注:本文内容适用于J5 OE 1.1.74版本之前,从1.1.74版本开始新增了pointpillars预处理DSP代码,并且将centerpoint预处理代码做了优化且文件名称修改为了centerpoint而非pointpillar,请用户注意辨别。
前言
在自动驾驶应用中,除了在2D图像中检测目标之外,往往还需要在3D空间中做检测,如汽车、行人、自行车等。雷达通过构建3D空间的点云,可以提供一种精确、高空间维度、高分辨率的数据,弥补3D空间的距离信息。-
在雷达点云算法中,pointpillars(后文简称PP)和centerpoint(后文简称CP)表现突出,地平线的J5工具链已将这两种算法集成为参考算法供开发者使用,PP针对四维点云数据做单类别3D检测,CP针对五维点云数据做多类别3D检测。针对板端部署的需求,ai benchmark示例提供了PP和CP的C++后处理代码,以及CP的C++预处理代码。其中,CP的C++预处理代码包括了纯CPU的实现,以及结合了DSP和CPU的加速实现。上述内容从J5工具链的1.1.57版本开始全部支持。-
**本文首先会对CP算法的C++预处理,包括纯CPU实现和DSP+CPU的加速实现做简单说明,之后会介绍如何修改CP预处理代码,让其支持PP所需的四维点云输入。**在正式阅读本文前,建议大家优先学习社区文章《DSP开发快速上手》和J5工具链手册《AI-Benchmark使用说明》章节。
CP预处理C++代码说明
CP预处理的C++实现源码,位于J5工具链交付包的以下路径:-
ddk/sampls/ai_benchmark/code/src/method/qat_centerpoint_preprocess_method.cc-
纯CPU实现,以及结合了DSP和CPU的加速实现,均包含在该代码文件中(其中DSP部分的源码在OE包的vdsp_rpc_sample目录)。同时,在J5工具链用户手册的《DSP示例包使用说明》章节,已对这两种实现方案做了细致的介绍,因此这里只做简单梳理。
CP模型输入分析
点云数据-
CP模型基于nuscenes的lidar数据训练,OE包提供了少量数据以进行性能测试,可以在以下路径找到:-
ddk/samples/ai_benchmark/j5/qat/mini_data/nuscenes_lidar-
CP模型使用的点云文件是点云数为30万的五维数据,五维依次是(x,y,z,r,t),分别表示点的x轴坐标、y轴坐标、z轴坐标、r反射强度、t时间戳。-
模型输入信息-
CP模型位于以下目录:-
ddk/samples/ai_benchmark/j5/qat/model/runtime/centerpoint_pointpillar_nuscenes-
将model.hbm复制到开发板,之后在板端运行以下命令即可查看CP模型的输入信息:-
hrt_model_exec model_info --model_file model.hbm-
CP模型的输入信息如下所示:
[model name]: centerpoint_pointpillar_nuscenes
input[0]:
name: arg0[coors]_torch_native
input source: HB_DNN_INPUT_FROM_DDR
valid shape: (1,1,40000,4,)
aligned shape: (1,1,40000,4,)
aligned byte size: 640000
tensor type: HB_DNN_TENSOR_TYPE_S32
tensor layout: HB_DNN_LAYOUT_NHWC
quanti type: SHIFT
stride: (640000,640000,16,4,)
shift data: 0,0,0,0,
quantizeAxis: 3
input[1]:
name: arg0[features]
input source: HB_DNN_INPUT_FROM_DDR
valid shape: (1,5,20,40000,)
aligned shape: (1,5,20,40000,)
aligned byte size: 4000000
tensor type: HB_DNN_TENSOR_TYPE_S8
tensor layout: HB_DNN_LAYOUT_NCHW
quanti type: SCALE
stride: (4000000,800000,40000,1,)
scale data: 0.00776405,0.00776405,0.00776405,0.00776405,0.00776405,
quantizeAxis: 1
可以看到,CP模型有两个输入,其中input[0]是坐标信息,input[1]是特征信息。一份点云数据在经过预处理后,会转变为符合CP模型输入要求的两份输入数据。-
预处理结果解读-
input[0]/坐标信息的layout为1x1x40000x4,其中40000表示柱体数量,4表示柱体坐标(0, 0, y, x)。-
input[1]/特征信息的layout为1x5x20x40000,其中5表示点云的五维xyzrt,20表示每个柱体中的点云数。
CP预处理纯CPU实现
CP预处理的纯CPU实现,主要由3个重要函数组成。

GenVoxel-
该函数做了体素化操作,包括计算和访存,遍历全部点云数据并将无效的过滤,通过计算伪图像坐标并转换为一维索引的方式,更新每个柱体的坐标,进而计算出所有柱体的坐标信息(即上文的input[0]),并将点云数据写入到一个个柱体中。-
GenFeatureDim5-
该函数针对柱体中的点云数据,做了特征编码和量化计算。将量化计算和前处理融合,是一个常见的性能优化思路,因为可以减少数据遍历的次数,尤其是在点云这种输入数据量较大的场景下,能有效减少耗时。量化值可以使用API(hbDNNGetInputTensorProperties)从模型输入张量中获取。-
TransposeDim5-
经过上述计算后,特征信息的数据排布是1x40000x20x5,不符合CP模型input[1]的输入要求,因此需要在这一步将layout转变为1x5x20x40000。-
这里之所以要对layout做出调整,是因为根据BPU硬件对齐规则,原有的layout方式会有大量padding操作,为避免浪费算力在无效计算上,需要将较大的维度(40000)放在最后。-
至此,CP模型input[0]和input[1]所需的数据已经准备完毕。
CP预处理DSP+CPU加速实现
实现方案-

在ai benchmark示例中,同时也包含了DSP+CPU加速实现的预处理代码。DSP比CPU更擅长并行计算,在处理大量数据时,具有极高的运行效率,但考虑到DSP硬件方面的限制,预处理中体素化计算的访存操作还是放在了CPU。对于该加速实现方案,坐标信息和特征信息的计算流程如下所示:-
input[0](坐标信息):体素化计算(DSP)-
input[1](特征信息):体素化计算(DSP)+ 体素化访存(CPU)+ 特征编码、量化、转置(DSP)-
由于该方案中间回到了CPU计算,因此一共需要调用两次hbDSPRpc接口。-
性能对比-
以下展示在单核单线程下,10帧点云数据的Latency测试结果对比。由于点云前处理的耗时与输入数据的分布和有效点云的数量相关,因此数值波动较大。
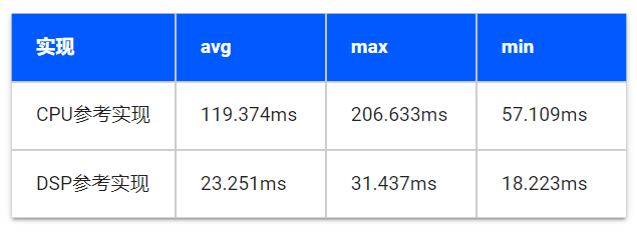
可以看出,对于加速实现方案,即便有访存操作回归到了CPU上,也依然在总体性能上遥遥领先。
PP预处理修改指导
J5的OE包提供了针对五维点云数据的CP模型的C++预处理代码,但如果您在实际部署时,选择了PP模型,那么可以根据以下指导,对CP模型的C++预处理代码做修改,以适应四维点云输入。
PP模型输入分析
导出不含预处理的PP模型-
对于PP参考算法,导出的模型默认包含有预处理,因此您需要先参考社区文章《Pointpillars导出不含预处理模型的配置说明》导出不含预处理的PP模型。-
点云数据-
PP和CP使用的点云数据集是不同的,点云文件在维度上存在差异,因此导致了算法前处理也存在差异。-
PP使用kitti3d数据集训练,OE包提供了少量数据以进行性能测试,可以在以下路径找到:-
ddk/samples/ai_benchmark/j5/qat/mini_data/kitti3d-
PP模型使用的点云文件是点云数为15万的四维数据,四维依次是(x,y,z,r),分别表示点的x轴坐标、y轴坐标、z轴坐标、r反射强度。相比于CP,少了第五维t时间戳。-
模型输入信息-
将编译出的hbm文件复制到开发板,之后在板端运行hrt_model_exec工具查看不含预处理的PP模型的输入信息:
[model name]: pointpillars_kitti_car
input[0]:
name: arg0[coordinates]_torch_native
input source: HB_DNN_INPUT_FROM_DDR
valid shape: (1,1,12000,4,)
aligned shape: (1,1,12000,4,)
aligned byte size: 192000
tensor type: HB_DNN_TENSOR_TYPE_S32
tensor layout: HB_DNN_LAYOUT_NHWC
quanti type: SHIFT
stride: (192000,192000,16,4,)
shift data: 0,0,0,0,
quantizeAxis: 3
input[1]:
name: arg0[voxels]
input source: HB_DNN_INPUT_FROM_DDR
valid shape: (1,4,12000,100,)
aligned shape: (1,4,12000,128,)
aligned byte size: 6144000
tensor type: HB_DNN_TENSOR_TYPE_S8
tensor layout: HB_DNN_LAYOUT_NCHW
quanti type: SCALE
stride: (6144000,1536000,128,1,)
scale data: 0.0078125,0.0078125,0.0078125,0.0078125,
quantizeAxis: 1
可以看到,PP模型有两个输入,其中input[0]是坐标信息,input[1]是体素信息(对应CP的input[1]/特征信息)。一份点云数据在经过预处理后,会转变为符合PP模型输入要求的两份输入数据。-
无论是否经过训练,PP模型的scale都为0.0078125(即1/128)。-
预处理结果解读-
input[0]/坐标信息的layout为1x1x12000x4,其中12000表示柱体数量,4表示柱体坐标(0, 0, y, x)。-
input[1]/特征信息的shape有两种,valid shape为1x4x12000x100,aligned shape为1x4x12000x128,其中4表示点云的四维xyzr,100或128表示每个柱体中的点云数,在对预处理代码做修改时,需要考虑到对这个维度新增padding操作,并且在layout方面,PP和CP也有所区别。-
PP与CP的输入对比如下:

PP预处理纯CPU实现
您可以参考以下步骤,对代码进行修改。这里基于J5 OE 1.1.60的代码做调整,原始代码和1.1.57版本略有区别,但从1.1.60开始,源码不再有变动。-
GenVoxel-
只需将函数最后的*(voxel_data_ + total_offset + 4) = point[4];注释即可,因为四维点云没有第五维的t时间戳。代码其他部分保持不变。-
GenFeatureDim5-
虽然scale发生了变化,但由于scale是从模型中读取的,因此scale相关代码不需要变动。-
对于config_->pillar_point_num[i]的if判断,可以把符号>右侧的config_->kmax_num_point_pillar_vec[j]替换为j,防止出现数值越界。-
最后将voxel_data_[index + 4] != 0的if判断注释掉,因为四维数据不需要对这一维进行操作。
void QATCenterPointPreProcessMethod::GenFeatureDim5(float scale) {
for (int i = 0; i < voxel_num_; i++) {
int idx = i * config_->kmax_num_point_pillar * config_->kdim;
for (int j = 0; j < config_->kmax_num_point_pillar; ++j) {
if (config_->pillar_point_num[i] > j) {
int index = idx + j * config_->kdim;
voxel_data_[index + 0] =
(voxel_data_[index + 0] - config_->kback_border) / //特征编码和量化
config_->kx_range / scale;
voxel_data_[index + 1] =
(voxel_data_[index + 1] - config_->kright_border) /
config_->ky_range / scale;
voxel_data_[index + 2] =
(voxel_data_[index + 2] - config_->kbottom_border) /
config_->kz_range / scale;
voxel_data_[index + 3] = (voxel_data_[index + 3] - config_->kr_lower) /
config_->kr_range / scale;
//if (voxel_data_[index + 4] != 0) { //注释+4的部分
// voxel_data_[index + 4] = voxel_data_[index + 4] / scale;
//}
}
}
}
}
TransposeDim5-
转置函数的修改方式较为复杂,因为在layout和padding方式上均有变化,同时需要修改量化计算的方式,以对齐参考算法,防止出现量化后的计算结果出现数值偏差1的问题。
void QATCenterPointPreProcessMethod::TransposeDim5() {
int kWC = config_->kmax_num_point_pillar * config_->kdim;
int kHW = config_->kmax_num_point * config_->kmax_num_point_pillar;
for (int c = 0; c < config_->kdim; ++c) {
for (int h = 0; h < voxel_num_; ++h) { //调整转置
for (int w = 0; w < config_->kmax_num_point_pillar; ++w) {
int old_index = h * kWC + w * config_->kdim + c;
int new_index = c * config_->kmax_num_point * 128 + h * 128 + w;
//float features_tmp = round(static_cast<float>(voxel_data_[old_index]));
float features_tmp = std::floor(static_cast<float>(voxel_data_[old_index])+0.5);
features_tmp = std::min(std::max(features_tmp, -128.f), 127.f);
features_s8_[new_index] = static_cast<int8_t>(features_tmp);
}
}
}
}
内存操作-
由于每个柱体内的点云数这个维度需要从100padding到128,因此内存分配和初始化的代码也需要做相应修改:
features_s8_ = static_cast<int8_t *>(
malloc(config_->kmax_num_point * (config_->kmax_num_point_pillar+28) *
config_->kdim * sizeof(int8_t)));
memset(features_s8_,
0,
config_->kmax_num_point * (config_->kmax_num_point_pillar+28) *
config_->kdim * sizeof(int8_t));
config-
配置文件位于以下路径:-
ddk/samples/ai_benchmark/j5/qat/script/config/preprocess/centerpoint_preprocess_5dim.json-
PP模型的config配置文件和CP不同,需要修改成以下数值:
{
"dim": 4,
"max_num_point": 12000,
"max_num_point_pillar": 100,
"back": 0.0,
"front": 69.12,
"right": -39.68,
"left": 39.68,
"bottom": -3.0,
"top": 1.0,
"r_lower": 0.0,
"r_upper": 1.0,
"x_scale": 0.16,
"y_scale": 0.16,
"x_bev_scale": 0.0,
"y_bev_scale": 0.0,
"run_on_dsp": false
}
到这里,就完成了PP预处理纯CPU实现的所有修改步骤。
PP预处理DSP+CPU加速实现
考虑到DSP开发需要向地平线申请License,因此若您希望修改DSP+CPU的加速实现方案,请联系地平线技术支持。
