1. 前言
随着深度学习的快速发展,Transformer算法在各类AI任务中都得到了广泛关注。然而,在AIoT等边缘计算场景中,Transformer的部署仍面临计算量大、延迟高等挑战。地瓜旭日5计算平台(以下简称X5)具备10 TOPS算力,能够支撑Transformer算法的高效推理。本文将介绍X5对Transformer的支持情况,并对性能优化方法做出详细说明,最后会以典型的Lightglue算法为例,介绍优化的完整流程。
2. 算子支持情况
X5 BPU对Transformer常用算子的支持情况如下:
-
Matmul:支持,输入输出可配置为int8。
-
Layernorm:支持,在X5算法工具链opset=11的限制条件下,Layernorm会被等效替换为ReduceMean,Sub,Pow,Add,Sqrt,Div,Mul等算子,以上算子输入输出均可配置为int8或int16。
-
Gelu:支持,在X5算法工具链opset=11的限制条件下,Gelu会被等效替换为Div,Erf,Add,Mul等算子,以上算子输入输出均可配置为int8或int16。
-
Softmax:支持,输入输出可配置为int8或int16。
-
Reshape /Transpose:支持,输入输出可配置为int8或int16。
可以看到,Transformer常用算子均被X5 BPU所支持,且除Matmul外,均支持int16高精度输入输出,为量化精度提供了保障。
3. 模型性能Benchmark
部分常见Transformer类算法在X5的运行效率如下表所示。这些算法在公版的基础上针对X5 BPU特性做了适配,且量化后精度指标的下降幅度均在1%以内。
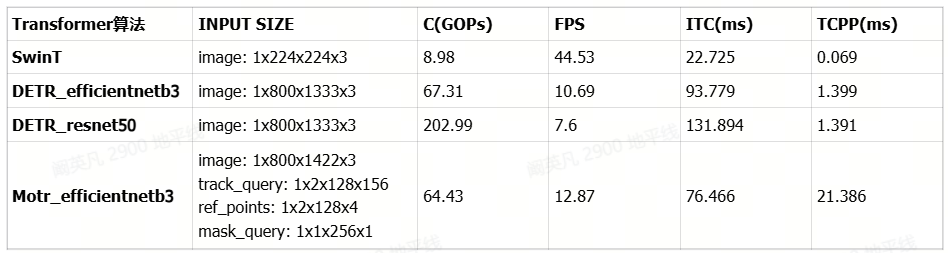
C = 运算量,BPU推理一帧数据要做的运算次数,1G为10亿次。
FPS = 每秒帧率。
ITC = 推理耗时,单位为ms(毫秒)。
TCPP = 后处理耗时,单位为ms(毫秒)。
4. 性能优化策略
尽管X5具备高效部署Transformer算法的能力,但由于Transformer结构的复杂性和特殊性,直接部署公版模型有时会不可避免地会遇到性能瓶颈,导致端侧推理速度较慢。这里介绍几种部署Transformer算法时常见的性能问题并提供优化策略。所有算子的耗时分析均基于模型编译时生成的html性能预估文件进行。
4.1 优化 Softmax 维度
以DETR算法为例,公版算法17个Softmax的总耗时约为58ms,地瓜优化算法17个Softmax总耗时约为42ms,有16ms的优化。
这些差异主要体现在SelfAttention部分,公版算法是对1x8x1050x1的Shape做Softmax,而地瓜优化算法是对8x25x42x1的Shape做Softmax。这个调整没有改变计算量,但是重排了Softmax的计算维度与批次结构,从而提高了并行度与缓存命中率。多个小Softmax(42维)比单个大Softmax(1050维)更容易并行化,并能让访存更加连续,减少访存延迟。多个Softmax同时分配到不同计算单元,使BPU计算资源被更高效地利用,从而有效降低计算耗时。
公版算法Softmax(1x8x1050x1)的静态耗时预估:

地瓜优化算法Softmax(8x25x42x1)的静态耗时预估:

X5对Softmax算子的量化策略为:将其替换为6个等效算子,再逐一对每个算子进行量化。
4.2 优化 BPU 硬件对齐耗时
这里还是以DETR算法为例,对于encoder中layers0的线性层计算,公版算法和地瓜优化算法的耗时情况如下:
公版算法

地瓜优化算法

可以看到,无论是公版算法还是地瓜优化算法,这两层结构的计算量都是相同的,均为1.1GOPs。但由于输入张量的Shape不同,导致耗时差异明显。公版算法的Shape是1x1050x1x2048和1x1050x256,受到BPU硬件对齐规则限制,第三维从1 Padding到8,大量计算资源消耗在无效数据上,造成了严重的算力浪费。而地瓜优化算法的Shape是1x25x42x2048和1x25x42x256,Padding规则仅仅将第二维的25变成26,第三维的42变成48,相比公版Shape节约了大量的BPU计算资源。仅这一处优化就可降低约3.6毫秒耗时,整个模型有多处相似结构,累计的性能提升非常明显。
更多BPU硬件对齐规则及优化策略的介绍,可以参考:X5高效模型设计指导
