在执行python export_bpu_actpolicy.py --config bpu_export_config.yaml,遇到如下问题
raise AttributeError(
AttributeError: ‘ACTPolicy’ object has no attribute ‘normalize_inputs’,
请问各位前辈们如何解决呢
在执行python export_bpu_actpolicy.py --config bpu_export_config.yaml,遇到如下问题
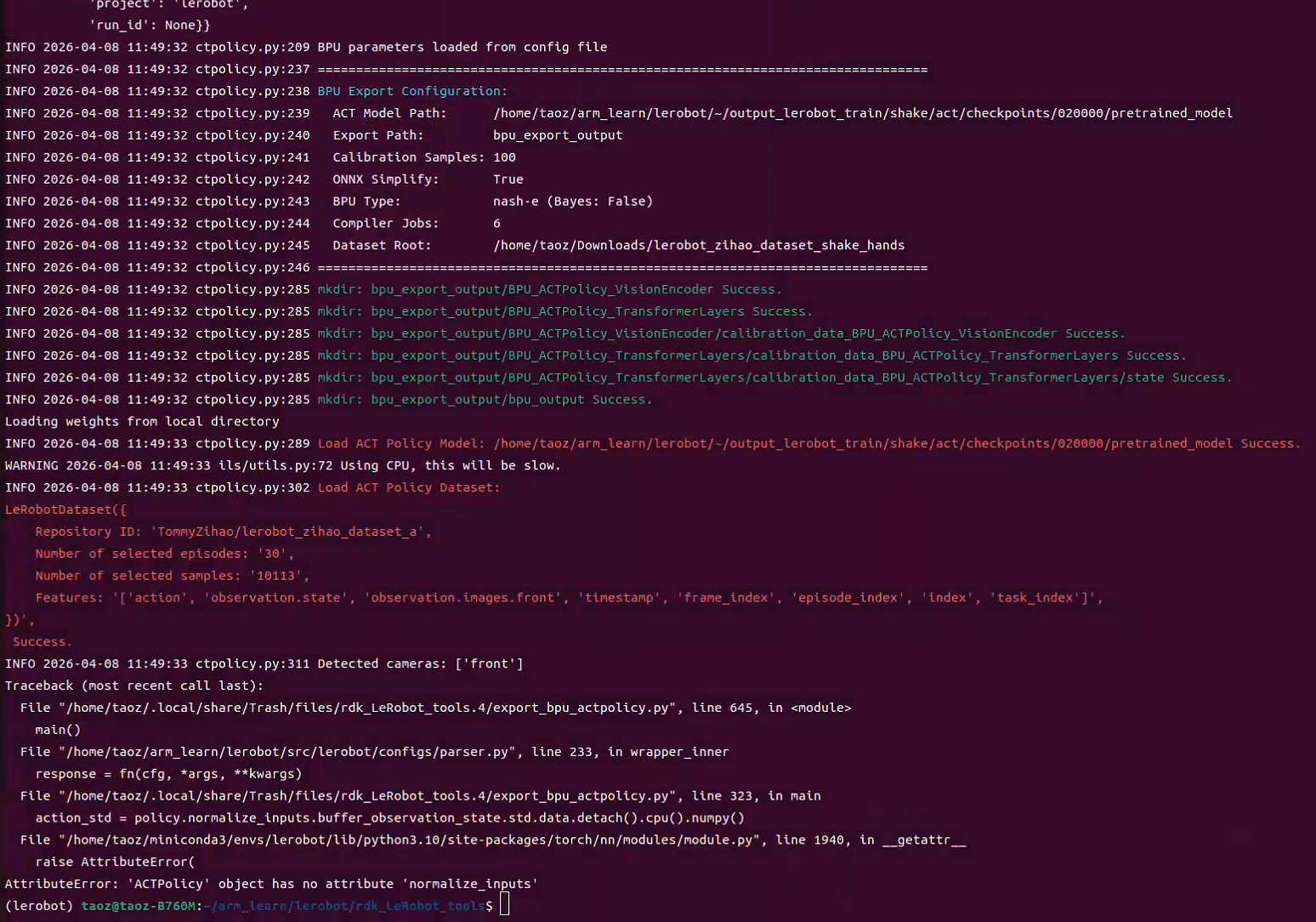
raise AttributeError(
AttributeError: ‘ACTPolicy’ object has no attribute ‘normalize_inputs’,
请问各位前辈们如何解决呢
根据错误信息 AttributeError: 'ACTPolicy' object has no attribute 'normalize_inputs',这是 LeRobot 版本不匹配 导致的。
D-Robotics 的 rdk_lerobot_tools 是基于特定版本的 LeRobot fork 开发的,而你可能使用了:
必须使用 D-Robotics fork 的 LeRobot 仓库:
# 删除现有的 lerobot 目录
rm -rf lerobot
# 克隆 D-Robotics 的 fork 版本
git clone https://github.com/D-Robotics/lerobot.git
# 进入目录
cd lerobot
# 安装依赖
pip install -e ".[feetech]"
# 在 lerobot 目录下
cd lerobot
git clone https://github.com/D-Robotics/rdk_LeRobot_tools
# 确认目录结构
ls -la rdk_lerobot_tools/
# 应该包含 export_bpu_actpolicy.py 等文件
检查 LeRobot 源码中 ACTPolicy 的实现:
# 查看 ACTPolicy 类定义
cat lerobot/common/policies/act_policy.py | grep -A 20 "class ACTPolicy"
正确的版本应该包含 normalize_inputs 方法。
# 激活 conda 环境(如果使用)
conda activate lerobot
# 执行导出命令
python rdk_lerobot_tools/export_bpu_actpolicy.py \
