在RDKX5上部署YOLO11时出现了问题,请求各位大佬帮助
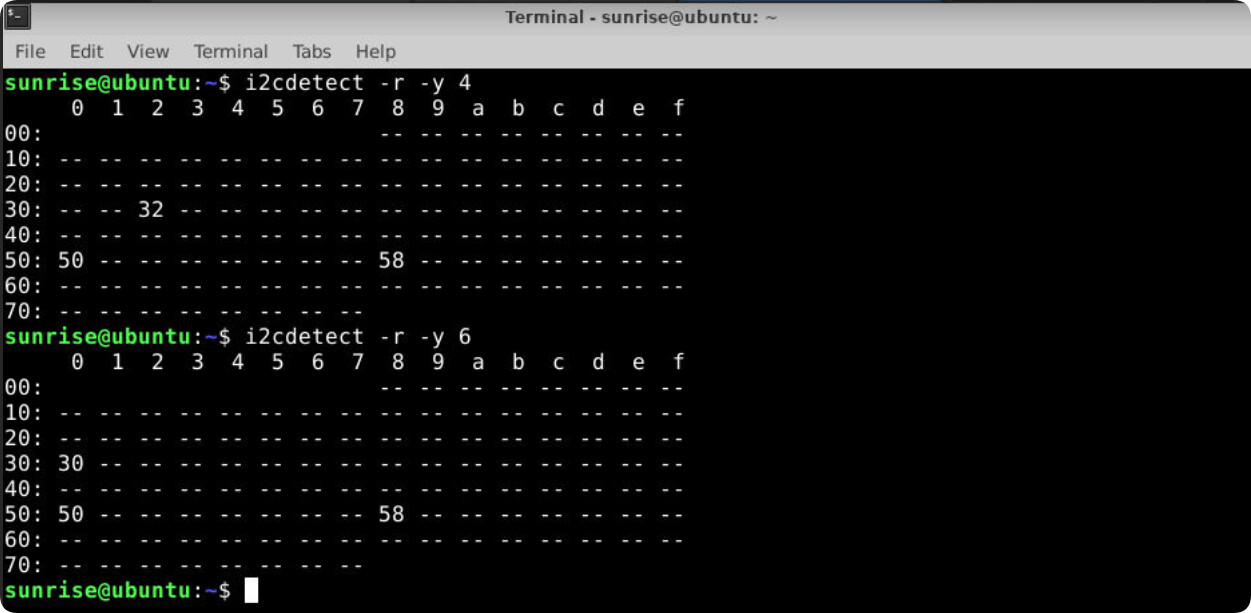
用python方法说找不到摄像头,摄像头是sc230ai,ls -l /dev/video*也说找不到,但我用tros部署官方的yolov2模型是正常的,摄像头硬件应该是没连错
can’t open camera by index
以下是原python部署代码有更改的部分
# 日志模块配置
# logging configs
logging.basicConfig(
level = logging.DEBUG,
format = '[%(name)s] [%(asctime)s.%(msecs)03d] [%(levelname)s] %(message)s',
datefmt='%H:%M:%S')
logger = logging.getLogger("RDK_YOLO")
parser = argparse.ArgumentParser()
parser.add_argument('--model-path', type=str, default='/home/sunrise/yolo/baitiao_modified.bin',
help="""Path to BPU Quantized *.bin Model.
RDK X3(Module): Bernoulli2.
RDK Ultra: Bayes.
RDK X5(Module): Bayes-e.
RDK S100: Nash-e.
RDK S100P: Nash-m.""")
parser.add_argument('--test-img', type=str, default='/home/sunrise/yolo/2.png', help='Path to Load Test Image.')
parser.add_argument('--img-save-path', type=str, default='jupyter_result.jpg', help='Path to Load Test Image.')
parser.add_argument('--classes-num', type=int, default=1, help='Classes Num to Detect.')
parser.add_argument('--reg', type=int, default=16, help='DFL reg layer.')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IoU threshold.')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold.')