4.3 优化数据搬运耗时
数据搬运特指Reshape/Transpose这类不做数值计算,只做搬运操作的算子。对于SwinT算法,公版和地瓜优化版本在Transformer核心算子(如Softmax,Layernorm,Matmul)的计算耗时方面表现相当,主要区别在于Reshape和Transpose的耗时差异,具体如下表所示:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}| SwinT算法 | Transpose算子数量 | Transpose总耗时 | Reshape算子数量 | Reshape总耗时 |
|---|---|---|---|---|
| 公版 | 55 | 53.6 ms | 55 | 170 ms |
| 地瓜优化版 | 0 | 0 ms | 36 | 2.1 ms |
这种优化手段需要用户通过算法设计,尽可能规避模型中出现耗时明显的Transpose和Reshape算子。但也不是所有的Transpose和Reshape都有大量耗时,需要结合html静态性能报告进一步分析排查。
如果用户选择使用QAT链路进行Transformer算法的量化部署,X5算法工具链还提供了更多了性能优化手段。
4.4 使用 QAT 算子避免数据搬运
4.4.1 Matmul
在Transformer结构中,经常需要对Matmul的其中一个输入Transpose变换维度,这个Transpose往往会带来一定的性能开销。用户可以使用QAT封装的Matmul算子,该算子可以通过入参识别用户希望对哪个输入做维度变换,并在内部做高效处理,从而避免显式的Transpose操作。QAT封装的Matmul算子使用示例如下:
# 原本使用方式
k = k.transpose(-1, -2)
attention = torch.matmul(q, k)
# QAT使用方式
import horizon_plugin_pytorch.nn.quantized as quantized
self.matmul = quantized.FloatFunctional()
attention = self.matmul.matmul(q, k, x_trans=False, y_trans=True)
4.4.2 Layernorm
公版的Layernorm仅支持对最后若干维度做计算,如果要对中间维度做Layernorm,需要先Transpose。而使用QAT封装算子可以避免Transpose,直接对中间维度做Layernorm。具体使用方式如下:
# 原本使用方式
# NCHW -> NHWC
x = x.permute(0, 2, 3, 1)
# NHWC 按通道 C 做归一化
self.layernorm = nn.LayerNorm((C))
x = self.layernorm(x)
# NHWC -> NCHW
x = x.permute(0, 3, 1, 2)
# QAT使用方式
from horizon_plugin_pytorch.nn import LayerNorm as LayerNorm2d
# NCHW 按通道 C 做归一化
self.layernorm = LayerNorm2d([C, 1, 1], dim=1)
x = self.layernorm (x)
4.5 使用四维算子代替三维算子
X5 BPU的硬件特性决定了其对四维数据的支持更加高效,在地瓜优化版本的Transformer算法中,大量使用了四维算子替换三维算子,以充分发挥BPU的计算特性。QAT也提供了封装好的四维Transformer模块供用户使用,如MultiHeadAttention,PatchMerging等。
4.5.1 MultiHeadAttention
此处展示QAT四维算子HorizonMultiHeadAttention的部分定义,可在GPU Docker中访问/usr/local/lib/python3.10/dist-packageshat/models/base_modules/attention.py查看完整代码:
class HorizonMultiheadAttention(nn.Module):
"""modify torch.nn.MultiheadAttention to support quantization.
