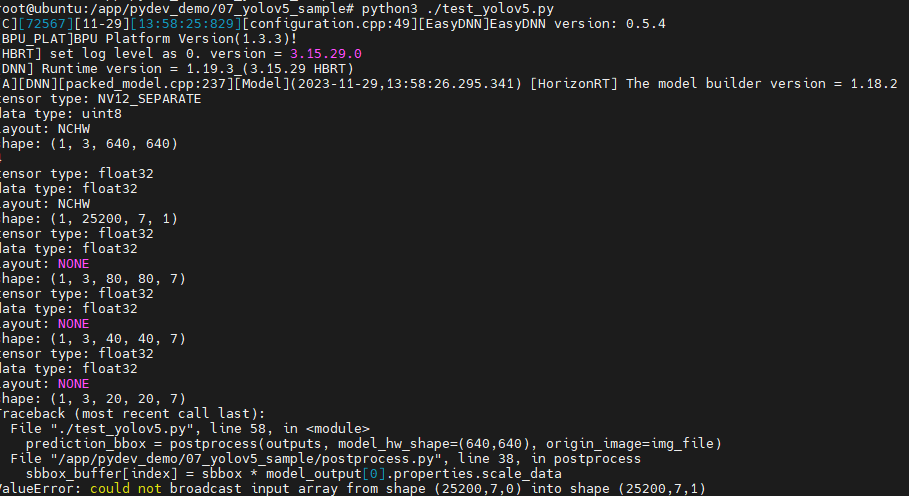
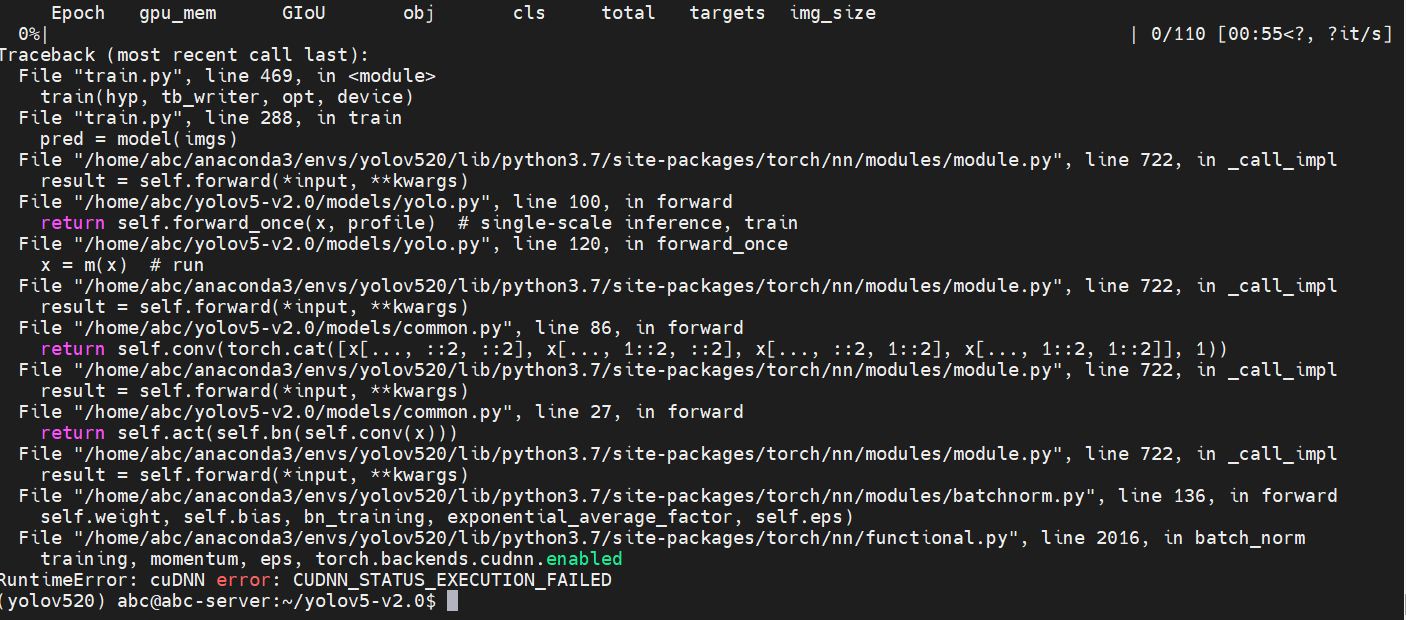
依照工具链说明和地平线社区内大佬的教程帖,帖主成功把yolov5部署在了X3pi板端,但推理时间长达300ms以上,大佬的教程中有提到Cython加速后处理部分,但yolov5模型推理时间的优化在地平线站内几乎没有见过。
请教过徐总之后受到启发,开辟了思路,翻阅X3pi手册发现有提到yolov5的加速方法-

基本原理就如图示所说,删除了模型的后处理层(这也就是为什么demo的yolov5模型有3个output),这一部分在板上完成而不在模型内部进行,从而加速模型推理速度,而后处理部分站内已有用C++包装代码加速的帖子,在此不做赘述。
先说缺点:-
这个修改模型的方法只在yolov5-v2.0有效,尝试过使用2.0的代码转7.0的模型,或直接在7.0版本修改,但都失败了;而2.0的权重文件比起后代版本的权重,2.0未经过优化训练速度慢,batch-size高点基本GPU就跑不了了,贴主的显卡是RTX3060,在7.0跑x权重8个batch-size,在2.0只能跑s了…
其次是2.0版本是两年前的,存在bug,和现在的环境也存在小冲突
本文将从yolov5-v2.0的bug修复开始,到修改模型,一步步说明推理的加速方法
前期准备
首先来到yolov5官网>https://github.com/ultralytics/yolov5/ tag选择v2.0,打包项目-

下载权重,每个版本权重不一定通用,这里要下载2.0的权重,右下角releases,新页面点开tag,找到v2.0的tag-

新页面下滑,这些就是v2.0的模型了,这边建议可以先用s试试水,太大的模型显卡可能带不动

将下载的文件解压,把权重放在weights里-

布置好训练集,改好yaml文件和train参数等-


进入yolov5环境-

BUG修改
第一次运行
运行train.py,发生如下报错:-
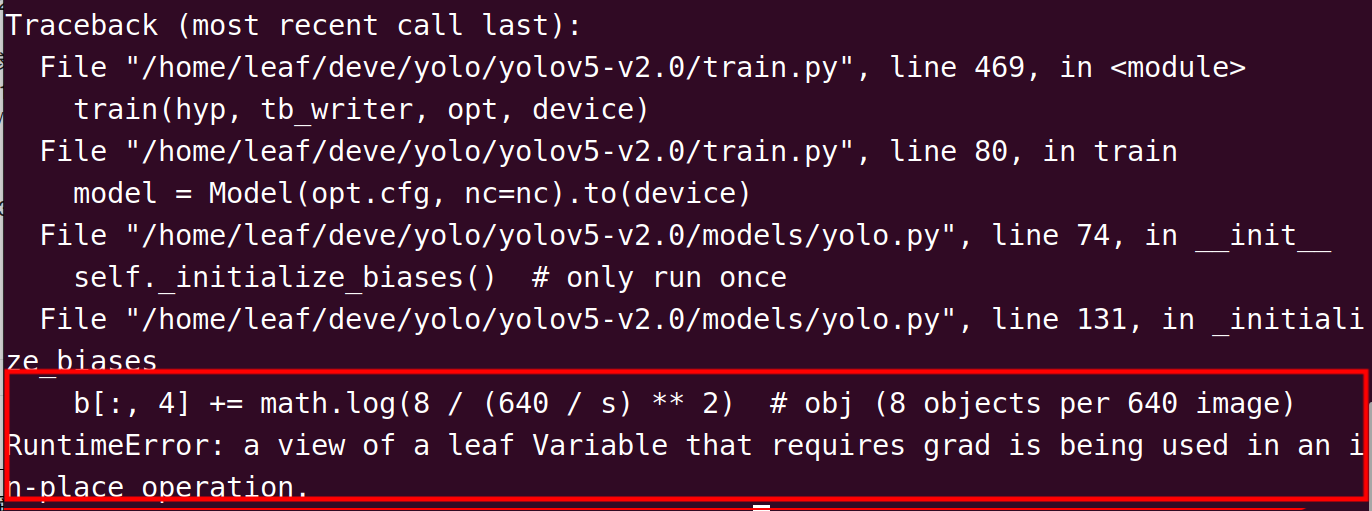
这大概是由于torch版本兼容问题导致的,修正办法:
来到models/yolo.py的130行左右-