opt = parser.parse_args()
logger.info(opt)
def signal_handler(signal, frame):
sys.exit(0)
…
def postProcess(self, outputs: list[np.ndarray]) → tuple[list]:
begin_time = time()
# reshape
s_bboxes = outputs[0].reshape(-1, 64)
m_bboxes = outputs[1].reshape(-1, 64)
l_bboxes = outputs[2].reshape(-1, 64)
s_clses = outputs[3].reshape(-1, 1)
m_clses = outputs[4].reshape(-1, 1)
l_clses = outputs[5].reshape(-1, 1)
…
coco_names = [
“BAITIAO”
]
…
#if name == ‘main’: #主函数
# 打开 mipi camera
cap = cv2.VideoCapture(6) # 使用摄像头6
if not cap.isOpened():
print(“Cannot open camera”)
#sys.exit()
# 设置 camera的输出图像格式为 MJPEG, 分辨率 1920 x 1080
codec = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
cap.set(cv2.CAP_PROP_FOURCC, codec)
cap.set(cv2.CAP_PROP_FPS, 30)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 640)
# Get HDMI display object
# 获取HDMI显示对象
#"""
#disp = srcampy.Display()
# For the meaning of parameters, please refer to the relevant documents of HDMI display
#disp_w, disp_h = get_display_res()
#disp.display(0, 640, 480)
#disp.display(0, disp_w, disp_h)
#print(disp_w,disp_h)
#"""
#显示输入尺寸
#model = dnn.load('./byolo11n_detect_bayese_640x640_nv12.bin')
model = YOLO11_Detect(opt.model_path, opt.conf_thres, opt.iou_thres)
start_time = time()
image_counter = 0
#-------------------------------------------------------------------------------------------------------
while True: #主循环
#读取摄像头帧
ret, frame = cap.read()
if not ret:
print(“Can’t receive frame (stream end?). Exiting …”)
break
nv12_data = model.bgr2nv12(frame)
#outputs = model[0].forward(nv12_data)
outputs = model.c2numpy(model.forward(nv12_data)) # 模型推理
ids, scores, bboxes = model.postProcess(outputs) # 后处理
# 在处理检测结果之前添加检查
if len(ids) == 0:
logger.info("No objects detected.")
else:
for class_id, score, bbox in zip(ids, scores, bboxes):
x1, y1, x2, y2 = bbox
logger.info("(%d, %d, %d, %d) -> %s: %.2f" % (x1, y1, x2, y2, coco_names[class_id], score))
draw_detection(frame, (x1, y1, x2, y2), score, class_id)
# 保存结果
#tensor = <dnnpy.PyDNNTensor object at 0xffff74e48ad0>
#print(dir(tensor))
#prediction_bbox = postprocess(outputs, input_shape, origin_img_shape=(1080,1920))
"""
HDMI输出
