求助,rdkos_info如下
info.txt (12.2 KB)
目前需要测试大模型在bpu上运行的性能,但是之前搜到的帖子里只有一个准备好的demo和怎么用cpu直接运行语言模型,并没有怎么把大语言模型转换成hbm模型的流程。
在转换qwen2.5-0.5b的onnx模型时,提示sequence_length为动态维度且不在第一个维度报错,
 和这个问题一样,
和这个问题一样,
之后按测试的要求固定了序列长度为512,预处理数据输入尺寸也调整成了512,并且量化部分节点,转换成了hbm模型文件,但是推理的时候首token延迟,吞吐量和响应时间都很不理想,用的模型接口不管是model[0].forward还是model.run,都很慢,每次推理都好像生成了所有的token而不是生成一个然后在下一次推理时与前一次结果结合,如下
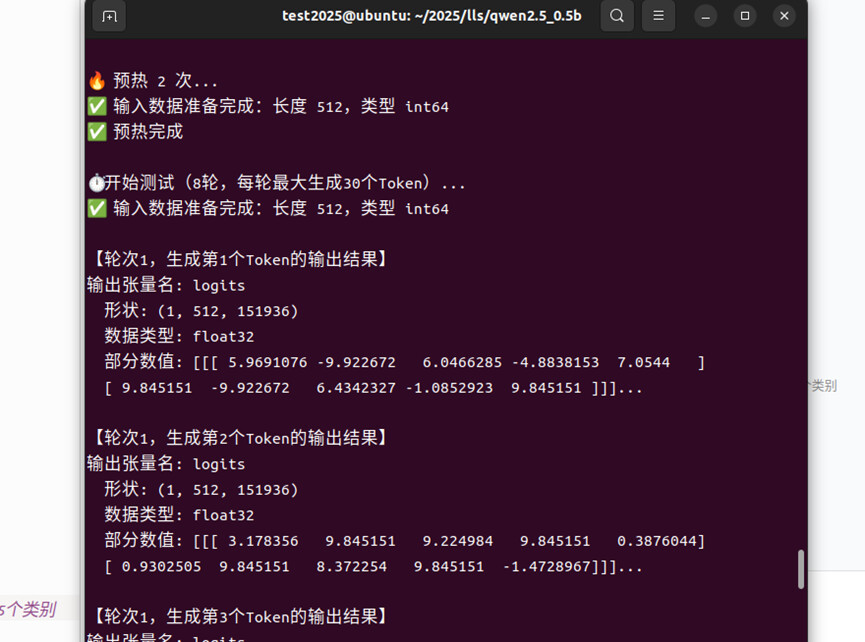
所以想请教一下,
第一,大模型的转换流程有没有规范一点的参考教程?可以让hbm可以接收动态序列长度;
第二,大模型推理用到的是不是model.run或者forward,如果是的话,这两个接口的结果是一次性生成了全部token还是只生成了这一次的?如果不是,有没有什么更好的方法?
如果有大佬有s100端大模型转换成功和测试成功的经验也跪求分享一下,万分感谢!!