Args:
embed_dim: Total dimension of the model.
num_heads: Number of parallel attention heads.
Note that ``embed_dim`` will be split across ``num_heads``,
i.e. each head will have dimension ``embed_dim // num_heads``.
dropout: Dropout probability. Default: ``0.0`` (no dropout).
bias: If specified, adds bias to input / output projection layers.
Default: ``True``.
"""
def __init__(
self,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
bias: bool = True,
):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.bias = bias
self.head_dim = embed_dim // num_heads
assert (
self.head_dim * num_heads == self.embed_dim
), "embed_dim must be divisible by num_heads"
scale = self.head_dim ** -0.5
self.register_buffer("scale", torch.Tensor([scale]))
# define q k v projection layers
self.q_proj = nn.Conv2d(embed_dim, embed_dim, 1, bias=bias)
self.k_proj = nn.Conv2d(embed_dim, embed_dim, 1, bias=bias)
self.v_proj = nn.Conv2d(embed_dim, embed_dim, 1, bias=bias)
self.out_proj = nn.Conv2d(embed_dim, embed_dim, 1, bias=bias)
self.attention_drop = nn.Dropout(dropout)
self.softmax = nn.Softmax(dim=-1)
self.mul = quantized.FloatFunctional()
self.matmul = quantized.FloatFunctional()
self.add = quantized.FloatFunctional()
self.mask_add = quantized.FloatFunctional()
self.attn_matmul = quantized.FloatFunctional()
self.scale_quant = QuantStub()
self.attn_mask_quant = QuantStub(scale=1)
self._reset_parameters()
def forward(
self,
query: Tensor,
key: Tensor,
value: Tensor,
key_padding_mask: Optional[Tensor] = None,
attn_mask: Optional[Tensor] = None,
):
# set up shape vars
bsz, embed_dim, tgt_h, tgt_w = query.shape
_, _, src_h, src_w = key.shape
self.checkdim(embed_dim, key, value)
q = self.q_proj(query)
k = self.k_proj(key)
v = self.v_proj(value)
# prep attention mask
attn_mask, key_padding_mask = self.prep_attention_mask(
attn_mask, tgt_h, tgt_w, src_h, src_w, bsz, key_padding_mask,
)
q, k, v = self._view_qkv(bsz, src_h, src_w, tgt_h, tgt_w, q, k, v)
# update source sequence length after adjustments
src_len = k.size(3)