"""
#"""
#resized_data = cv2.resize(frame,(1920,1080))#如果压缩或者1拉升只有十五帧左右
#resized_data = frame
#nv12_data = bgr2nv12_opencv(resized_data)#通过上面函数转化成HDMI显示屏可输出格式
#print("is ok")
#disp.set_img(nv12_data.tobytes())
#"""
#cv2.imshow("frame",frame)
"""
over
"""
# 显示图像
#cv2.imshow('Original', frame)
#if ser.in_waiting:
# data_receive_from_uart = ser.read_until(b"\n").decode('UTF-8')
# print("\033[31m" + "--> RDK X3 Received Message From ESP32: \n%s"%data_receive_from_uart + "\033[0m")
# 计算帧率
finish_time = time()
image_counter = image_counter + 1
#print(finish_time-begin_time)
if finish_time - start_time > 5:
print("FPS: {:.2f}".format(image_counter / (finish_time - start_time)))
start_time = finish_time
image_counter = 0
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
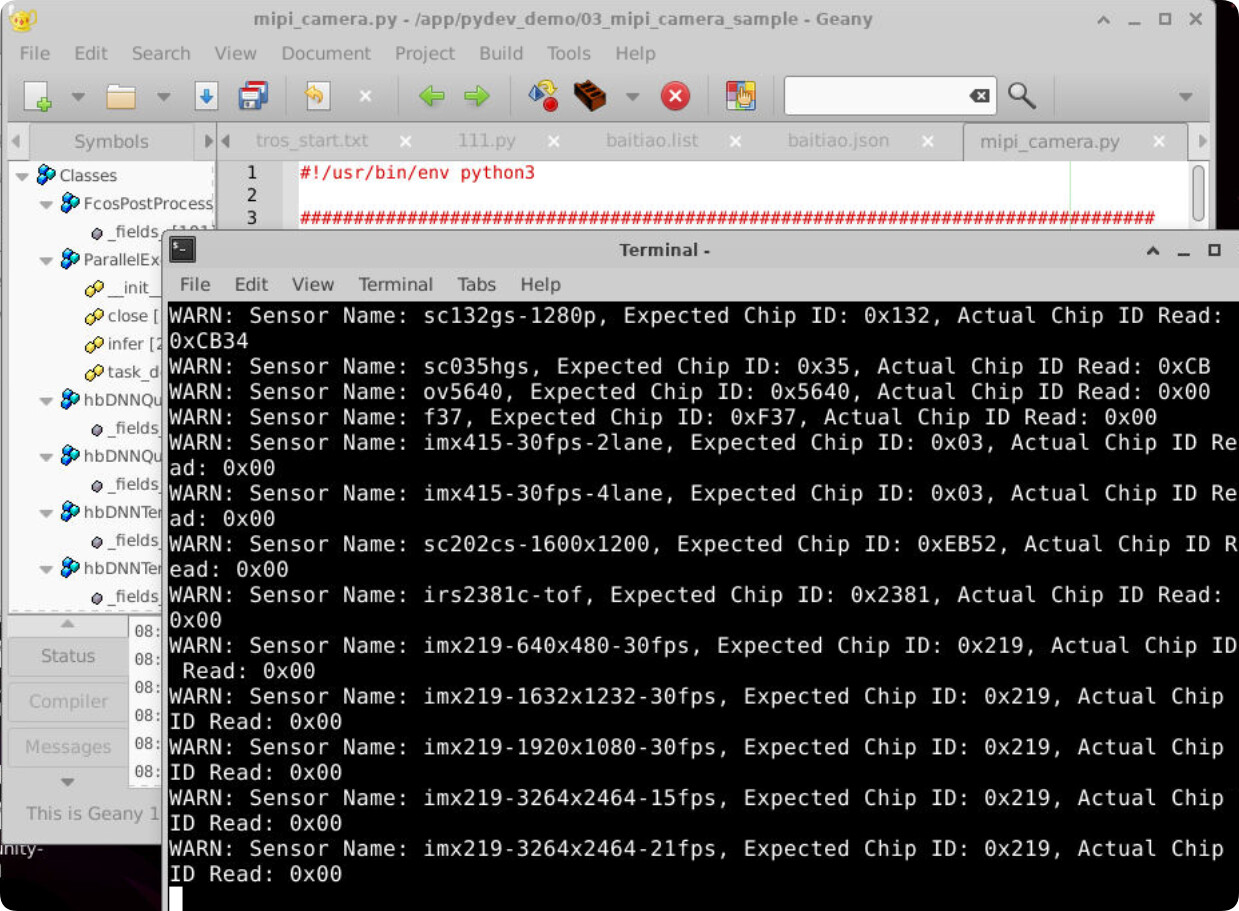
用tros会报错,而且我之前用config_file=/config/yolov2workconfig可以实现今天也报错了(可能因为今天我重新烧录了一次系统?)这是官方示例的报错
Camera calibration file is not exist
下面也是Websocket did not receive AI data
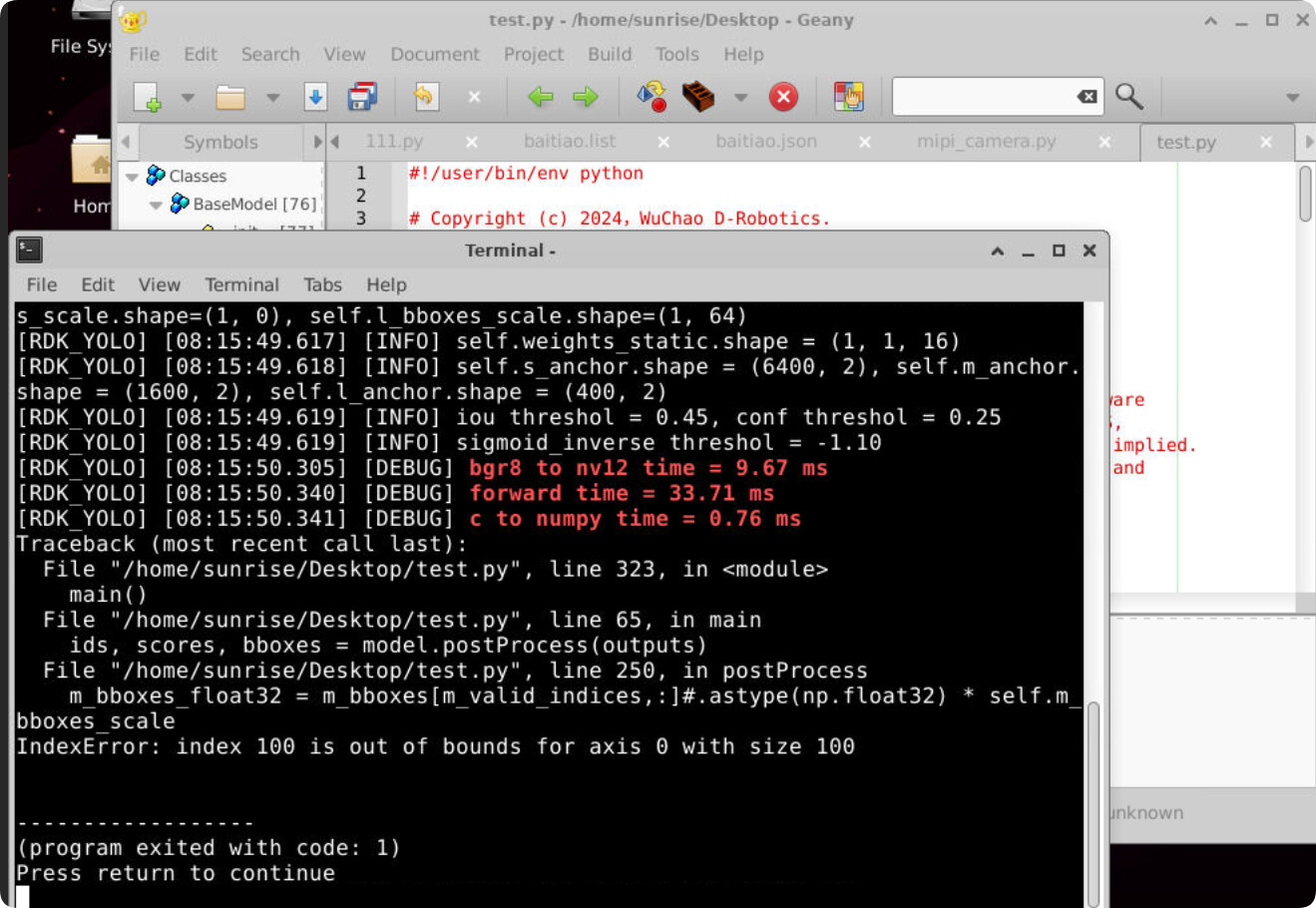
这是我自己的模型报错
Camera calibration file is not exist!
