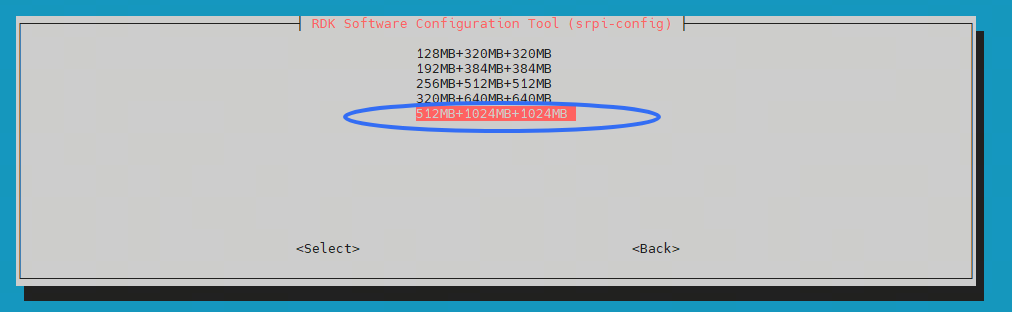
您好,我在RDK x5的板子上成功编译。但是运行的时候出现如下报错可以帮忙解答一下吗?我的文件层级是下面这样子的。应该没有放错路径。


root@ubuntu:~/model/llama.cpp_internvl2_bpu/llama.cpp# ./build/bin/llama-intern2vl-bpu-cli -m ./Qwen2.5-0.5B-Instruct-Q4_0.gguf --mmproj ./vit_model_int16_v2.bin --image image2.jpg -p “描述一下这张图片.” --temp 0.5 --threads 8
build: 0 (unknown) with cc (Ubuntu 11.2.0-19ubuntu1) 11.2.0 for aarch64-linux-gnu
llama_model_loader: loaded meta data with 38 key-value pairs and 291 tensors from ./Qwen2.5-0.5B-Instruct-Q4_0.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = qwen2
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Qwen2.5 0.5B Instruct
llama_model_loader: - kv 3: general.organization str = Qwen
llama_model_loader: - kv 4: general.finetune str = Instruct
llama_model_loader: - kv 5: general.basename str = Qwen2.5
llama_model_loader: - kv 6: general.size_label str = 0.5B
llama_model_loader: - kv 7: general.license str = mit
llama_model_loader: - kv 8: general.base_model.count u32 = 2
llama_model_loader: - kv 9: general.base_model.0.name str = InternViT 300M 448px V2_5
llama_model_loader: - kv 10: general.base_model.0.organization str = OpenGVLab
llama_model_loader: - kv 11: general.base_model.0.repo_url str = https://huggingface.co/OpenGVLab/Inte…
llama_model_loader: - kv 12: general.base_model.1.name str = Qwen2.5 0.5B Instruct
llama_model_loader: - kv 13: general.base_model.1.organization str = Qwen
llama_model_loader: - kv 14: general.base_model.1.repo_url str = https://huggingface.co/Qwen/Qwen2.5-0…
llama_model_loader: - kv 15: general.tags arr[str,3] = [“internvl”, “custom_code”, "image-te…
llama_model_loader: - kv 16: general.languages arr[str,1] = [“multilingual”]
llama_model_loader: - kv 17: qwen2.block_count u32 = 24
llama_model_loader: - kv 18: qwen2.context_length u32 = 32768
llama_model_loader: - kv 19: qwen2.embedding_length u32 = 896
llama_model_loader: - kv 20: qwen2.feed_forward_length u32 = 4864
llama_model_loader: - kv 21: qwen2.attention.head_count u32 = 14
llama_model_loader: - kv 22: qwen2.attention.head_count_kv u32 = 2
llama_model_loader: - kv 23: qwen2.rope.freq_base f32 = 1000000.000000
llama_model_loader: - kv 24: qwen2.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 25: qwen2.attention.layer_norm_epsilon f32 = 24.000000
llama_model_loader: - kv 26: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 27: tokenizer.ggml.pre str = qwen2
llama_model_loader: - kv 28: tokenizer.ggml.tokens arr[str,151674] = [“!”, “\”", “#”, “$”, “%”, “&”, “'”, …
llama_model_loader: - kv 29: tokenizer.ggml.token_type arr[i32,151674] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
llama_model_loader: - kv 30: tokenizer.ggml.merges arr[str,151387] = [“Ġ Ġ”, “ĠĠ ĠĠ”, “i n”, “Ġ t”,…
llama_model_loader: - kv 31: tokenizer.ggml.bos_token_id u32 = 151643
llama_model_loader: - kv 32: tokenizer.ggml.eos_token_id u32 = 151645