# merge key padding and attention masks
attn_mask = self.merge_key_padding_attention_masks(
key_padding_mask,
bsz,
src_len,
attn_mask,
)
# q = q * self.scale
# attention = (q @ k.transpose(-2, -1))
scale = self.scale_quant(self.scale)
q = self.mul.mul(
q, scale
) # [bsz*self.num_heads, tgt_h, tgt_w, self.head_dim]
attention = self.matmul.matmul(
q, k
) # [bsz*self.num_heads, tgt_h, tgt_w, src_h*src_w]
attention = self.mask_attention(
attention, attn_mask, tgt_h, tgt_w, src_h, src_w,
)
attention = self.softmax(attention)
attention = self.attention_drop(attention)
# output = (attention @ v)
attn_output = self.attn_matmul.matmul(
attention, v
) # [bsz*self.num_heads, tgt_h, tgt_w, self.head_dim]
attn_output = (
attn_output.permute(0, 3, 1, 2)
.contiguous()
.view(bsz, embed_dim, tgt_h, tgt_w)
)
attn_output = self.out_proj(attn_output)
return attn_output, None
4.5.2 PatchMerging
DETR算法的PatchMerging结构也可以使用四维算子做替换,示例如下:
# 原始的使用方式
class PatchMerging(nn.Module):
def _init_(self, dim, norm_layer):
super().__init_()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
self.cat = quantized.FloatFunctional()
def forward(self,x,H,W):
B, L, C = x.shape
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2
X2 = x[:, 0::2, 1::2, :] # B H/2 W/2
X3 = x[:, 1::2, 1::2, :] # B H/2 W/2
x = self.cat.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
if self.norm is not None:
x = self.norm(x)
x = self.reduction(x)
return x
# 4d算子的使用方式
class PatchMerging4d(nn.Module):
def _init_(self,dim,norm_layer):
super().__init_()
self.dim = dim
self.reduction = nn.Conv2d(4 * dim, 2 * dim, 1, bias=False)
self.norm = norm_layer(4 * dim)
self.cat = quantized.FloatFunctional()
def forward(self,x,H,W):
x0 = x[:, :, 0::2; :][:, :, :, 0::2] # B C H/2 W/2
x0 = x[:, :, 1::2; :][:, :, :, 0::2] # B C H/2 W/2
x0 = x[:, :, 0::2; :][:, :, :, 1::2] # B C H/2 W/2
x0 = x[:, :, 1::2; :][:, :, :, 1::2] # B C H/2 W/2
x = self.cat.cat([x0, x1, x2, x3], 1) # B 4*C H/2 W/2
if self.norm is not None:
x = self.norm(x)
x = self.reduction(x)
return x
4.6 使用Conv2d代替Vector计算
这里Vector并不是指std::vector或者一维向量,而是指模型中可以并行处理的一批数据元素,例如一个通道内的像素值。Vector计算通常指逐元素操作,如均值/求和/取最大值等,与之相对应的是Tensor计算。Transformer算法中比较典型的Vector计算有Elementwise、Reduce等,模型中如果Vector计算占比较多,会影响BPU利用率,导致部署性能下降。
在一些情况下,可以使用Conv2d等效替换Vector操作(如Mul/Reduce等)。像是Conv->ReduceSum->Conv串接的结构,其中ReduceSum就可以替换成Conv2d:比如reduce on C可以构建为input channel = C,output channel = 1的Conv2d;reduce on H/W 可以构建为kernel_h = H或kernel_w = W的Conv2d等。使用Conv2d代替Vector计算,会提升算法的部署性能,同时不影响计算精度。
5. Lightglue性能优化实战
LightGlue是一种图像特征点匹配算法,它的目标是在两张图像之间找到成对的关键点,常用于SLAM、三维重建或视觉定位等任务。Lightglue使用了Transformer的SelfAttention和CrossAttention机制,用于建模关键点之间的关系,并让一张图的关键点能够看到另一张图的所有关键点,再经过后处理完成特征点匹配。
本节我们重点分析Lightglue的Transformer结构,通过html静态性能分析报告了解部署性能瓶颈,并使用上一节介绍的优化策略提升性能,同时保持模型的输出一致性不变。最终Lightglue算法的BPU耗时预估从16.37ms下降到14.9ms,优化幅度达到9%,效果显著。
5.1 html分析报告解读
可以使用PTQ的fast-perf方法编译ONNX模型,得到html静态性能分析报告,此时报告中显示的latency为16.37ms。

通过算子耗时预估发现,在每个CrossAttention结构的开头,有两个Matmul算子各跟随一个Reshape,这两个Reshape的最后一维度会从16 Padding到128,导致需要耗费共485us,占模型总耗时的2.8%,该模型一共有5个CrossAttention结构,这10个Reshape一共耗时2.4ms,约占总耗时的14%,需要优化。
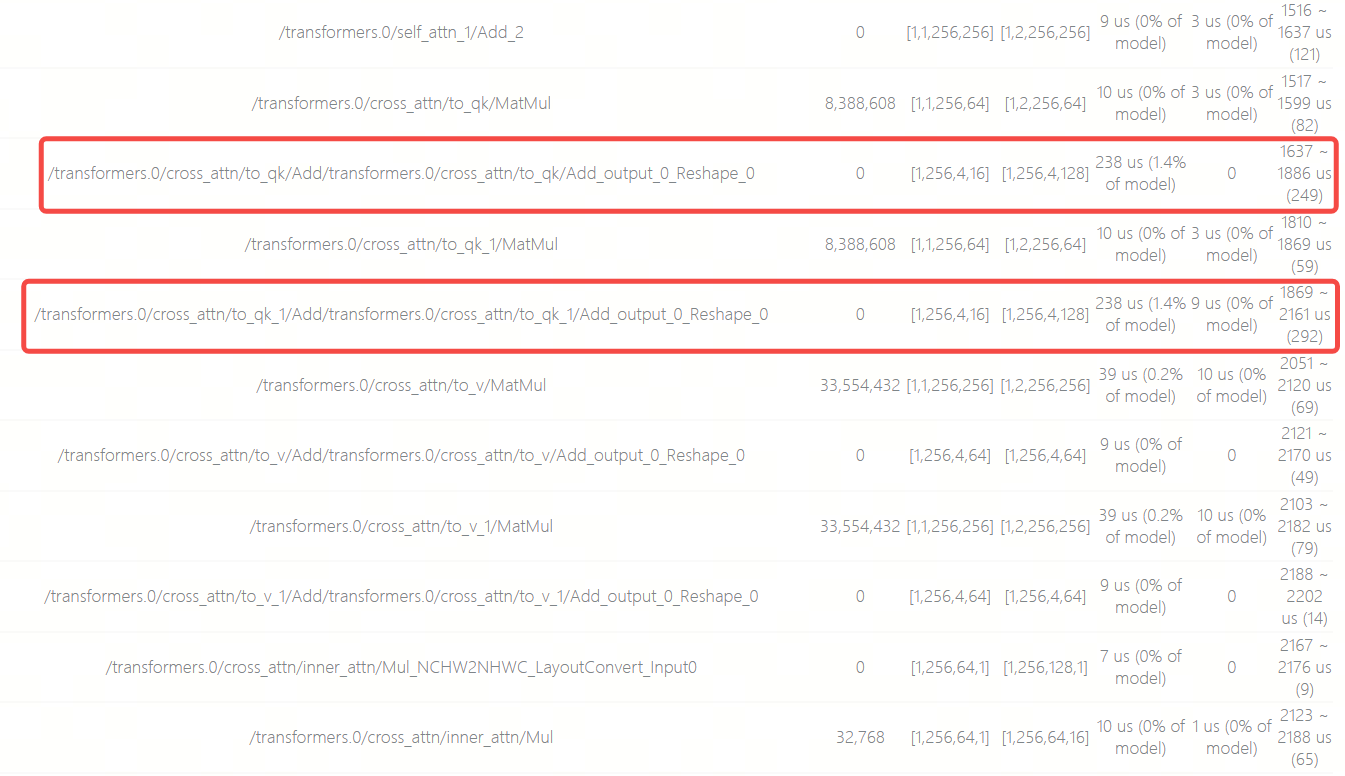
该模型并无其他耗时明显较高的算子,由此我们可以从Reshape入手优化模型结构,提升部署性能。
需要特别注意的是,html的算子耗时预估只体现单个算子的执行时间,实际BPU在推理模型时,会并行执行多个算子的计算指令,因此html中所有算子的累计耗时并不会等于模型的总耗时。
5.2 性能优化流程
CrossAttention结构的Pytorch源码如下所示,主要关注Attention和CrossBlock类的forward函数。为方便对比模型的Shape变化情况,forward代码的大部分变量均替换为固定数值,并使用注释标明每次计算后的Shape情况。
class Attention(nn.Module):
def __init__(self) -> None:
super().__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v) -> torch.Tensor:
attention = torch.matmul(q, k.permute(0, 1, 3, 2)) * 0.25
attention = self.softmax(attention)
x = torch.matmul(attention, v)
return x
class CrossBlock(nn.Module):
def __init__(
self, embed_dim: int, num_heads: int, flash: bool = False, bias: bool = True
) -> None:
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.to_qk = nn.Linear(embed_dim, int(embed_dim * 0.25), bias=bias)
self.to_v = nn.Linear(embed_dim, embed_dim, bias=bias)