--config bpu_export_config.yaml
运行以下命令检查你的 LeRobot 版本是否正确:
python -c "from lerobot.common.policies.act_policy import ACTPolicy; import inspect; print('normalize_inputs' in dir(ACTPolicy))"
True:版本正确False:版本错误,需要重新安装详细的全流程文档请参考:
![]() 不要使用官方的 huggingface/lerobot 主分支,代码接口已经变化,会导致兼容性问题。
不要使用官方的 huggingface/lerobot 主分支,代码接口已经变化,会导致兼容性问题。
![]() 如果问题仍然存在,请提供:
如果问题仍然存在,请提供:
git log -1 的输出(查看 commit 版本)你好,可以看一下github的Readme,因为Lerobot变化比较大,所以仓库里保留了一个稳定版本的commit,从日志看是数据集格式的问题,可以尝试让AI修复一下适配新版本lerobot数据集格式
根据 GitHub README 说明,rdk_LeRobot_tools 的 stable 版本 是基于 LeRobot v2.1 数据集格式 开发的。你遇到新错误很可能是因为:
# 1. 完全清理现有环境
rm -rf lerobot
conda remove -y lerobot # 如果用了 conda
# 2. 克隆 D-Robotics 的 fork 版本(已锁定正确依赖)
git clone https://github.com/D-Robotics/lerobot.git
cd lerobot
# 3. 克隆工具链
git clone https://github.com/D-Robotics/rdk_LeRobot_tools.git
# 4. 安装依赖
pip install -e ".[feetech]"
# 5. 安装导出所需额外包
pip install onnx onnxsim termcolor tqdm
# 6. 强制降级 datasets 到兼容版本
pip install datasets==2.19.0
# 1. 清理
rm -rf lerobot
# 2. 克隆官方仓库并切换到 v2.1 对应 commit
git clone https://github.com/huggingface/lerobot.git
cd lerobot
git checkout 8cfab3882480bdde38e42d93a9752de5ed42cae2
# 3. 克隆工具链
git clone https://github.com/D-Robotics/rdk_LeRobot_tools.git
# 4. 安装
pip install -e ".[feetech]"
pip install onnx onnxsim termcolor tqdm datasets==2.19.0
# 1. 验证 ACTPolicy 类是否有 normalize_inputs 方法
python -c "from lerobot.common.policies.act_policy import ACTPolicy; print('normalize_inputs' in dir(ACTPolicy))"
# 应输出: True
# 2. 验证 datasets 版本
python -c "import datasets; print(datasets.__version__)"
# 应输出: 2.19.0
# 3. 查看当前 commit
cd lerobot && git log -1 --oneline
# 修改配置文件 bpu_export_config.yaml
# 关键字段:
# - dataset.root: 你的数据集路径
# - act_path: 训练好的模型路径(包含 config.json 和 model.safetensors)
# - type: nash-e (S100) 或 bayes (X5)
# 执行导出
python rdk_lerobot_tools/export_bpu_actpolicy.py --config bpu_export_config.yaml
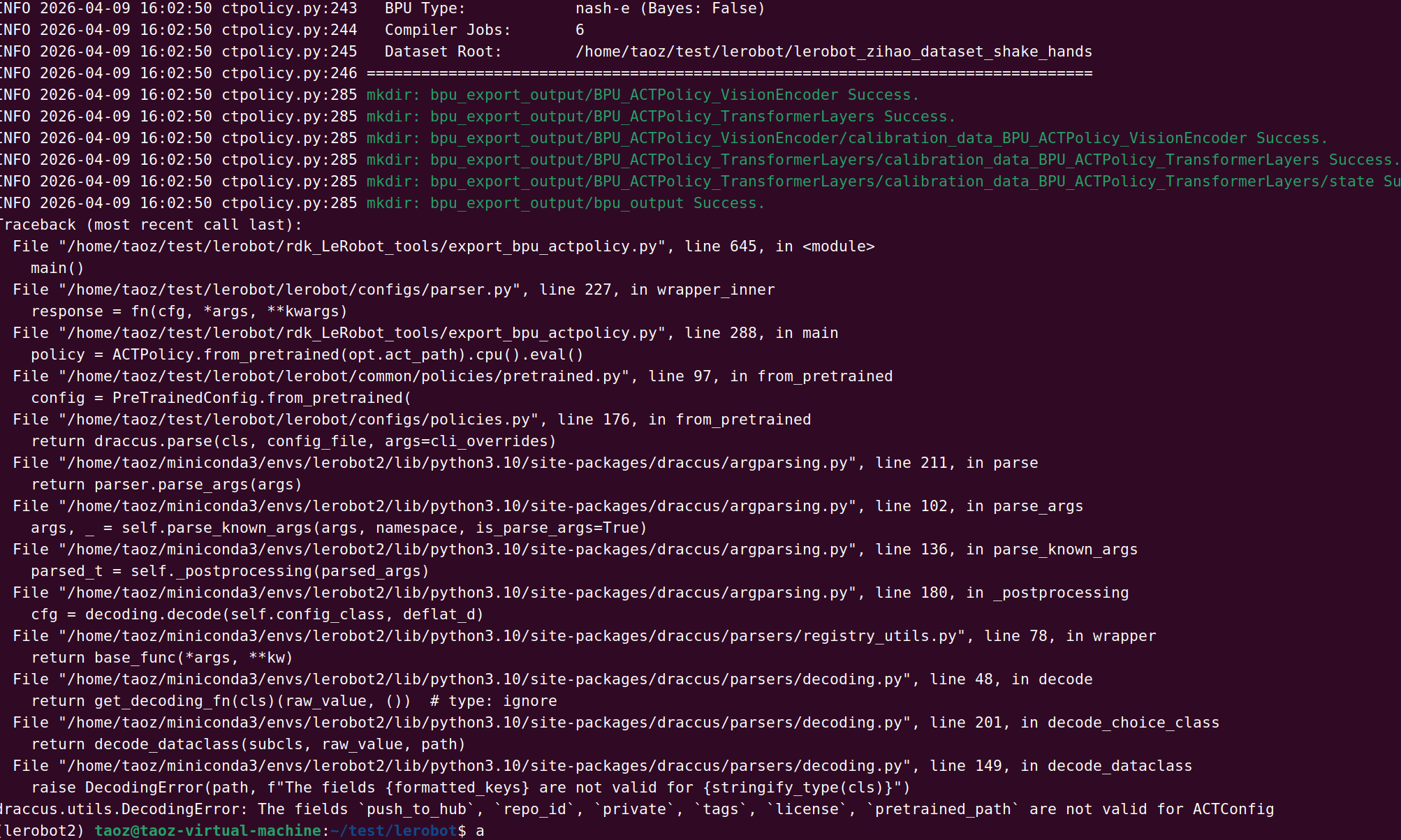
datasets==2.19.0,新版 datasets 会导致数据集格式不兼容huggingface/lerobot 的 main 分支,代码接口已变化如果按上述步骤仍有问题,请提供:
git log -1 输出(确认 commit 版本)pip list | grep -E "lerobot|datasets" 输出(确认版本)参考文档:
从错误截图看,这次是 数据集加载失败 的问题。核心错误是数据集格式与 LeRobot 版本不匹配。
# 检查当前版本
pip show datasets
# 强制降级到兼容版本
pip install datasets==2.19.0
bpu_export_config.yaml根据 README 说明,v2.1 版本需要取消注释 policy 和 dataset 相关配置:
# bpu_export_config.yaml
# 必须取消注释并正确配置以下字段:
policy:
