-
为什么把量化数据类型设置未float16后,所有算子都在cpu上运行了呢?
-
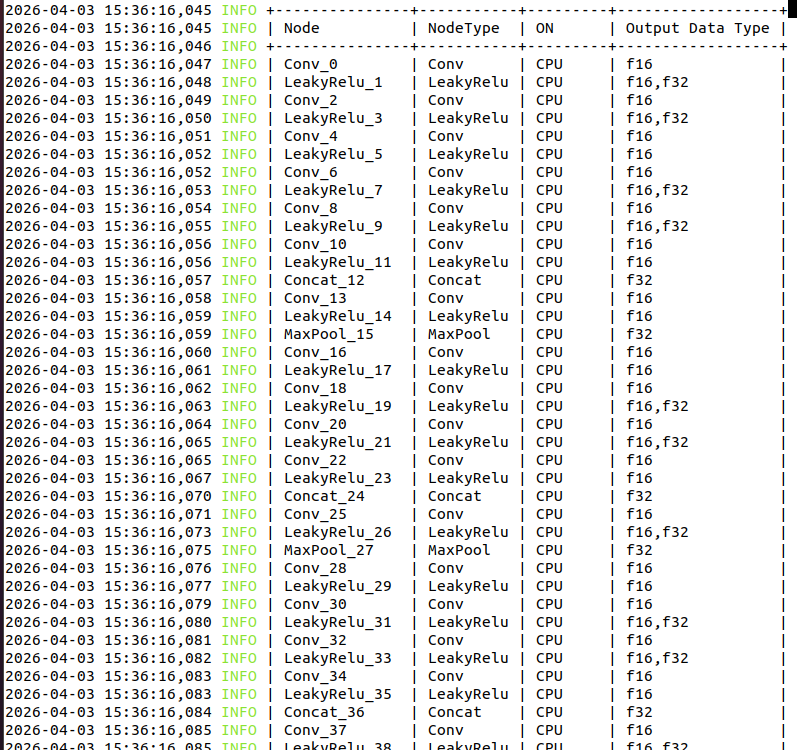
oe v3.2.0的docker里hb_compile会打印算子运行在 cpu/bpu 和 数据类型 的信息。如附件图所示。但v3.7.0的不打印了。为什么呢?
-
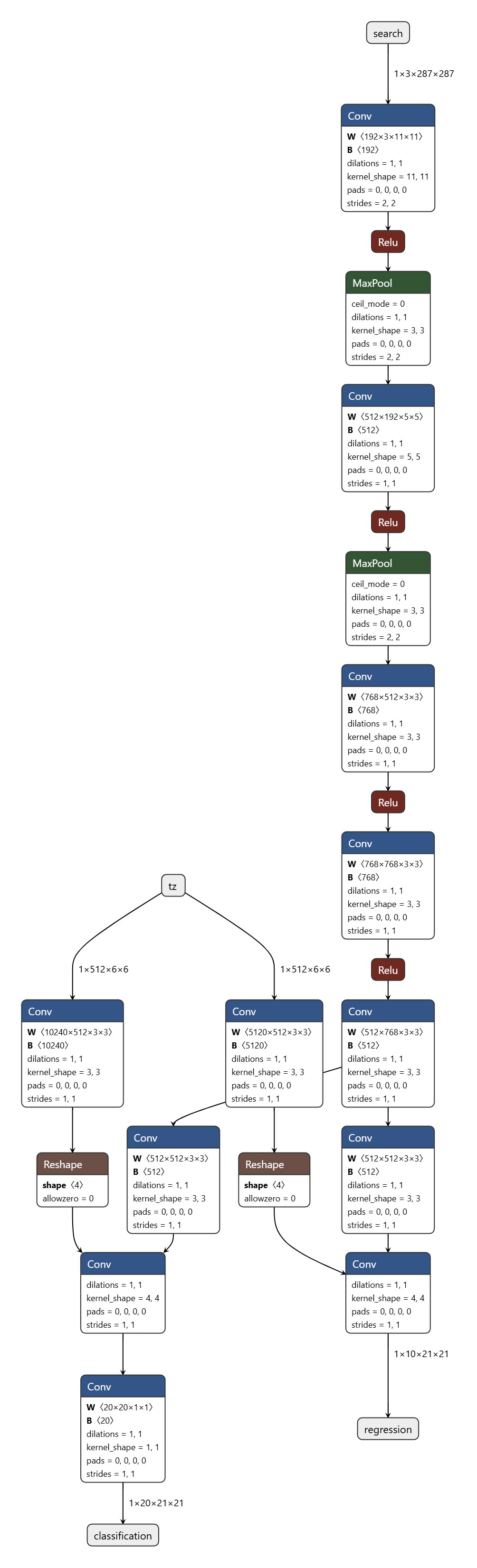
我有一个siamRPN的里面有Reshape算子,看支持列表是支持的。但转出来的hbm会有在cpu上运行的部分,导致推理很慢,信息如附件图片所示。这是为什么呢?

- 若模型中包含 BPU 不支持 float16 的算子(如 LayerNorm、Exp、ScatterND、Cast 等常见非线性或控制流算子),
- 工具链无法在 BPU 上执行它们,就会自动调度到 CPU,
到 v3.7.0 及之后版本,为提升编译速度和减少冗余输出,默认日志级别提高,不再逐算子打印设备分配信息
BPU加速:……还有一些则依赖特定的上下文(如 Reshape、Transpose 需要前后均为 BPU 算子)才能被动量化。
感谢回复。还是有些疑惑:
-
1楼问题2 的图片时v3.2.0 转换yolov7-tiny的打印。我设置了float16。看打印是所有算子都到cpu上去了。而不是非线性或控制流算子。这是为什么呀?
-
1楼中问题3的截图是设置成int16(all node)转换的结果,总有一部分被转换到cpu上执行。netron看onnx网络并没有不能在bpu上执行的算子呢(那怕是Reshape 算子的前后)。所以很疑惑为什么转换出的hbm,会有在cpu上执行的2段。
是需要看算子支持列表 这些算子 是否支持 fp16 /不支持就会回退到CPU
设置int16需要手动把一些支持的算子指定到bpu上