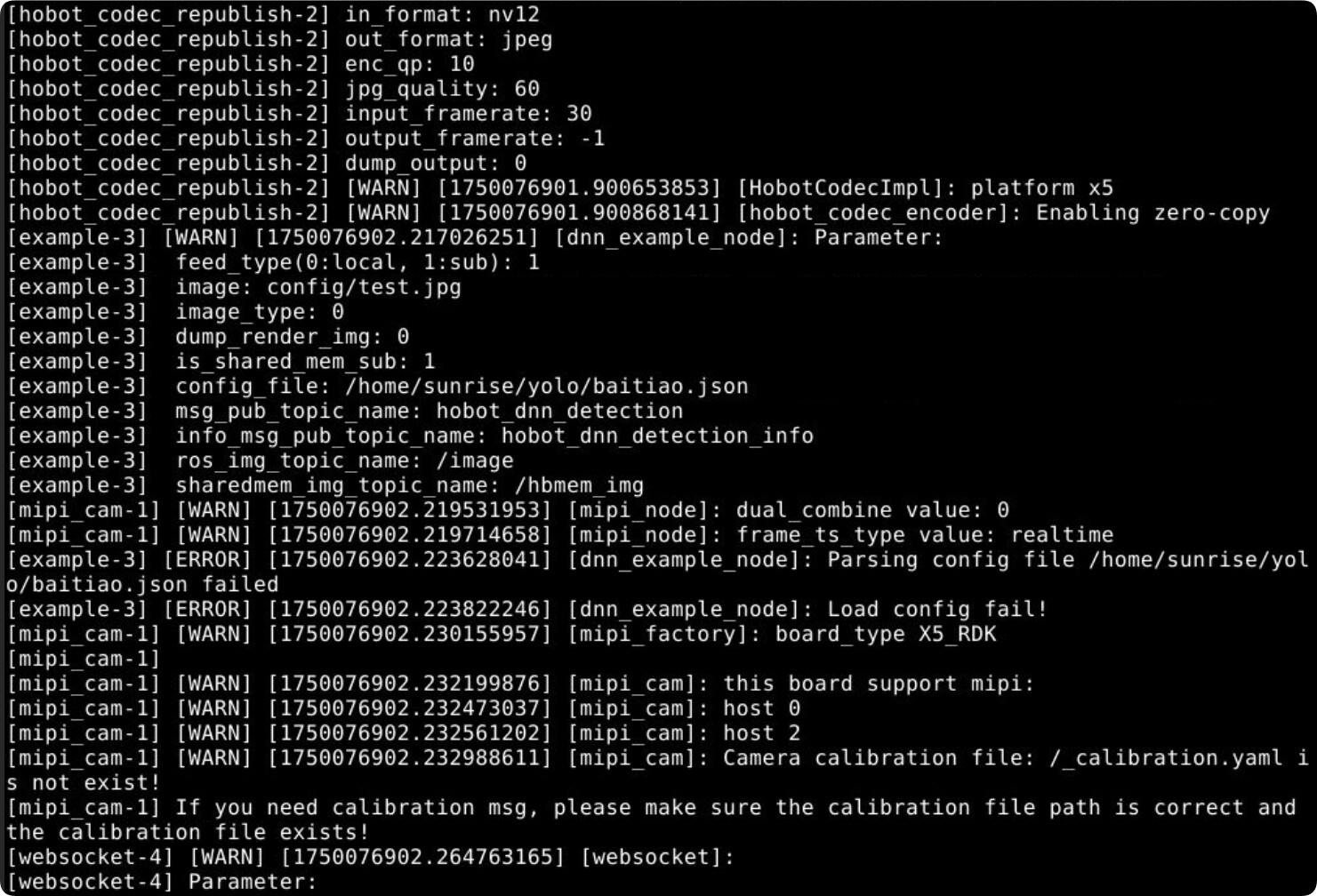
下面也是Websocket did not receive AI data
这是我的baitiao.json
{
“model_file”: “/home/sunrise/yolo/baitiao3_modified.bin”,
“task_num”: 4,
“dnn_Parser”: “yolov8”,
“model_output_count”: 6,
“reg_max”: 16,
“class_num”: 1,
“cls_names_list”: “/home/sunrise/yolo/baitiao.list”,
“strides”: [8, 16, 32],
“score_threshold”: 0.25,
“nms_threshold”: 0.7,
“nms_top_k”: 300,
# “output_order”: [0,1,2,3,4,5]
}
我的转换过程如下:
按教程先删ultralytics
优化block里的attention模块
def _forward(self, x):
“”"
Forward pass of the Attention module.
Args:
x (torch.Tensor): The input tensor.
Returns:
(torch.Tensor): The output tensor after self-attention.
"""
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, self.key_dim * 2 + self.head_dim, N).split(
[self.key_dim, self.key_dim, self.head_dim], dim=2
)
attn = (q.transpose(-2, -1) @ k) * self.scale
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, C, H, W) + self.pe(v.reshape(B, C, H, W))
x = self.proj(x)
return x
def forward(self, x):
print(f"{x.shape = }")
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, self.key_dim * 2 + self.head_dim, N).split(
[self.key_dim, self.key_dim, self.head_dim], dim=2
)
attn = (q.transpose(-2, -1) @ k) * self.scale
attn = attn.permute(0, 3, 1, 2).contiguous() # CHW2HWC like
max_attn = attn.max(dim=1, keepdim=True).values
exp_attn = torch.exp(attn - max_attn)
sum_attn = exp_attn.sum(dim=1, keepdim=True)
attn = exp_attn / sum_attn
attn = attn.permute(0, 2, 3, 1).contiguous() # HWC2CHW like
x = (v @ attn.transpose(-2, -1)).view(B, C, H, W) + self.pe(v.reshape(B, C, H, W))
x = self.proj(x)
return x
再修改head里面的输出头,两个顺序我都试过了都不行
def _forward(self, x):
“”“Concatenates and returns predicted bounding boxes and class probabilities.”“”
if self.end2end:
return self.forward_end2end(x)
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training: # Training path
return x
y = self._inference(x)
return y if self.export else (y, x)
def forward(self, x):
result = []
for i in range(self.nl):
result.append(self.cv2[i](x[i]).permute(0, 2, 3, 1).contiguous())
result.append(self.cv3[i](x[i]).permute(0, 2, 3, 1).contiguous())
return result
然后编译成.onnx
这是编译成.bin的yaml文件
model_parameters:
onnx_model: ‘./baitiao.onnx’
march: “bayes-e”
layer_out_dump: False
working_dir: ‘datasetworkenv’
output_model_file_prefix: ‘baitiao’
# YOLO11 n, s, m
node_info: {“/model.10/m/m.0/attn/Softmax”: {‘ON’: ‘BPU’,‘InputType’: ‘int16’,‘OutputType’: ‘int16’}}
# YOLO11 l, x
# node_info: {“/model.10/m/m.0/attn/Softmax”: {‘ON’: ‘BPU’,‘InputType’: ‘int16’,‘OutputType’: ‘int16’},
# “/model.10/m/m.1/attn/Softmax”: {‘ON’: ‘BPU’,‘InputType’: ‘int16’,‘OutputType’: ‘int16’}}
input_parameters:
input_name: “”
input_type_rt: ‘nv12’
input_type_train: ‘rgb’
input_layout_train: ‘NCHW’
norm_type: ‘data_scale’
scale_value: 0.003921568627451
calibration_parameters:
cal_data_dir: ‘./dataset’
cal_data_type: ‘float32’
compiler_parameters:
compile_mode: ‘latency’
debug: False
optimize_level: ‘O3’
编译出.bin后删除反量化系数,这是bin文件输出
[baitiao]
input[0]:
name: images
input source: HB_DNN_INPUT_FROM_PYRAMID
valid shape: (1,3,640,640,)
aligned shape: (1,3,640,640,)
aligned byte size: 614400
tensor type: HB_DNN_IMG_TYPE_NV12
tensor layout: HB_DNN_LAYOUT_NCHW
quanti type: NONE
stride: (0,0,0,0,)
output[0]:
name: output0
valid shape: (1,80,80,64,)
aligned shape: (1,80,80,64,)
aligned byte size: 1638400
tensor type: HB_DNN_TENSOR_TYPE_S32
tensor layout: HB_DNN_LAYOUT_NHWC
quanti type: SCALE
stride: (1638400,20480,256,4,)