type: act
# 其他 policy 参数...
dataset:
repo_id: 你的数据集ID
root: 你的数据集本地路径 # 如果本地加载
# v2.1 格式需要的字段
# 测试数据集能否正常加载
python -c "
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset
dataset = LeRobotDataset('你的数据集路径')
print('数据集加载成功')
print(f'数据量: {len(dataset)}')
"
# 1. 清理环境
rm -rf lerobot
conda deactivate
# 2. 使用 D-Robotics fork(已锁定 v2.1 兼容版本)
git clone https://github.com/D-Robotics/lerobot.git
cd lerobot
git clone https://github.com/D-Robotics/rdk_LeRobot_tools.git
# 3. 安装依赖
pip install -e ".[feetech]"
pip install datasets==2.19.0 onnx onnxsim termcolor tqdm
# 4. 重新训练模型(用 v2.1 格式)
python lerobot/scripts/train.py --config your_config.yaml
如果不想重新训练,可以尝试转换数据集:
# 使用 DAMO 平台的转换脚本(如果有)
python rdk_lerobot_tools/damo/replace.py
| 检查项 | 正确值 |
|---|---|
datasets 版本 |
2.19.0 |
| LeRobot 来源 | D-Robotics/lerobot 或 指定 commit |
bpu_export_config.yaml |
policy/dataset 字段已取消注释 |
| 数据集路径 | 绝对路径,且包含 meta.json |
| 模型路径 | 包含 config.json + model.safetensors |
如果上述方案仍无法解决,请提供:
# 1. 完整错误堆栈(复制文字,不要截图)
# 2. 环境信息
pip list | grep -E "lerobot|datasets|huggingface"
# 3. LeRobot commit 版本
cd lerobot && git log -1 --oneline
