背景
我在使用RDKX5进行神经网络模型的部署, 想要通过地瓜算法工具链将ONNX模型转为定点的bin模型. 我的神经网络模型是在仿真器IsaacGym中通过强化学习训练得到的机器人运动控制策略, 它的输入为机器人状态(摇杆命令, 基座姿态, 基座角速度等)的历史帧的堆叠(每帧长度为31, 堆叠10帧, 输入总长度为310).
开发机环境
- Docker镜像: docker_openexplorer_ubuntu_20_x5_cpu_v1.2.8
- OE开发包: horizon_x5_open_explorer_v1.2.8-py310_20240926
操作过程
我参考了万字长文,学弟一看就会的RDKX5模型转换及部署,你确定不学?和地瓜机器人的官方文档进行模型的转换. 转换后得到xxx_original_float_model.onnx, xxx_optimized_float_model.onnx, xxx_calibrated_model.onnx, xxx_quantized_model.onnx, 再加上我原本导出的原始onnx模型共5个模型, 我使用官方文档中精度分析部分的示例代码加载onnx模型来测试这5个模型的输出是否一致, 代码如下:
# 加载D-Robotics 依赖库
from horizon_tc_ui import HB_ONNXRuntime
import numpy as np
# 准备模型运行的feed_dict
def prepare_input_dict(input_names):
feed_dict = dict()
for input_name in input_names:
# your_custom_data_prepare代表您的自定义数据
# 根据输入节点的类型和layout要求准备数据即可
feed_dict[input_name] = np.random.rand(1, 1, 1, 310).astype(np.float32)
return feed_dict
if __name__ == '__main__':
# 创建推理Session
sess = HB_ONNXRuntime(model_file="../Jan14_15-40-13_gym_ee_policy.onnx")
sess_original_float = HB_ONNXRuntime(model_file='rdkx5_original_float_model.onnx')
sess_optimized_float_model = HB_ONNXRuntime(model_file="rdkx5_optimized_float_model.onnx")
sess_calibrated = HB_ONNXRuntime(model_file="rdkx5_calibrated_model.onnx")
sess_quantized = HB_ONNXRuntime(model_file="rdkx5_quantized_model.onnx")
input_names = sess.input_names
output_names = sess.output_names
# 准备模型输入数据
feed_dict = prepare_input_dict(input_names)
outputs = sess.run(output_names, feed_dict, input_offset=0)
print("Model outputs:", outputs)
# 开始模型推理,推理的返回值是一个list,依次与output_names指定名称一一对应
outputs = sess_original_float.run(output_names, feed_dict, input_offset=0)
print("Original float model outputs:", outputs)
outputs = sess_optimized_float_model.run(output_names, feed_dict, input_offset=0)
print("Optimized float model outputs:", outputs)
outputs = sess_calibrated.run(output_names, feed_dict, input_offset=0)
print("Calibrated model output:", outputs)
outputs = sess_quantized.run(output_names, feed_dict, input_offset=0)
print("Quantized model output:", outputs)
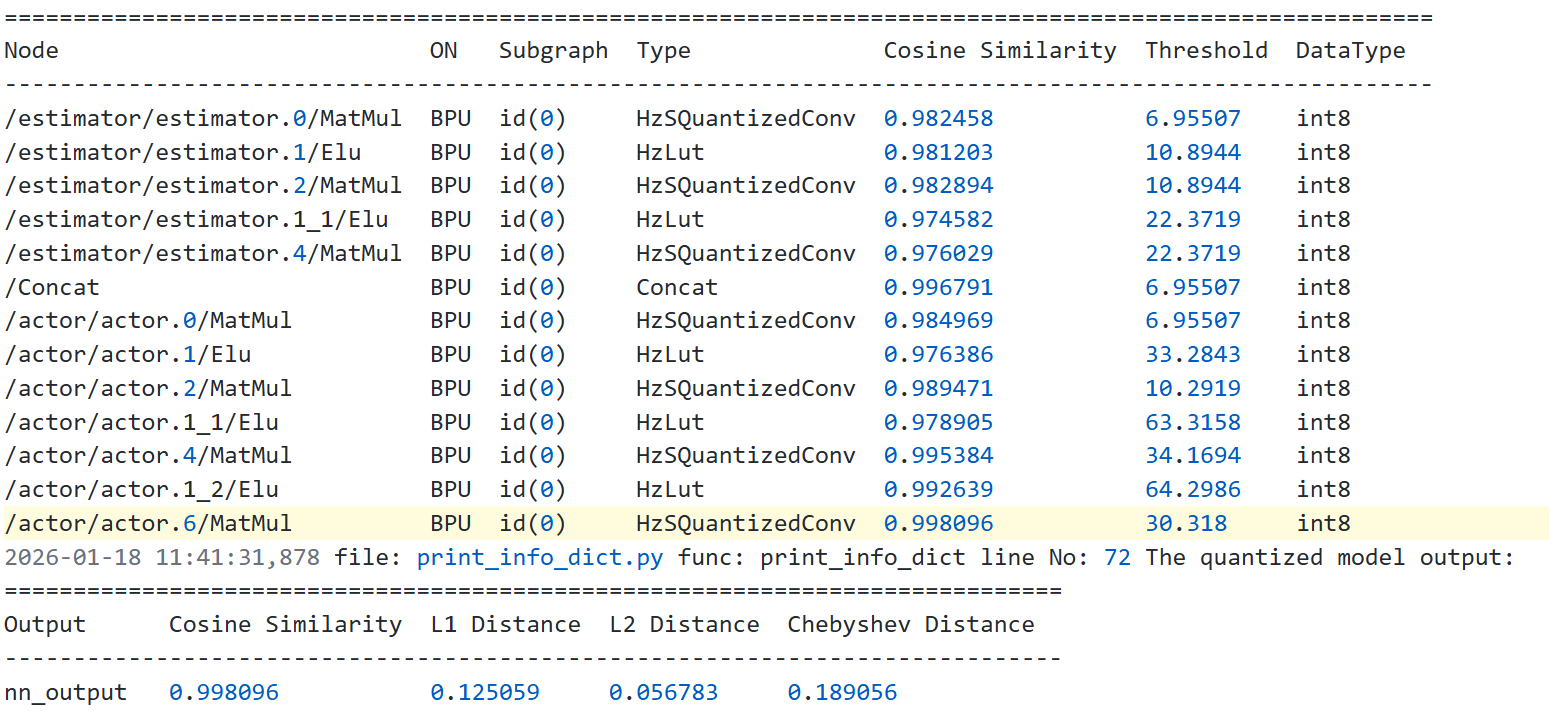
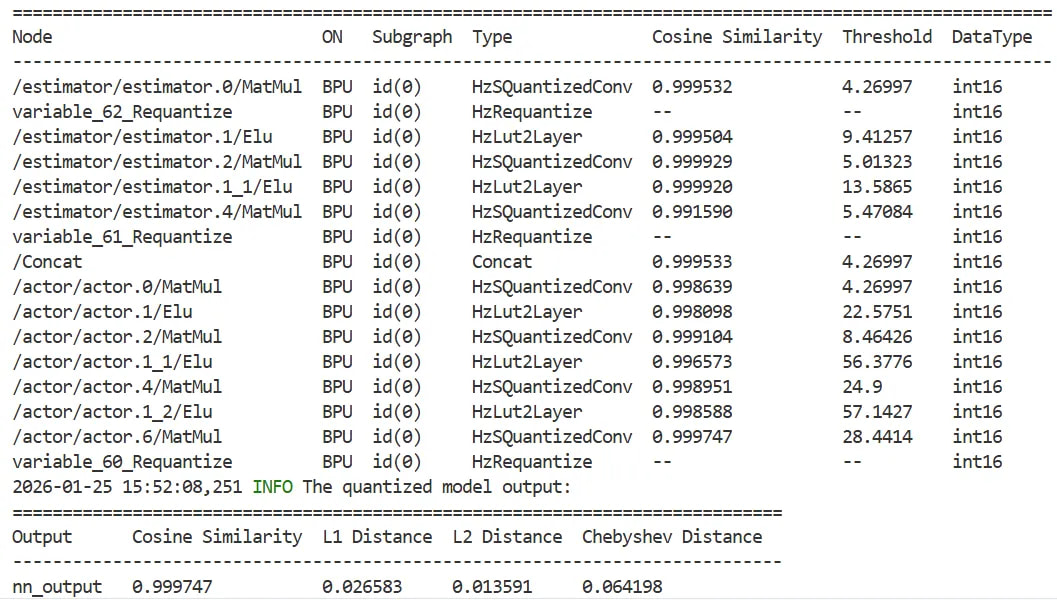
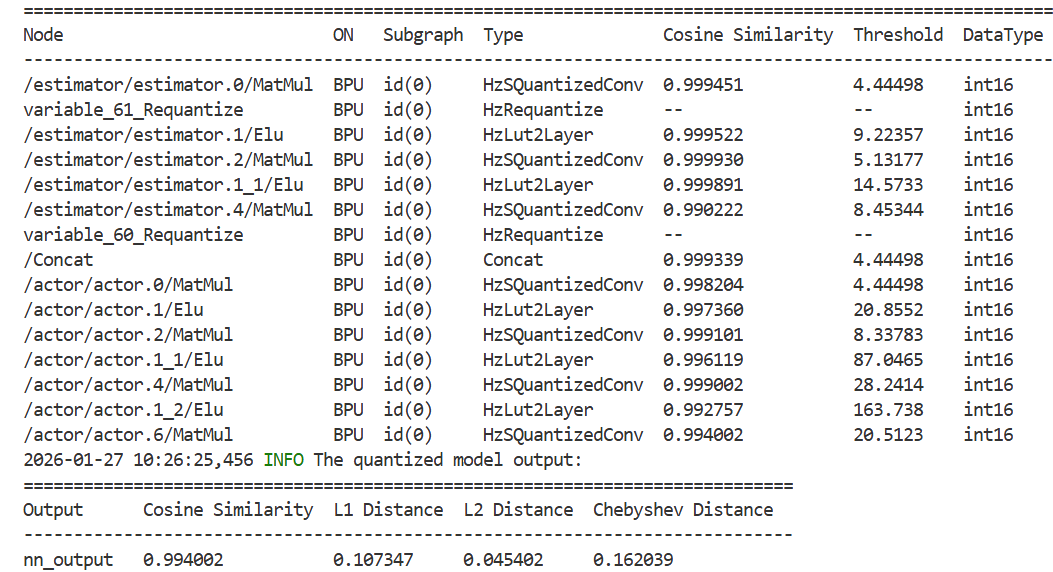
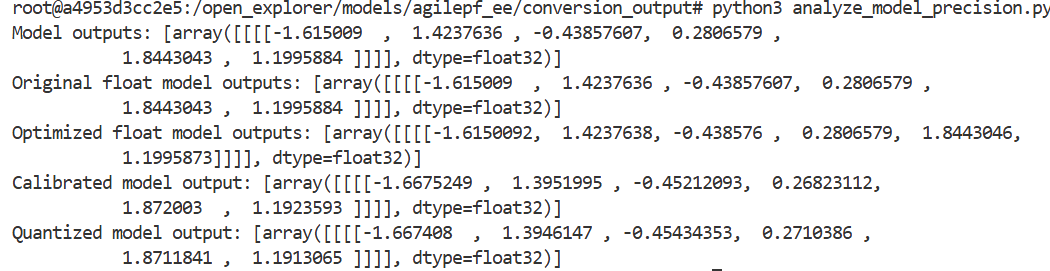
结果是从xxx_calibrated_model.onnx开始就已经不对了:
Model outputs: [array([[[[ -6.0534725, 1.932514 , 20. , -20. ,
5.816453 , -15.180331 ]]]], dtype=float32)]
Original float model outputs: [array([[[[ -6.0534725, 1.932514 , 20. , -20. ,
5.816453 , -15.180331 ]]]], dtype=float32)]
Optimized float model outputs: [array([[[[ -6.053468 , 1.9325157, 20. , -20. ,
5.8164496, -15.180326 ]]]], dtype=float32)]
Calibrated model output: [array([[[[-5.109056 , -3.6565728, 6.955066 , -6.9552784, -0.6518451,
-2.129587 ]]]], dtype=float32)]
Quantized model output: [array([[[[-5.0708494, -3.563816 , 6.955066 , -6.9552784, -0.6505715,
-2.1688547]]]], dtype=float32)]
我的校准数据是通过numpy.to_file()将仿真中的模型输入保存为bin文件得到的:
for i in range(100):
model_input = policy_observation.reshape(1,1,1,-1) # 将策略输入policy_observation reshape为(1,1,1,310)
model_input.cpu().numpy().to_file(f'./samples_rdk/rdk_model_input_{i:03d}.bin') # cuda的tensor转为numpy然后保存为bin文件
我在转换过程中使用的yaml文件, 原始模型, 校准数据以及转换过程中的模型产物, 日志文件都在如下的模型转换文件.zip中, 这些文件被我放在开发机的OE开发包的一个单独的目录下(如下图).
模型转换文件.zip (8.9 MB)
问题
-
RDKX5是否支持非图像输入的神经网络模型量化及BPU推理?
我看到了论坛中相关的2个帖子: 强化学习RDK X5部署量化bin模型时和onnx模型不匹配, 【强化学习算法】【RDK X5】非图像数据类型的扁平化输入数据模型推理错误. 其中第2个帖子的回答中说"X5的BPU接口目前不支持feature map输入,需要使用C/C++写Runtime程序,其他的输入类型需要使用libdnn的C/C++接口", 意思是目前RDKX5官方提供的接口无法直接进行feature map输入的推理?
同时我还看到了基于RDK S100的逐际动力点足运控模型部署全流程讲解这篇帖子, 但并没有找到文中说的配置文件和校准数据. 我目前的理解是, RDKX5不可以进行非图像输入的神经网络模型量化及推理, 但RDKS100可以, 不知道这个理解对不对?
-
from horizon_tc_ui import HB_ONNXRuntime中HB_ONNXRuntime并没有run_feature这个函数官方文档写了如果输入类型为FEATURE则需要调用run_feature函数, 但是运行后会报错:
AttributeError: 'HB_ONNXRuntime' object has no attribute 'run_feature'