llama_model_loader: - kv 33: tokenizer.ggml.add_bos_token bool = false
llama_model_loader: - kv 34: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 35: tokenizer.chat_template str = {%- if tools %}\n {{- '<|im_start|>…
llama_model_loader: - kv 36: general.quantization_version u32 = 2
llama_model_loader: - kv 37: general.file_type u32 = 2
llama_model_loader: - type f32: 121 tensors
llama_model_loader: - type q4_0: 169 tensors
llama_model_loader: - type q8_0: 1 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = Q4_0
print_info: file size = 402.83 MiB (5.37 BPW)
load: special tokens cache size = 31
load: token to piece cache size = 0.9311 MB
print_info: arch = qwen2
print_info: vocab_only = 0
print_info: n_ctx_train = 32768
print_info: n_embd = 896
print_info: n_layer = 24
print_info: n_head = 14
print_info: n_head_kv = 2
print_info: n_rot = 64
print_info: n_swa = 0
print_info: n_embd_head_k = 64
print_info: n_embd_head_v = 64
print_info: n_gqa = 7
print_info: n_embd_k_gqa = 128
print_info: n_embd_v_gqa = 128
print_info: f_norm_eps = 0.0e+00
print_info: f_norm_rms_eps = 1.0e-06
print_info: f_clamp_kqv = 0.0e+00
print_info: f_max_alibi_bias = 0.0e+00
print_info: f_logit_scale = 0.0e+00
print_info: n_ff = 4864
print_info: n_expert = 0
print_info: n_expert_used = 0
print_info: causal attn = 1
print_info: pooling type = 0
print_info: rope type = 2
print_info: rope scaling = linear
print_info: freq_base_train = 1000000.0
print_info: freq_scale_train = 1
print_info: n_ctx_orig_yarn = 32768
print_info: rope_finetuned = unknown
print_info: ssm_d_conv = 0
print_info: ssm_d_inner = 0
print_info: ssm_d_state = 0
print_info: ssm_dt_rank = 0
print_info: ssm_dt_b_c_rms = 0
print_info: model type = 1B
print_info: model params = 629.70 M
print_info: general.name = Qwen2.5 0.5B Instruct
print_info: vocab type = BPE
print_info: n_vocab = 151674
print_info: n_merges = 151387
print_info: BOS token = 151643 ‘<|endoftext|>’
print_info: EOS token = 151645 ‘<|im_end|>’
print_info: EOT token = 151645 ‘<|im_end|>’
print_info: LF token = 198 ‘Ċ’
print_info: FIM PRE token = 151659 ‘<|fim_prefix|>’
print_info: FIM SUF token = 151661 ‘<|fim_suffix|>’
print_info: FIM MID token = 151660 ‘<|fim_middle|>’
print_info: FIM PAD token = 151662 ‘<|fim_pad|>’
print_info: FIM REP token = 151663 ‘<|repo_name|>’
print_info: FIM SEP token = 151664 ‘<|file_sep|>’
print_info: EOG token = 151643 ‘<|endoftext|>’
print_info: EOG token = 151645 ‘<|im_end|>’
print_info: EOG token = 151662 ‘<|fim_pad|>’
print_info: EOG token = 151663 ‘<|repo_name|>’
print_info: EOG token = 151664 ‘<|file_sep|>’
print_info: max token length = 256
load_tensors: loading model tensors, this can take a while… (mmap = true)
load_tensors: CPU_Mapped model buffer size = 400.50 MiB
load_tensors: CPU_AARCH64 model buffer size = 191.95 MiB
…
[BPU_PLAT]BPU Platform Version(1.3.6)!
[HBRT] set log level as 0. version = 3.15.55.0
[DNN] Runtime version = 1.24.5_(3.15.55 HBRT)
[A][DNN][packed_model.cpp:247][Model](2025-05-30,21:16:46.663.819) [HorizonRT] The model builder version = 1.24.3
[ERROR][utils/mem_log.c:94] [5589.31558][18191:18191][ION_ALLOCATOR] <mem_ion_alloc_internal:601> Fail to do ION_IOC_ALLOC(ret=Cannot allocate memory)!
[ERROR][utils/mem_log.c:94] [5589.31558][18191:18191][ION_ALLOCATOR] <mem_alloc_handle_and_buf:750> Fail to allocate ion memory(ret=-12).
[ERROR][utils/mem_log.c:94] [5589.31558][18191:18191][ION_ALLOCATOR] <mem_osal_alloc_com_buf:945> Fail to allocate handle and buf(ret=-16777211).
[ERROR][utils/mem_log.c:94] [5589.31558][18191:18191][MEM_ALLOCATOR] <mem_try_alloc_com_buf_locked:297> Fail to allocate memory(Insufficient memory).
[ERROR][utils/mem_log.c:94] [5589.31558][18191:18191][MEM_ALLOCATOR] <hb_mem_alloc_com_buf_with_lable:491> Fail to allocate common buffer(ret=-16777211).
[ERROR][utils/mem_log.c:94] [5589.31610][18191:18191][HBMEM] <hbmem_alloc:246> Fail to allocate buffer(ret=-16777211).
[21:16:48:840:601] pid=18191 tid=18191 [HBRT 3.15.55.0] (line 265 in alloc_bpu_mem_usage from file=d1d314f3db5c18dae0d474f72ebb3d2844afca41) hbrt memory allocation fails, this memory allocation: 452329472, current total usage: 0, max total usage: 0
[ERROR][utils/mem_log.c:94] [5589.31610][18191:18191][MEM_ALLOCATOR] <hb_mem_invalidate_buf_with_vaddr:3470> Invalid NULL virtual address.
[ERROR][utils/mem_log.c:94] [5589.31610][18191:18191][HBMEM] <hbmem_cache_invalid:601> Fail to invalidate buffer(ret=-16777214).
[ERROR][utils/mem_log.c:94] [5589.32070][18191:18191][ION_ALLOCATOR] <mem_ion_alloc_internal:601> Fail to do ION_IOC_ALLOC(ret=Cannot allocate memory)!
[ERROR][utils/mem_log.c:94] [5589.32070][18191:18191][ION_ALLOCATOR] <mem_alloc_handle_and_buf:750> Fail to allocate ion memory(ret=-12).
[ERROR][utils/mem_log.c:94] [5589.32070][18191:18191][ION_ALLOCATOR] <mem_osal_alloc_com_buf:945> Fail to allocate handle and buf(ret=-16777211).
[ERROR][utils/mem_log.c:94] [5589.32070][18191:18191][MEM_ALLOCATOR] <mem_try_alloc_com_buf_locked:297> Fail to allocate memory(Insufficient memory).
[ERROR][utils/mem_log.c:94] [5589.32122][18191:18191][MEM_ALLOCATOR] <hb_mem_alloc_com_buf_with_lable:491> Fail to allocate common buffer(ret=-16777211).
[ERROR][utils/mem_log.c:94] [5589.32122][18191:18191][HBMEM] <hbmem_alloc:246> Fail to allocate buffer(ret=-16777211).
[21:16:48:845:772] pid=18191 tid=18191 [HBRT 3.15.55.0] (line 265 in alloc_bpu_mem_usage from file=d1d314f3db5c18dae0d474f72ebb3d2844afca41) hbrt memory allocation fails, this memory allocation: 452329472, current total usage: 0, max total usage: 0
[ERROR][utils/mem_log.c:94] [5589.32122][18191:18191][MEM_ALLOCATOR] <hb_mem_invalidate_buf_with_vaddr:3470> Invalid NULL virtual address.
[ERROR][utils/mem_log.c:94] [5589.32122][18191:18191][HBMEM] <hbmem_cache_invalid:601> Fail to invalidate buffer(ret=-16777214).
hbrtErrorBPUMemAllocFail
file=d1d314f3db5c18dae0d474f72ebb3d2844afca41
1194
hbrtErrorBPUMemAllocFail 3.15.55 file=7b0c25e023bb537c72d2b9349b00937143a7e5f8 2074
hbrtErrorBPUMemAllocFail 3.15.55 file=7b0c25e023bb537c72d2b9349b00937143a7e5f8 2097
hbrtErrorBPUMemAllocFail 3.15.55 file=7b0c25e023bb537c72d2b9349b00937143a7e5f8 2376
hbrtErrorBPUMemAllocFail 3.15.55 file=7b0c25e023bb537c72d2b9349b00937143a7e5f8 2509
hbrtErrorIllegalHBMHandle 3.15.55 file=7b0c25e023bb537c72d2b9349b00937143a7e5f8 2948
hbrtErrorIllegalHBMHandle 3.15.55 file=7b0c25e023bb537c72d2b9349b00937143a7e5f8 3023
[E][DNN][packed_model.cpp:437][Model](2025-05-30,21:16:48.919.665) hybrid model init fail
[E][DNN][packed_model.cpp:170][Model](2025-05-30,21:16:48.994.47) Load model failed, model file:./vit_model_int16_v2.bin
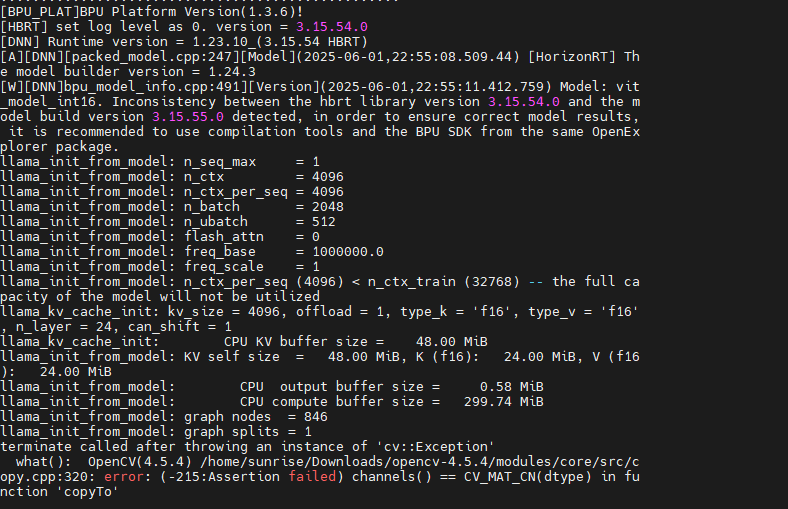
llama_init_from_model: n_seq_max = 1
llama_init_from_model: n_ctx = 4096
llama_init_from_model: n_ctx_per_seq = 4096
llama_init_from_model: n_batch = 2048
llama_init_from_model: n_ubatch = 512
llama_init_from_model: flash_attn = 0
llama_init_from_model: freq_base = 1000000.0
llama_init_from_model: freq_scale = 1
llama_init_from_model: n_ctx_per_seq (4096) < n_ctx_train (32768) – the full capacity of the model will not be utilized
llama_kv_cache_init: kv_size = 4096, offload = 1, type_k = ‘f16’, type_v = ‘f16’, n_layer = 24, can_shift = 1
llama_kv_cache_init: CPU KV buffer size = 48.00 MiB
llama_init_from_model: KV self size = 48.00 MiB, K (f16): 24.00 MiB, V (f16): 24.00 MiB
llama_init_from_model: CPU output buffer size = 0.58 MiB
llama_init_from_model: CPU compute buffer size = 299.74 MiB
llama_init_from_model: graph nodes = 846
llama_init_from_model: graph splits = 1
[E][DNN][hb_dnn.cpp:116][Model](2025-05-30,21:16:49.43.345) packed dnn handle is invalid
段错误