# 4. bpu_export_config.yaml 内容(脱敏后)
cat rdk_lerobot_tools/bpu_export_config.yaml
# 5. 数据集目录结构
tree -L 2 你的数据集路径
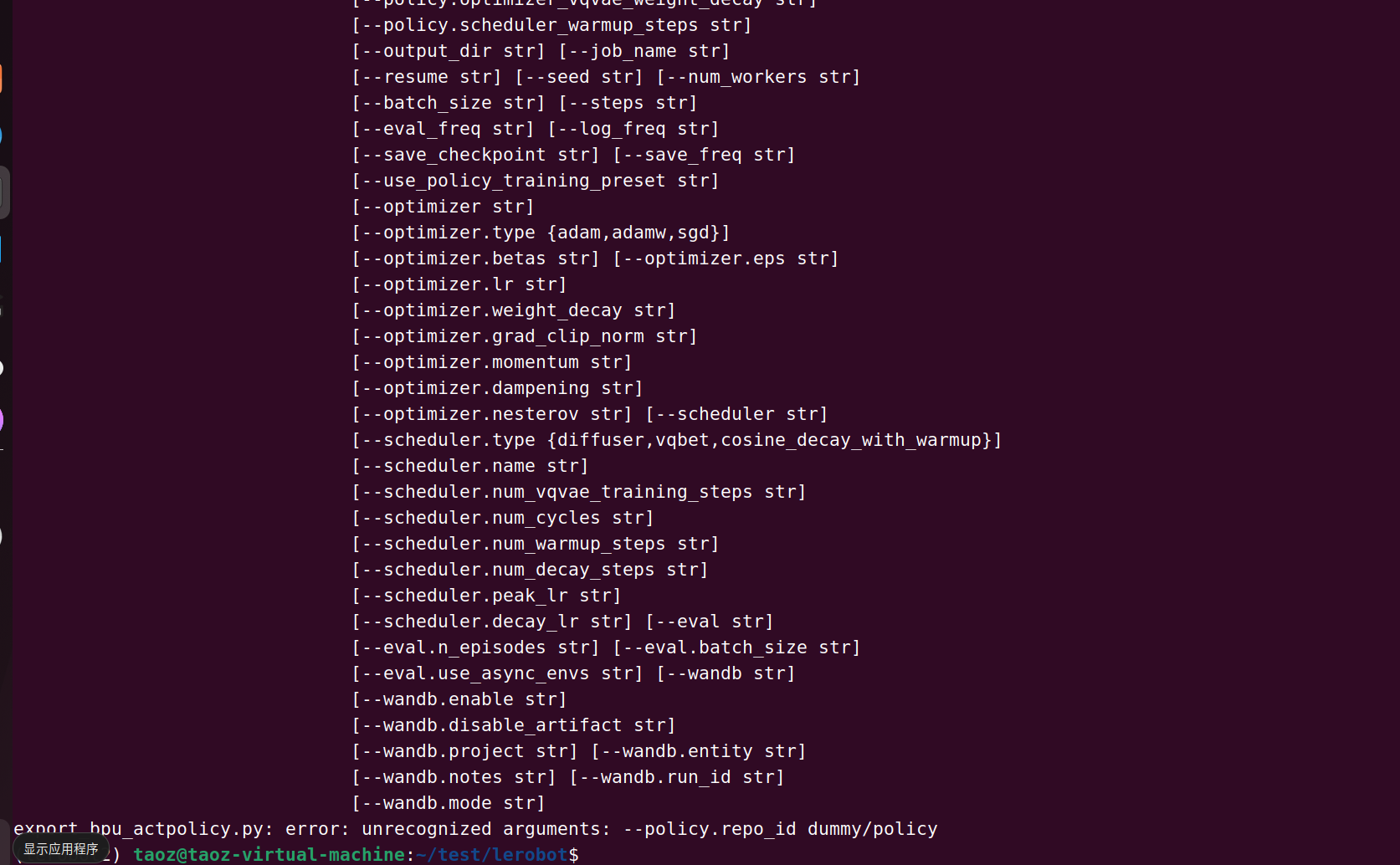
根据 bpu_export_config.yaml 配置文件,policy.id 字段不需要填写(或者说应该注释掉)。
查看配置文件原文:
# 策略配置
policy:
type: "act"
device: "cpu"
# repo_id: "dummy/policy" # 占位符 仅较新版本 LeRobot 需要,需要时放开注释即可
关键点:
repo_id 字段默认是注释状态(前面有 #)打开 bpu_export_config.yaml,确保 policy.repo_id 是注释状态:
policy:
type: "act"
device: "cpu"
# repo_id: "dummy/policy" # 保持注释,不要取消注释!
必须正确填写的字段只有:
# 数据集路径(必须修改为你的实际路径)
dataset:
root: "/your/actual/dataset/path"
# 训练好的模型路径(必须修改)
act_path: "/your/actual/pretrained_model/path"
# BPU 芯片类型(根据硬件选择)
type: "nash-e" # S100 用 nash-e,X5 用 bayes
python rdk_lerobot_tools/export_bpu_actpolicy.py --config bpu_export_config.yaml
你看到的错误 policy.repo_id 相关报错,很可能是因为:
repo_id 的注释在 v2.1 版本中,导出脚本通过 act_path 直接加载本地模型,不需要 repo_id。
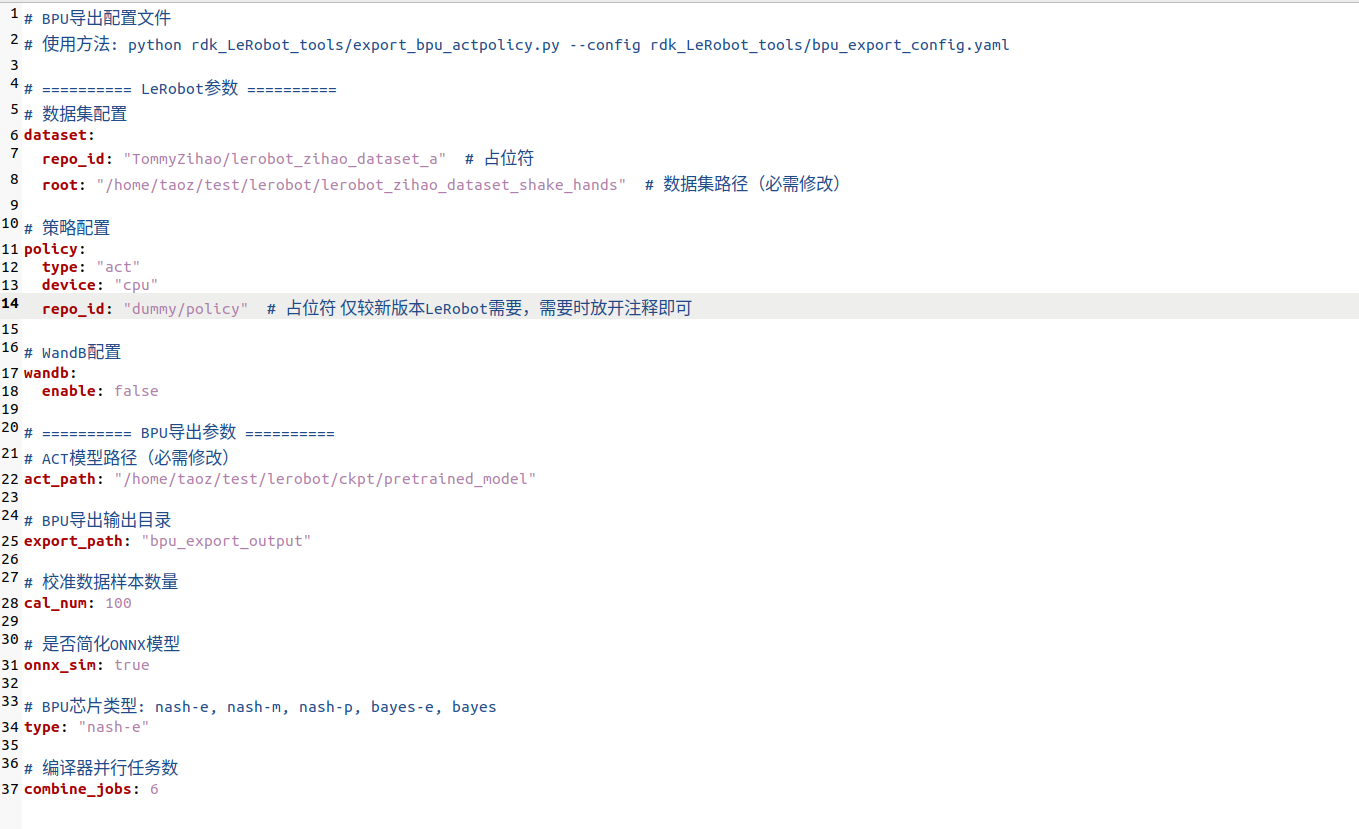
# ========== LeRobot 参数 ==========
dataset:
# repo_id: "dummy/dataset" # 保持注释
root: "/home/taoz123/datasets/so100_test" # 你的数据集路径
policy:
type: "act"
device: "cpu"
# repo_id: "dummy/policy" # 保持注释!
wandb:
enable: false