self.inner_attn = Attention()
self.to_out = nn.Linear(embed_dim, embed_dim, bias=bias)
self.ffn = nn.Sequential(
nn.Linear(2 * embed_dim, 2 * embed_dim),
nn.LayerNorm(2 * embed_dim, elementwise_affine=True),
nn.GELU(),
nn.Linear(2 * embed_dim, embed_dim),
)
def forward(self, x0: torch.Tensor, x1: torch.Tensor) -> Tuple[torch.Tensor]:
B, N, C = x0.shape # ([1, 256, 256])
qk0 = self.to_qk(x0) # ([1, 256, 64])
qk1 = self.to_qk(x1) # ([1, 256, 64])
qk0 = qk0.reshape(1, 256, 4, 16).permute(0, 2, 1, 3) # ([1, 4, 256, 16])
qk1 = qk1.reshape(1, 256, 4, 16).permute(0, 2, 1, 3) # ([1, 4, 256, 16])
v0 = self.to_v(x0) # ([1, 256, 256])
v1 = self.to_v(x1) # ([1, 256, 256])
v0 = v0.reshape(1, 256, 4, 64).permute(0, 2, 1, 3) # ([1, 4, 256, 64])
v1 = v1.reshape(1, 256, 4, 64).permute(0, 2, 1, 3) # ([1, 4, 256, 64])
m0 = self.inner_attn(qk0, qk1, v1) # ([1, 4, 256, 64])
m1 = self.inner_attn(qk1, qk0, v0) # ([1, 4, 256, 64])
m0 = m0.permute(0, 2, 1, 3).reshape(1, 256, 256)
m1 = m1.permute(0, 2, 1, 3).reshape(1, 256, 256)
m0 = self.to_out(m0)
m1 = self.to_out(m1)
x0 = x0 + self.ffn(torch.cat([x0, m0], dim=-1))
x1 = x1 + self.ffn(torch.cat([x1, m1], dim=-1))
return x0, x1
通过对比代码和html信息,可以定位到CrossAttention中耗时最高的两个Reshape算子对应qk0 = qk0.reshape(1, 256, 4, 16).permute(0, 2, 1, 3)和qk1 = qk1.reshape(1, 256, 4, 16).permute(0, 2, 1, 3)这两句代码中的Reshape操作。
结合算法原理,可以发现这里的结构是将qk0/qk1做数据搬运后分别与v1/v0做Attention计算,在Attention中qk1/qk0又会做一次数据搬运。其中较高的耗时发生在数据搬运第一步的Reshape,Reshape的最后一维从16 Padding到256,带来了较高的BPU硬件对齐耗时。既然这样,我们可以考虑先做Transpose,将Tensor本身就有的256维移动到最后,再对前几维做Reshape。如此一来Tensor的最后一维就会直接符合BPU对齐规则,避免硬件对齐浪费计算资源。
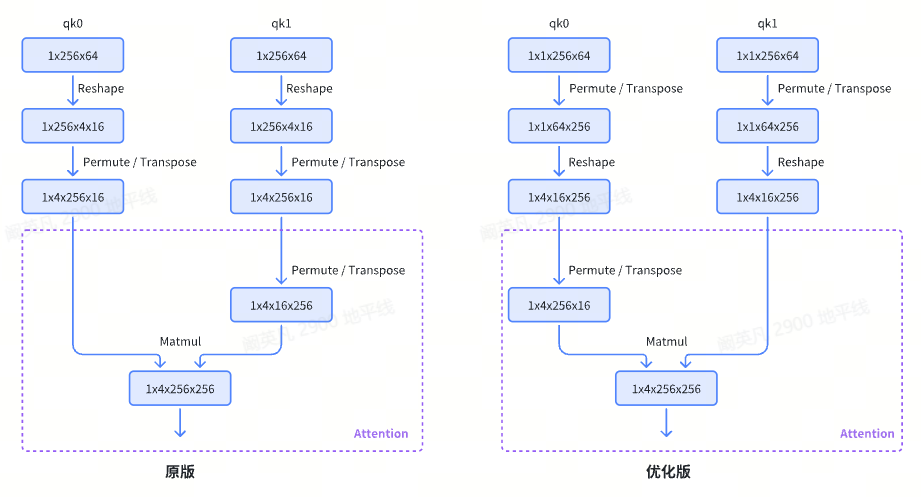
上方左图为原始版本的CrossAttention结构示意图,右图为重新整理数据排布后的示意图。这种调整不会影响计算精度,也不需要重训模型,原本训练好的权重可以直接加载到该模型中,并保证修改前后模型输出的一致性。
修改后的Pytorch代码如下,全部修改点为:
-
把CrossBlock模块中qk0和qk1扩展成四维,并将原本的先Reshape再Permute修改为先Permute再Reshape
-
去除Attention模块Matmul前对第二个张量做的Permute,改为对第一个张量做Permute
class Attention(nn.Module):
def __init__(self) -> None:
super().__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v) -> torch.Tensor:
attention = torch.matmul(q.permute(0, 1, 3, 2), k) * 0.25
attention = self.softmax(attention)
x = torch.matmul(attention, v)
return x
class CrossBlock(nn.Module):
def __init__(
self, embed_dim: int, num_heads: int, flash: bool = False, bias: bool = True
) -> None:
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.to_qk = nn.Linear(embed_dim, int(embed_dim * 0.25), bias=bias)
self.to_v = nn.Linear(embed_dim, embed_dim, bias=bias)
self.inner_attn = CrossBlockAttention()
self.to_out = nn.Linear(embed_dim, embed_dim, bias=bias)
self.ffn = nn.Sequential(
nn.Linear(2 * embed_dim, 2 * embed_dim),
nn.LayerNorm(2 * embed_dim, elementwise_affine=True),
nn.GELU(),
nn.Linear(2 * embed_dim, embed_dim),
)
def forward(self, x0: torch.Tensor, x1: torch.Tensor) -> Tuple[torch.Tensor]:
B, N, C = x0.shape # ([1, 256, 256])
qk0 = self.to_qk(x0) # ([1, 256, 64])
qk1 = self.to_qk(x1) # ([1, 256, 64])
qk0 = qk0.unsqueeze(0).permute(0, 1, 3, 2).reshape(1, 4, 16, 256)
qk1 = qk1.unsqueeze(0).permute(0, 1, 3, 2).reshape(1, 4, 16, 256)
v0 = self.to_v(x0) # ([1, 256, 256])
v1 = self.to_v(x1) # ([1, 256, 256])
v0 = v0.reshape(1, 256, 4, 64).permute(0, 2, 1, 3) # ([1, 4, 256, 64])
v1 = v1.reshape(1, 256, 4, 64).permute(0, 2, 1, 3) # ([1, 4, 256, 64])
m0 = self.inner_attn(qk0, qk1, v1) # ([1, 4, 256, 64])
m1 = self.inner_attn(qk1, qk0, v0) # ([1, 4, 256, 64])
m0 = m0.permute(0, 2, 1, 3).reshape(1, 256, 256)
m1 = m1.permute(0, 2, 1, 3).reshape(1, 256, 256)
m0 = self.to_out(m0)
m1 = self.to_out(m1)
x0 = x0 + self.ffn(torch.cat([x0, m0], dim=-1))
x1 = x1 + self.ffn(torch.cat([x1, m1], dim=-1))
return x0, x1
使用fast-perf编译优化后的模型,得到html静态性能分析报告,查看CrossAttention中的算子预估耗时,发现原本200us以上的Reshape操作已经消失,且所有数据搬运类算子均没有额外的BPU硬件对齐。现在的Reshape和Transpose算子均只有很轻微的耗时。

5.3 优化前后性能对比
通过统计html中,发现模型优化后,Reshape算子的累计耗时明显下降。
| 算子类型 | 优化前累计耗时 | 优化后累计耗时 |
|---|---|---|
| Reshape | 3.225 ms | 0.745 ms |
优化后模型的html静态性能分析报告显示完整模型的latency为14.9ms,显著低于原版的16.37ms,性能提升约9%,收益明显。

由此,可以认为已经较为理想地完成了对Lightglue模型中数据搬运算子的耗时优化。