禁用梯度计算-

第二次运行
再次运行,发生以下报错(有int字眼)-

这个报错是由于,在新版的numpy库中,
np.int被删去,直接使用int就可以了
在VScode中找到在文件中替换,为了防止将np.int16或np.interp等语句替换掉,我们将(np.int)替换成(int)即可
第三次运行
再次运行,发现在跑第0个epoch的时候报错,且报错有cpu字眼-
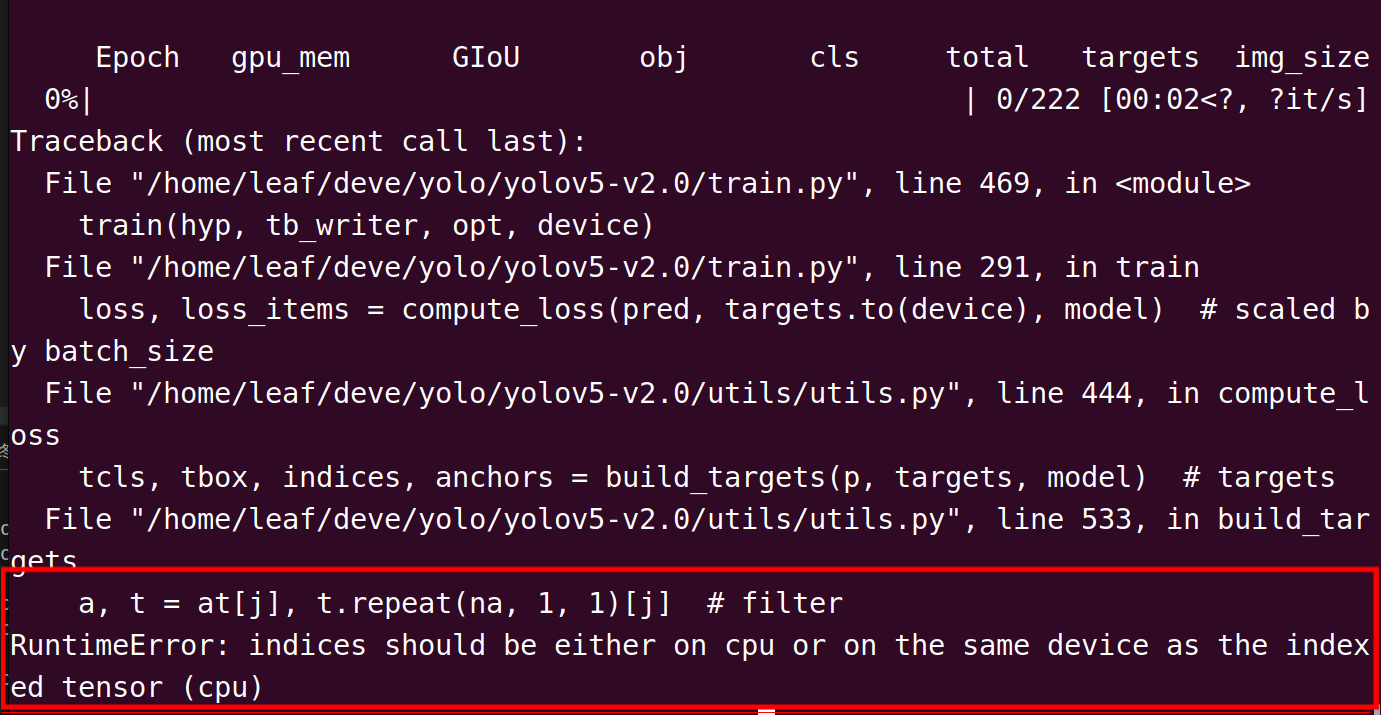
这个错误是由于变量
a不在GPU中导致的
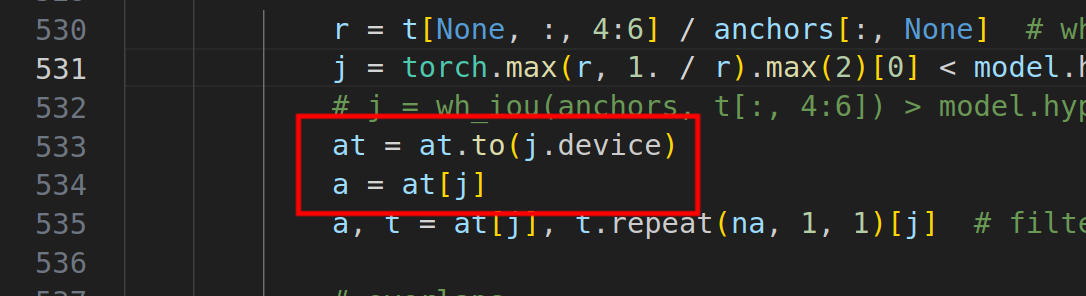
不慌,来到utils/utils.py的533行-

添加如下代码,即可将变量转移到GPU中-
第四次运行
报错如下-
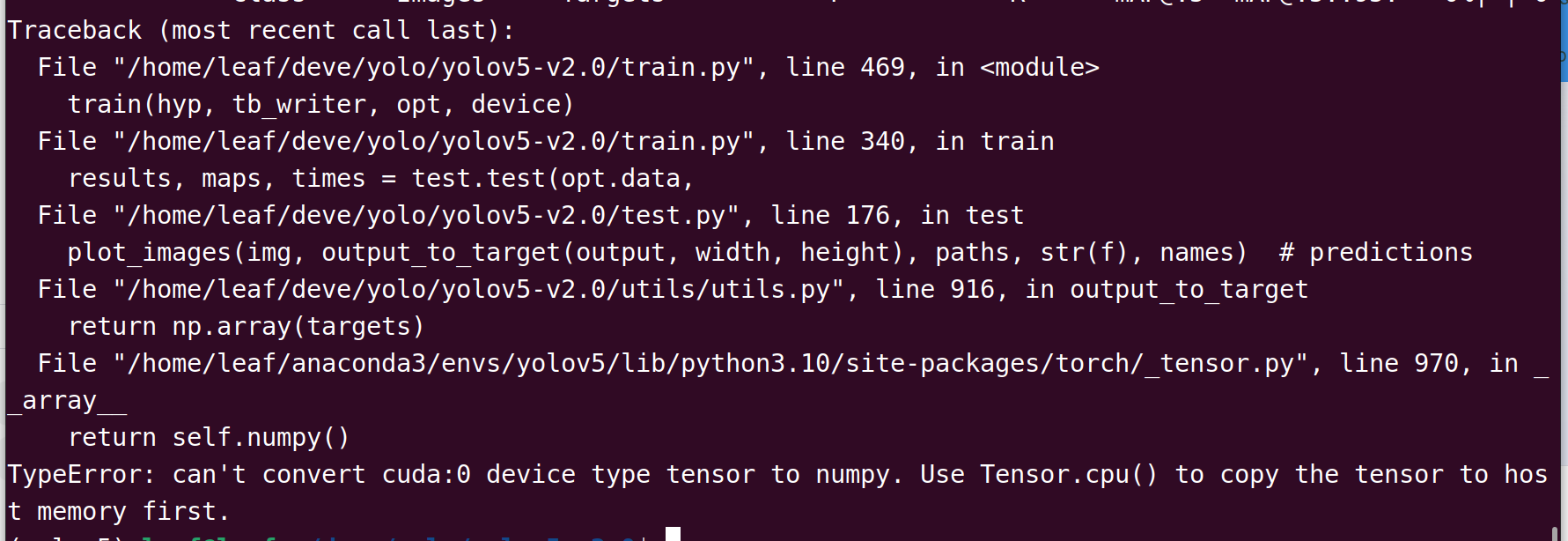
解决方法:来到utils/utils.py的第916行-
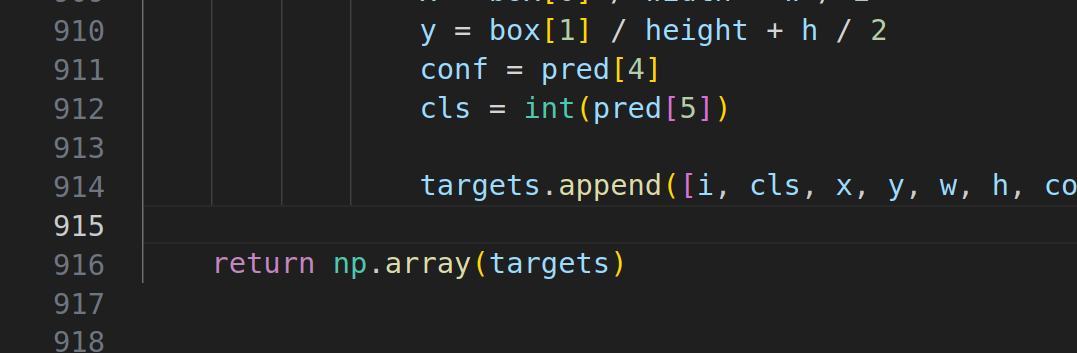
做如下修改即可-
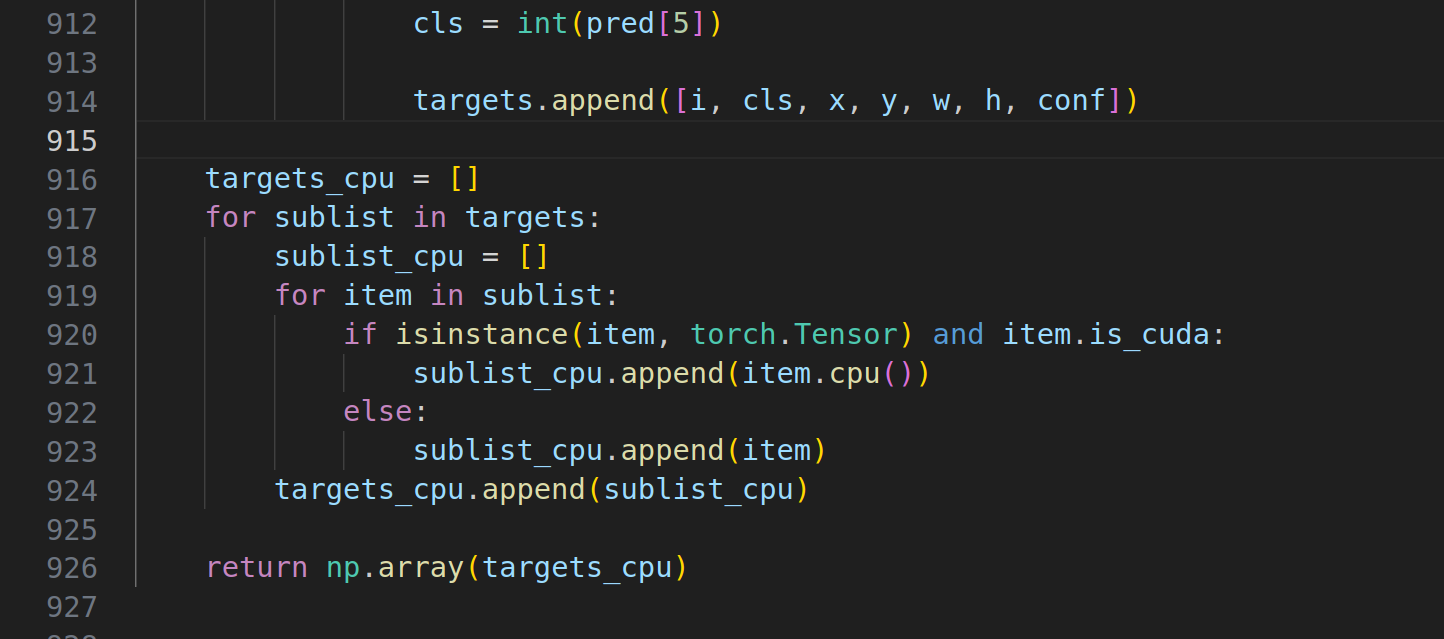
供复制:
targets_cpu = []
for sublist in targets:
sublist_cpu = []
for item in sublist:
if isinstance(item, torch.Tensor) and item.is_cuda:
sublist_cpu.append(item.cpu())
else:
sublist_cpu.append(item)
targets_cpu.append(sublist_cpu)
再次运行代码,就跑通开始训练啦-

这里还要再提一嘴,部分同学可能会遇到如下报错-
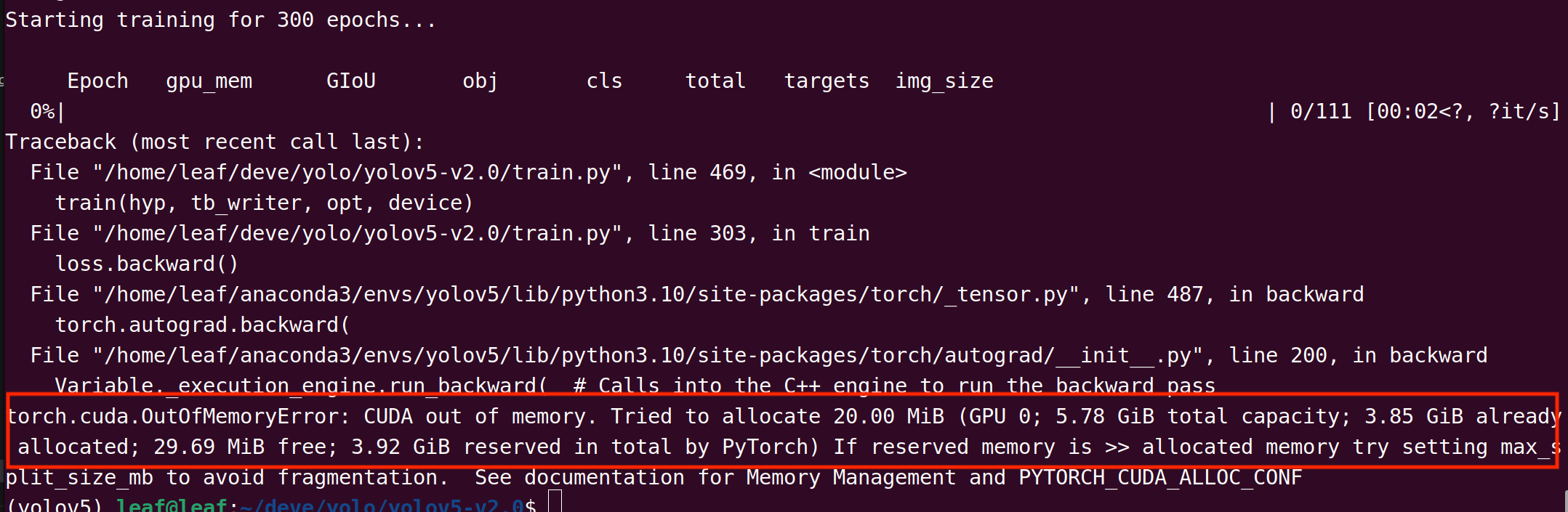
这是因为yolov5-v2.0的权重模型相比后来的版本,没有优化,占用显存过大,但为了加速推理又不得不使用v2.0训练,因此请减小
batch-size数或使用轻量的权重
训练完成,测试一下推理-

-

效果很好
至此,我们已经训练得到v2.0版本的模型,接下来可以开始修改模型输出层
修改模型并转化成onnx
直接说修改方法:
先把models/export.py复制到最外层目录下-
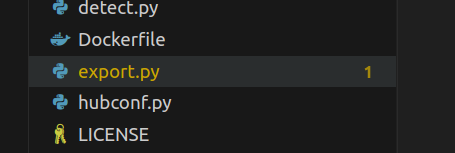
打开最外层目录的export.py来到主函数下,修改刚刚训练出的模型的路经,特别要注意的是这边的参数--img-size最好是32的倍数,且一定要记得你模型尺寸(此参数)-

继续看41行开始的ONNX export部分,opset_version就是转化后的ONNX版本,默认12,务必要改成11!!!否则模型转bin文件会报错;此外,这边的input_name也是你需要记得的-

来到models/yolo.py第22行的forward方法中,把29行的x[i] = x[i].view...(省略)...contiguous()注释掉,替换成x[i] = x[i].permute(0, 2, 3, 1).contiguous()-

保存修改后直接运行export.py,就可以在runs/exp/weights/中看到onnx文件啦-

转化成bin文件
将onnx模型移动到另外的文件夹,并且进入工具链环境(工具链的部署和使用的教程站内有很多,这里就不细说部署过程了),下面是贴主专门用于模型转化的文件夹结构,供参考-
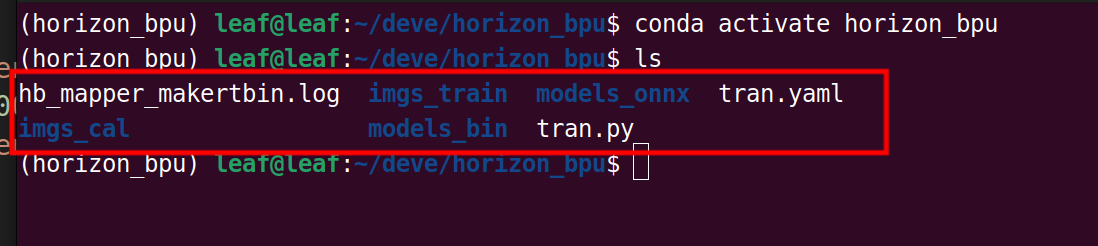
hb_mapper_makertbin.log是工具链自动生成的日志文件-imgs_train存放训练集中的原图片-imgs_cal存放转化模型需要的图片校准数据-tran.py用于将原训练集图片转化成校准数据-medels_onnx存放转化前的onnx模型-models_onnx存放转化后的bin文件-tran.yaml是转化所需的文本
验证模型
使用hb_mapper checker指令验证模型-

这边的
--input-shape就是之前需要记住的参数了
可以看到,新模型只有少数几个算子是不被bpu支持的-

准备图片校准数据
校准数据转化方面是借鉴了小玺玺大佬的,地平线手册中也有很完整的教学,本处不多赘述
模型转换
转换之前,需要准备一下yaml文件,我的yaml文件供大家参考,需要修改的地方已经标出!
model_parameters:
# ----------------------------------------
onnx_model: './models_onnx/head.onnx' #原模型位置
output_model_file_prefix: 'head_yolov5' #模型名字
# ----------------------------------------
march: 'bernoulli2'
input_parameters:
input_type_train: 'rgb'
input_layout_train: 'NCHW'
input_type_rt: 'nv12'
norm_type: 'data_scale'
scale_value: 0.003921568627451
input_layout_rt: 'NHWC'
calibration_parameters:
# ----------------------------------------
cal_data_dir: './imgs_cal/head' #校准数据位置
# ----------------------------------------
calibration_type: 'max'
max_percentile: 0.9999
compiler_parameters:
compile_mode: 'latency'
optimize_level: 'O3'
debug: False
core_num: 2
转化指令hb_mapper makertbin --config yaml文件的位置 --model-type onnx![]() 图片.png
图片.png
可以看到生成的model_output文件夹中的bin文件模型-

上板运行
这里为了方便,我们直接CV地平线的示例文件/app/ai_inference/07_yolov5_sample到自己的home中,并将bin模型移动到板上-