# ========== BPU 导出参数 ==========
act_path: "/home/taoz123/lerobot/outputs/train/act_test/pretrained_model"
export_path: "bpu_export_output"
cal_num: 100
onnx_sim: true
type: "nash-e" # S100 用这个
combine_jobs: 6
执行前确认:
dataset.root 指向正确的数据集路径act_path 指向包含 config.json 和 model.safetensors 的文件夹policy.repo_id 保持注释状态type 与你的硬件匹配(S100=nash-e,X5=bayes)修改后应该可以正常执行导出,如果还有问题请提供完整的错误堆栈文字。
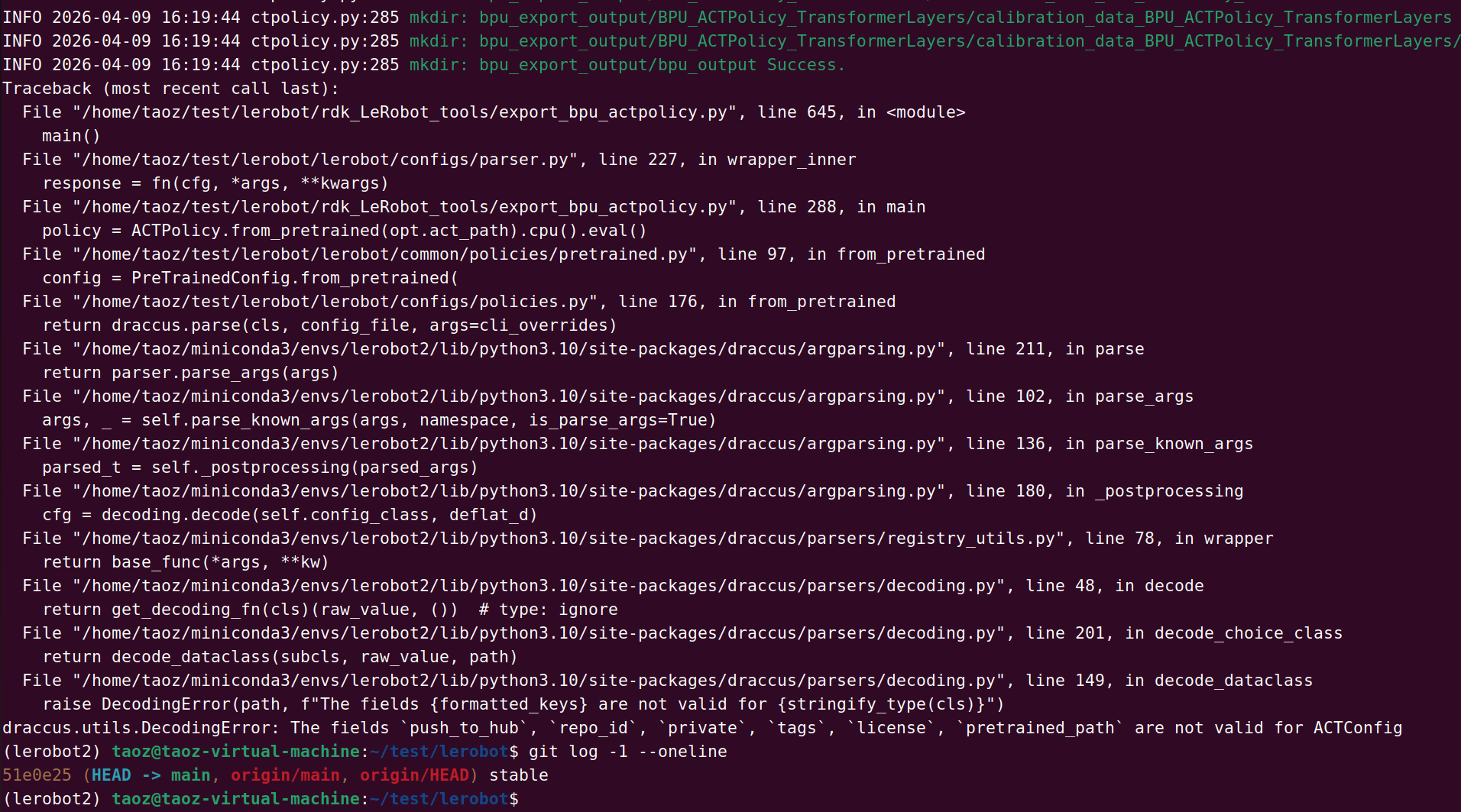
从错误堆栈看,这次是 数据集加载失败 的问题。核心原因是数据集格式与 LeRobot v2.1 不匹配。
# 检查你的数据集目录结构
tree -L 3 /home/taoz123/datasets/so100_test
v2.1 格式的数据集应该包含:
so100_test/
├── meta.json # 必须有
├── train/
│ ├── chunk-000/
│ │ ├── action.hdf5
│ │ ├── observation.image.hdf5
│ │ └── ...
└── info.json # 可能有
python -c "
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset
try:
dataset = LeRobotDataset(root='/home/taoz123/datasets/so100_test')
print('✓ 数据集加载成功')
print(f'数据量:{len(dataset)}')
print(f'特征 keys: {dataset.camera_keys}')
except Exception as e:
print('✗ 数据集加载失败')
print(f'错误:{e}')
"
# 查看当前配置
cat rdk_lerobot_tools/bpu_export_config.yaml
确保以下字段正确:
dataset:
# repo_id: "dummy/dataset" # 保持注释!
root: "/home/taoz123/datasets/so100_test" # 绝对路径
policy:
type: "act"
device: "cpu"
# repo_id: "dummy/policy" # 保持注释!
act_path: "/home/taoz123/lerobot/outputs/train/xxx/pretrained_model"
type: "nash-e"
根据错误堆栈,问题可能是:
| 可能原因 | 概率 | 解决方案 |
|---|---|---|
| 数据集是 v3.x 格式 | 高 | 用 v2.1 环境重新采集或转换 |
| 数据集路径错误 | 中 | 检查路径是否存在 |
| meta.json 缺失 | 中 | 检查数据集完整性 |
| datasets 版本不对 | 低 | 确认 pip show datasets 是 2.19.0 |
# 1. 确认环境正确
cd lerobot && git log -1 --oneline
pip show datasets | grep Version # 应该是 2.19.0
# 2. 重新采集 1 组测试数据
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.num_episodes=1 \
--control.episode_time_s=30 \
--control.root=datasets/so100_v2_test
# 3. 用新数据集重新训练
python lerobot/scripts/train.py \
--dataset.root=datasets/so100_v2_test \
--policy.type=act \
--output_dir=outputs/act_v2_test
# 4. 导出模型
python rdk_lerobot_tools/export_bpu_actpolicy.py \
--config bpu_export_config.yaml
如果数据集是在新版 LeRobot 下采集的,需要转换格式:
# 检查是否有转换脚本
ls rdk_lerobot_tools/damo/
# 如果有 replace.py,运行转换
python rdk_lerobot_tools/damo/replace.py
如果上述方案仍无法解决,请提供:
# 1. 数据集目录结构
tree -L 3 /home/taoz123/datasets/so100_test
# 2. 环境版本
pip list | grep -E "lerobot|datasets"
cd lerobot && git log -1 --oneline
# 3. 完整错误文字(复制终端输出,不要截图)
# 4. 数据集是如何采集的?
# - 用哪个 LeRobot 版本?
# - 用哪个 commit?
是不是用新版本Lerobot录制的数据集,去年某个版本后Lerobot升级dataset到3.0版本了,数据的保存格式产生了变动,官方有一个v21 到 v30 的转化脚本,可以逆转化一下
根据 Marcelo6151 的提示,问题明确了:你的数据集是用新版 LeRobot (v3.0 格式) 录制的,但导出工具需要 v2.1 格式。
LeRobot 官方仓库提供了数据集格式转换脚本:
# 在 LeRobot 仓库中查找转换脚本
find lerobot -name "*convert*" -o -name "*migrate*"
# 常见路径:
# lerobot/scripts/convert_dataset_v2_to_v3.py
# lerobot/scripts/migrate_dataset.py
# 方法 A:使用官方转换脚本(如果有)
python lerobot/scripts/convert_dataset_v3_to_v2.py \
--input /home/taoz123/datasets/so100_test \
--output /home/taoz123/datasets/so100_test_v2
# 方法 B:手动转换(如果官方脚本只有 v2→v3)
# 需要修改数据集的 meta.json 和 chunk 结构
# 检查 rdk_LeRobot_tools 是否有转换脚本
ls rdk_lerobot_tools/damo/
# 如果有 replace.py 或 convert 脚本
python rdk_lerobot_tools/damo/replace.py
如果转换脚本找不到或转换失败,建议用正确环境重新采集 1 组测试数据:
# 1. 确认环境版本
cd lerobot
git log -1 --oneline # 应该是 D-Robotics fork 或指定 commit
pip show datasets | grep Version # 必须是 2.19.0
# 2. 重新采集 1 组数据(30 秒即可)
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.num_episodes=1 \
--control.episode_time_s=30 \
--control.root=datasets/so100_v2_test \
--control.warmup_time_s=5
# 3. 用新数据集重新训练
python lerobot/scripts/train.py \
--dataset.root=datasets/so100_v2_test \
--policy.type=act \
--output_dir=outputs/act_v2_test \
--training.num_episodes=50
# 4. 导出模型
python rdk_lerobot_tools/export_bpu_actpolicy.py \
--config bpu_export_config.yaml
# 测试数据集能否被 v2.1 环境加载
python -c "
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset
import os
dataset_path = '/home/taoz123/datasets/so100_test'
# 检查必要文件
print('检查数据集结构:')
print(f' meta.json: {os.path.exists(os.path.join(dataset_path, \"meta.json\"))}')
print(f' train/: {os.path.exists(os.path.join(dataset_path, \"train\"))}')
# 尝试加载
try:
dataset = LeRobotDataset(root=dataset_path)
print('✓ 数据集加载成功')
print(f' 数据量:{len(dataset)}')
except Exception as e:
print('✗ 数据集加载失败')
print(f' 错误:{e}')
"
| 特征 | v2.1 格式 | v3.0 格式 |
|---|---|---|
| datasets 库版本 | 2.19.0 | 3.x |
| meta.json 结构 | 旧格式 | 新格式 |
| chunk 命名 | chunk-000 | chunk-0.000 |
| 兼容性 | rdk_LeRobot_tools stable | 新版工具 |
1. 先用 v2.1 环境重新采集 1 组数据(30 秒)
↓
2. 快速训练 1 轮(验证 pipeline 能跑通)
↓
3. 导出成功 → 确认环境正确
↓
4. 再处理正式数据集(转换或重新采集)
请提供以下信息以便进一步协助:
# 1. 数据集是如何采集的?
# - 用的哪个 LeRobot 仓库?(D-Robotics fork 还是 huggingface 官方?)
# - git commit 是什么?
# 2. 当前环境信息
pip list | grep -E "lerobot|datasets"
cd lerobot && git log -1 --oneline
# 3. 数据集目录结构
tree -L 3 /home/taoz123/datasets/so100_test