x3m板端量化方式
请问这个量化方式要怎么判断选择呢?
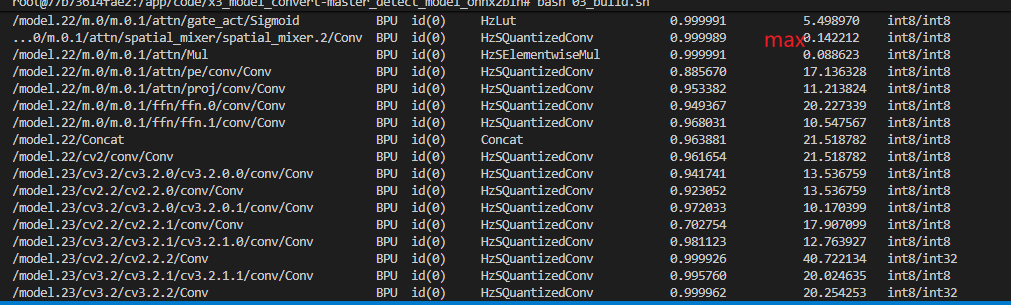
我测试了下default和max两种量化方式在我的业务场景的效果,第一种default自动选择的应该是max,max_percentile系数为0.9995;第二种我选择max,但没有配置max_percentile参数,按手册上的 说法来说应该默认为1;
这两种配置方式下,default量化出来的余弦相似度比max的要好,但是实际推理效果精度却不如max,损失很严重,这可能是什么问题?
x3m板端量化方式
请问这个量化方式要怎么判断选择呢?
我测试了下default和max两种量化方式在我的业务场景的效果,第一种default自动选择的应该是max,max_percentile系数为0.9995;第二种我选择max,但没有配置max_percentile参数,按手册上的 说法来说应该默认为1;
这两种配置方式下,default量化出来的余弦相似度比max的要好,但是实际推理效果精度却不如max,损失很严重,这可能是什么问题?
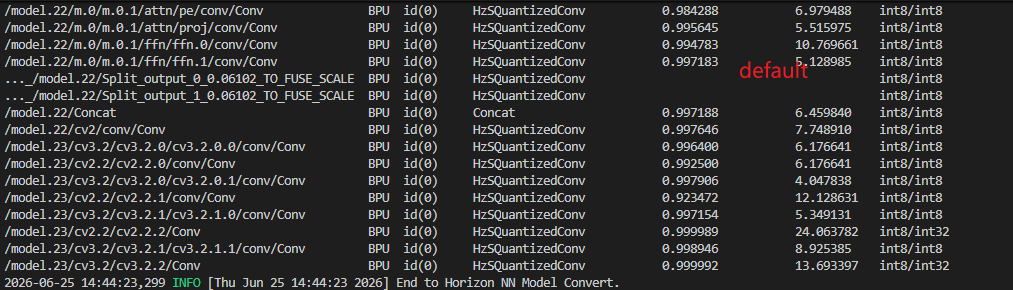
另外似乎default方式多了两个量化算子?
