnx.py \
--config config_sem_robotwin.py \
--model /your/float_model_dir/ \
--output_path /your/onnx_model \
--num_joint 14 \
--validate
1.2 校准数据准备
在RoboOrchardLab-master/projects/sem/robotwin/onnx_scripts/export_onnx.py中添加代码如下,目的为导出 onnx 时 dump 模型部署的部分评测数据作为PTQ量化的校准数据,校准数据需经过前处理,样例代码如下:
def prepare_calib_data(dataset, data_processor, encoder, sample_dataset=True):
os.makedirs("calibration_data_dir", exist_ok=True)
for e_name in ENCODER_INPUT_NAMES:
os.makedirs(os.path.join("calibration_data_dir", e_name), exist_ok=True)
for d_name in DECODER_INPUT_NAMES:
os.makedirs(os.path.join("calibration_data_dir", d_name), exist_ok=True)
if sample_dataset:
new_dataset = []
# 均匀采样数据集,这里取100份数据作为校准数据(可调整)
num_samples = 100
indices = np.arange(0, len(dataset), len(dataset) // num_samples)[:num_samples]
for idx in indices:
new_dataset.append(dataset[idx])
dataset = new_dataset
for i in range(len(dataset)):
# 校准数据需经过前处理
data = data_processor(dataset[i])
# 对齐onnx导出时的输入信息
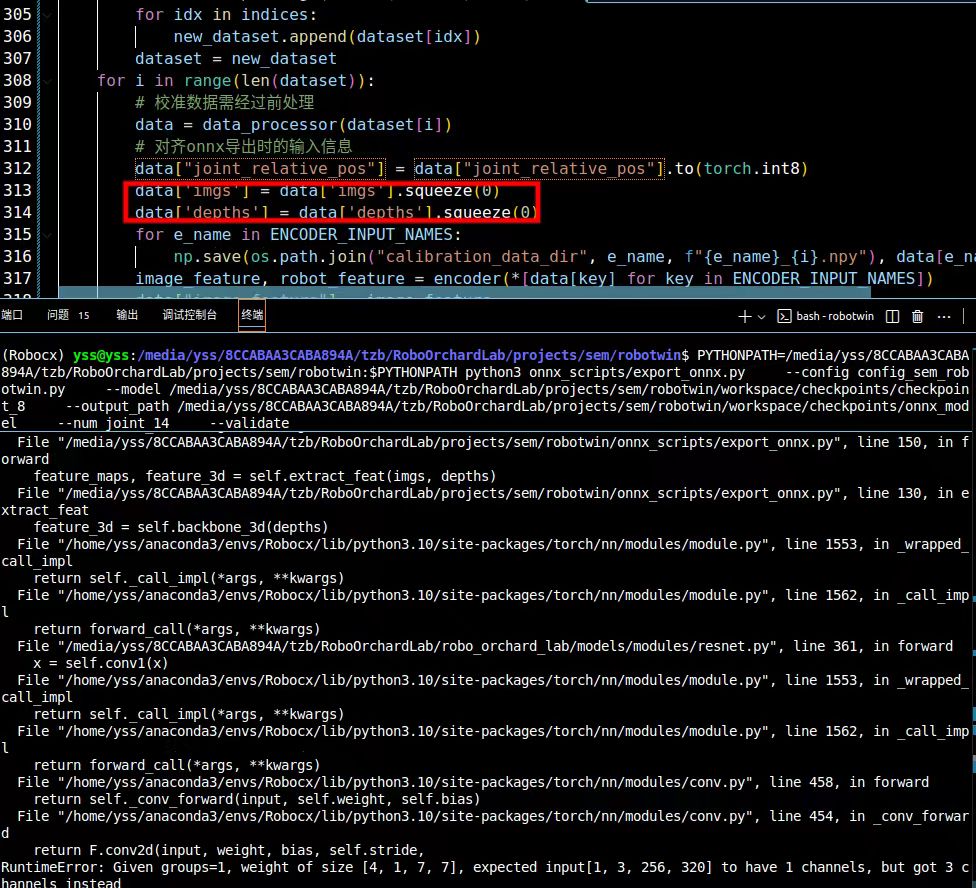
data["joint_relative_pos"] = data["joint_relative_pos"].to(torch.int8)
data['imgs'] = data['imgs'].squeeze(0)
data['depths'] = data['depths'].squeeze(0)
for e_name in ENCODER_INPUT_NAMES:
np.save(os.path.join("calibration_data_dir", e_name, f"{e_name}_{i}.npy"), data[e_name].cpu().numpy())
image_feature, robot_feature = encoder(*[data[key] for key in ENCODER_INPUT_NAMES])
data["image_feature"] = image_feature
data["robot_feature"] = robot_feature
data["timestep"] = torch.tensor([999], dtype=torch.int16)
for d_name in DECODER_INPUT_NAMES:
np.save(os.path.join("calibration_data_dir", d_name, f"{d_name}_{i}.npy"), data[d_name].cpu().numpy())
# 不采样的话默认取前200份数据作为校准数据
if not sample_dataset and i == 199:
break
logger.info("prepare calib data done")
def export_onnx(config, model, num_joint, output_path, validate=True):
# 原代码不变
prepare_calib_data(dataset, data_processor, encoder)
2. PTQ 量化
2.1 环境准备
- 建议使用算法工具链标准缴付的 docker(GPU) 环境,会在校准时调用 GPU 加速
docker run -itd \
--network host \
--gpus all \
--shm-size=15g \
-v {oe_dir_path}:/open_explorer \
-v {data_path}:/data// \
{docker_image_name}
2.2 校准数据准备
参考 1.2 节
2.3 校准 config 准备
- 参考:模型量化编译 - OpenExplorer
- 需要根据实际路径修改校准数据以及 onnx 路径,需要根据实际量化的需要调整量化精度,样例中给到的是全 int 16
# encoder config
calibration_parameters:
cal_data_dir: ./calibration_data_dir/imgs;./calibration_data_dir/depths;./calibration_data_dir/pixels;./calibration_data_dir/projection_mat_inv;./calibration_data_dir/hist_robot_state;./calibration_data_dir/joint_scale_shift;./calibration_data_dir/joint_relative_pos
quant_config: {
"model_config": {
"all_node_type": "int16"
}
}
compiler_parameters:
advice: 0
balance_factor: 0
cache_mode: enable
cache_path: 'cache'
compile_mode: latency
core_num: 1
jobs: 64
max_time_per_fc: 0
optimize_level: O2
input_parameters:
input_layout_train: NCHW;NCHW;NCHW;NCHW;NCHW;NCHW;NCHW
input_name: imgs;depths;pixels;projection_mat_inv;hist_robot_state;joint_scale_shift;joint_relative_pos
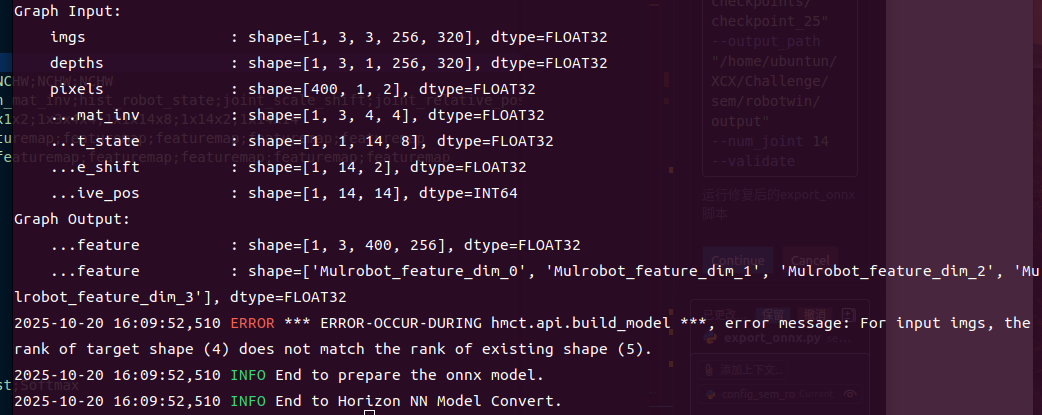
input_shape: 3x3x256x320;3x1x256x320;400x1x2;1x3x4x4;1x1x14x8;1x14x2;1x14x14
input_type_rt: featuremap;featuremap;featuremap;featuremap;featuremap;featuremap;featuremap
input_type_train: featuremap;featuremap;featuremap;featuremap;featuremap;featuremap;featuremap
mean_value: ''
scale_value: ''
separate_batch: false
std_value: ''
model_parameters:
debug_mode: ''
march: nash-e
onnx_model: test_onnx_model/encoder.onnx
output_model_file_prefix: encoder_opt
output_nodes: ''
remove_node_name: ''
remove_node_type: Quantize;Dequantize;Cast;Softmax
working_dir: ./model_output_calib
# decoder config
calibration_parameters:
cal_data_dir: ./calibration_data_dir/noisy_action;./calibration_data_dir/image_feature;./calibration_data_dir/robot_feature;./calibration_data_dir/timestep;./calibration_data_dir/joint_relative_pos
quant_config: {
"model_config": {
"all_node_type": "int16"
}
}
compiler_parameters:
advice: 0
balance_factor: 0
cache_mode: enable
cache_path: 'cache'
compile_mode: latency
core_num: 1
jobs: 64
max_time_per_fc: 0
optimize_level: O2
input_parameters:
input_layout_train: NCHW;NCHW;NCHW;NCHW;NCHW
input_name: noisy_action;image_feature;robot_feature;timestep;joint_relative_pos
input_shape: 1x64x14x8;1x3x400x256;1x14x1x256;1;1x14x14
input_type_rt: featuremap;featuremap;featuremap;featuremap;featuremap
input_type_train: featuremap;featuremap;featuremap;featuremap;featuremap
mean_value: ''
scale_value: ''
separate_batch: false
std_value: ''
model_parameters:
debug_mode: ''
march: nash-e
onnx_model: test_onnx_model/decoder.onnx
output_model_file_prefix: decoder_opt_resize
output_nodes: ''
remove_node_name: ''
remove_node_type: Quantize;Dequantize;Cast;Softmax
working_dir: ./model_output_calib
2.4 模型校准及编译
- 使用如下指令分别校准及编译对应模型,从而得到 hbm 模型;
- 输出的 log 会打印中间结果的相似度,也可以从输出的 .log 查看;
- 模型校准取决于校准的数据量,如果无 GPU 加速,速度会比较慢
hb_compile -c encoder_calib_deploy.yaml
hb_compile -c decoder_calib_deploy.yaml
3. HBM 模型板端部署
- 在开发机编译完得到 hbm 模型后,需将 hbm 模型手动拷贝至 S100 运行
- 板端开发使用地瓜提供的 python 接口,可以方便地进行 hbm 模型的读取和推理(链接)
3.1 输入输出量化/反量化
- 由于 sem 将 encoder 和 decoder 分为两部分导出,因此整体的输入输出量化/反量化流程如下:
- 实际操作时,需参考接口定义,检查 hbm 模型输入输出的 name、type,根据 scale 进行量化及反量化操作
- 量化/反量化公式如下:

import numpy as np
# 量化,此处以 int16 为例
x = input_float / scale
x = np.clip(np.round(x), -32768, 32767)
x = x.astype(np.int16)
# 反量化
float_data = int_data * scale
4. 一致性验证
- 通过 dump GPU 推理的输入和中间输出以及最终输出,再进行 BPU 推理来对比每一步的余弦相似度
5. 真机部署调试
- 这部分可以参考地平线机器人实验室开源的部署工具进行真机部署(robo_orchard_deploy_ros2)