scale data: 0.000400265,0.000335505,0.000401362,0.000324712,0.000252452,0.000259953,0.000339713,0.000298552,0.000256294,0.000217145,0.000184949,0.000199218,0.000225743,0.000214218,0.000266172,0.000240378,0.000334408,0.000330383,0.00029032,0.000300199,0.000313553,0.000273673,0.0002766,0.000258489,0.000255928,0.000264343,0.000277149,0.000346299,0.000594909,0.000507466,0.00067723,0.000257391,0.000380142,0.000354897,0.000374288,0.000292881,0.000294711,0.000343189,0.000421485,0.00032087,0.000276234,0.000249891,0.000242391,0.00025355,0.000228305,0.000218792,0.000234342,0.000210743,0.000394777,0.000381605,0.000308248,0.000266172,0.000348677,0.000347762,0.000288308,0.000250257,0.000202693,0.000207267,0.000241659,0.000266538,0.000143605,0.000151837,0.000195193,0.000183028,
quantizeAxis: 3
output[1]:
name: 615
valid shape: (1,80,80,1,)
aligned shape: (1,80,80,1,)
aligned byte size: 25600
tensor type: HB_DNN_TENSOR_TYPE_F32
tensor layout: HB_DNN_LAYOUT_NCHW
quanti type: NONE
stride: (25600,320,4,4,)
output[2]:
name: 623
valid shape: (1,40,40,64,)
aligned shape: (1,40,40,64,)
aligned byte size: 409600
tensor type: HB_DNN_TENSOR_TYPE_S32
tensor layout: HB_DNN_LAYOUT_NHWC
quanti type: SCALE
stride: (409600,10240,256,4,)
scale data: 0.000508657,0.00054944,0.000411608,0.000367427,0.000378944,0.000305685,0.000269622,0.000298133,0.000259993,0.000253762,0.000243189,0.000274154,0.000234692,0.000225629,0.000249608,0.000271133,0.000453147,0.000453147,0.000368559,0.00032721,0.000344958,0.000279252,0.000281517,0.000269056,0.000304552,0.000246399,0.000263014,0.000270566,0.000265468,0.000253196,0.000238091,0.000242622,0.000424447,0.000490154,0.000394615,0.000343447,0.000346846,0.00034628,0.000337972,0.000306818,0.000313427,0.000316825,0.000332685,0.000315315,0.000285294,0.000278685,0.000309084,0.000291902,0.000396881,0.00038272,0.000327965,0.000341937,0.000263203,0.00031286,0.000284161,0.000278874,0.000280196,0.00030814,0.000295678,0.00030021,0.000276042,0.000259049,0.000280762,0.000310028,
quantizeAxis: 3
output[3]:
name: 637
valid shape: (1,40,40,1,)
aligned shape: (1,40,40,1,)
aligned byte size: 6400
tensor type: HB_DNN_TENSOR_TYPE_F32
tensor layout: HB_DNN_LAYOUT_NCHW
quanti type: NONE
stride: (6400,160,4,4,)
output[4]:
name: 645
valid shape: (1,20,20,64,)
aligned shape: (1,20,20,64,)
aligned byte size: 102400
tensor type: HB_DNN_TENSOR_TYPE_S32
tensor layout: HB_DNN_LAYOUT_NHWC
quanti type: SCALE
stride: (102400,5120,256,4,)
scale data: 0.000407474,0.000465104,0.000411778,0.000406278,0.0003673,0.000494995,0.000385235,0.000395757,0.000343866,0.000359887,0.000446213,0.000414169,0.000443104,0.00126164,0.00189294,0.00188241,0.0004333,0.000430191,0.000398148,0.000370409,0.000346974,0.000380452,0.000395517,0.000309671,0.000401257,0.000436169,0.000358692,0.00032091,0.000543777,0.00263615,0.0289249,0.0149139,0.000379257,0.0004003,0.000375909,0.000453865,0.000385952,0.00034267,0.000335975,0.000318757,0.000296519,0.000361083,0.000368735,0.000411539,0.000862773,0.0016079,0.00237406,0.00736896,0.000381409,0.000395278,0.000362518,0.000382126,0.00031541,0.000391931,0.000327127,0.000333822,0.0003893,0.000380452,0.000309192,0.000333344,0.000431626,0.000755166,0.00100912,0.00110955,
quantizeAxis: 3
output[5]:
name: 659
valid shape: (1,20,20,1,)
aligned shape: (1,20,20,1,)
aligned byte size: 1600
tensor type: HB_DNN_TENSOR_TYPE_F32
tensor layout: HB_DNN_LAYOUT_NCHW
quanti type: NONE
stride: (1600,80,4,4,)
纯小白第一次接触开发板,只好跟着教程一步步走,如有低级错误请多多海涵,python部署部分仿照了 RDKx5板载yolov11我也是成功了! - 板卡使用 / 新手上路 - 地瓜机器人论坛 (d-robotics.cc)
请问我的问题出在了哪里,或者还需要我提供些什么来查错?
非常感谢!
总结
此文本将被隐藏