打开test_yolov5.py,来到主函数入口-
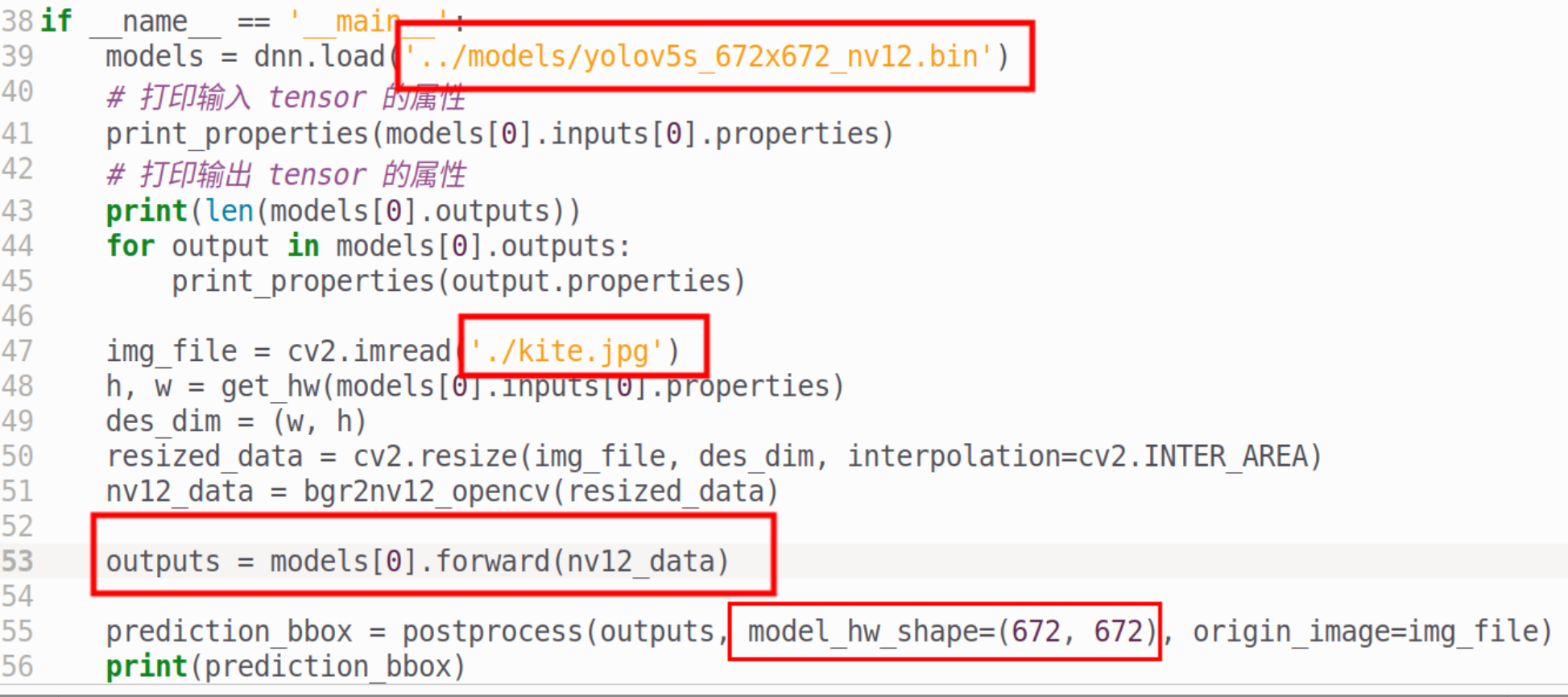
下方的forward就是推理的过程,后面的postprocess就是后处理过程
我们不妨加上性能测试,把model_hw_shape改成自己模型的大小,也记得把模型路径和图片路径修改一下-

接下来打开postprocess.py,把第21行的num_classes改成自己模型的class数量-

再看35行的3个box-

reshape的第2,3个参数,就是你模型尺寸分别除以8,16,32;第5个参数要改成刚才的num_classes+5-
修改完成,运行test_yolov5.py-

-

推理时间约42ms,已经和pc端运行很相近了,但模型精度较低低,且后处理时间依然较长
关于模型的精度校准,工具链手册中有提到,大家可以参考
至于后处理方面的话,极度建议大家去看小玺玺大佬的文章,其中提到了使用cython加速后处理,效果拔群
总结
使用X3pi已经半年多了,目前也着手使用X3pi参加一些比赛,作为国产真的是十分优秀的,尽管BPU的使用较麻烦,但多多询问地平线的技术人员(万分感谢徐总!),借助手册(这里不得不说X3pi的手册是真的太全了),教程等帮助后会发现其实BPU作为模型推理的算力是真的很强大,而且调通后会有一种国产自豪感(手动狗头),期待地平线的更多产品