这是量化过程产生的正常现象吗
针对您在 X3M 板端遇到的“余弦相似度高但实际推理精度低”以及 default 与 max 量化配置选择的问题,这通常涉及量化敏感度分析、评估指标局限性以及数据预处理一致性三个核心方面。
以下是基于地平线工具链最佳实践的分析与建议:
余弦相似度(Cosine Similarity)主要衡量向量方向的相似性,对数值的大小(幅度)不敏感。如果量化导致输出值的整体幅度发生偏移(例如整体变大或变小),余弦相似度可能依然很高,但具体的检测框坐标、分类置信度等业务指标会严重偏离,导致 mAP 等精度指标下降。
排查建议:
hmct-info或 hb_verifier查看其他误差指标。如果 L1/L2 距离很大,说明数值偏差大,即使方向一致,业务逻辑也会出错。
参考案例中曾出现 det 分支余弦相似度正常,但 L1/L2 距离同浮点偏差很大的情况,此时需更换评估指标 [3]。
mse (均方误差)作为敏感度评估指标。MSE 对数值偏差更敏感,能更准确地定位导致精度损失的算子 [3]。# 示例:使用 MSE 指标获取节点敏感度
hmct-debugger get-sensitivity-of-nodes model.onnx calibration_data/ -n node -m mse -v True -s ./debug_result
default vs max 量化方式的选择与差异Default 模式:
max 或 percentile。您观察到的 max_percentile=0.9995 表明它自动选择了百分位校准来剔除异常值。Max 模式 (未配置 percentile):
max_percentile,默认行为通常是取绝对最大值(即 percentile=1.0)。选择建议:
percentile 校准算法,并调整 max_percentile(如 0.999, 0.9995, 0.9999)。这比纯 max 更能保留主要分布区的精度 [2]。default 和 max 之间纠结。应使用 hmct-debugger进行节点敏感度分析,找出对精度影响最大的敏感节点,将这些节点设置为 INT16高精度量化,其余保持 INT8 [2]。debug_mode: "dump_calibration_data"保存校准数据。get-sensitivity-of-nodes获取敏感度排序。除了量化算法本身,以下因素常导致“仿真/验证好,上板差”:
输入数据预处理不一致(最高频原因):
hb_verifier对比原始浮点模型和量化模型在相同输入图片下的逐层输出。如果第一层卷积输出就不一致,大概率是预处理问题 [1]。hb_verifier \
-m ./float_model.onnx,./quantized_model.bc \
-i ./input.npy
校准数据集代表性不足:
max 模式对离群值非常敏感。如果校准集太小或分布不均,计算出的 Max Value 可能无法代表真实推理数据的分布。建议增加校准集数量(通常推荐几百到几千张覆盖场景的图片)。后处理逻辑差异:
hb_verifier确认浮点与量化模型在板端输入下的底层输出一致性,排除预处理错误 [1]。max (percentile=1),尝试显式配置 percentile校准算法,并搜索最佳 max_percentile (如从0.999到0.9999步进测试) [2]。hmct-debugger结合 mse指标进行敏感度分析,将Top敏感节点升级为 INT16 [3]。参考链接:
是的,这是完全正常的现象。
default 模式与手动指定 max 模式在量化策略和图优化逻辑上存在差异,导致生成的计算图(Graph)中算子数量或类型不同。这通常由以下两个原因引起:
在地平线工具链(尤其是针对 BPU 架构如 X3M/J6)中,为了保证算子融合后的精度或满足硬件输入输出约束,编译器可能会在某些节点后自动插入 Requantize 或 Quant/Dequant 对。
max校准,且未开启某些高级优化标志,工具链可能不会插入这些额外的保护性算子,或者采用了不同的融合策略。注意:多出的这两个算子通常是
QuantStub→FakeQuantize→DeQuantStub的组合,或者是 BPU 特定的Requant指令映射。它们的存在往往意味着工具链认为该处需要额外的精度控制 [1]。
不同的量化配置会影响**算子融合(Operator Fusion)**的结果。
default 模式下,某些本应融合的算子(如 Conv + BN + ReLU)因为量化参数(Scale/ZeroPoint)不匹配而未能融合,它们可能会以独立算子的形式存在,并在连接处产生额外的量化节点。default 模式下的 Trace 过程可能与手动配置不同,导致动态块边界处的量化节点处理方式不同 [1]。虽然现象正常,但您需要确认它们是否导致了您提到的“精度损失严重”。请按以下步骤排查:
使用 hb_mapper checker 或查看编译日志中的 Graph 信息,确认多出的两个算子是什么。
Requantize:通常是为了精度保护,一般无害,甚至有益。Quant/Dequant 对:可能导致不必要的舍入误差累积。使用 hb_verifier 对比浮点模型和两种量化模型在相同输入下的逐层输出差异 [1]。
# 对比 default 量化模型
hb_verifier -m float_model.onnx,default_quant.bc -i input.npy -o diff_default.txt
# 对比 max 量化模型
hb_verifier -m float_model.onnx,max_quant.bc -i input.npy -o diff_max.txt
运行 hmct-debugger获取节点敏感度,看多出的这两个算子对应的原始节点是否属于高敏感节点 [3]。
hmct-debugger get-sensitivity-of-nodes model.onnx calib_data/ -n node -m mse -v True -s ./debug_result
default 模式比手动配置更复杂,多出少量量化/重量化算子是常见的图优化结果。hb_verifier定位误差发生的具体层级 [1]。参考链接: